
4

常见分布式基础设施系统设计图解(八):分布式键值存储系统
source link: https://www.raychase.net/7121
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

常见分布式基础设施系统设计图解(八):分布式键值存储系统
Key-value 存储系统大概是分布式存储系统中最常见的一种类型了。从功能需求的角度说,最核心的包括:
- 可以创建一张表和删除一张表,同时对于表的数据可以进行:
- 读,即 get(key) 返回 value
- 写,即 put(key, value)
- 删除,即 delete(key)
当然,也有一些其它的功能需求,比如支持事务性,支持 key 排序查询,range key 或者特定列索引,支持同一 key 下 value 的 version 等等。
从非功能需求的角度说,凡是存储系统,Durability 是最重要的,数据不能丢失;其次是 Availability;再次是 Performance,这样的系统需要考虑 throughput 和 latency 二者。
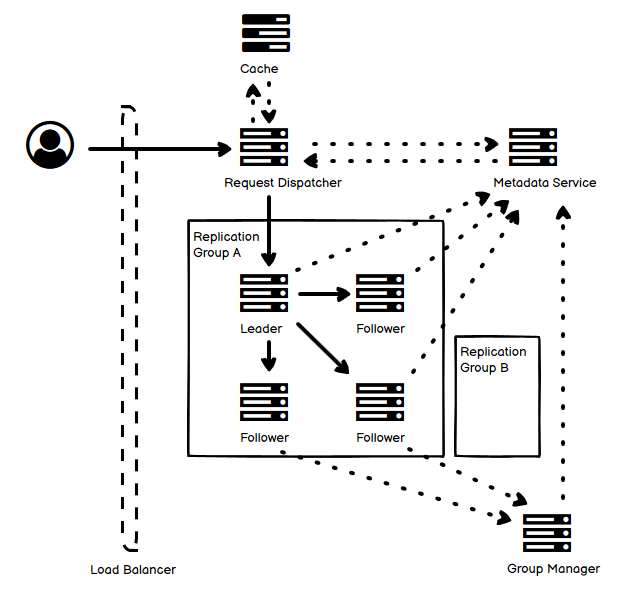
- 宏观上看,实线是数据流,虚线是控制流。
- get 或是 put 请求被发送到 Request Manager,而 Request Manager 会询问 Metadata Service 来获知这个请求应该被送到哪一个 Replication Group 去。
- 每一个 Replication Group 都存放有若干个数据节点,包括一个 leader 和若干个 follower,他们都和 Group Manager 通信。
- Group Manager 会根据它们的健康状况、繁忙状况来动态调整,并将调整同步到 Metadata Service。
- Metadata Service 主要负责下面两件事情,它可以由 Zookeeper 等技术来实现:
- 一个是记录每个 Replication Group 中,谁是 leader。
- 这个 leader 可以由 Metadata Service 来确定。
- 另一个是存储 key 到每一个 replication group 的映射关系。
- 当 Metadata Service 的节点映射表生成以后,就可以缓存在 Request Manager 的内存中,这样不需要每次来一个请求就查询 Metadata Service。
- 对它的任何修改都要立即持久化并 propagate,不可丢失。
- 一个是记录每个 Replication Group 中,谁是 leader。
- 然后是 Replication Group,每一个 group 都有一个 leader,其它的都是 follower。
- 所有的读或写的请求,全部都先送到 leader 去,仅有一个 leader 也保证了一致性。
- 每次写的请求,leader 在得知大多数的节点都更新成功后,就可以返回并用户。
- 对于节点上的数据存储:
- 优化写:使用 Append Only Log (commit log),第一时间使用磁盘顺序写入的 Append Only Log 来记录,同时保证了 latency 和 durability,它是所谓的 source of truth。之后更新内存,等内存到一定 threshold,就进行 merge 存放到磁盘上,比如在 SST 中(相当于定期 snapshot / compaction)。
- 优化读:使用内存中的 Bloom Filter 来判断存在性,如果数据不存在直接返回。
- 对于 key 在内存里存放的结构,如果是读多写少的系统,可以使用 B+ Tree;如果是写多读少的系统,可以使用 LSM Tree。并非整棵树都要放在内存里,而是部分节点可以存放在内存中。
- Group 中的每一个节点都要和 Metadata Service 心跳汇报健康状况。
- 接着是 Group Manager,它会监控并注意到 Replication Group 中节点的问题,动态加入和挪出节点。
- 有时候热点数据让节点特别繁忙或者数据量过大,Group Manager 会拆分节点的数据到多个节点中,并更新 Metadata Service。
- 在节点更新和数据搬迁的过程中,考虑到潜在的数据不一致问题,同一个请求可能会被 Request Manager 岔分成两个请求,必须同时访问到两个数据节点,来获取最新的数据。对于每一条数据,都有一个自动生成的 version,即版本号,用来判断一旦有冲突发生时的先后顺序。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Comment *
Name
Save my name, email, and website in this browser for the next time I comment.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK