

TICK: I 时序数据库InfluxDB
source link: http://abcdxyzk.github.io/blog/2022/08/25/influx-influxdb/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

TICK: I 时序数据库InfluxDB
2022-08-25 08:45:00
wget https://repos.influxdata.com/rhel/8/x86_64/stable/influxdb-1.8.10.x86_64.rpm
基本概念 何谓时间序列数据库?
什么是时间序列数据库,最简单的定义就是数据格式里包含Timestamp字段的数据,比如某一时间环境的温度,CPU的使用率等。但是,有什么数据不包含Timestamp呢?几乎所有的数据其实都可以打上一个Timestamp字段。时间序列数据的更重要的一个属性是如何去查询它,包括数据的过滤,计算等等。
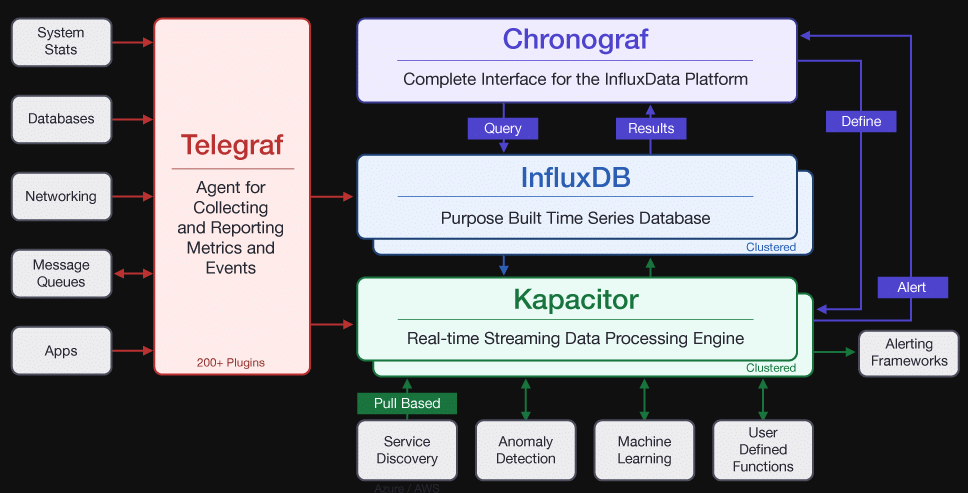
1、特色功能
时序性(Time Series):与时间相关的函数的灵活使用(诸如最大、最小、求和等);
度量(Metrics):对实时大量数据进行计算;
事件(Event):支持任意的事件数据,换句话说,任意事件的数据我们都可以做操作。
2、主要特点
schemaless(无结构),可以是任意数量的列;
min, max, sum, count, mean, median 一系列函数,方便统计;
Native HTTP API, 内置http支持,使用http读写;
Powerful Query Language 类似sql;
Built-in Explorer 自带管理工具。
# 路径:/usr/bin
influxd # influxdb服务器
influx # influxdb命令行客户端
influx_inspect # 查看工具
influx_stress # 压力测试工具
influx_tsm # 数据库转换工具(将数据库从b1或bz1格式转换为tsm1格式)
# 路径:/var/lib/influxdb/
data # 存放最终存储的数据,文件以.tsm结尾
meta # 存放数据库元数据
wal # 存放预写日志文件
service influxdb startinflux在具体的讲解influxdb的相关操作之前先说说influxdb的一些专有名词,这些名词代表什么。
database:数据库;
measurement:数据库中的表;
points:表里面的一行数据。
influxDB中独有的一些概念
Point由时间戳(time)、数据(field)和标签(tags)组成。
time:每条数据记录的时间,也是数据库自动生成的主索引;
fields:各种记录的值;
tags:各种有索引的属性。
还有一个重要的名词:series
所有在数据库中的数据,都需要通过图表来表示,series表示这个表里面的所有的数据可以在图标上画成几条线(注:线条的个数由tags排列组合计算出来)
#显示用户
show users
#创建用户
create user "username" with password 'password'
#创建管理员权限用户create user "username" with password 'password' with all privileges
#删除用户
drop user "username"数据库访问权限
创建权限 GRANT READ ON mydb TO leo
撤消权限 REVOKE ALL ON mydb FROM leo 管理权限
创建集群管理权限 GRANT ALL PRIVILEGES TO leo
撤消集群管理权限 REVOKE ALL PRIVILEGES FROM leo
#创建数据库
create database "db_name"
#显示所有的数据库
show databases
#删除数据库
drop database "db_name"
#使用数据库
use db_name
#显示该数据库中所有的表
show measurements
#创建表,直接在插入数据的时候指定表名
insert test,host=127.0.0.1,monitor_name=test count=1
#删除表
drop measurement "measurement_name"向数据库中插入数据。
通过命令行
use testDb
insert test,host=127.0.0.1,monitor_name=test count=1通过http接口
curl -i -XPOST 'http://127.0.0.1:8086/write?db=testDb' --data-binary 'test,host=127.0.0.1,monitor_name=test count=1'读者看到这里可能会观察到插入的数据的格式貌似比较奇怪,这是因为influxDB存储数据采用的是Line Protocol格式。那么何谓Line Protoco格式?
Line Protocol格式:写入数据库的Point的固定格式。 在上面的两种插入数据的方法中都有这样的一部分:
test,host=127.0.0.1,monitor_name=test count=1test:表名;
host=127.0.0.1,monitor_name=test:tag;
count=1:field想对此格式有详细的了解参见官方文档
查询数据库中的数据。
通过命令行
select * from test order by time desc通过http接口
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=testDb" --data-urlencode "q=select * from test order by time desc"influxDB是支持类sql语句的
InfluxDB 数据保留策略操作
语法:CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
<retention_policy_name>:保留策略名称
<database_name>:数据库名称
<duration>:保留策略对应数据的过期时间
REPLICATION:副本因子
SHARD DURATION:分片组默认时长
[DEFAULT]:是否为默认的保留策略创建数据保留策略
CREATE RETENTION POLICY "influx_retention" ON "mydb" DURATION 30d REPLICATION DEFAULT;查看保留期
SHOW RETENTION POLICIES ON mydb修改保留期
ALTER RETENTION POLICY "influx_retention" ON mydb DURATION 15d删除保留期
DROP RETENTION POLICY "influx_retention" ON mydb influxdb函数分为聚合函数,选择函数,转换函数,预测函数等。除了与普通数据库一样提供了基本操作函数外,还提供了一些特色函数以方便数据统计计算,下面会一一介绍其中一些常用的特色函数。
聚合函数:FILL(), INTEGRAL(),SPREAD(), STDDEV(),MEAN(), MEDIAN()等。
选择函数: SAMPLE(), PERCENTILE(), FIRST(), LAST(), TOP(), BOTTOM()等。
转换函数: DERIVATIVE(), DIFFERENCE()等。
预测函数:HOLT_WINTERS()。
GROUP BY,FILL()
如下语句中 GROUP BY time(12m),* 表示以每12分钟和tag(location)分组(如果是GROUP BY time(12m)则表示仅每12分钟分组,GROUP BY 参数只能是time和tag)。然后fill(200)表示如果这个时间段没有数据,以200填充,mean(field_key)求该范围内数据的平均值(注意:这是依据series来计算。其他还有SUM求和,MEDIAN求中位数)。LIMIT 7表示限制返回的point(记录数)最多为7条,而SLIMIT 1则是限制返回的series为1个。
INTEGRAL(field_key, unit)
计算数值字段值覆盖的曲面的面积值并得到面积之和。测试数据如下:
SPREAD(field_key)
计算数值字段的最大值和最小值的差值。
> SELECT SPREAD("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),* fill(18) LIMIT 3 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time spread
---- ------
2015-08-17T23:48:00Z 18
2015-08-18T00:00:00Z 0.052000000000000046
2015-08-18T00:12:00Z 0.09799999999999986STDDEV(field_key)
计算字段的标准差。influxdb用的是贝塞尔修正的标准差计算公式 ,如下:
mean=(v1+v2+…+vn)/n;
stddev = math.sqrt(((v1-mean)2 + (v2-mean)2 + …+(vn-mean)2)/(n-1))
PERCENTILE(field_key, N)
选取某个字段中大于N%的这个字段值。
如果一共有4条记录,N为10,则10%*4=0.4,四舍五入为0,则查询结果为空。N为20,则 20% * 4 = 0.8,四舍五入为1,选取的是4个数中最小的数。如果N为40,40% * 4 = 1.6,四舍五入为2,则选取的是4个数中第二小的数。由此可以看出N=100时,就跟MAX(field_key)是一样的,而当N=50时,与MEDIAN(field_key)在字段值为奇数个时是一样的。
SAMPLE(field_key, N)
随机返回field key的N个值。如果语句中有GROUP BY time(),则每组数据随机返回N个值。
CUMULATIVE_SUM(field_key)
计算字段值的递增和。
DERIVATIVE(field_key, unit) 和 NON_NEGATIVE_DERIVATIVE(field_key, unit)
计算字段值的变化比。unit默认为1s,即计算的是1秒内的变化比。
如下面的第一个数据计算方法是 (2.116-2.064)/(6*60) = 0.00014..,其他计算方式同理。虽然原始数据是6m收集一次,但是这里的变化比默认是按秒来计算的。如果要按6m计算,则设置unit为6m即可。
http://wjhsh.net/dehai-p-4883451.html
http://t.zoukankan.com/jackyroc-p-7677508.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK