

超详细的RabbitMQ入门与实战介绍,看这篇文章就够了
source link: https://www.51cto.com/article/717108.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一、前情提示
上一篇文章《教你面试的时候如何迅速完成90%以上的海量数据处理题》,我们已经给出了一整套的数据一致性的保障方案。
我们从如下三个角度,给出了方案如何实现。并且通过数据平台和电商系统进行了举例分析。
- 核心数据的监控。
- 数据链路追踪。
- 自动化数据链路分析。
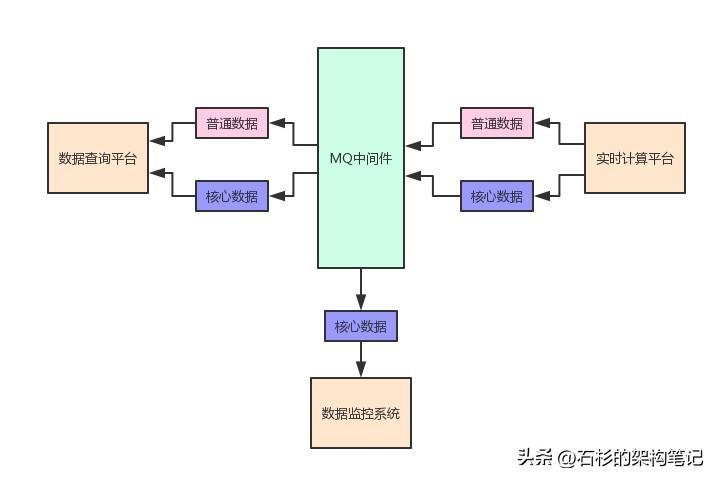
目前为止,我们的架构图大概如下所示:
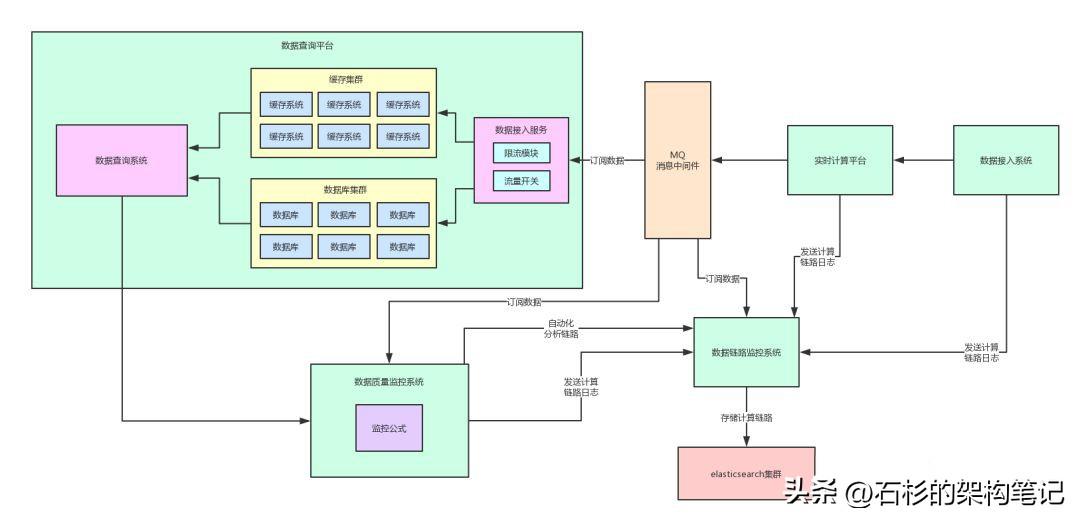
并且咱们之前对于这种架构下,如何基于MQ进行解耦的实现也做了详细的说明。
那么这篇文章,我们就基于这个架构,在数据一致性方面做进一步的说明。同样,我们以RabbitMQ这个消息中间件来举例。
二、选择性的订阅部分核心数据
首先一个基于MQ实现的细节点就在于,比如对数据监控系统而言,他可能仅仅只是要从MQ里订阅部分数据来消费罢了。
这个是啥意思呢?因为比如实时计算平台他是会将自己计算出来的所有的数据指标都投递到MQ里去的。
但是这些数据指标可能是多达几十个甚至是几百个的,这里面不可能所有数据指标都是核心数据吧?
基本上按照我们过往经验而言,对于这种数据类的系统核心数据指标,大概就占到10%左右的比例而已。
然后对于数据查询平台而言,他可能是需要把所有的数据指标都消费出来,然后落地到自己的存储里去的。
但是对于数据监控系统而言,他只需要过滤出10%的核心数据指标即可,所以他需要的是有选择性的订阅数据。
咱们看看下面的图,立马就明白是什么意思了。

三、RabbitMQ的queue与exchange的绑定
不知道大家是否还记得之前讲解基于RabbitMQ实现多系统订阅同一份数据的场景。
我们采用的是每个系统使用自己的一个queue,但是都绑定到一个fanout exchange上去,然后生产者直接投递数据到fanout exchange。
fanout exchange会分发一份数据,绑定到自己的所有queue上去,然后各个系统都会从自己的queue里拿到相同的一份数据。
大家再看看下面的图回顾一下。
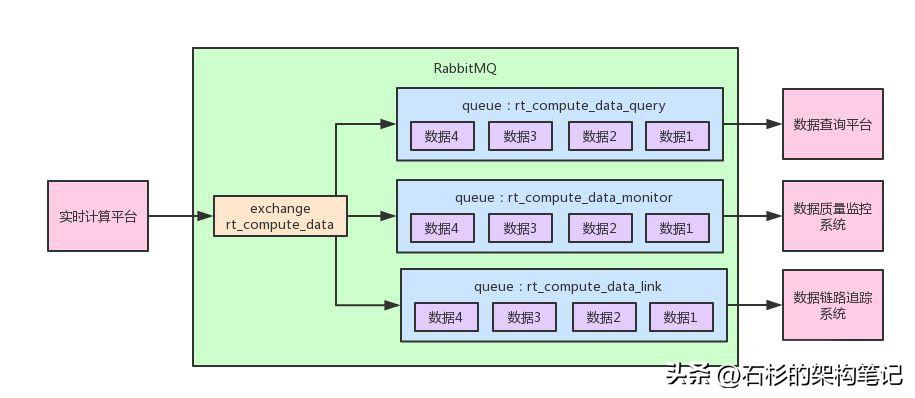
在这里有一个关键的代码如下所示:
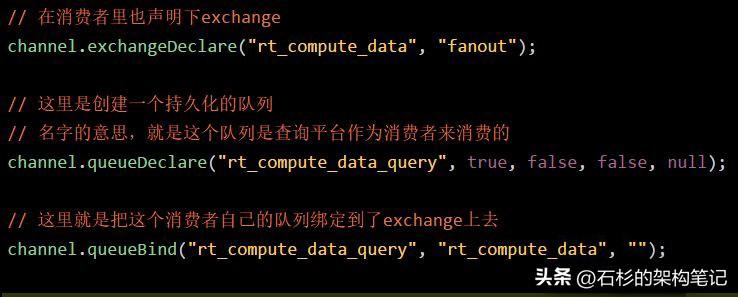
也就是说,把自己创建的queue绑定到exchange上去,这个绑定关系在RabbitMQ里有一个专业的术语叫做:binding。
四、direct exchange实现消息路由
如果仅仅使用之前的fanout exchange,那么是无法实现不同的系统按需订阅数据的,如果要实现允许不同的系统按需订阅数据,那么需要使用direct exchange。
direct exchange允许你在投递消息的时候,给每个消息打上一个routing key。同时direct exchange还允许binding到自己的queue指定一个binding key。
这样,direct exchange就会根据消息的routing key将这个消息路由到相同binding key对应的queue里去,这样就可以实现不同的系统按需订阅数据了。
说了这么多,是不是感觉有点晕,老规矩,咱们来一张图,直观的感受一下怎么回事儿:
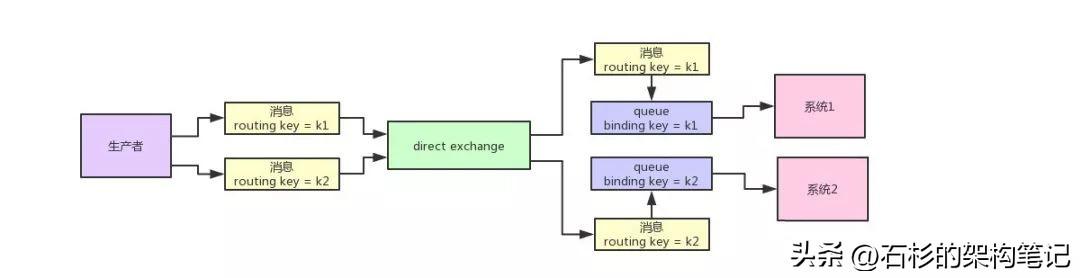
而且一个queue是可以使用多个binding key的,比如说使用“k1”和“k2”两个binding key的话,那么routing key为“k1”和“k2”的消息都会路由到那个queue里去。
同时不同的queue也可以指定相同的ruoting key,这个时候就跟fanout exchange其实是一样的了,一个消息会同时路由到多个queue里去。
五、按需订阅的代码实现
首先在生产者那块,比如说实时计算平台吧,他就应该是要定义一个direct exchange了。
如下代码所示,所有的数据都是投递到这个exchange里去,比如我们这里使用的exchange名字就是“rt_data”,意思就是实时数据计算结果,类型是“direct”:
channel.exchangeDeclare(
"rt_data",
"direct");而且,在投递消息的时候,要给一个消息打上标签,也就是他的routing key,表明这个消息是普通数据还是核心数据,这样才能实现路由,如下代码所示:
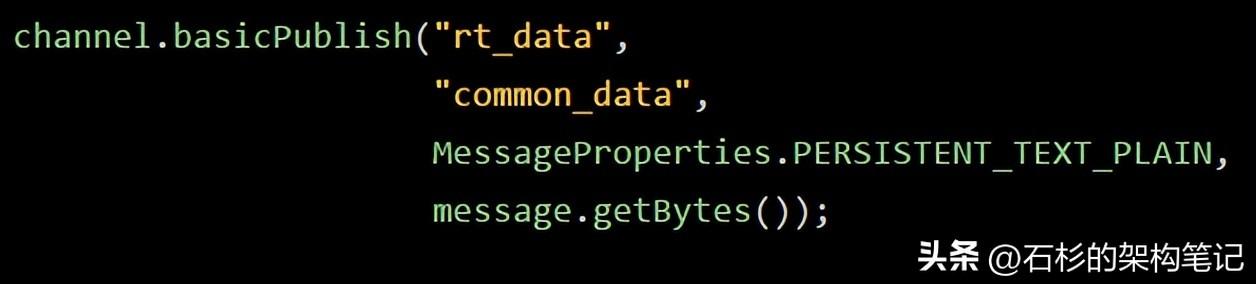
上面第一个参数是指定要投递到哪个exchange里去,第二个参数就是routing key,这里的“common_data”代表了是普通数据,也可以用“core_data”代表核心数据,实时计算平台根据自己的情况指定普通或者核心数据。
然后消费者在进行queue和exchange的binding的时候,需要指定binding key,代码如下所示:
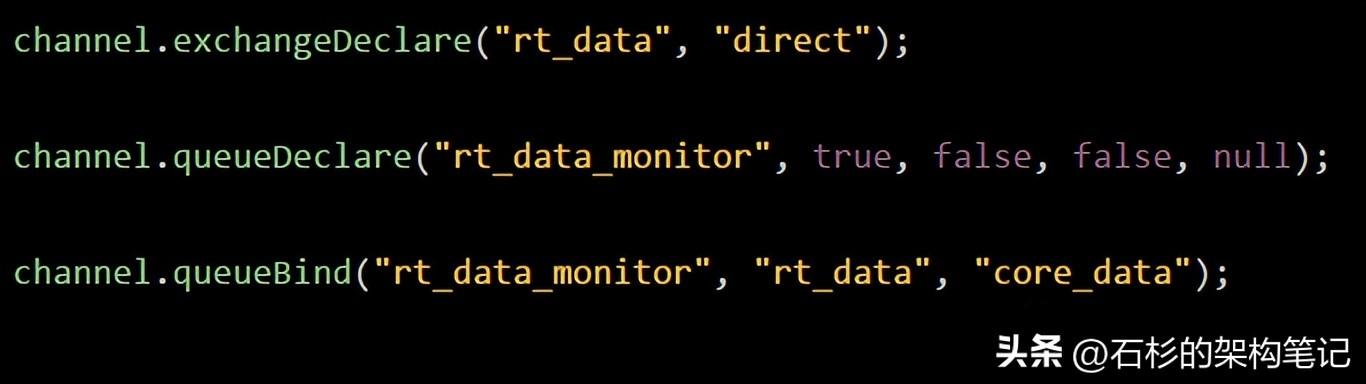
上面第一行就是在消费者那里,比如数据监控系统那里,也是定义一下direct exchange。
然后第二行就是定义一个“rt_data_monitor“这个queue。
第三行就是对queue和exchange进行绑定,指定了binding key是“core_data”。
如果是数据查询系统,他是普通数据和核心数据都要的,那么就可以在binding key里指定多个值,用逗号隔开,如下所示:
channel.queueBind(
"rt_data_query",
"rt_data",
"common_data, core_data");到这里,大家就明白如何对数据打上不同的标签(也就是routing key),然后让不同的系统按需订阅自己需要的数据了(也就是指定binding key),这种方式用到了direct exchange这种类型,非常的灵活。
最后,再看看之前画的那幅图,大家再来感受一下即可:
六、更加强大而且灵活的按需订阅
RabbitMQ 还支持更加强大而且灵活的按需数据订阅,也就是使用topic exchange,其实跟direct exchange是类似的,只不过功能更加的强大罢了。
比如说你定义一个topic exchange,然后routing key就需要指定为用点号隔开的多个单词,如下所示:
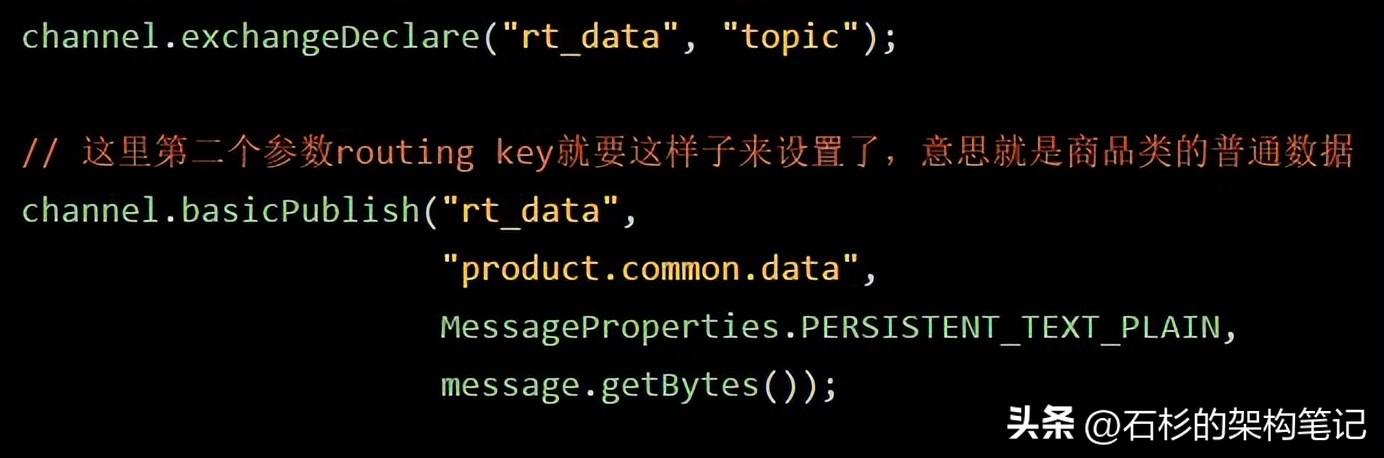
然后,你在设置binding key的时候,他是支持通配符的。 * 匹配一个单词,# 匹配0个或者多个单词,比如说你的binding key可以这么来设置:
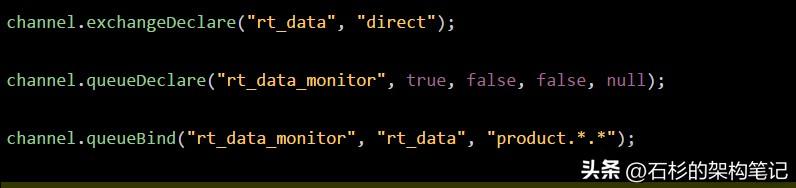
这个product.*.* ,就会跟“product.common.data”匹配上,意思就是,可能某个系统就是对商品类的数据指标感兴趣,不管是普通数据还是核心数据。
所以到这里,大家就应该很容易明白了,通过RabbitMQ的direct、topic两种exchange,我们可以轻松实现各种强大的数据按需订阅的功能。
通过本文,我们就将最近讲的数据一致性保障方案里的一些MQ中间件落地的细节给大家说明白了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK