

字节跳动开源自研 Shuffle 框架——Cloud Shuffle Service
source link: https://www.51cto.com/article/717086.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Cloud Shuffle Service(以下简称CSS) 是字节自研的通用 Remote Shuffle Service 框架,支持 Spark/FlinkBatch/MapReduce 等计算引擎,提供了相比原生方案稳定性更好、性能更高、更弹性的数据 Shuffle 能力,同时也为存算分离/在离线混部等场景提供了 Remote Shuffle 解决方案。
目前,CSS 已在 Github 上开源,欢迎感兴趣的同学一起参与共建!
项目地址:
https://github.com/bytedance/CloudShuffleService
在大数据计算引擎中,Pull-Based Sort Shuffle 是一种常见的 Shuffle 方案,比如 Spark/MapReduce/FlinkBatch (高于1.15版本)等都将 Sort Shuffle 作为引擎默认方案,但是 Sort Shuffle 实现机制有一定的缺陷,在大规模生产环境下经常因为 Shuffle 问题影响作业稳定性。
以 Spark 的 Sort Shuffle 为例:
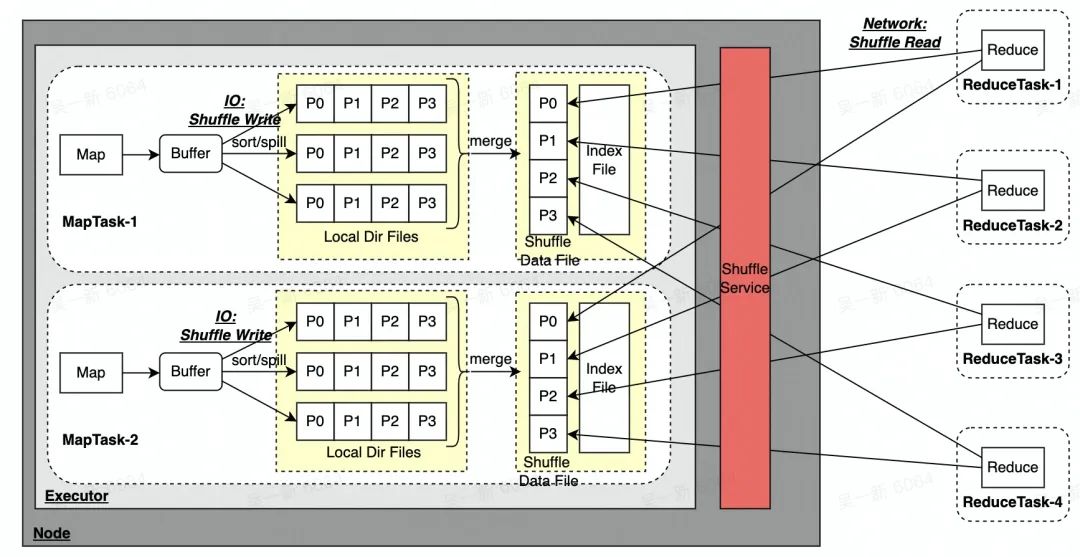
如上图所示链路,Sort Shuffle 会存在以下一些问题:
- 将多个 Spill 文件合并成一个文件,会额外消耗读写 IO;
假设有 m 个 MapTask & n 个 ReduceTask,会产生 m*n 个网络链接,当数量特别多时:
- 大量的网络请求会导致 Shuffle Service 容易形成积压;
- Shuffle Service 会产生大量的随机读取,容易导致 IO 瓶颈,特别是 HDD 集群;
- Shuffle Service 无法做到 Application 的资源隔离,当有一个异常作业时,可能会影响同一个 Shuffle Service 节点上其它所有作业,问题容易放大;
- MapTask 生成的 Shuffle Data File 只存储一份到本地,当磁盘坏了也会导致数据丢失,同样引起 FetchFailed 问题;
- Shuffle Data File 写到本地磁盘的方式,依赖计算节点上的磁盘,无法做到存算分离
这些都很容易导致 ShuffleRead 慢或者超时,引起 FetchFailed 相关错误,严重影响线上作业的稳定性,ShuffleRead 慢也会大大降低资源利用率(CPU&Memory),同时 FetchFailed 也会导致 Stage 中相关 Task 重算,浪费大量资源,拖慢整个集群作业运行;无法存算分离的架构,在在离线混部(在线资源磁盘不足)/Serverless 云原生等场景下,也很难满足要求。字节跳动使用 Spark 作为主要的离线大数据处理引擎,每天线上运行作业数过百万,日均 Shuffle 量 300+PB。在 HDFS 混部&在离线混部等场景,Spark 作业的稳定性经常无法得到保障,影响业务 SLA:
- 受限 HDD 磁盘 IO 能力/磁盘坏等情况,导致大量的 Shuffle FetchFailed 引起的作业慢/失败/Stage 重算等问题,影响稳定性&资源利用率
- External Shuffle Service (以下简称ESS) 存算无法分离,遇到磁盘容量低的机器经常出现磁盘打满影响作业运行
在此背景下,字节跳动自研了 CSS,用来解决 Spark 原生 ESS 方案的痛点问题。自 CSS 在内部上线一年半以来,当前线上节点数 1500+,日均 Shuffle 量 20+PB,大大提高了 Spark 作业的 Shuffle 稳定性,保障了业务的 SLA。
Cloud Shuffle Service 介绍
CSS 是字节自研的 Push-Based Shuffle Service,所有 MapTask 通过 Push 的方式将同一个 Partition 的 Shuffle 数据发送给同一个 CSS Worker 节点进行存储,ReduceTask 直接从该节点通过 CSS Worker 顺序读取该 Partition 的数据,相对于 ESS 的随机读取,顺序读的 IO 效率大大提升。
CSS 架构
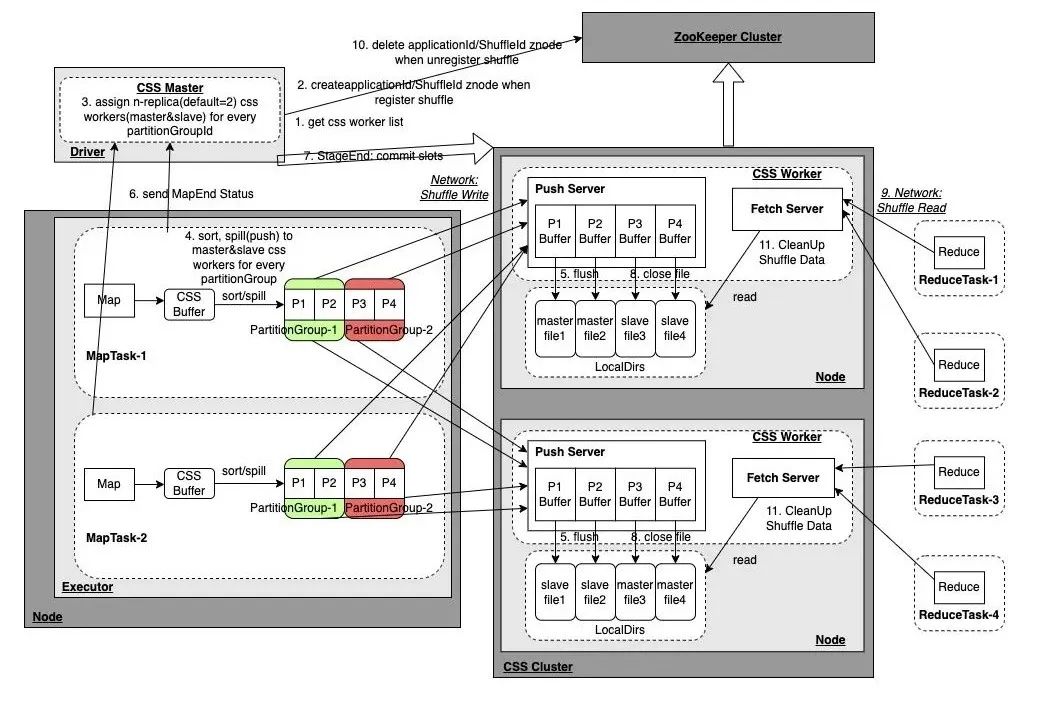
CSS Worker
CSS Worker 启动后会向 ZooKeeper 节点注册节点信息,它提供 Push/Fetch 两种服务请求,Push 服务接受来自 MapTask 的 Push 数据请求,并将同一个 Partition 的数据写到同一个文件;Fetch 服务接受来自 ReduceTask 的 Fetch 数据请求,读取对应 Partition 数据文件返回;CSS Worker还负责 Shuffle 数据清理的工作,当 Driver 进行 UnregisterShuffle 请求删除 ZooKeeper 对应 ShuffleId 的 Znode 时,或者 Application 结束删除 ZooKeeper 中 ApplicationId 的 Znode 时,CSS Workers 会 Watch 相关事件对 Shuffle 数据进行清理。
CSS Master
作业启动后会在 Spark Driver 中启动 CSS Master,CSS Master 会从 ZooKeeper 中获取到 CSS Worker 的节点列表,然后为后续 MapTask 产生的各个 Partition 分配 n 个副本(默认为2)的 CSS Worker 节点,并对这些 Meta 信息进行管理,供 ReduceTask 获取 PartitionId 所在的 CSS Worker 节点进行拉取,同时在 RegisterShuffle/UnregisterShuffle 过程中会在 ZooKeeper 中创建对应的 ApplicationId/ShuffleId 的 Znode,CSS Worker 会 Watch Delete 事件对 Shuffle 数据进行清理。
ZooKeeper
如前描述,用来存储 CSS Worker 节点信息以及 ShuffleId 等信息。
CSS 特性
多引擎支持
CSS除了支持 Spark(2.x&3.x) 之外,也可以接入其他引擎,目前在字节跳动内部,CSS 还接入了 MapReduce/FlinkBatch 引擎。
PartitionGroup 支持
为了解决单个 Partition 太小,Push 效率比较低的问题,实际会将多个连续的 Partition 组合成更大的 PartitionGroup进行 Push。
高效统一的内存管理
跟 ESS 类似,MapTask 中的 CSS Buffer 将所有 Partition 的数据都存储在一起,在 Spill 之前会对数据按照 PartitionId 进行排序,然后按照 PartitionGroup 维度进行数据推送;同时 CSS Buffer 完全纳入 Spark 的 UnifiedMemoryManager 内存管理体系,内存相关参数由 Spark 统一管理。
容错处理
Push 失败:当触发 Spill 进行 Push PartitionGroup 数据时,每次 Push 的数据大小为 4MB(一个Batch),当某次 Push batch 失败时,并不影响之前已经 Push 成功的数据,只需要重新分配节点(Reallocate)继续 Push 当前失败的数据以及后续还未 Push 的数据,后续 ReduceTask 会从新老节点读取完整的 Partition 数据;多副本存储:ReduceTask 从 CSS Worker 读取某个 Partition 数据是按照 Batch 粒度进行拉取的,当 CSS Worker 异常(如网络问题/磁盘坏等)导致无法获取该 Batch 数据,可以继续选择另外一个副本节点继续读取该 Batch 以及后续 Batch 的数据;数据去重:当作业开启 Speculative 推测执行会有多个 AttempTask 并发跑,需要在读取的时候进行去重。在 Push Batch 的时候,会给 Batch 数据加上 Header 信息,Header 信息中包含 MapId + AttempId + BatchId 等信息,ReduceTask 读取时可以根据这些 ID 信息进行去重。
Adaptive Query Execution(AQE) 适配
CSS 完整支持 AQE 相关的功能,包括动态调整 Reduce 个数/ SkewJoin 优化/Join 策略优化。对于SkewJoin,CSS做了更多的适配优化工作,解决了 Skew Partition 数据被多个 ReduceTask 重复读取问题,大大提高了性能。
CSS 性能测试
我们将 CSS 与开源的 ESS 使用独占 Label 计算资源进行 1TB 的 TPC-DS Benchmark 测试对比,整体端到端的性能提升15%左右,部分 Query 有30%以上的性能提升。同时我们也使用线上混部资源队列(ESS 稳定较差)进行 1TB 的 TPC-DS Benchmark 测试对比,整体端到端性能提升4倍左右。
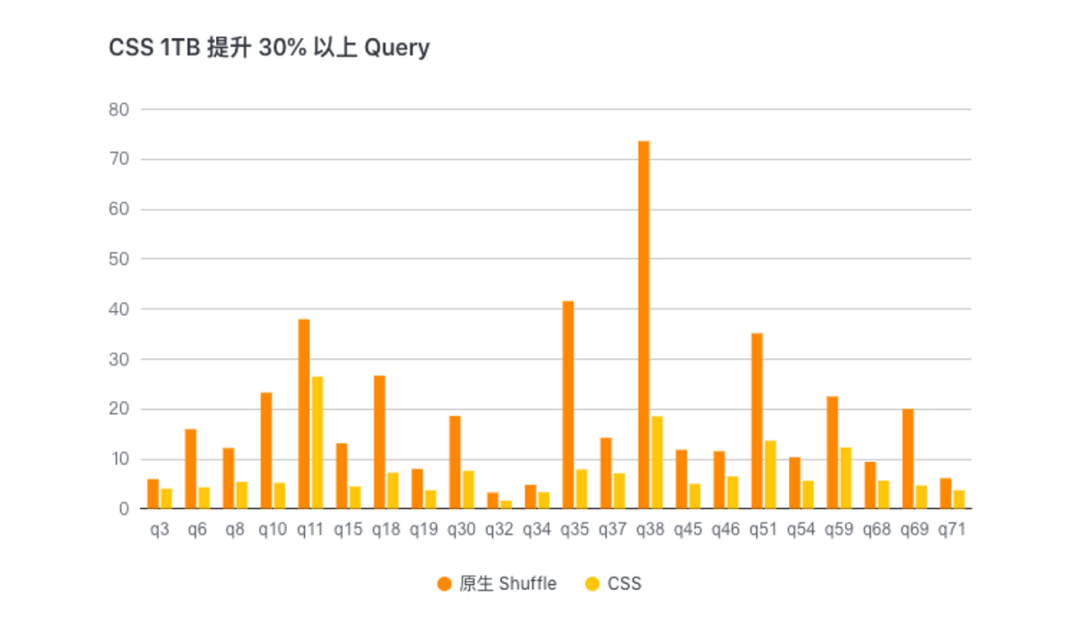
CSS 1TB 测试提升 30% 以上的 Query
CSS 目前开源了部分 Feature,还有一些 Feature & 优化后续会陆续开放:
- 支持 MapReduce/FlinkBatch 引擎;
- CSS 集群增加 ClusterManager 服务角色,管理 CSS Worker 的状态&负载信息,同时将当前 CSS Master 分配 CSS Worker 的功能提到 ClusterManager;
- 基于异构机器(如磁盘能力不同)/负载 等维度的 CSS Worker 分配策略。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK