

Hadoop的由来、Block切分、进程详解 - 伍点
source link: https://www.cnblogs.com/bfy0221/p/16614084.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Hadoop的由来、Block切分、进程详解
一、hadoop的由来
Google发布了三篇论文:
- GFS(Google File System)
- MapReduce(数据计算方法)
- BigTable:Hbase
Doug cutting 花费了两年的业余时间实现了前两篇论文,并重新命名为HDFS和MapReduce
Doug cutting看到他儿子在牙牙学语时,抱着黄色小象,亲昵的叫 hadoop,他灵光一闪,就把这技术命名为 Hadoop,而且还用了黄色小象作为标示 Logo,不过,事实上的小象瘦瘦长长,不像 Logo 上呈现的那么圆胖。“我儿子现在 17 岁了,所以就把小象给我了,有活动时就带着小象出席,没活动时,小象就丢在家里放袜子的抽屉里。” Doug Cutting 大笑着说。

Hadoop由三大开源发行版本:Apache、Cloudera(CDH)、Hortonworks(HDP)。Apache版本是最原始的版本。Cloudera在大型互联网企业中用的较多。Hotronworks文档较好。
2018年10月,均为开源平台的Cloudera与Hortonworks公司宣布他们以52亿美元的价格合并。两大开源大数据平台Cloudera与Hortonworks宣布合并,合并后的企业定位为企业数据云提供商,推出了ClouderaDataPlatform(CDP),可以跨AWS、Azure、Google等主要公有云架构进行数据管理。2020年6月,Cloudera发布CDP私有云,将本地部署环境无缝连接至公有云。
Hadoop Common:基础型功能
Hadoop Distributed File System (HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。负责存放数据
Hadoop YARN:作业调度和集群资源管理的框架。负责资源的调配
Hadoop MapReduce:基于 YARN 的系统,用于并行处理大型数据集。大数据的计算框架
二、分布式文件系统
1、FS File System
文件系统时极域硬盘之上的文件管理的工具
我们用户操作文件系统可以和硬盘进行解耦
2、DFS Distributed File System
分布式文件系统
将我们的数据存放在多台电脑上存储
分布式文件系统有很多,HDFS(Hadoop Distributed FileSyetem)是Hadoop自带的分布式文件系统
HDFS是mapreduce计算的基础
三、文件切分的思想
- 文件存放在一个磁盘上效率肯定是最低的,如果文件特别大可能会超出磁盘的存储范围
- 文件在磁盘中真是存储文件的方式是字节数组,数组可以进行拆分和组装,源文件不会收到影响
- 对字节数组进行拆分,按照数组的偏移量将数据连到一起。偏移量可以理解为下标。
四、Block块拆分
数据块block
- 是磁盘进行数据读写的最小单位,数据被切分后的一个整体称为一个block块
- 在Hadoop2之后默认一个block块的大小为128M,这是为了最小寻址化开销
- 同一个文件中,每个数据块的大小一致,除了最后一个节点
- HDFS中小于一个块大小的文件不会占据整个块的空间,也就是说,如果一个文件小于128M,它在HDFS中所占的真实存储空间与文件大小一致,也会占一个block块
为什么拆分的数据块要等大
- 数据计算的时候简化问题的复杂度,否则进行分布式算法设计的时候会因为数据量不一致很难设计
- 数据拉取的时间相对一致
- 通过偏移量就知道这个块的位置
- 相同文件分成的数据块大小应该相等
HDFS中为什么块不能设置太大也不能设置太小,为什么要设置成128M
- 如果块设置太大
- 从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时变得很慢
- mapreduce中的map任务通常一次只处理一个块的数据,如果块太大运行速度会很慢
- 在数据读写计算的时候,需要进行网络传输,如果block块过大导致网络传输时间增加,可能会出现程序卡顿/超时/无响应。任务执行过程中拉取其他节点的block或者失败重试的成本会过高
- namenode监管容易判断数据节点死亡。导致集群频繁产生/移除副本,占用cpu、网络、内存资源
- 如果块设置过小
- 文件块过小,寻址时间增大,导致程序一直在找block块的开始位置
- 存放大量小文件会导致namonode中占用大量内存来存储元数据,而namenode的物理内存是有限的
- 操作系统对目录中的小文件处理存在性能问题,比如同一个目录下文件数量操作100万,执行"fs -l "之类的命令会卡死;
- 会频繁的进行文件传输 ,严重占用cpu、网络资源
- 首先HDFS中平均寻址时间大概为10ms;
经过大量测试发现,寻址时间为传输时间的1%时,为最佳状态,所以最佳传输时间为:
10ms/0.01=1000s=1s
目前磁盘的传输速度普遍为100MB/s,最佳block大小计算:
100MB/s*1s=100MB
所以我们设置block大小为128MB
而在实际中,
磁盘传输速率为200MB/s时,一般设定block大小为256MB;
磁盘传输速率为400MB/s时,一般设定block大小为512MB。
- 只要有一个块丢失,整个数据文件损坏
- HDFS中文件一旦被存储,数据不允许修改,修改会影响偏移量,但是可以被追加(不推荐)追加设置需要手动打开
五、block块数据安全
- HDFS是直接对原始数据进行备份,这样可以保证恢复效率和读取效率
- 备份的数据不能放到一个节点上,使用数据的时候可以就近获取
- 备份的数量要小于等于从节点的数量
- 每个数据块默认有三个副本,相同副本不会存放在同一个节点上
- 副本的数量可以变更
六、block的管理效率
- 主节点
- NameNode:记录元数据
- Secondary NameNode:日志
- 从节点
- DataNode:实际存储数据的节点
七、NameNode(NN)详解
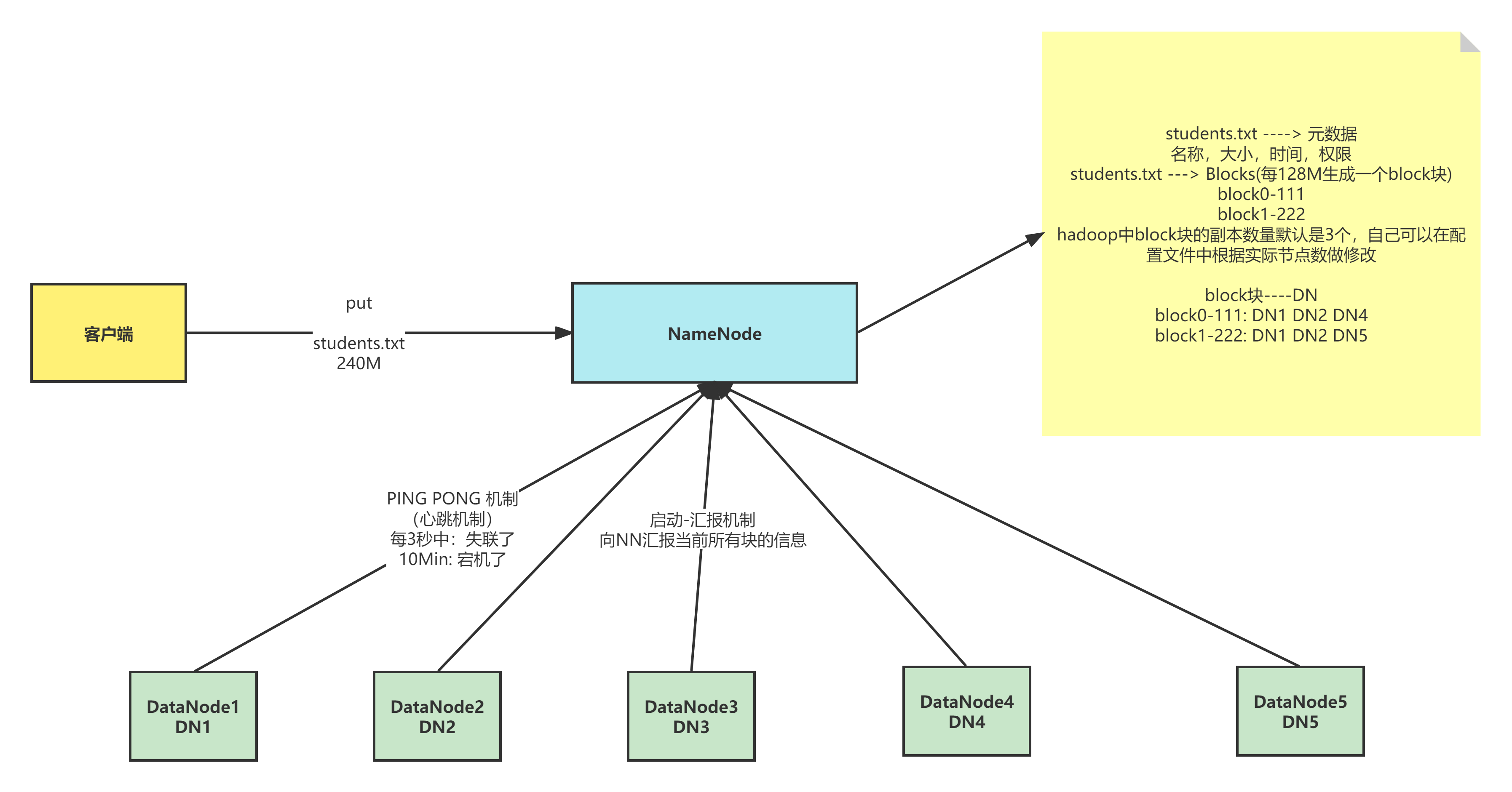
- 接收客户端的读写请求,因为namenode知道数据文件与datanode的对应关系
- 保存文件的时候会保存文件的元数据信息
- 文件的归属
- 文件的权限
- 文件的大小、时间
- Block信息,但是block信息不会持久化,需要每次开启集群的时候DN向NN报告
- 收集block的位置信息
- 系统启动
- NN关机的时候是不会保存Block块与DataNode的映射信息的
- DN启动的时候会自动将自己节点上的block块信息汇报给NN
- NN接收请求之后会重新生成映射关系 File-->NN Block-->DN
- 如果数据块的副本数小于设置数,那么NN会将这个副本拷贝到其他节点
- 集群运行中
- NN与DN保持心跳机制,每3秒钟发送一次
- 如果NN与DN3秒没有心跳,则认为DN出现异常,将不会让新的数据写入这个DN中,客户端访问的时候不提供异常DN节点地址
- 如果超过10分钟没有心跳,NN会将这个节点的数据转移到其他节点
- 系统启动
- 将所有的操作放到内存中执行
- 执行速度快
- NameNode不会和磁盘进行任何的数据交换
- 会出现两个问题:数据的持久化、断电数据丢失
八、DataNode(DN)
- 存放的是文件的数据信息,以及验证文件完整性的校验信息
- 数据存放在磁盘上
- 启动时:向NN汇报当前DN上block的信息 运行时:时刻与NN保持心跳机制
- 当客户端读取数据的时候,首先会去NN查询File与Block与DN的映射,然后客户端直接与DN建立连接,然后读取数据
九、NameNode的持久化方案SecondaryNameNode(SNN)
-
传统的持久化方式
- 日志方式
- 做任何操作之前先记录日志
- 在数据改变之前先记录对应的日志,当NN停止的时候
- 当我下次启动的时候,只需要重新按照以前的日志“重做一遍”即可
- 缺点:
- log日志文件的大小不可控,随着时间的发展,集群启动的时间会越来越长
- 有可能日志中存在大量的无效日志
- 优点:
- 绝对不会丢失数据
- 快照方式
- 我们可以将内存中的数据写出到硬盘上(序列化)
- 启动时还可以将硬盘上的数据写回到内存中(反序列化)
- 缺点:
- 关机时间过长
- 如果是异常关机,数据还在内存中,没法写入到硬盘
- 如果写出的频率过高,导致内存使用效率低
- 优点:
- 启动时间较短
- 日志方式
-
SNN的解决方案
-
- 让日志大小可控(每64M)
- 快照需要定时保存(每隔一小时)
- 日志加快照
-
-
当我们启动一个集群的时候,会产生4个文件 ..../name/current/
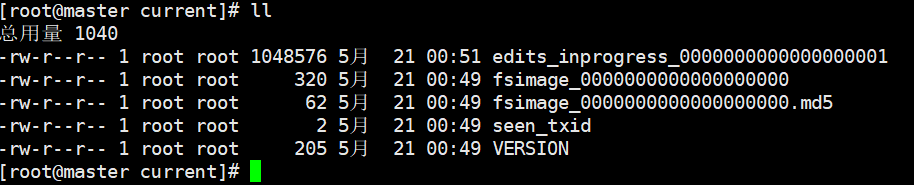
-
我们每次操作都会记录日志-->edits-inprogress- edits_00000001,随着时间的推移,日志文件会越来越大-当达到阈值的时候(64M或3600秒),会生成新的日志文件,edits_inprogress-000000001 -->edits_0000001,创建新的日志文件 edits_inprogress-0000000022。
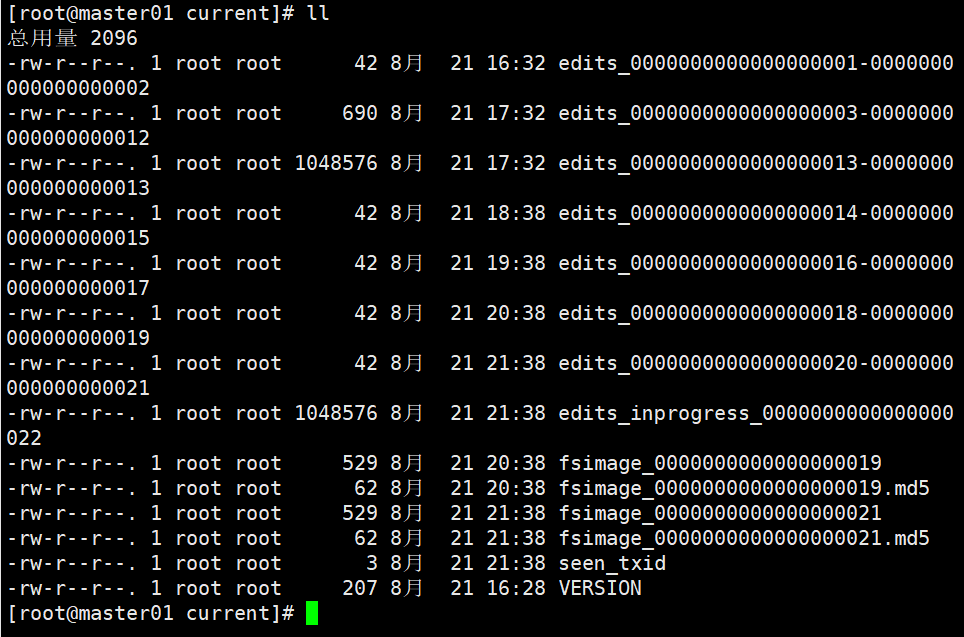
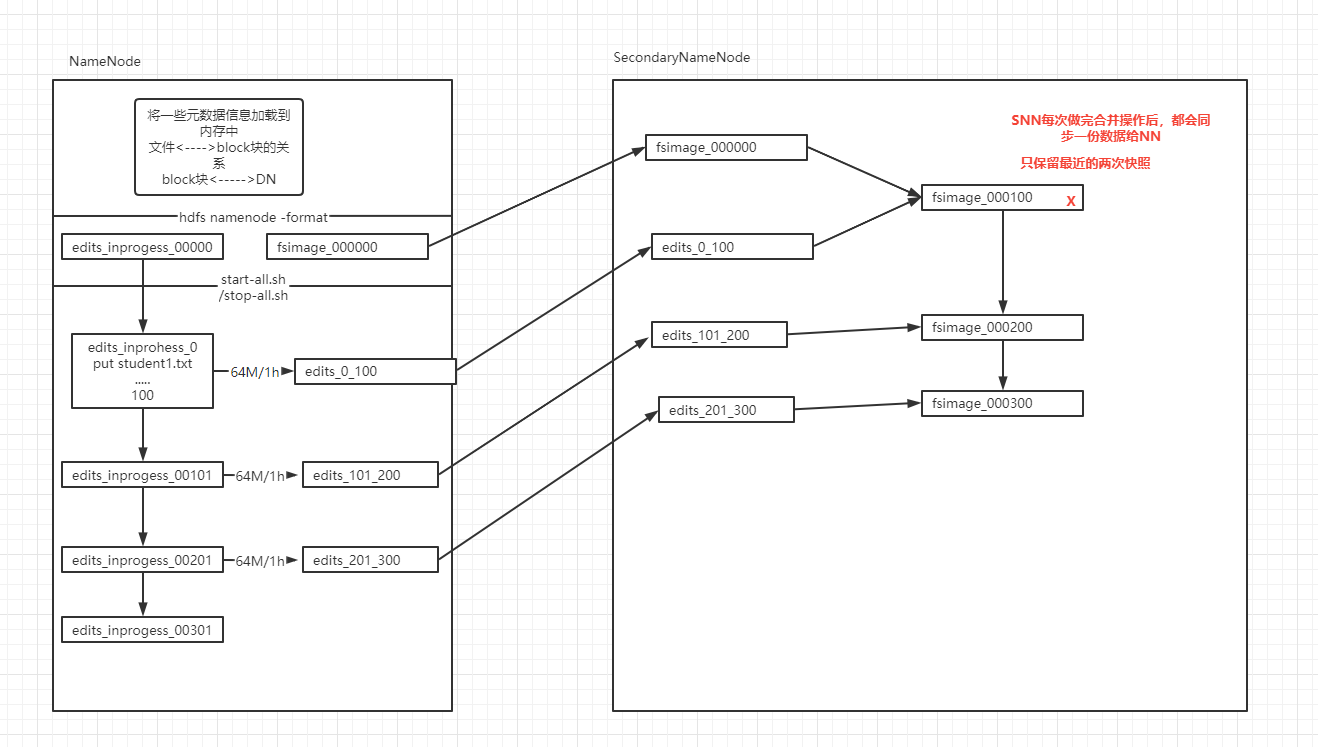
-
-
十、安全模式
安全模式是HDFS的一种工作状态,处于安全模式的状态下,只向客户端提供文件的只读视图,不接受对命名空间的修改,同时NameNode节点也不会进行数据块的复制或者删除。
NameNode启动时,首先将镜像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作,一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件和一个空的编辑日志。NameNode开始监听RPC和HTTP请求,此时NameNode处于安全模式,只接受客户端的读请求,目的是为了保护数据的安全。
a.启动 NameNode,NameNode 加载 fsimage 到内存,对内存数据执行 edits log 日 志中的事务操作。
b.文件系统元数据内存镜像加载完毕,进行 fsimage 和 edits log 日志的合并,并创 建新的 fsimage 文件和一个空的 edits log 日志文件。
c.NameNode 等待 DataNode 上传 block 列表信息,直到副本数满足最小副本条件。
d.当满足了最小副本条件,再过 30 秒,NameNode 就会退出安全模式。最小副本条件指 整个文件系统中有 99.9%的 block 达到了最小副本数(默认值是 1,可设置)
查看namenode是否处于安全模式
hdfs dfsadmin -safemode get
进入安全模式
hdfs dfsadmin -safemode enter
强制退出安全模式
hdfs dfsadmin -safemode leave
等待安全模式结束
hadoop dfsadmin -safemode wait
十一、机架感知
机架感知是为了保证副本在集群中的安全性,我们将block块的副本放在不同的节点上
第一个节点:
- 集群内部:
- 优先考虑和客户端相同的节点
- 集群外部
- 优先选择资源丰富且不繁忙的节点
第二个节点:选择与一个节点不同机架的其他节点
第三个节点:选择与第二个节点相同机架的不同节点
第N个节点:选择与前面节点不重复的其他节点。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK