

基于模板的中文命名实体识别数据增强 - 西西嘛呦
source link: https://www.cnblogs.com/xiximayou/p/16611936.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于模板的中文命名实体识别数据增强
本文将介绍一种基于模板的中文命名实体识别数据增强方法,自然语言处理中最常见的一个领域就是文本分类。文本分类是给定一段文本,模型需要输出该文本所属的类别。对文本分类进行数据增强较为简单的一种是对文本中的词进行同义词替换、随机删除、随机插入、打乱顺序等。命名实体识别不同于文本分类,但又和文本分类密切相关,因为实体识别是对每一个字或者词进行分类,我们要识别出的是一段字或词构成的短语,因此,上述文本分类中的数据增强可能会让实体进行切断而导致标签和实体不一致。这里,介绍一种基于模板得实体增强方法,能够解决上述得问题的同时,使得模型的性能进一步得到提升。
代码地址:https://github.com/taishan1994/pytorch_bert_bilstm_crf_ner
接下来以简历数据集为例。简历数据集由三个文件构成:train.char.bmes、dev.char.bmes、test.char.bmes。从文件名我们可以看到,其是由BMESO的标注方法标注的,例如:
高 B-NAME
勇 E-NAME
: O
男 O
, O
中 B-CONT
国 M-CONT
国 M-CONT
籍 E-CONT
, O
无 O
境 O
外 O
居 O
留 O
权 O
, O
我们将数据放置在data/cner/raw_data下,并在raw_data下新建一个process.py,主要是为了获得data/cner/mid_data下的数据。process.py代码如下:
import os
import re
import json
def preprocess(input_path, save_path, mode):
if not os.path.exists(save_path):
os.makedirs(save_path)
data_path = os.path.join(save_path, mode + ".json")
labels = set()
result = []
tmp = {}
tmp['id'] = 0
tmp['text'] = ''
tmp['labels'] = []
# =======先找出句子和句子中的所有实体和类型=======
with open(input_path,'r',encoding='utf-8') as fp:
lines = fp.readlines()
texts = []
entities = []
words = []
entity_tmp = []
entities_tmp = []
for line in lines:
line = line.strip().split(" ")
if len(line) == 2:
word = line[0]
label = line[1]
words.append(word)
if "B-" in label:
entity_tmp.append(word)
elif "M-" in label:
entity_tmp.append(word)
elif "E-" in label:
entity_tmp.append(word)
if ("".join(entity_tmp), label.split("-")[-1]) not in entities_tmp:
entities_tmp.append(("".join(entity_tmp), label.split("-")[-1]))
labels.add(label.split("-")[-1])
entity_tmp = []
if "S-" in label:
entity_tmp.append(word)
if ("".join(entity_tmp), label.split("-")[-1]) not in entities_tmp:
entities_tmp.append(("".join(entity_tmp), label.split("-")[-1]))
entity_tmp = []
labels.add(label.split("-")[-1])
else:
texts.append("".join(words))
entities.append(entities_tmp)
words = []
entities_tmp = []
# for text,entity in zip(texts, entities):
# print(text, entity)
# print(labels)
# ==========================================
# =======找出句子中实体的位置=======
i = 0
for text,entity in zip(texts, entities):
if entity:
ltmp = []
for ent,type in entity:
for span in re.finditer(ent, text):
start = span.start()
end = span.end()
ltmp.append((type, start, end, ent))
# print(ltmp)
ltmp = sorted(ltmp, key=lambda x:(x[1],x[2]))
tmp['id'] = i
tmp['text'] = text
for j in range(len(ltmp)):
tmp['labels'].append(["T{}".format(str(j)), ltmp[j][0], ltmp[j][1], ltmp[j][2], ltmp[j][3]])
else:
tmp['id'] = i
tmp['text'] = text
tmp['labels'] = []
result.append(tmp)
# print(i, text, entity, tmp)
tmp = {}
tmp['id'] = 0
tmp['text'] = ''
tmp['labels'] = []
i += 1
with open(data_path,'w', encoding='utf-8') as fp:
fp.write(json.dumps(result, ensure_ascii=False))
if mode == "train":
label_path = os.path.join(save_path, "labels.json")
with open(label_path, 'w', encoding='utf-8') as fp:
fp.write(json.dumps(list(labels), ensure_ascii=False))
preprocess("train.char.bmes", '../mid_data', "train")
preprocess("dev.char.bmes", '../mid_data', "dev")
preprocess("test.char.bmes", '../mid_data', "test")
labels_path = os.path.join('../mid_data/labels.json')
with open(labels_path, 'r') as fp:
labels = json.load(fp)
tmp_labels = []
tmp_labels.append('O')
for label in labels:
tmp_labels.append('B-' + label)
tmp_labels.append('I-' + label)
tmp_labels.append('E-' + label)
tmp_labels.append('S-' + label)
label2id = {}
for k,v in enumerate(tmp_labels):
label2id[v] = k
path = '../mid_data/'
if not os.path.exists(path):
os.makedirs(path)
with open(os.path.join(path, "nor_ent2id.json"),'w') as fp:
fp.write(json.dumps(label2id, ensure_ascii=False))
得到以下几个文件:train.json、test.json、dev.json、labels.json、nor_ent2id.json。其中,labels.json是实际的标签:
["PRO", "ORG", "CONT", "RACE", "NAME", "EDU", "LOC", "TITLE"]
nor_ent2id.json是每个字对应的标签:
{"O": 0, "B-PRO": 1, "I-PRO": 2, "E-PRO": 3, "S-PRO": 4, "B-ORG": 5, "I-ORG": 6, "E-ORG": 7, "S-ORG": 8, "B-CONT": 9, "I-CONT": 10, "E-CONT": 11, "S-CONT": 12, "B-RACE": 13, "I-RACE": 14, "E-RACE": 15, "S-RACE": 16, "B-NAME": 17, "I-NAME": 18, "E-NAME": 19, "S-NAME": 20, "B-EDU": 21, "I-EDU": 22, "E-EDU": 23, "S-EDU": 24, "B-LOC": 25, "I-LOC": 26, "E-LOC": 27, "S-LOC": 28, "B-TITLE": 29, "I-TITLE": 30, "E-TITLE": 31, "S-TITLE": 32}
train.json、dev.json、test.json是我们处理后得到的数据:
[
{
"id": 0,
"text": "常建良,男,",
"labels": [
[
"T0",
"NAME",
0,
3,
"常建良"
]
]
},
]
接下来,我们在data同级目录下新建一个data_augment文件夹,并在data_augment下新建一个aug.py用于编写数据增强代码。具体如下:
import copy
import glob
import json
import os
import random
import re
from pprint import pprint
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--data_name', type=str, default='c',
help='数据集名字')
parser.add_argument('--text_repeat', type=int, default=2,
help='增强的数目')
args = parser.parse_args()
data_dir = "../data/{}".format(args.data_name)
text_repeat = args.text_repeat
if not os.path.exists(data_dir):
raise Exception("请确认数据集是否存在")
train_file = os.path.join(data_dir, "mid_data/train.json")
labels_file = os.path.join(data_dir, "mid_data/labels.json")
output_dir = os.path.join(data_dir, "aug_data")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
def get_data():
# ["PRO", "ORG", "CONT", "RACE", "NAME", "EDU", "LOC", "TITLE"]
"""获取基本的数据"""
with open(train_file, "r", encoding="utf-8") as fp:
data = fp.read()
with open(labels_file, "r", encoding="utf-8") as fp:
labels = json.loads(fp.read())
entities = {k:[] for k in labels}
texts = []
data = json.loads(data)
for d in data:
text = d['text']
labels = d['labels']
for label in labels:
text = text.replace(label[4], "#;#{}#;#".format(label[1]))
entities[label[1]].append(label[4])
texts.append(text)
for k,v in entities.items():
with open(output_dir + "/" + k + ".txt", "w", encoding="utf-8") as fp:
fp.write("\n".join(list(set(v))))
with open(output_dir + "/texts.txt", 'w', encoding="utf-8") as fp:
fp.write("\n".join(texts))
def aug_by_template(text_repeat=2):
"""基于模板的增强
text_repeat:每条文本重复的次数
"""
with open(output_dir + "/texts.txt", 'r', encoding="utf-8") as fp:
texts = fp.read().strip().split('\n')
with open(labels_file, "r", encoding="utf-8") as fp:
labels = json.loads(fp.read())
entities = {}
for ent_txt in glob.glob(output_dir + "/*.txt"):
if "texts.txt" in ent_txt:
continue
with open(ent_txt, 'r', encoding="utf-8") as fp:
label = fp.read().strip().split("\n")
ent_txt = ent_txt.replace("\\", "/")
label_name = ent_txt.split("/")[-1].split(".")[0]
entities[label_name] = label
entities_copy = copy.deepcopy(entities)
with open(train_file, "r", encoding="utf-8") as fp:
ori_data = json.loads(fp.read())
res = []
text_id = ori_data[-1]['id'] + 1
for text in tqdm(texts, ncols=100):
text = text.split("#;#")
text_tmp = []
labels_tmp = []
for i in range(text_repeat):
ent_id = 0
for t in text:
if t == "":
continue
if t in entities:
# 不放回抽样,为了维持实体的多样性
if not entities[t]:
entities[t] = copy.deepcopy(entities_copy[t])
ent = random.choice(entities[t])
entities[t].remove(ent)
length = len("".join(text_tmp))
text_tmp.append(ent)
labels_tmp.append(("T{}".format(ent_id), t, length, length + len(ent), ent))
ent_id += 1
else:
text_tmp.append(t)
tmp = {
"id": text_id,
"text": "".join(text_tmp),
"labels": labels_tmp
}
text_id += 1
text_tmp = []
labels_tmp = []
res.append(tmp)
# 加上原始的
res = ori_data + res
with open(data_dir + "/mid_data/train_aug.json", "w", encoding="utf-8") as fp:
json.dump(res, fp, ensure_ascii=False)
if __name__ == '__main__':
# 1、第一步:获取基本数据
get_data()
# 2、第二步:进行模板类数据增强
aug_by_template(text_repeat=text_repeat)
下面进行说明。
- 1、首先我们要将文本中的每一个实体分别提取出来并存储在相应类别的文件夹中。同时,我们将每一个实体用#;#实体类型#;#进行代替,并将替换后的文本存储到texts.txt中,也就是我们得到data/cner/aug_data/以下文件:
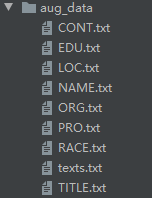
- 2、接着我们遍历texts.txt的每条文本,随机不放回从实体文件中提取实体替换文本中的类型。这里采取随机不放回是为了尽可能的让每一个实体都出现在文本中。然后将增强后的文本添加到原始的文本集中。
- 3、运行指令:
python aug.py --data_name "cner" --text_repeat 2
其中data_name是数据集的名称,与data下的数据集名称保持一致。text_repeat是每一条文本进行增强的次数。最后会在data/cner/mid_data下生成一个train_aug.json文件。
- 4、在preprocess.py中,我们定义好数据集和文本最大长度,运行后得到data/cner/final_data下的train.pkl、dev.pkl、test.pkl。
- 5、使用以下指令运行main.py进行命名实体识别训练、验证、测试和预测。
!python main.py \
--bert_dir="../model_hub/chinese-bert-wwm-ext/" \
--data_dir="./data/cner/" \
--data_name='cner' \
--model_name='bert' \
--log_dir="./logs/" \
--output_dir="./checkpoints/" \
--num_tags=33 \
--seed=123 \
--gpu_ids="0" \
--max_seq_len=150 \
--lr=3e-5 \
--crf_lr=3e-2 \
--other_lr=3e-4 \
--train_batch_size=32 \
--train_epochs=3 \
--eval_batch_size=32 \
--max_grad_norm=1 \
--warmup_proportion=0.1 \
--adam_epsilon=1e-8 \
--weight_decay=0.01 \
--lstm_hidden=128 \
--num_layers=1 \
--use_lstm='False' \
--use_crf='True' \
--dropout_prob=0.3 \
--dropout=0.3 \
| 评价指标:F1 | PRO | ORG | CONT | RACE | NAME | EDU | LOC | TITLE | F1 |
|---|---|---|---|---|---|---|---|---|---|
| baseline | 0.90 | 0.92 | 1.00 | 0.93 | 0.99 | 0.96 | 1.00 | 0.91 | 0.9244 |
| baseline+数据增强 | 0.92 | 0.93 | 1.00 | 0.97 | 1.00 | 0.97 | 1.00 | 0.91 | 0.9293 |
在简历数据集上还是有一定的效果的。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK