

《软件研发效能提升之美》书评
source link: https://zhangferry.com/2022/08/21/devops_quailty/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


这本书看下来的整体感受是对研发效能涉及的各个层面有了一个整体认识,可以搭建一个大概全景图。研发效能整体可以分为三个方面:组织效能、用于提效的研发工具、DevOps,DevOps 是前两者的串联。
还有一点比较大的收获是,书中讲到很多研发效能相关的工具。工具是提升效能最直接的手段,或自研或借鉴业内的成熟方案,它对效能提升带来的影响是最直接的。书中是基于一个后端视角来介绍这些工具的,但这些工具背后的思路同样可以迁移至前端、移动端领域。
软件研发效能概论
什么是研发效能:在保证质量的前提下,尽可能高效地持续交付价值。「顺畅、高质量地持续交付有效价值的闭环」首先效能提升是没有银弹的,但效能体系的建设却有着一套惯用的思路。本文会对整个效能体系需要面对的问题,以及对应的解决方案有一个全面的介绍。
研发效能的第一性原理:顺畅、高质量的持续交付有效价值的闭环。
- 顺畅:价值的流动过程必须顺畅,没有阻碍
- 高质量:如果质量不行,那么流动越快,死的也越快
- 持续:不能时断时续,小步快跑才是正道,不要憋大招
- 有效价值:这是从需求层面来说的,你的交付物是不是真正解决了用户的本质问题。比如「女生减肥不是本质问题,女生爱美才是」
- 闭环:强调快速反馈的重要性
由这些概念,我们引出了持续开发,持续集成,持续测试,持续交付和持续运维,它们是研发效能落地的必要实践。与此同时,我们还需要从流动速度、长期质量、客户价值及数据驱动四个维度来对研发效能进行有效度量。
软件质量和效能密切相关,效能的提升能够将软件研发中的风险更快、更及时地暴露出来,同时减轻人脑负担,反过来又能提升质量本身。
研发效能进阶解读
霍桑效应(Hawthorne Effect)起源于1924年至1933年间的一系列实验研究,霍桑实验最初的研究是探讨一系列控制条件(薪水、车间照明度、湿度、休息间隔等)对员工工作表现的影响。研究人员在研究过程中意外发现,各种实验处理对生产效率都有促进作用,甚至当控制条件回归初始状态时,促进作用仍然存在。
那这是怎么回事呢?后来实验者给出的解释是:实验对象对正在进行的实验本身产生了正向反应,员工意识到自己正在被测试,不自觉效率就提高了。这个现象被称为「霍桑效应」。
在实际工作中即便不进行任何策略改进,仅仅是定期通晒一下各团队的需求交付吞吐量的数据,也能起到一定的正面促进作用。这就是典型的霍桑效应的体现,当人们意识到自己正在被关注时,会不自觉地去改变自己的某种行为。团队知道自己正在被统计需求交付吞吐量数据,于是会更重视这方面的工作,从而促进了需求交付效率的提升。
霍桑效应还有个叫法是「宣泄效应」,在美国有一个霍桑工厂,虽然福利待遇不错,但是员工还是有很多抱怨,因而影响了生产。为此,著名心理学家梅奥在该厂组织开展了一系列实验课题,发现通过与员工谈话,让员工发泄出自己的不满,能使员工干劲倍增,大幅度提高生产效率。
这里带给我们的启示是:渴望尊重和欣赏,是人性的需求之一。适度的关注和赞美能够产生强烈的心理暗示,继而带来效能的提升。
摩尔定律与反摩尔定律
摩尔定律我们都比较清楚了,每18个月集成电路上的电路数翻一倍,微处理的性能每18个月提高一倍,价格下降一半,它预示了信息技术的进步速度。反摩尔定律由Google 前CEO埃里克施密特提出,为:一个IT公司今天要想和18个月前卖掉同样多同样质量的产品,那么它的营业额就会下降一半。正因为技术的快速发展,它所带来的量变潜力会很快被挖掘光,所以IT公司必须不断向前发展,发展不仅仅是为了扩张,还是为了保住手中原有的市场。这多少也能解释,互联网公司的压力来源和扩张原因。
反摩尔定律告诉我们越迟交付的产品价值越低,由此科技行业的工作模式由传统的瀑布流转向敏捷开发,以尽快将有效且高质量的产品交付,来追赶摩尔定律的速度抢占市场先机。
不容忽视的沟通成本
《人月神话》中有个著名的推论「向进度落后的仙姑中增加人手,只会促使进度更加落后」。这里主要考虑的是新加入员工总是需要老员工的指导,这期间会产生沟通成本,增加人手越多沟通成本越大,同时老员工的工作也会被滞后。
沟通是一项隐形成本,它容易被忽略却影响巨大。书中有一些建议:
- 相关会议尽量聚集一处,如果必须远程,则优先采用视频会议的模式
- 沟通交流中避免使用领域特定的术语,降低沟通理解的成本
- 有重要需求或工作任务罗列时,优先使用邮件
- 不讲空话,不讲正确的废话,不罗列大量没有价值的堆砌性文字。
同时合理组织有效的文档,代码里必要性的注释都能帮助降低沟通成本
项目管理中的提效手段
可以先看下敏捷宣言,这是敏捷方法所倡导的价值观:
个体和互动 高于 流程和工具 > > 工作的软件 高于 详尽的文档 > > 客户合作 高于 合同谈判 > > 响应变化 高于 遵循计划
敏捷的应用还需要考虑实际的工作场景,不一定完全遵循,但其中有两点内容可以重视一下,一个是个体和团队沟通非常重要,因为项目是人来完成的,不要掉入只关注工作方式而忽视员工的感受。另一个是响应变化非常重要,每次都遵循计划这是非常理想的状态,我们应该接受变化,允许计划上有一定的灵活性。
建立度量体系:无法度量就无法改进
软件研发的效能不太好度量的,因为整个开发流程会有很多不可见因素,人的影响也比较大。既然无法通过单一指标去度量研发效能,那尝试多个指标去衡量产出会是一个相对合适的方法。研发效能可以有五项度量指标。
质量指标
质量应该是最优先考虑的,按照时间角度划分,它可以有过程质量、交付质量。过程质量关注的是缺陷、性能和安全问题。交付质量关注的是发布之后的稳定性等。有这些指标可以设立:
- 千行代码缺陷率
- 万行代码线上事故数
- 缺陷燃尽图/缺陷存量
- 安全漏洞发现数
- 生产可用性时长/宕机时长
- 生产发布回滚率
交付吞吐指标
质量之后就需要考虑交付速度和交付效率了,有这些指标可以关注:
- 回归测试执行时长
- 缺陷修复时长
- 需求周期时间
- 生产周期时间
- 需求平均交付周期/需求吞吐率
产出指标
用于衡量研发工作中的结果产出。
- 人均提交代码行数
- 人均关闭需求数
- 人均关闭缺陷数
成本指标
随着业务量的逐渐增大,成本就需要控制了,成本度量主要体现在人和物上:
- 人均服务器/实例使用数
- 服务器资源使用率
- 依赖第三方资源费用
业务价值指标
所有的技术投入都应该体现在业务价值上,准确度量业务价值用于衡量技术团队是否完整地交付了正确的产品。
- 静推荐值(NPS),其反应的是口碑
- 用户价值产出量
- 功能采纳率
- 验收通过率
把上面的指标进行汇总,构建一个具有普适性的,能够启动引导作用的度量体系也是研发效能需要做的事情。
度量体系可以分这三层:
- 基础能力层:完善基础设施,通过对人和工具的度量,促进研发能力的增强
- 产品交付层:以流动效率为核心,关注过程指标,致力于效率、产出和成本的平衡
- 业务价值层:以业务指标为核心,交付准确、优质的产品,达到预期的业务结果
度量的作用并非完美,在经济学中有一个定律叫「古德哈特定律」:当决策者试图以一个事物的客观指标作为指针来实施政策时,这一指标就再也不能有效测量事物了,因为这很容易触发大家过于追求指标而导致一些「作弊」行为。所以在研发中的度量体系里要避免对指标的依赖,或者通过单一指标去衡量。
善用可视化
数据有了,度量体系有了,还要选用合适的可视化工具去消费。可视化的方式有饼图、折线图、条状图、散点图、气泡图等,选用哪种方式更利于数据呈现,需要结合指标需求。其中项目管理中的任务看板、表现任务周期和时间维度的甘特图、燃尽图等都是比较好的可视化方式。
依赖解耦,提升交付速度
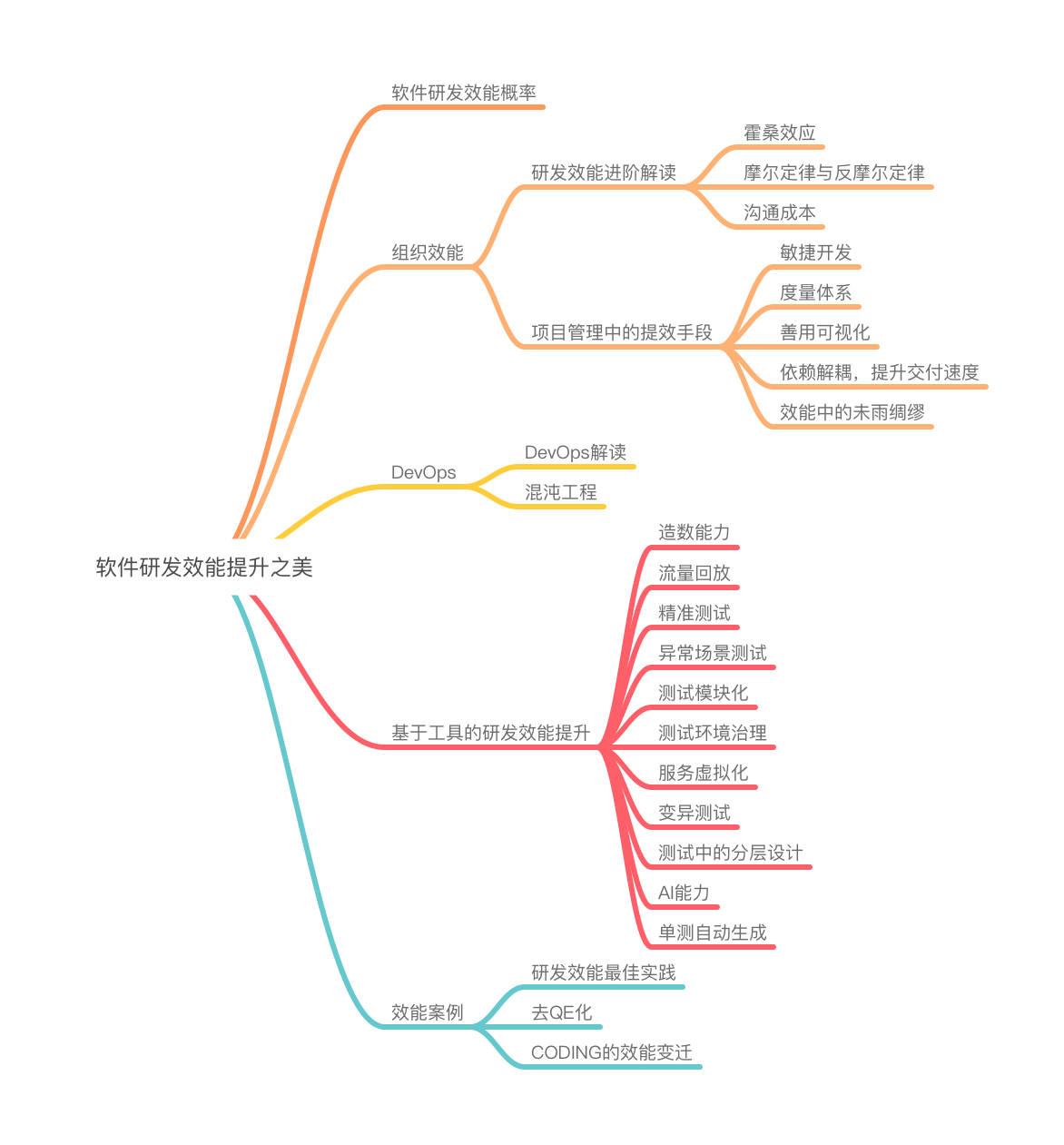
传统的软件项目研发生命周期是这样的:
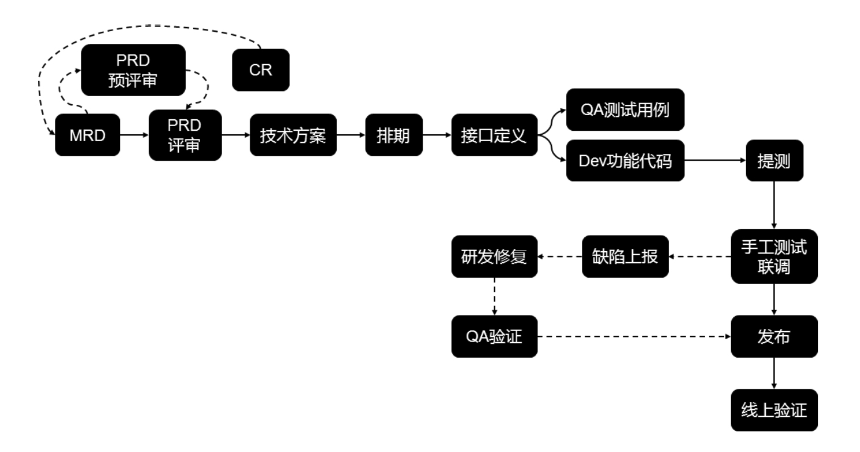
为了提高交付速度就需要解除前置依赖,比如测试流程,测试人员依赖开发人员的代码提交,如果解除依赖,由研发人员提前完成回归测试,确保没问题后再提测,这就是「回归前置」的概念。初次之后还有一些手段:
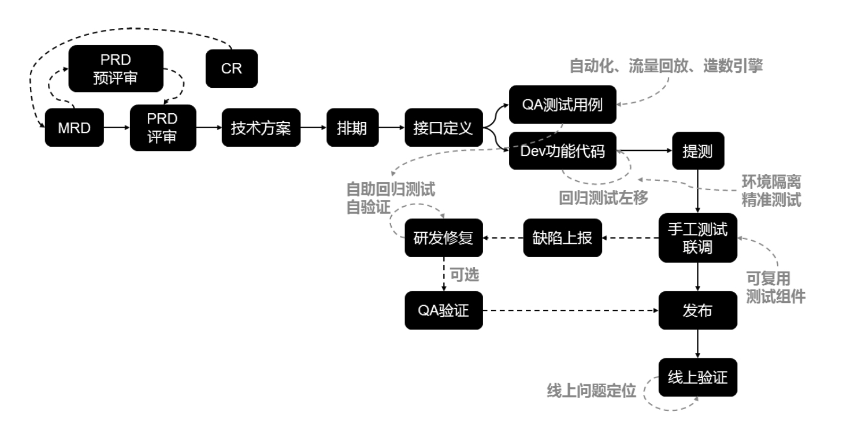
效能中的未雨绸缪
未雨绸缪就为不确定的未来寻求最佳保障,我们有这些方式可以做。
- 提前把风险暴露出来。这里可以通过前面引入的度量体系提前预测,比如前置时间过长,任务量挤压等。
- 防御性管理。编程人员都是乐观主义者,但软件研发中最靠不住的就是人。防御性思维有悖人性,但很有必要。比如Mock等方式,模拟一些边界条件测试程序稳定性。
- Plan B。假设出问题了,我会有什么应对措施,对于高危问题或已经暴露风险的问题,优先考虑制定Plan B。
DevOps 落地
DevOps 解读
DevOps 是 Development和 Operations 的组合,即开发和运维,再加上保证质量的测试,就构成了完整的 DevOps。通常 DevOps 会用下图表示:
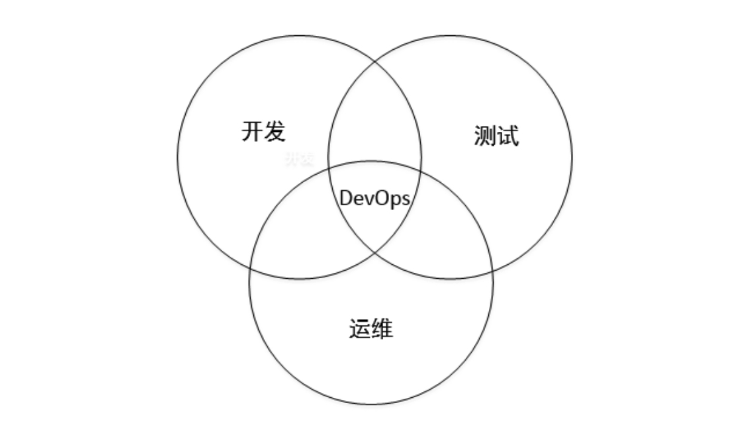
DevOps 要解决的问题主要有两个:
1、开发流程中原本的三方是各自独立且顺序依赖的。这样效率会很低,DevOps 将开发流程中原本独立的三方进行聚合,这也是为什么它的结构是一个重叠的环形结构。
2、传统的开发模式更新迭代比较慢。DevOps 接收敏捷开发中快速迭代思想,将各个开发环节都设计成自动化、可持续的流程。
DevOps 不是具体的开发工具,而是一种软件研发管理模式和思想,是一种文化实践,所有在保证质量的前提下提升效能的方法都属于 DevOps 的范畴。围绕这个理念催生出了很多开发工具和技术实践。
根据业界主流观点,DevOps 的生命周期可以化为这 7 个阶段:持续开发、持续集成、持续测试、持续监控、持续反馈、持续部署和持续运营。持续开发对应于编码工作,这个阶段需要用到代码仓库、版本控制工具、包管理工具等。持续集成是频繁的提交代码、编译代码、执行单测等,尽可能早的发现问题。持续测试是保证代码的每次提交都能够被及时验证。持续部署是指频繁的把构建出的产品发布到测试环境、生产环境的流程,以尽早接受检验。CI/CD 对应的是持续集成和持续部署,它是 DevOps 生命周期里最重要也是最基本的两个阶段,也可以说它们是 DevOps 概念的实践方式。
DevOps 的 7 个阶段都用到了「持续」一词,为了实现持续,需要串联开发中的各项任务,由此引出了流水线的概念。流水线是讲究顺序的,任何一个节点出错都会导致任务的失败,这可以加快了周转速度,也利于尽早暴露问题。像是 Jenkins、GitLab、Github 都为 CI/CD 提供了便捷的流水线配置方案。
DevOps 还常会跟容器技术同时出现,无容积化流程通常是这样的:
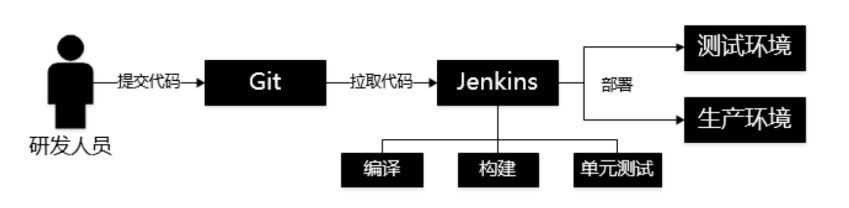
任务量小时这样没问题,但当面对大规模的提交时多场景的提交时,机器的执行效率就显得尤为重要。除了增加机器外,还可以利用容积化技术最大化机器的利用效率。Kubernetes 是用于优化容积化流程的技术方案,它可以提供容积化负载均衡、弹性伸缩等服务。
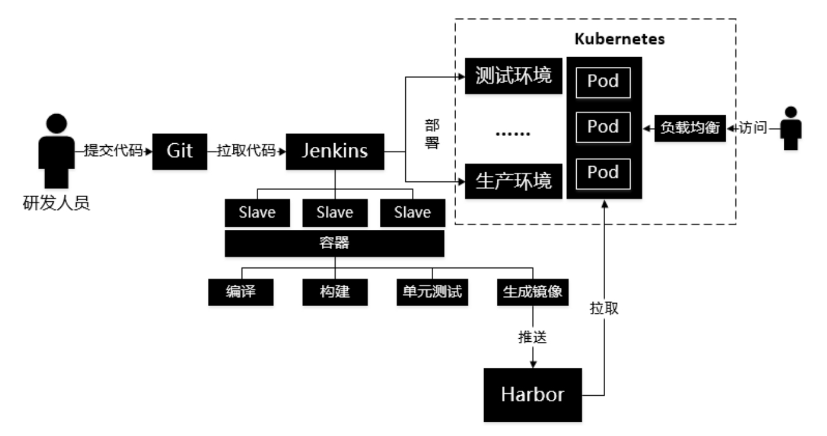
DevOps 理念的发展又推动了其他开发环节的进化,并演化出了这些开发实践。
- DevSecOps:Sec 表示 Secure,就是将安全防护与 DevOps 结合起来。需要监控 DevOps 各个阶段的安全问题,通常会通过扫描代码、交互式安全扫描、模拟攻击等方式来保证安全性。
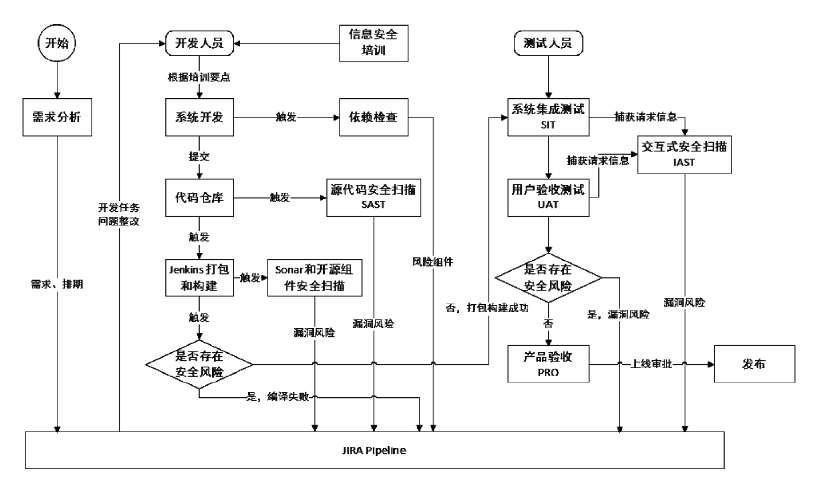
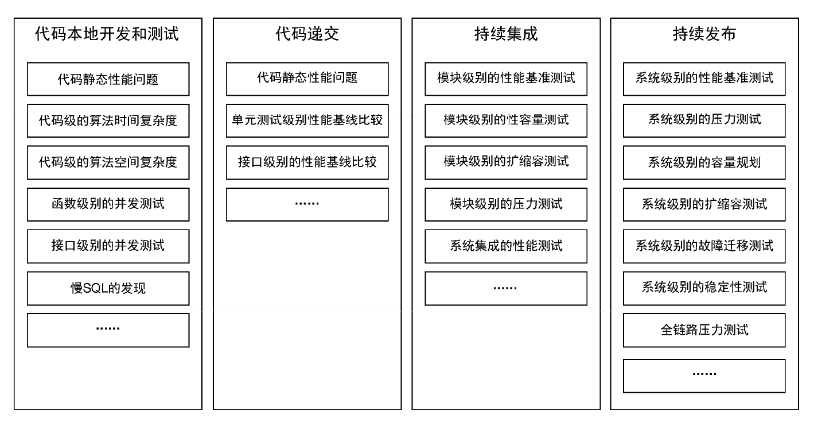
- DevPerfOps:Perf 表示 Performance,就是将性能保障与 DevOps 结合起来。它需要监控各个阶段的性能指标,开发阶段的技术方案有:代码静态性能问题、算法时间复杂度、接口级并发测试、性能基线比较等。持续集成阶段有模块级扩缩容测试、压力测试等。持续发布有系统级别的性能基准测试、故障迁移测试、全链路压力测试等。
- BizDevOps:Biz 表示 Business,就是将业务与 DevOps 结合起来。BizDevOps 的概念是将不写代码的业务团队,像是产品和运行也参与进来。它要解决的问题源于三个不等式:局部效率不等于高效交付,高效交付不等于持续高效,高效交付不等于业务成功。为了起到真正助力业务的目标,需要落地产品导向的交付,建设标准化基础设施,不断积累技术资产,同时还需要与业务之间建立快速的反馈闭环。
- AIOps:AI 表示 Artificial Intelligence,就是在原有 DevOps 的各个阶段都融入 AI 能力。通过不断的数据采集和分析,根据算法自动的下发或变更执行规则。更进一步,通过自动化测试,不断的分析测试结果,还可以用于异常检测、瓶颈分析、资源优化、容量规划、性能优化、故障预测甚至于故障自愈。
随着软件系统的发展,其复杂度也在不断上升,质量保障的难度有随之增加,单靠穷举测试越来越不可能实现了。混沌工程提供了一种新思路,它是面向失败设计,它一开始就接受系统一定存在缺陷和发生故障的混沌态,通过一系列演练频繁暴露这些问题,倒逼质量内建和防御意识提升。
Chaos Monkey
故障一定会发生,且我们无法阻止,那应对的最好办法就是「经常故障」。比如 SSD 年故障率约为1.5%,如果机房有超过 100 份 SSD,那么从概率角度看,一年一定会出现损坏的情况,其他硬件同理。Chaos Monkey 是混沌工程中著名的实验方法,想象一支痴迷捣乱的猴子军团在机房乱窜,随机地关闭服务节点,以验证系统的健壮性和弹性。此外还有 Latency Monkey 引入延时来模拟服务降级,Chaos Gorilla,模拟整个可用区故障等等。
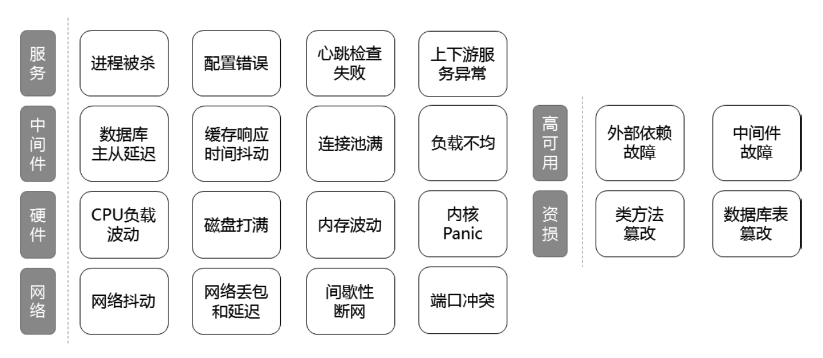
混沌工程的实施要点
- 在生产环境实施。这样更贴近实际用户,生产环境拥有最完备的监控、告警、容灾和故障转移手段,也最能反应系统真实的健壮性。
- 最小化爆炸半径。破坏是用于暴露隐患的,需要控制影响范围,破坏时间也需要控制。
- 攻防演练。这个有点像是军事演习,技术团队分为攻击方和防御方,扮演蓝军红军,以挖掘潜在问题。
混沌领域有一些现成的工具,像是ChaosBlade,可以非常方便的模拟一些混沌场景,像是模拟CPU占用率达到100%,模拟网络丢包故障等。
基于工具的研发效能提升
研发效能的提升很多时候都需要借助于一些便利的自动化工具用于提高效率,下面介绍一些比较重要的效能工具。
数据是研发过程中最基础的元素,对于一些特殊的场景,比如退单服务,依赖订单数据,如果订单接口出了问题我们会无法完成测试;为了保证测试覆盖率,针对某营销场景需要准备多种类型的消费券,但测试环境只有一部分。面对这些测试需要,我们需要提供一套完备的造数能力,以一套外卖系统为例:
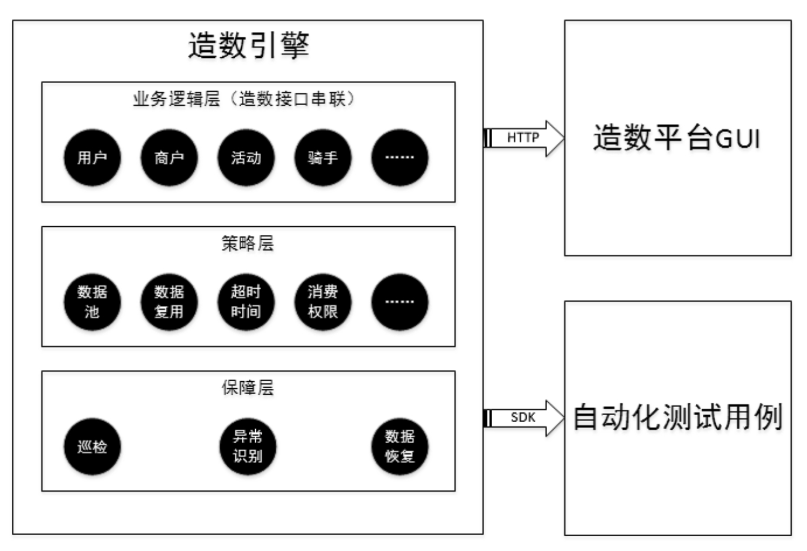
造数中的数据集除了特殊生成还可以抓取线上的一部分数据作为数据集,但需要注意对一些敏感信息,像是姓名、手机号等做一些脱敏处理。
功能回归是软件系统中一个老生常谈的话题,但是传统的回归测试成本非常高,根据业务复杂度经常需要花几个小时甚至几天不等。业内对于回归测试的效能提升大致有两个方向,第一是精确找到需要回归的范围,尽可能缩小回归测试规模,即精准测试;第二是通过自动生成不相互依赖的回归测试用例,通过对比的方式校验正确性,比较著名的就是流量回放技术。流量回放是将线上流量录制下来,在开发或测试环境进行回放,检验系统功能是否正常。
以 GoReplay为例,整体分为录制和回放两大部分,录制在线上进行,通过监听的方式获取流量,将其输出至服务器或保存为文件,GoReplay 本身不会拦截任何请求,只会复制请求,在这一过程中可以对请求进行过滤和加工。接下来,通过转发的方式,将这些加工好的流量回放值测试环境,流程如下图所示:
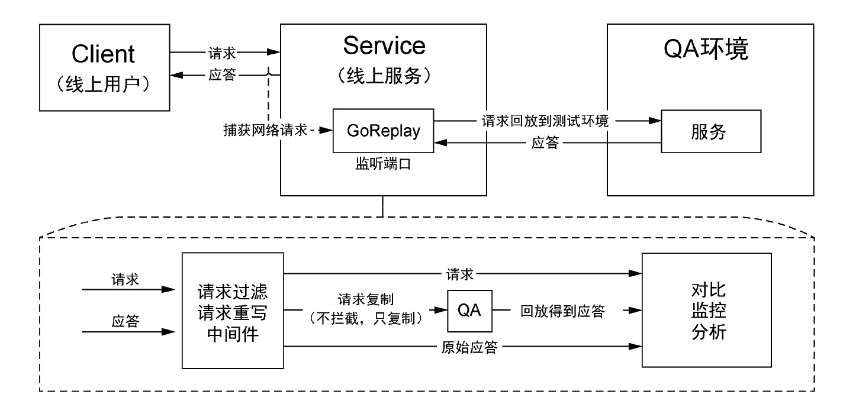
其中对比监控分析是又一关键环节,其将同一请求在录制和回放时获得的响应内容逐字段校对,如果相同则通过测试,反之则报错。但实际场景中这种方式也会不准,因为有些字段可能是时间戳或者随机数之类的信息,本身就会存在差异,这些属于噪音。
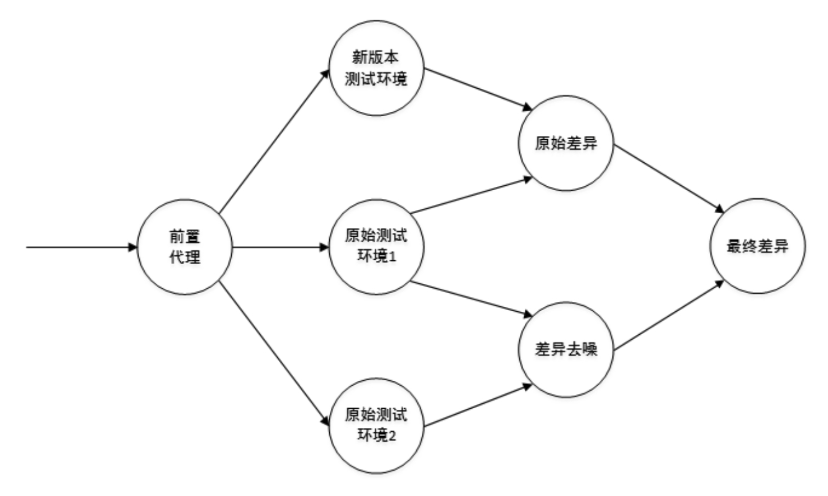
关于噪音的去除可以参考 Diffy 的处理方式,将流量会放至两个同样的原始环境中,针对同样的请求获得响应内容的对比,如果某些字段不一致,就可以将其视为噪音,噪音内容加入白名单。之后在新环境中回放相同请求得出与原始环境的差异,再去除白名单内容的值就是最终的有效差异。如果存在有效差异,则大概率是有异常存在。
高级流量回放
传统的流量回放其实也有硬伤,那就是对环境和数据依赖较高,只支持读请求,使用场景有限。有一种高级流量回放技术,就是阿里开源的JVM-Sandbox生态下的jvm-sandbox-repeater,它利用字节码动态增强技术,不仅能够获取每次请求中涉及的各个环节入口出口信息,还可以在回放时适时进行干预,达到mock的效果,以支持写请求的回放。
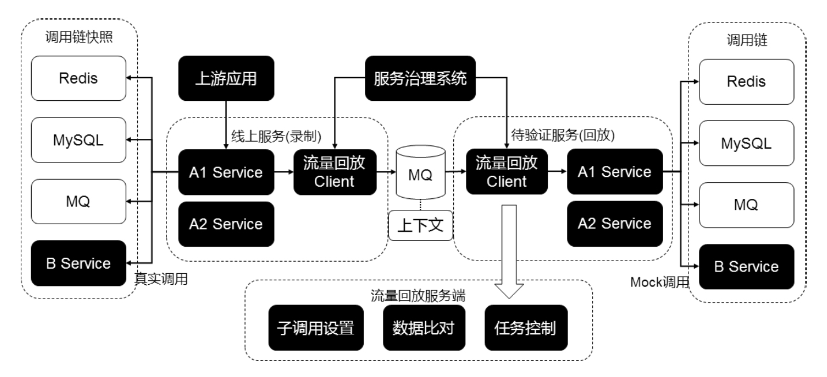
图片左侧表示录制流程,jvm-sandbox-repeater 作为代理attach到目标服务进程中,它可以识别调用链路中的数据库、操作Redis、写数据至消息队列及其他调用服务。图片右侧表示回放流程,它将上一步保存的上下文按照顺序进行回放,以数据库为例其回放内容会查询结果而非实际调用数据库,所以这期间也支持对中间链路的修改。最后将结果进行对比,输出报告。
研发效能中关于优化测试环节耗时的问题,有两个方向,一种是并行执行测试用例以提高执行速度,一种是只运行需要运行的测试用例。因为随着回归测试用例的不断扩大,并行速度显然很难一直提升下去,按需测试则显得更加科学有效。
以下是三种常用的测试模式:
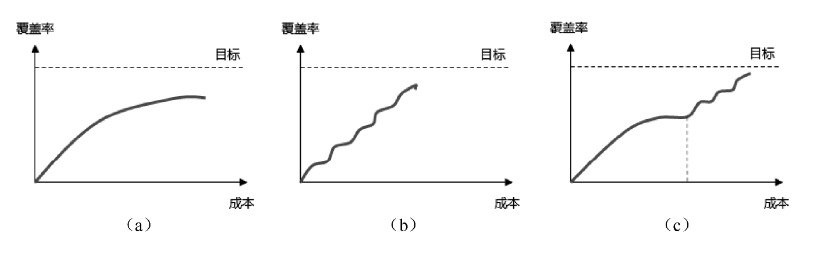
a:黑盒测试。前期覆盖率会迅速增长,但是“最后一公里”却很难达到。
b:白盒测试。用例数和覆盖率是正比关系,但白盒测试需要清楚代码逻辑,显然成本较高。
c:穿线测试。前期采用黑盒测试,当覆盖率达到70%水位时,采用白盒测试补充用例。
穿线测试相对科学,但它有个前提是我们需要知道黑盒测试覆盖了哪些代码,然后才能推断出未覆盖的代码,通过白盒测试进行补充。穿线测试的理论推广就是精准测试了,就是通过将测试用例和代码进行关联,在代码变更时能够识别出需要执行的测试用例,达到「改哪里,测哪里」的效果。
以下是一个精准测试的设计架构:
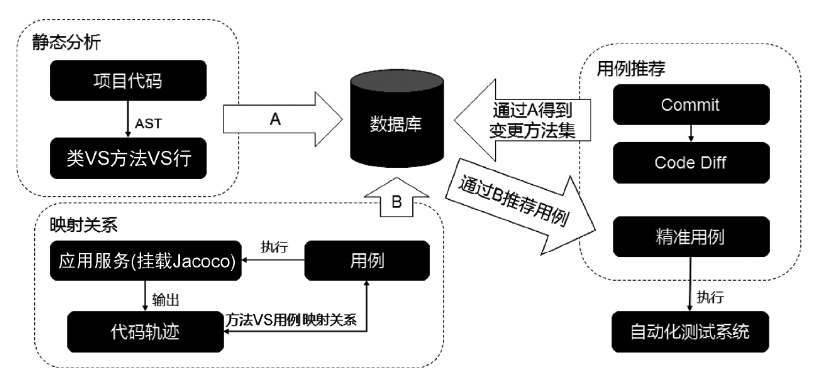
- 静态分析。基于代码的AST分析出这是哪个类、什么方法及对应的行号,然后将这些信息落库。
- 映射关系。将代码与用例之间建立映射关系,用例需要执行,所以需要使用 Jacoco(处理Java代码覆盖率的库) 对目标代码进行插桩。输出的代码执行数据与用例关联后也需要入库。
- 用例推荐。在提交MR或者回归测试阶段,通过代码 Diff 去数据库中找到关联用例,然后执行这部分用例。
精准测试通过精确的覆盖率信息反馈,提供了明确的质量评估信息,这对质量本身还是对质量提效都非常有帮助。
异常场景测试
异常场景是模拟一些程序异常的情况,比如我们通常认为消息队列是不可靠的,为了应对丢失情况,需要有相应的补偿机制。像是电商交易的下单链路中,会涉及扣减资源,那测试时就需要验证扣减失败触发的补偿机制,这对常规测试来说是一个挑战。要做到高效的异常测试场景,有这些关键点:
- 能够有办法制造出所需的异常场景
- 能够以较低成本制造出异常场景
- 异常场景不能阻塞正常功能测试
- 异常场景的测试自动化实施
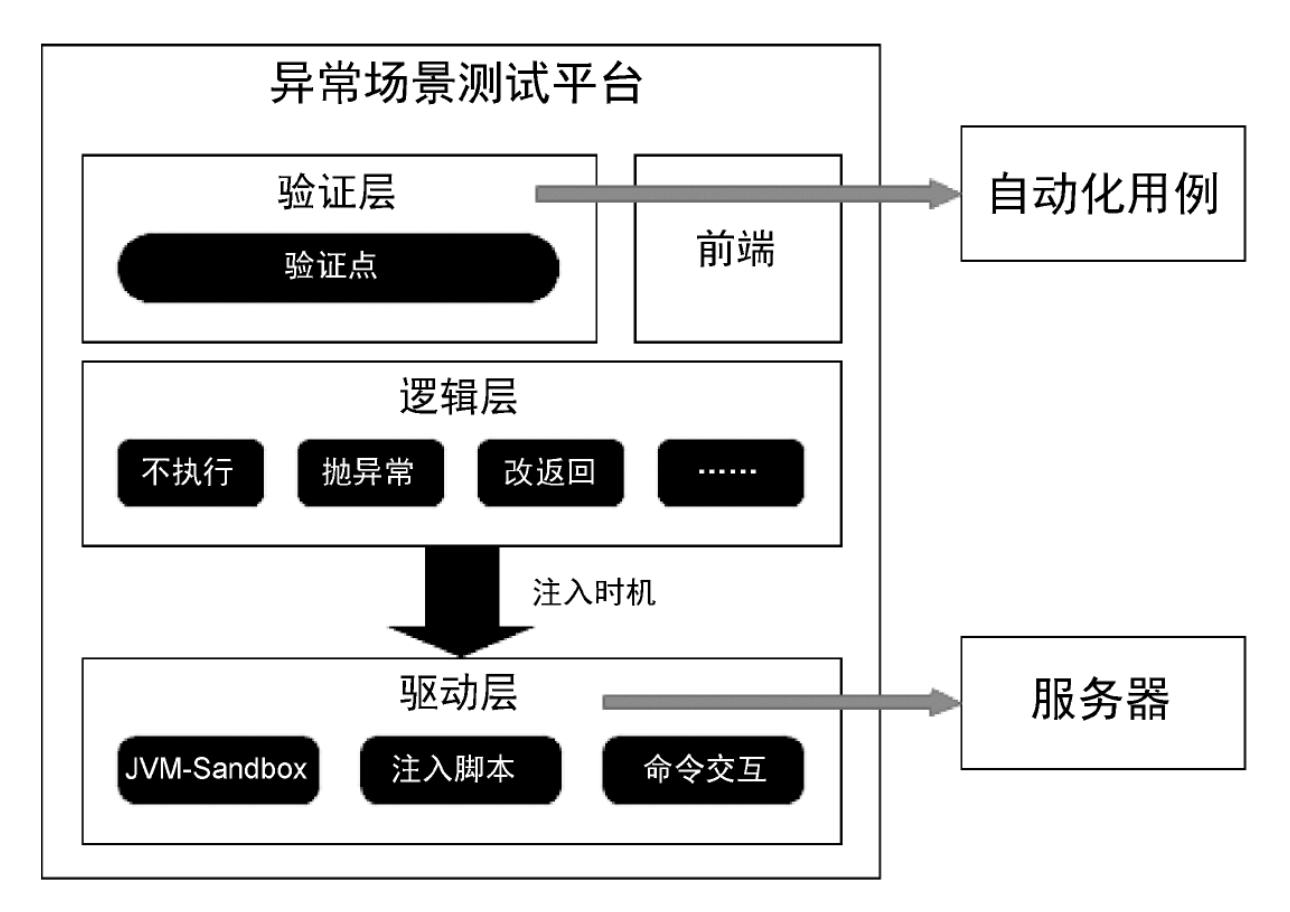
JVM-Sandbox 提供了便捷的异常场景接入能力,具体实现需要梳理场景、安装工具、注入脚本等,一种更好的方案是将这些功能封装做成一个异常场景测试平台。该平台可以分为驱动层、逻辑层、验证层等三层,多数情况用户只要在验证层填入需要验证的节点就可以完成测试任务,大大降低使用门槛。整个平台大概的架构如下所示:
测试模块化
前面讲了流量回放这种偏自动化的测试流程,但它不一定能解决所有问题,端到端的测试不进行mock,直接走通链路,其虽然传统,却可以作为流量回放的有力补充。对于这种传统的测试流程是否还有优化空间呢?想一下覆盖所有回归场景的case,它里面肯定会涉及非常多的重叠情况,有重叠就有优化空间,通过解决重叠路径衍生出来的测试方式就是建立可复用单元,模块化测试。可复用单元需要时原子化(最小)场景,为了满足复用性,各单元的输入和输出要遵循一定的格式,做到可插拔,这样我们需要什么场景,直接拿对应的原子模块就行了。以下是一个电商场景的模块化验证示例,对于右边的目标用例,我们可以通过左侧的模块化组合拼接得出右边的场景。
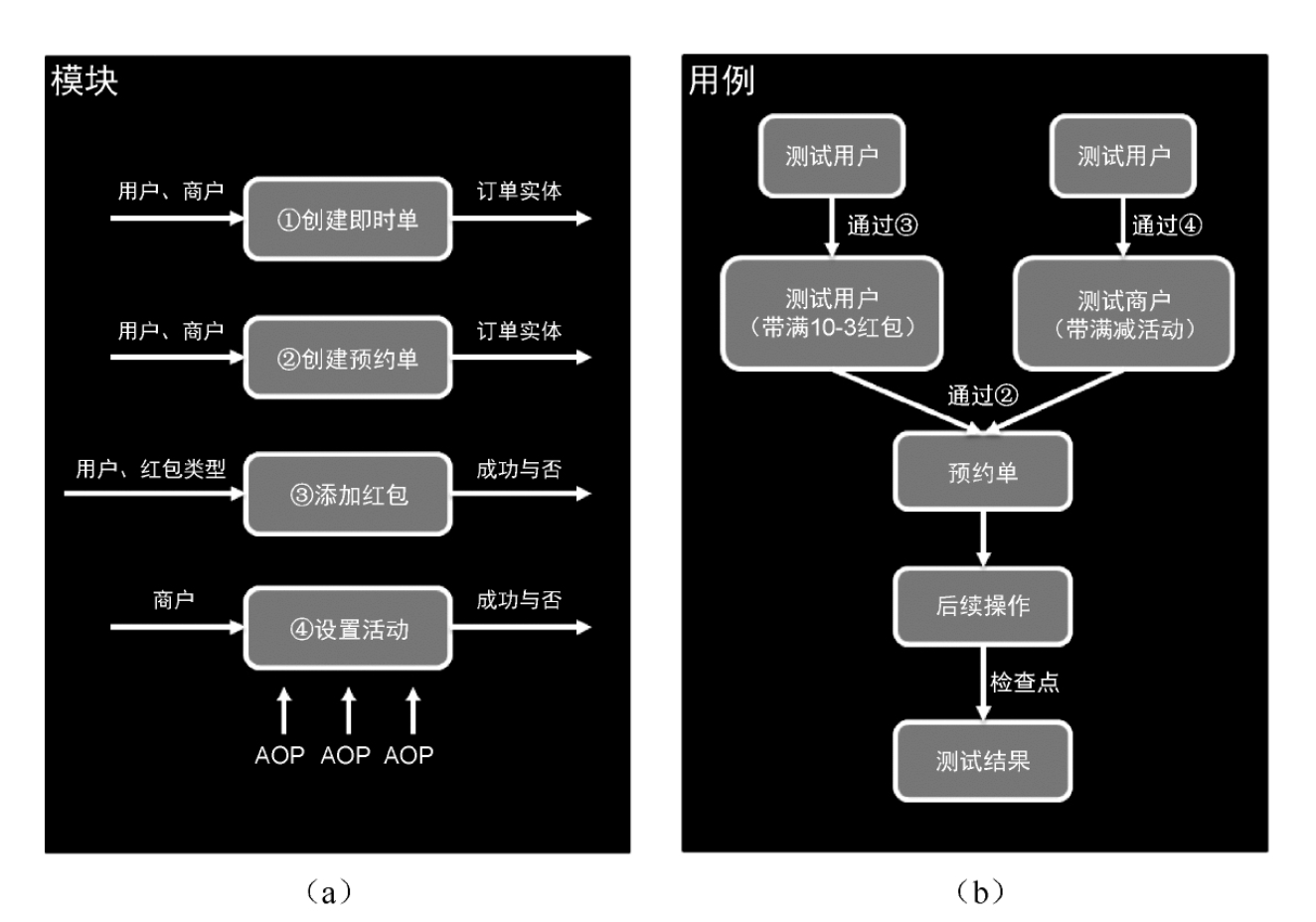
模块化还可以方便的做成可视化界面,通过拖拽的方式操作测试模块,生成测试用例。
测试环境治理
测试环境治理主要源于以下几点:
- 测试环境不稳定。频繁部署但维护不及时
- 测试环境不够用。用于支持多版本并行开发
- 测试环境成本高。可能会有多套测试环境,维护成本高
- 测试环境差异大。更多的是跟线上环境不一致问题
这些问题的治理有这几个方案可供选择。
- 标签容器方案。把测试环境做成容器,对于测试内容通过标签的形式进行区分。
- 测试环境配置管理。通过GitOps能力,把配置作为代码的一部分稳定下来。
- 测试环境巡检。对服务和更细粒度的业务定期巡检,判断其是否还可用,高频抛出问题,倒逼基础设施的优化。
服务虚拟化
这里介绍一个高级的Mock工具:Hoverfly,它能够创建一个虚拟服务,作为客户端与服务器之间的代理,并通过录制回放的手段进行学习,继而模拟外部服务行为。Hoverfly 有多种工作模式已模拟不同场景,我们选取其中几种进行说明。
- 捕获模式(Capture Mode):Hoverfly 作为中间人记录客户端到服务端的请求,并存储这些请求及返回结果,相当于流量录制。
- 仿真模式(Simulate Mode):使用捕获模式存储的返回结果直接响应请求,结果内容也支持手动创建。如果没有命中录制数据会报错。
- 间谍模式(Spy Mode):也是一种回放模式,它的特点是对于没有匹配到的请求不会报错而是直接发到真实服务并获得响应。这对于仅想测试不稳定服务的需求比较有用。
- 合成模式(Synthesize Mode):也是一种回放模式,但它不会录制数据,而是通过一个外部的可执行程序实时生成数据,Hoverfly代替服务器用这些数据应答。对于一些难以录制的复杂场景,可以使用这种模式。
- 差异模式(Diff Mode):其将真实的响应内容与录制的内容进行对比,并输出差异报告,相当于流量对比。这在服务重构等较大改动时有较大作用,可以识别出潜在缺陷。
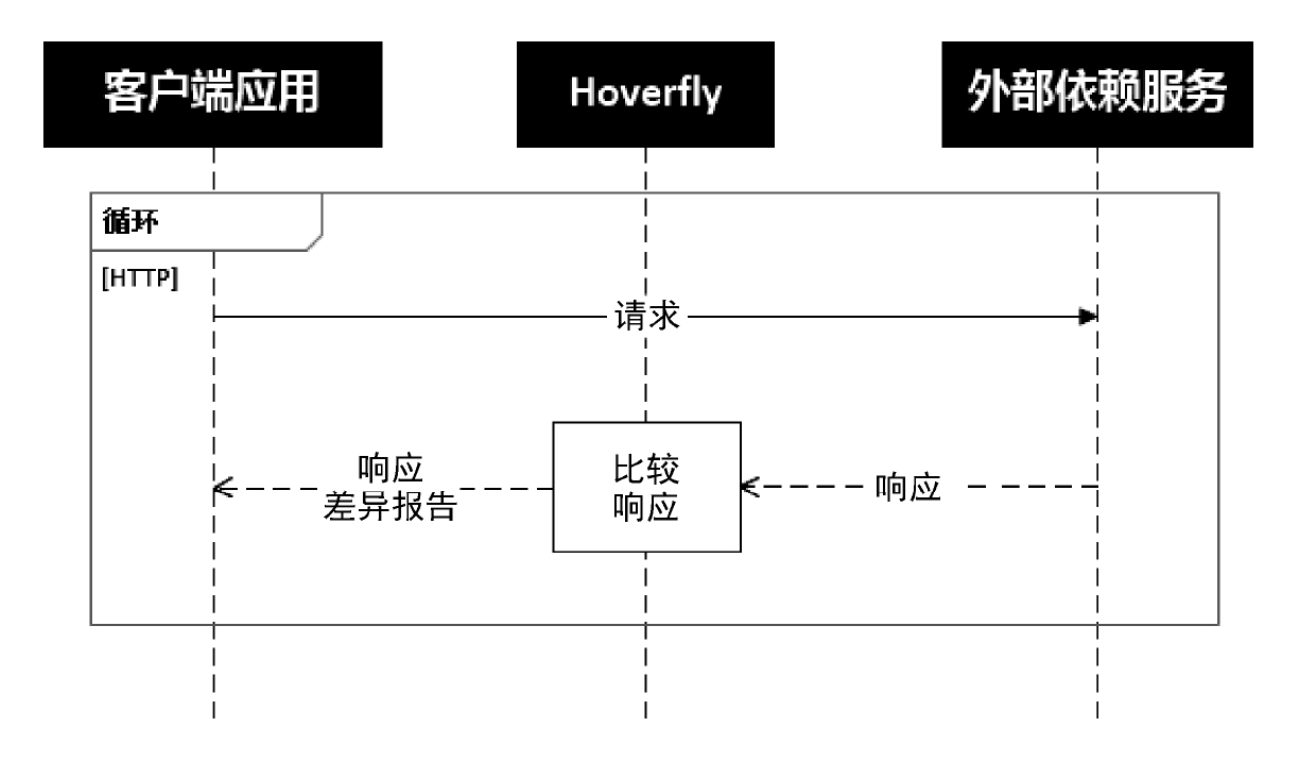
变异测试的提出是用于弥补精准测试的不足的,因为即使测试覆盖率达到了100%,任不能保证程序一定没问题,因为像是除0、数组越界等问题不是精准测试能解决的。换句话说,测试用例数量多不代表测试用例好,有可能这些很多是无效的测试用例。变异测试可以用来衡量测试用例有效性。变异测试有六个概念:
- 变异算子。在不违反编程语言语法的前提下,通过对程序的微笑改动来生成目标变异体的规则。变异算子有很多种,删除某一运算符、交换 break 和continue、删除异常处理等。
- 一阶变异体。在源程序基础上通过单变异算子转换形成目标程序。
- 高阶变异体。在源程序基础上通过多次执行变异算子形成目标程序。
- 可杀除变异体。如果该用例在变异程序执行结果和源程序执行结果不一致,则称为可杀除变异体。
- 可存活变异体。如果该用于在变异程序执行结果和源程序结果一致,则称为可存活变异体。
- 等价变异体。语法不同但语义等价的变异。
变异测试的原理是加入变异因子,如果仍有可存活变异体存在则说明用例中存在无效用例或者缺失用例。有一个工具专门用于变异测试 PITest。
高效的API自动还测试分层设计
后端测试中的API测试是非常基本的能力,大概流程如下:
# 1.mock params
product_params = {
"device-id": "1234",
"station_id": "asdf3423"
...
}
# 2.request
product.request()
# 3.assert
assert product_detail_res["code"] == 0
但随着业务场景的不断增多,像是下面这样的架构:
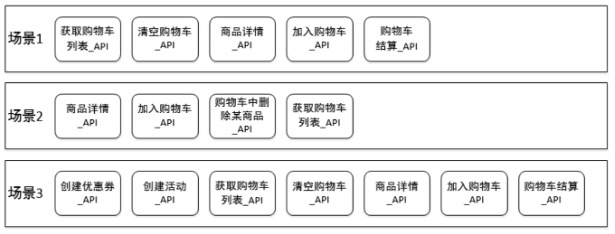
这种写法会越来越吃力,因为它可读性、灵活性、复用性、维护性都比较差。利用开发中的分层思想,我们把测试用例当做代码来看的话,可以通过这种架构将测试用例的编写变得更加清晰和明确。
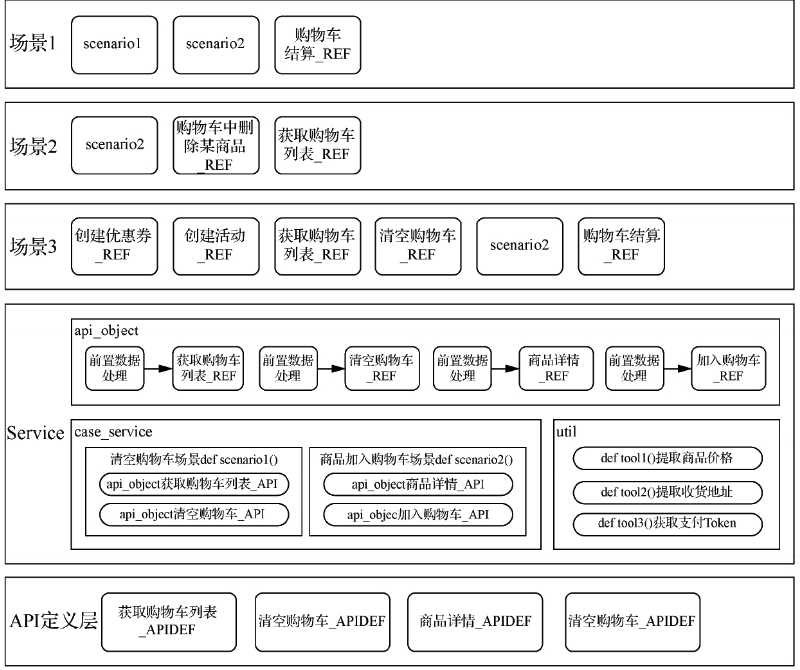
GUI 测试也有分层需求,虽然它没有 API 那么容易地做精细化控制,但按模块、页面、组件、元素等维度划分也可以可以做到复用的。
AI 的作用
提到了两个可以应用的场景。
结果分析:在测试用例执行时有可能遇到测试环境、测试数据异常导致执行失败的情况。它们会跟「有效的异常」混在一起较难分辨,如果人为介入一个一个分析又比较浪费人力。这时就可以利用AI算法,通过提取用例信息、异常信息、报错信息等内容自动筛选出有效异常。
智能代码:利用 AI 技术提高编写代码的效率,通过海量的开源代码训练,预测用户编码习惯。Github 有 Copilot,国内厂商在做的有 aiXcoder。
单元测试用例自动化生成
单元测试在软件保障中发挥着重要的作用,但其推广程度却很不理想。时间、性价比等都不同程度制约着单测覆盖率提升,归根结底不是不愿意而是成本较高。如果这些单测用例能够自动生成就可以大大提升这方面的意愿,以 Java 为例,有两款单测自动生成的工具:EvoSuite、DiffBlue Cover 。
业界优秀研发效能提升案例
我们来从一些优秀公司的实践中来学习下如何提供研发效能。
研发效能的最佳实践
作者总结了研发效能的八项实践建议。
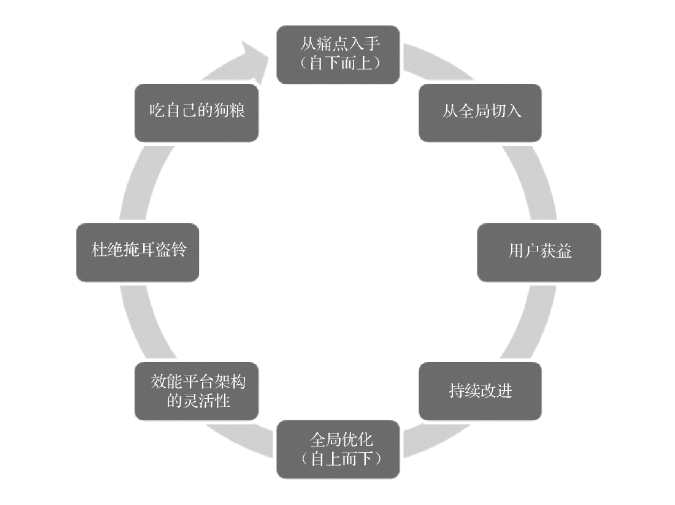
1、从痛点入手。去调研研发环节有哪些痛点需求,比如本地编译耗时长,可以提供增量编译和分布式编译能力;自动化测试用例数量大,执行回归时间长,可以采用并发测试,多设备运行的方式;自动化测试用例维护成本高,可以采用测试用例模块化和分层体系等。
2、从全局切入。不要只关注某一具体环节而忽略了全局优化的可能,问题的梳理可以更多考虑全局的影响。
3、用户获益。用户获益才是检验研发效能成功的唯一标准。研发效能团队需要抱着「不是我们的研发效能平台有多好,而是业务线用了以后有什么提升」的态度定位自己。才能从结构上获得成功的筹码。在研发效能平台落地的过程中,需要与业务线互助以实现双赢,业务线收获现成可用的方案,研发效能收获最佳实践沉淀,这些实践爱你沉淀可以为后期批量成功复制提供技术基础。
4、持续改进。持续改进是效能平台的必经之路,研发效能团队可以采取「先圈地、后改进」的策略。
5、全局优化。研发效能发展早期主要靠「自下往上」的工程实践来解决问题,比如通过分布式编译来降低编译时长,通过AI技术来自动生成单元测试用例等。通过这些专项的效率提升逐渐向管理层证明研发效能提升的实际价值,由此引起管理层对研发效能的重视,进而为管理层从上往下推进研发效能打下基础。随着研发效能实践逐渐进入深水区,单一领域效能提升的边际效应会逐渐递减,此时基于横向拉通的全局优化变得更加关键。
6、效能平台架构的灵活性。刚开始做研发效能时,既需要搭建效能平台(搭台),又需要提供各业务线的解决方案(唱戏)。但是当业务线接入越来越多时,各种各样定制性需求就需要我们在设计上考虑可扩展性和灵活性。
7、杜绝「掩耳盗铃」。“接入研发效能平台的项目数”就是属于虚荣指标,与之对应的可执行指标是“百分之多少的项目使用过研发效能平台来完成开发测试和发布流程”。我们需要的是雪中送炭,而不是锦上添花。
8、吃自己的狗粮。做自己研发效能平台的第一个用户,只有站在用户的视角来客观地评价我们的产品和方案,才不至于出现“王婆卖瓜自卖自夸”的现象。
去QE化实践
去 QE(Quality Engineer) 化是从 GTAC(Google Test Automation Conference)大会提起的。这是 Google 举办的围绕自动化测试展开的技术大会,该会议举办至第十届时宣布取消,Google 给出的理由是「相比自动化测试技术,我们更关心工程效能的提升」,这是去QE化的信号之一,Google、Facebook也都在推行这种模式。
去QE化并非不要测试,而是将测试任务转移到开发人员身上,这样的好处是缩短开发->测试-> 修复问题这条路径周期,但它带来的挑战也不小,一个是开发一般不具备测试人员的「破坏性思维」,对自己的代码判断不客观,另外大量的测试数据、多样的测试环境、多种测试框架,这些对开发来说也都是一种负担。能有效解决这些问题才是去QE化的前提,以下是某电商公司践行测试服务化理念所构建出来的测试架构设计。
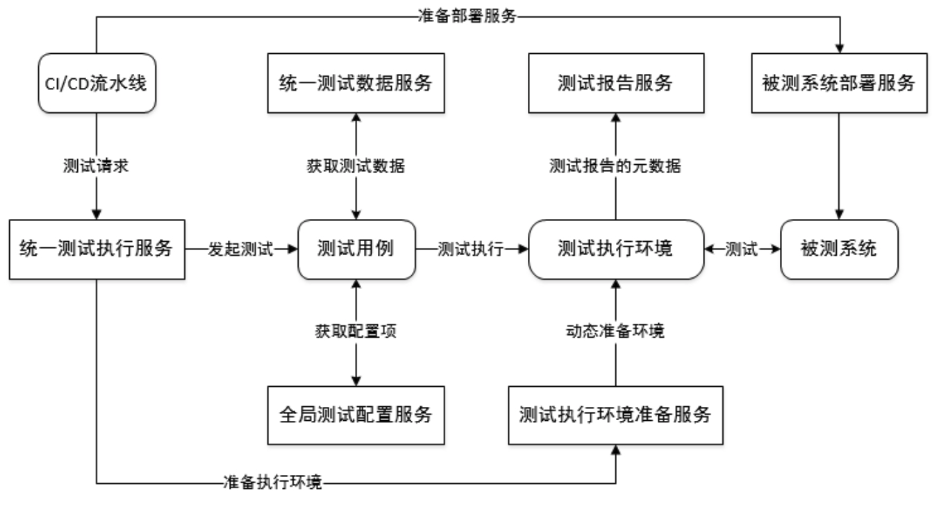
- 统一测试执行服务:承接来自CI/CD的测试需求,把测试数据和测试脚本解耦,用例和驱动解耦。
- 全局测试配置服务:把测试数据,统一为测试配置。
- 测试报告服务:针对测试结果输出详细的报告。
这样一套服务既可以降低开发接入测试的成本,又可以能够很好的承接不同类型的测试需求。
CODING 团队的组织效能变迁
这是CODING团队某一时期的团队配合模式,这是大部分公司的研发模式。
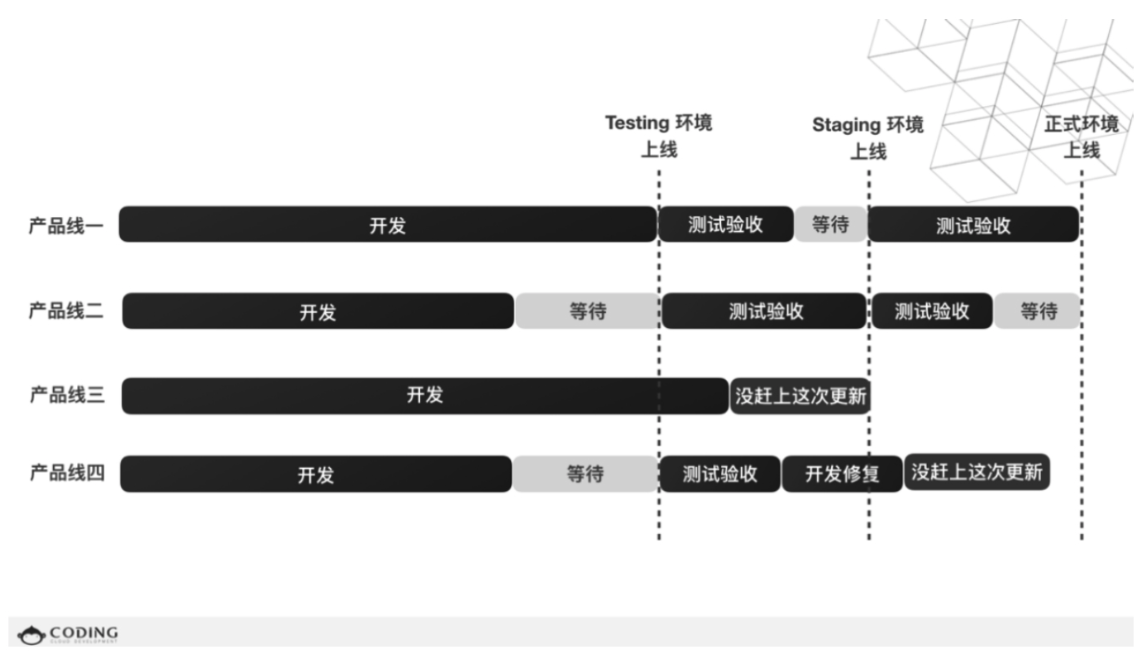
但它存在一个问题就是,各个产品线都有独立的产品经理、设计师和研发人员,但需要共同的运维人员协助部署测试环境,再统一验收,这中间会空出大量的等待时间。对应的解决方案有两个:
一:产品制的团队组织
效能提升,其中一个重要方式就是组织方式的提升,可以按照产品线拆分不同研发部门。每个部门都有产研、测试团队,在工具平台上,研发CODING DevOps CD 产品,将发布权限下放到各个部门。这样就没有了额外的等待时间,可以按需快速发布产品了。
二、基于工具的优化
随着产品线不断增多,公用的测试环境、测试配置带来的不稳定就趋于明显。为了解决这些问题,CODING 团队自研了 Nocalhost,它可以在 Kubernetes 上快速部署、开发和调试。研发人员可以在本地体验微服务切换、IDE 直连集群、热重载等功能。研发人员在开发过程的得到的反馈循环从 5 分钟缩短到 1 秒。
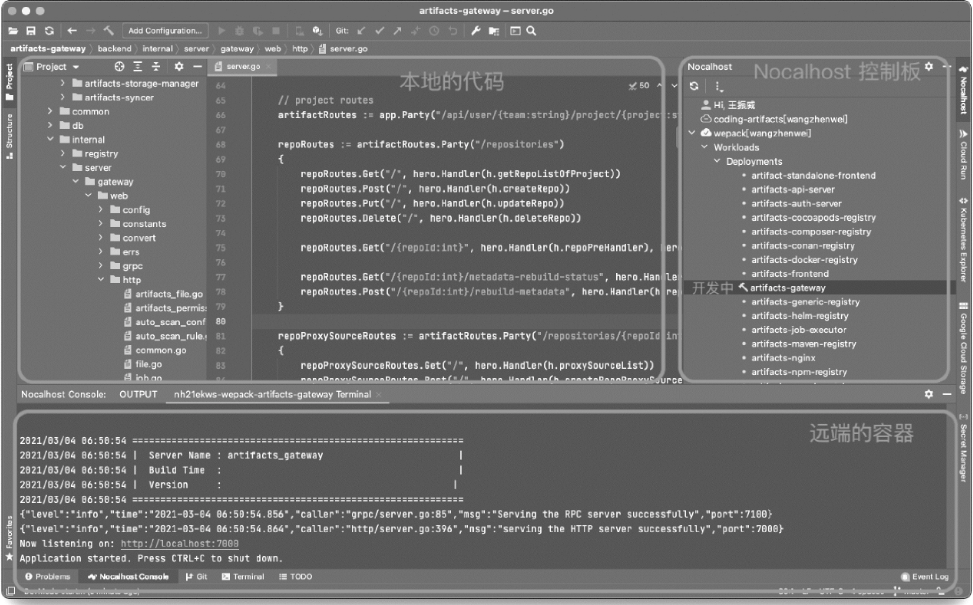
IDE 是离开发最近的东西,理想环境下,原有的测试部署环节都可以在这里得到快速验证。 �循环从 5 分钟缩短到 1 秒。
IDE 是离开发最近的东西,理想环境下,原有的测试部署环节都可以在这里得到快速验证。
Recommend
-
32
-
13
8 款 DevOps 检查清单,帮助你提升研发效能编程话题下的优秀回答者2019 年年初,我根据自身的需要在 GitHub 创建了一个名为『新项目检查清单』的开源项目:
-
5
端点科技吴小伟:提升研发效能,需要回归到组织里看整体|QCon-InfoQ
-
4
团队如何提升10倍研发效能?卓越工程生产力大会圆满落幕 ...
-
5
纯干货分享 | 研发效能提升——敏捷需求篇 - 云智慧技术社区的个人空间 - OSCHINA - 中文开源技术交流社区 建议阅读时间10mins 随着科学技术的高度发展,新兴产业的崛起,各行业对研发的需求量...
-
12
作者:徐钰菡 | 效能改进 在互联网行业,大部分研发团队都会通过建设中台(有些公司叫平台),来提高系统的可复用性,降低重复功能的研发成本。随着有赞业务的快速发展,我们也逐渐走向了大中台道路,充分享受着中台所...
-
6
一致性,是研发效能提升的必经之路!由 乔梁 | 2021-07-20「一致性会为组织带来逆熵,使其在规模化的过程中更加有序,从而带来效能提升(至少可以保持...
-
7
Lyft 如何提升微服务的研发效能(一) ...
-
5
「案例分享」研发效能提升之第一性原理 精选 原创 京东云官方 2022-11-23 16:25:0...
-
4
《软件研发效能度量规范》的解读与实践(文末附有下载)
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK