

从HashMap的执行流程开始 揭开HashMap底层实现 - 一乐乐
source link: https://www.cnblogs.com/shan333/p/16609378.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

☺ 心得:如何学习源码:
从某个执行过程入手,建议先从整体入手,了解底层的数据结构是怎么一步一步优化的。最后,在了解完底层的数据结构优化过程后,从重要的核心方法入手,从它的执行流程入手,先去网上搜索了解它的执行流程过程(推荐看流程图),再去看源码。
(1)
从某个执行过程入手,建议先从整体入手,了解底层的数据结构是怎么一步一步优化的:比如虽然我们知道HashMap 底层数据结构是:数组+链表+红黑树,但是一开始研究的是增删改查某个流程的执行,
它的整体思路是只用到
数组作为哈希表存储数据,即key 根据 哈希函数,换算得到 索引,然后根据索引定位操作对应的 数组元素。但是存储过程发生了哈希冲突,在解决哈希冲突使用-链地址法,于是
HashMap的底层结构才加入单链表。但是为提升效率,使用效率高的数据结构-红黑树,在链表的结点大于8且数组容量大于64,单链表转成红黑树,于是
HashMap的底层结构才加入红黑树。(2)
最后,在知道了底层的数据结构优化过程后,从重要核心方法的执行流程入手,先去了解到它的执行流程 (推荐看流程图),再去看源码:
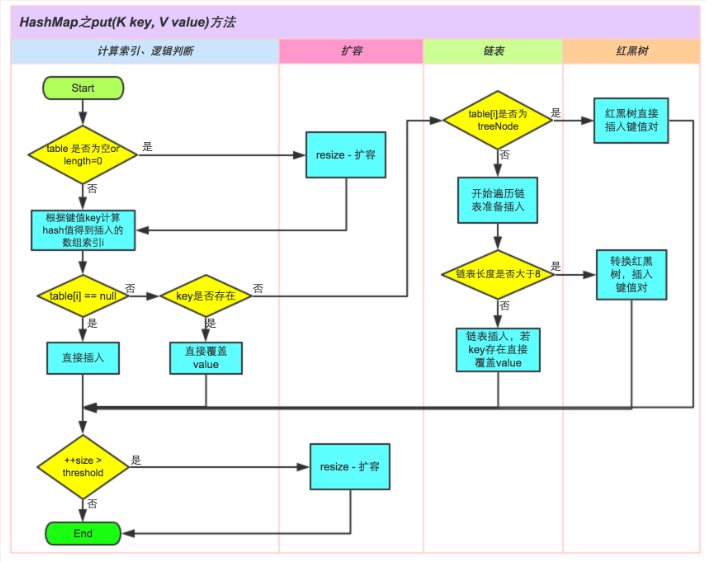
比如先了解整明白put方法执行流程图:
然后再使用idea 点击进入HashMap的put方法,自己去看源码:
一、HashMap 哈希表
1、 哈希表简单介绍:是【空间换时间】的典型应用
- 哈希函数,也叫做散列函数
- 哈希表内部的数组元素,很多地方也叫 Bucket(桶),整个数组叫 Buckets 或者 BucketArray
★ 2、(增删改查) 执行流程:
- 比如增加流程:
▪ 增删改查的流程都是类似的:
① 利用哈希函数生成key 对应的索引 index 【O(1)】
② 根据 index 操作定位到的数组 元素 【O(1)】
put("Jack", 666);
put("Rose", 777);
put("Kate", 888);
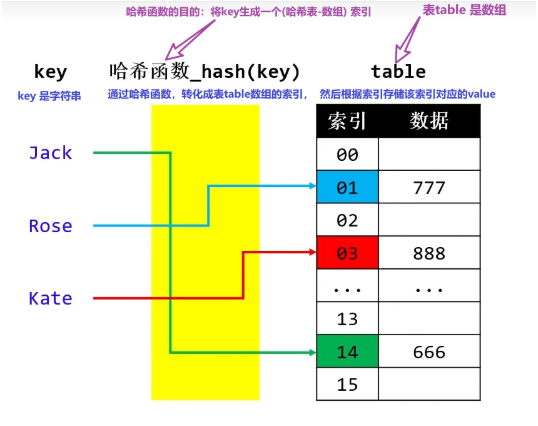
- 比如Key 是Object 类型,可以存储各种类型
★ 3、哈希冲突(哈希碰撞)
(1) 定义:2 个不同的 key,经过哈希函数计算出相同的结果(索引相同)
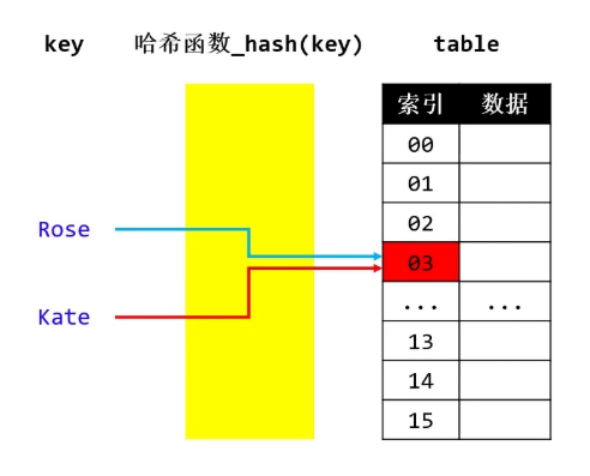
(2) 解决哈希冲突方法:
- 开放定址法:
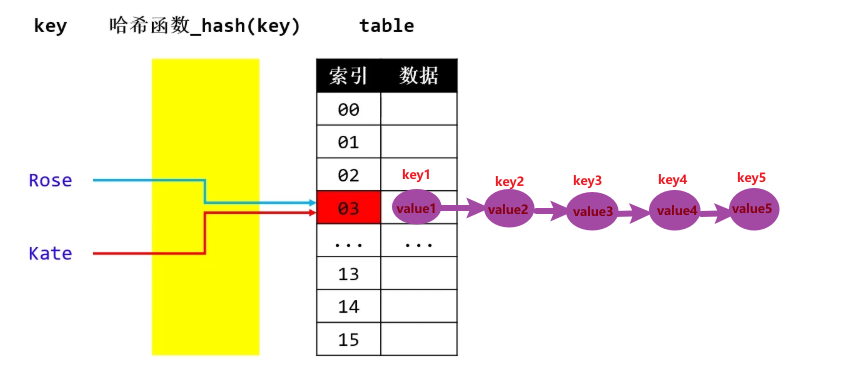
例如上图,key="Rose" 经过哈希函数换算得到索引是03,然后将key对应的value放到索引为03的数组元素位置上;
此时,key="Kate" 经过哈希函数换算得到索引也是03,而03的元素位置已经被key="Rose"对应的value 占据了,那么 从索引03的下一个位置 开始往下找一个新的"坑",往下一个一个地找(线性探测),直到找到哈希表的元素(桶),桶是空的,然后放上key="Kate"对应的value
▪ 当然往下继续找空桶,可以按平方找 12、22、32、42 等等 (平方探测)
- 再哈希法:设计了多个哈希函数
上图,按先来的先占坑,03索引的元素(桶)的"坑位" 已经被 key="Rose" 占据了,后来者key="Kate",换算得到的索引也是 03,而"坑位"已经被占据了,那么key="Kate",选择使用另外一个哈希函数,换算得到一个新的索引,直到可以成功占到"坑位"。
-
链地址法: 比如通过链表将同一index的元素串起来put("Jack", 666); put("Rose", 777); put("Kate", 888);
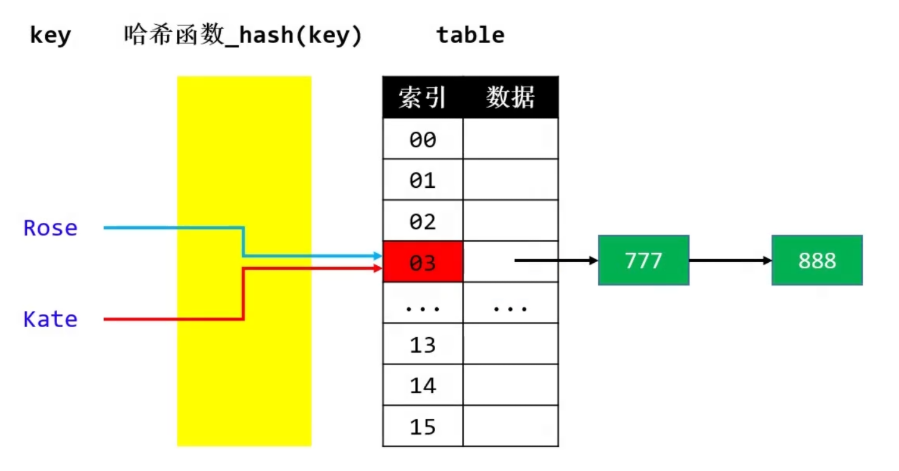
★ 4、JDK1.8的哈希冲突解决方法:链地址法(数据结构:单链表+红黑树)
◼ 默认使用单向链表将元素串起来
◼ 在添加元素的过程,可能会由单向链表转为红黑树来存储元素
比如当哈希表容量 ≥ 64 且 单向链表的节点数量大于 8 时
◼ 当红黑树节点数量少到一定程度时,会由红黑树转为单向链表
◼ JDK1.8中的哈希表是使用链表+红黑树解决哈希冲突
☺ 为什么使用 单向链表,不使用双向链表呢?
为了节省内存空间,单向链表比双向链表少一个指针;而且每次都需要从头开始遍历,使用单向链表完全满足
至此,咱就已经知道HashMap的底层数据结构为什么是数组+链表+红黑树,
接下来,咱需要了解具体实现HashMap的细节:比如哈希函数的具体实现过程,哈希值怎么计算,增删改查的具体实现细节、哈希表的扩容等等
5、哈希函数(散列函数)的作用:将各种类型的key 换算成哈希表(数组) 的索引
(1) 哈希函数的具体实现过程:
① 首先根据 key,生成 哈希值(必须是整数-int 类型)
② 然后再根据 key 的哈希值和 数组的大小 进行相关运算,生成一个 索引值
static final int hash(Object key) {
//return key.hashCode() % table.length;
// 为了提升运算效率,使用 & 位运算取代 % 运算(前提:数组长度设计为2的幂)
return key.hashCode() & (table.length - 1);
}
(2) 补充一下 与运算 &:
不管一个数 x 多大,x & 100, 最终的范围就是[0, 100]
- 使用 & 位运算取代 % 运算(前提:数组长度设计为2的幂):是为了保证被与数全是1
- 比如 2^1 是 10,2^1-1 是 00
- 比如 2^2 是 100,2^2-1 是 11
- 比如 2^3 是 1000,2^3-1 是 111
- 比如 2^4 是 10000,2^4-1 是 1111
(3) 良好的哈希函数(哈希函数作用):
- 让哈希值更加均匀分布 → 减少哈希冲突次数 → 提升哈希表的性能
6、哈希值计算
- 我们知道哈希函数第一步是根据key获取到哈希值,而且哈希值必须是整型;而key的类型是各种各样的,那么各种各样的key是如何获取到哈希值的呢?
▪ 不同种类的 key,哈希值的生成方式不一样,但目标是一致的
♢ 尽量让每个 key 的哈希值是唯一的
♢ 尽量让 key 的所有信息参与运算
◼ 在Java中,
HashMap 的 key 必须实现 hashCode、equals 方法,也允许 key 为 null
(1) 数值类型-哈希计算:包括整型、Long类型、浮点型Float、Double类型
① 整型-哈希值计算
-
整型的哈希值,已经满足哈希值是整数的特点了,所以整型的哈希值是它本身。
public static int hashCode(int value){ rerurn value; }
② 浮点型-哈希值计算
-
将浮点数对应的二进制数转成整数
- float 类型,直接调用:Float对象的floatToIntBits方法,直接将float类型的数据对应的二进制数转成整数
public static int hashCode(int value){
rerurn Float.floatToIntBits(value);
}
- double 类型,直接调用:Double 对象的doubleToIntBits方法,直接将double类型的数据对应的二进制数转成整数
细节:java 要求哈希值必须是int 类型,是32位的,对于 long(64位)、double(64位) 类型超过32位的都需要进行处理:
- 将64位分成两部分,让 高32bit 和 低32bit 混合计算出 32bit 的哈希值,充分利用所有信息计算出哈希值。
// double 类型
public static int hashCode(int value){
long bits = Double.DoubleToIntBits(value);
rerurn (int)(bits ^ (bits >>> 32));
}
//long 类型
public static int hashCode(int value){
rerurn (int)(value^(value >>> 32));
}

♢ 无符号的位运算>>> 和 异或运算^ 作用?
将64位分成两部分,让 高32bit 和 低32bit 混合计算出 32bit 的哈希值,充分利用所有信息计算出哈希值。
■ 补充一个细节:hash 函数,对哈希值进行右移16位后取异或
对哈希值的进一步处理:扰动计算,是哈希值分布更加均匀。
static final int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (table.length - 1);//将哈希值低16位与高16 位进行混合,企图让哈希值分布更加均匀
}
(3) 字符串-哈希值计算
- 利用字符串的字符本质是整数
例如:整数 5487 计算过程: 5 * 10^3 + 4 * 10^2 + 8 * 10^1 + 7 * 10^0
同理:字符串"kate",是由'k'、'a'、't'、'e' 组成:可以表示为 k * n^3 + a * n^2 + t * n^1 + e * n^0
合并,减少计算次数,等价于 [(k * n + a) * n + t] * n + e
java中 n=31,则[(k * n + a) * n + t] + e = [(k * 31 + a) * 31 + t] * 31 + e
发现规律:当前字符a或t或e的哈希值:是先算出前面的字符*31 + 当前的字符
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
(4) 自定义对象-哈希值计算
- 对自定义对象的属性根据key类型计算得出哈希值后,进行相加
7、为什么需要重写 equals
需要判断 key 是否相同,相同的话,直接用key 对应的value 覆盖掉原先的value
■ 为什么有hashCode 方法,比较 key 是否相同还需要 重写equals方法?
-
因为hashCode 方法的作用是 生成key的哈希值,而
对于不同的key,比如key类型是不同,最后算出的哈希值却是相同,所以hashCode 方法并不能判断两个key是否相同,需要重写equals方法,进一步比较两个key是否相同。
■ 总结:hashCode 方法 和 equals 方法 作用是不同的?
- hashCode 方法:生成key的哈希值
- equals 方法:比较key是否相同
8、HashMap源码分析
(1) 了解重要的几个常量
Node<K,V>[] table;//哈希桶数组,明显它是一个Node的数组
// Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。
-
HashMap就是使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,Java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
-
减少哈希冲突,依靠:好的Hash算法和扩容机制
int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的哈希桶的长度 16,要求哈希桶的长度必须是2的n次方
/* 构造函数就是对下面几个字段进行初始化 */
int threshold; // 可以容纳最大的Node个数(最大元素数目)
final float loadFactor; // 负载因子,默认值是0.75
int modCount; // 记录HashMap内部结构发生变化的次数
int size; // 节点的数量
// threshold = length * loadFactor 能容纳的最大节点个数=哈希桶容量*负载因子
- threshold就是在此loadFactor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。
■ 要求哈希桶的长度必须是2的n次方?
HashMap采用这种非 常规设计(常规是设计成素数),主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位 参与运算的过程。
int TREEIFY_THRESHOLD = 8; // 树化阀值
int MIN_TREEIFY_CAPACITY = 64; // 树化哈希桶最小容量
int UNTREEIFY_THRESHOLD = 6; // 树降级为链表的阀值
- 添加元素时,
当哈希表容量 ≥ 64 且 单向链表的节点数量大于 8 时,单向链表转为红黑树来存储元素
(2) 了解几个重要的方法
■ 确定哈希桶数组索引位置
方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的(在put方法中,有与运算来定位到索引位置)
return h & (length-1); //第三步 取模运算
}
总结:哈希函数将key换算成哈希桶数组的索引具体实现过程:
① 生成key的哈希值 ② 高位参与运算 ③ 取模运算
- 高位参与运算:将哈希值低16位与高16 位进行混合,企图让哈希值分布更加均匀
- 取模运算:定位到数组的索引位置
■ put 增加元素方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//判断哈希桶数组是否为空/是否存在,不存在-扩容
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//判断定位到的哈希桶数组的索引对应的元素是否为空/是否存在,不存在,直接创建插入该元素
tab[i] = newNode(hash, key, value, null);
else {//哈希桶数组的元素存在,那么判断key是否存在
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//key存在,直接覆盖元素的值
else if (p instanceof TreeNode)//key不存在,判断是否是一颗树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//是树节点,红黑树插入
else {
for (int binCount = 0; ; ++binCount) {//不是树节点,链表从头遍历插入该节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) //插入后节点大于8,开始树化成红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//key存在,直接覆盖元素的值
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//插入元素后判断是否大于 threshold(可以容纳的最大元素数目/节点数) --大于,则需要扩容
resize();
afterNodeInsertion(evict);
return null;
}
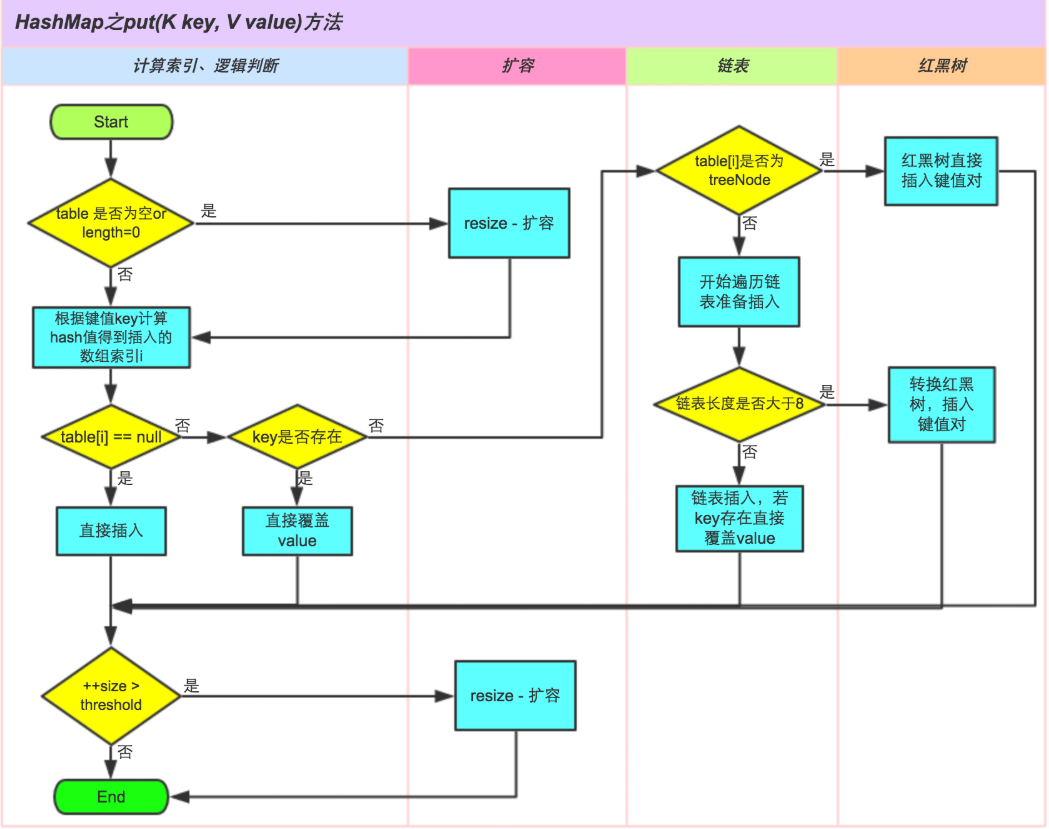
总结put时的思考点:
1、哈希表是否为空判断---空(需要扩容)
2、定位哈希表索引对应的元素是否为空判断---空(直接插入)
3、元素非空,判断key是否存在,存在直接覆盖
不存在,判断该节点是否是一颗树节点,是树节点->红黑树插入
不是树节点->链表插入,插入后判断节点数量是否大于8,大于8树化成红黑树
4、插入元素后判断是否大于 threshold(可以容纳的最大元素数目/节点数) --大于(需要扩容)
参考文章:美团技术团队 《Java 8系列之重新认识HashMap》
如果本文对你有帮助的话记得给一乐点个赞哦,感谢!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK