

光说不练假把式,一起Kafka业务实战。
source link: https://blog.51cto.com/boxuegu/5581454
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

光说不练假把式,一起Kafka业务实战。
推荐 原创
7.1 顺序性场景
7.1.1 场景概述
假设我们要传输一批订单到另一个系统,那么订单对应状态的演变是有顺序性要求的。
已下单 → 已支付 → 已确认
不允许错乱!
7.1.2 顺序级别
1)全局有序:
串行化。每条经过kafka的消息必须严格保障有序性。
这就要求kafka单通道,每个groupid下单消费者
极大的影响性能,现实业务下几乎没必要
2)局部有序:
业务局部有序。同一条订单有序即可,不同订单可以并行处理。不同订单的顺序前后无所谓
充分利用kafka多分区的并发性,只需要想办法让需要顺序的一批数据进同一分区即可。
7.1.3 实现方案
1)发送端:
指定key发送,key=order.id即可,案例回顾:4.2.3,PartitionProducer
2)发送中:
给队列配置多分区保障并发性。
3)读取端:
单消费者:显然不合理
吞吐量显然上不去,kafka开多个分区还有何意义?
所以开多个消费者指定分区消费,理想状况下,每个分区配一个。
但是,这个吞吐量依然有限,那如何处理呢?
方案:多线程
在每个消费者上再开多线程,是个解决办法。但是,要警惕顺序性被打破!
参考下图:thread处理后,会将data变成 2-1-3
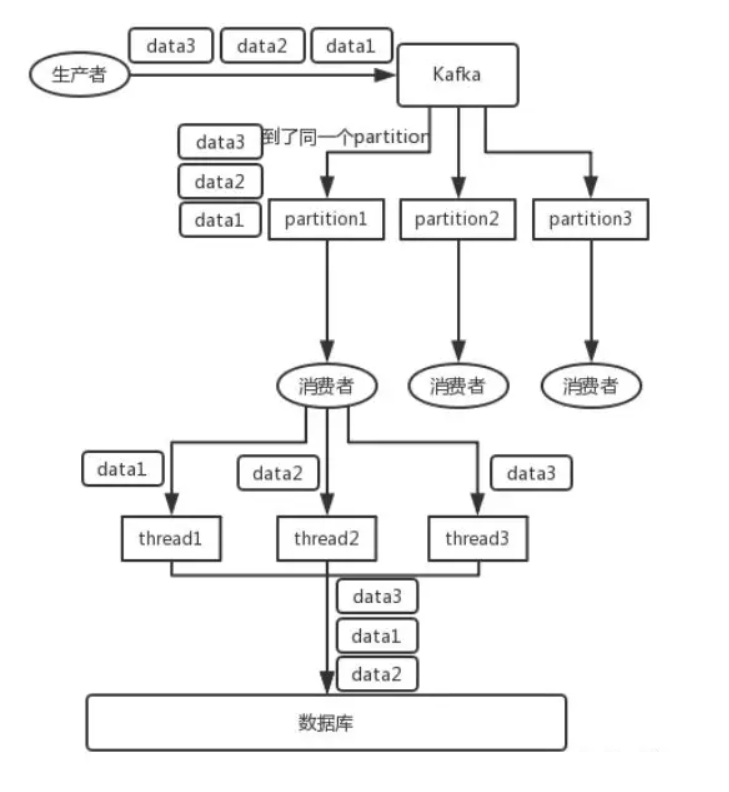
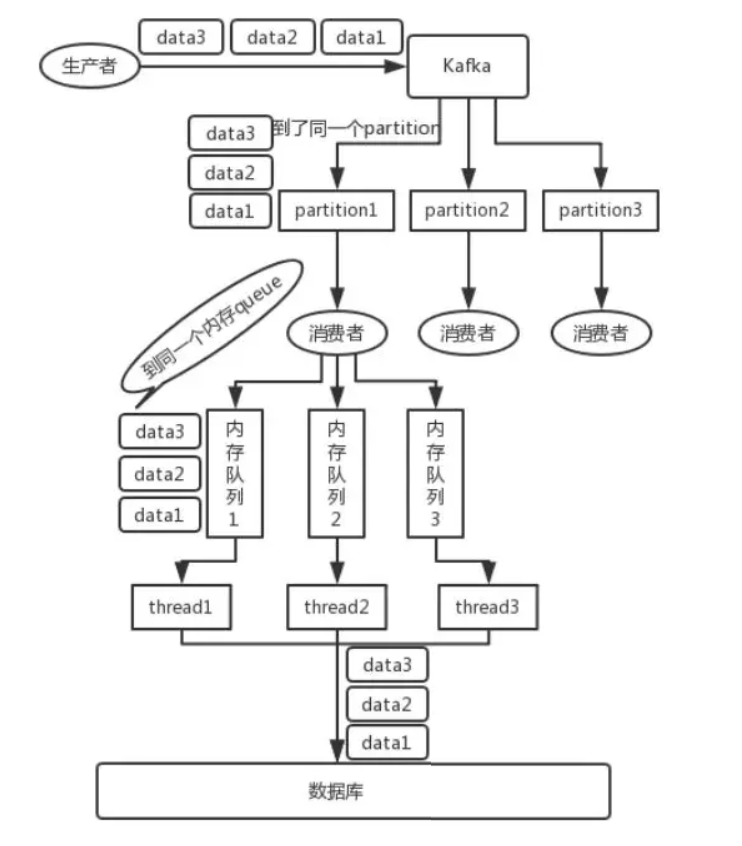
改进:接收后分发二级内存队列
消费者取到消息后不做处理,根据key二次分发到多个阻塞队列。
再开启多个线程,每个队列分配一个线程处理。提升吞吐量
7.1.4 代码验证
1)新建一个sort队列,2个分区
2)启动order项目
源码参考:
SortedProducer(顺序性发送端)
SortedConsumer(顺序性消费端 - 阻塞队列实现,方便大家理解设计思路)
SortedConsumer2(顺序性消费端 - 线程池实现,现实中推荐这种方式!)
3)通过swagger请求
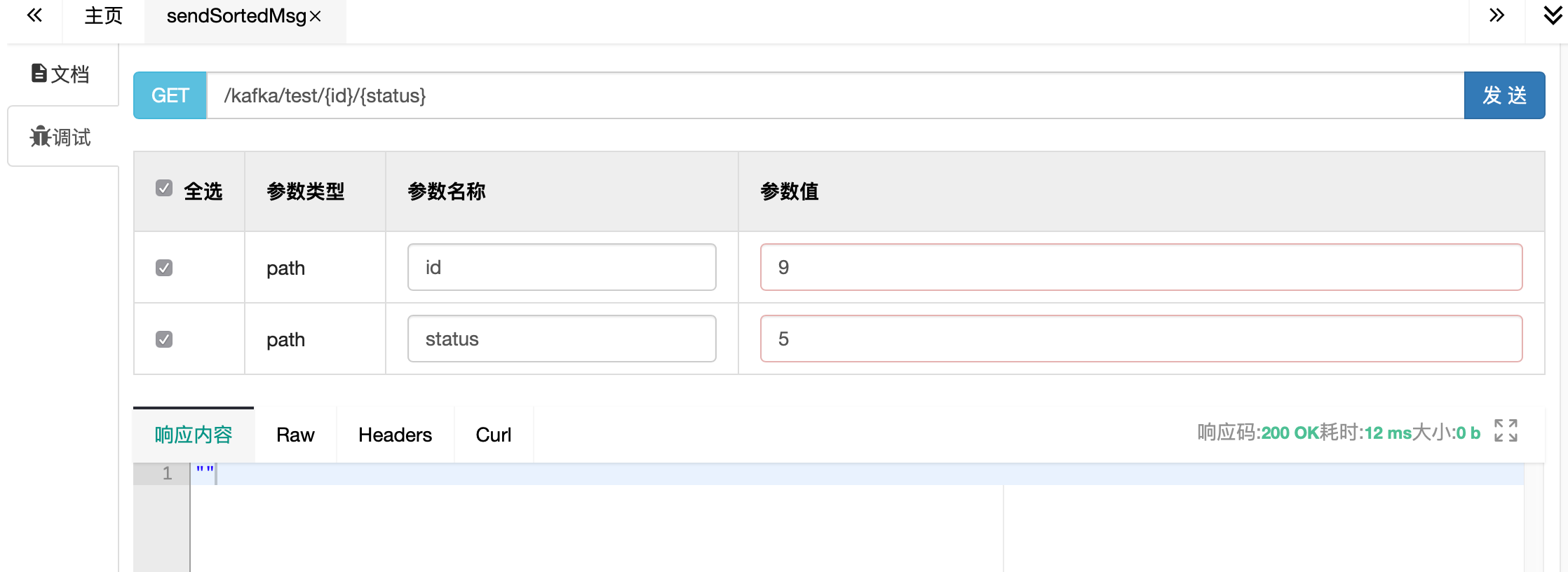
先按不同的id发送,查看控制台日志,id被正确分发到对应的队列

同一个key分配到同一个queue,顺序性得到保障

7.2 海量同步场景
假设大数据部门需要大屏来展示用户的打车订单情况,需要把订单数据送入druid
这里不涉及顺序,只要下单就传输,但是对实时性和并发量要求较高
7.2.1 常规架构
在下单完成mysql后,通过程序代码打印,直接进入kafka
或者logback和kafka集成,通过log输送
更符合常规的思维。将数据送给想要的部门
耦合度高,将kafka发送消息嵌入了订单下单的主业务,形成代码入侵。
下单不关心,也不应该关注送入kafka的情况,一旦kafka不可用,程序受影响
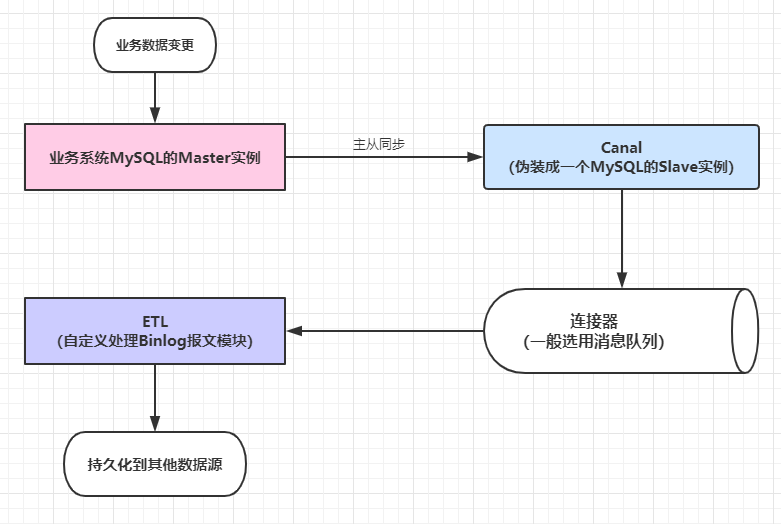
7.2.2 解耦合
借助canal,监听订单表的数据变化,不再影响主业务。
7.2.3 部署实现
1)mysql部署
注意,需要打开binlog,8.0 默认处于开启状态
docker run --name mysql8 -v /opt/data/mysql8:/var/lib/mysql -p 3389:3306 -e TZ=Asia/Shanghai -e MYSQL_ROOT_PASSWORD=thisisprizemysql8db -d daocloud.io/mysql:8.0
连上mysql,执行以下sql,添加canal用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal';
创建订单表
`id` int unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
2)canal部署
#附带资料里有,放到服务器 /opt/data/canal/ 目录下
#修改servers为你的kafka的机器地址
canal.serverMode = kafka
kafka.bootstrap.servers = 52.82.98.209:10903,52.82.98.209:10904
#附带资料里有canal.yml,随便找个目录,重命名为docker-compose.yml
#修改mysql的链接信息的链接信息
#然后在当前目录下执行 docker-compose up -d
version: '2'
services:
canal:
image: canal/canal-server
container_name: canal
restart: always
ports:
- "10908:11111"
environment:
#mysql的链接信息
canal.instance.master.address: 52.82.98.209:3389
canal.instance.dbUsername: canal
canal.instance.dbPassword: canal
#投放到kafka的哪个主题?要提前准备好!
canal.mq.topic: canal
volumes:
- "/opt/data/canal/canal.properties:/home/admin/canal-server/conf/canal.properties"
3)数据通道验证
进入kafka容器,用上面3.2.4里的命令行方式监听canal队列
在mysql上创建orders表,增删数据试一下
Query OK, 1 row affected (0.03 sec)
在kafka控制台,可以看到同步的消息
数据通道已打通,还缺少的是druid作为消费端来接收消息
4)druid部署
#在附带资料里有
#随便找个目录,执行
docker-compose -f druid.yml up -d
配置druid的数据源,从kafka读取数据,验证数据可以正确进入druid。

注:
关于druid的详细使用,在大数据篇章里会详细讲解。
7.3 kafka监控
7.3.1 eagle简介
Kafka Eagle监控系统是一款用来监控Kafka集群的工具,支持管理多个Kafka集群、管理Kafka主题(包含查看、删除、创建等)、消费者组合消费者实例监控、消息阻塞告警、Kafka集群健康状态查看等。
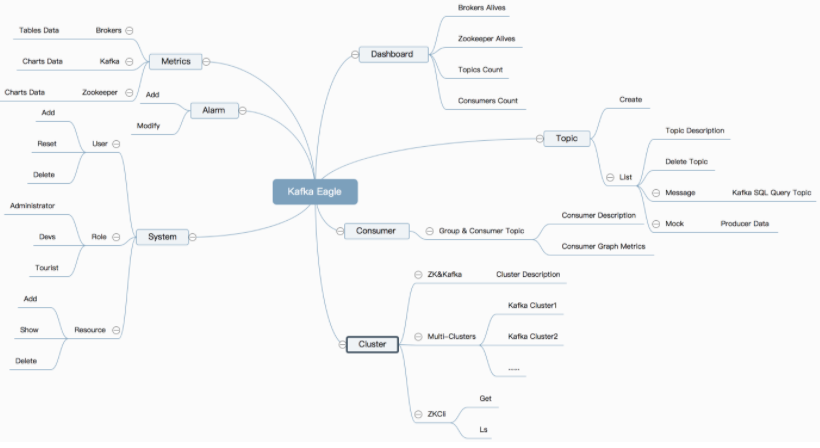
7.3.2 部署
推荐docker-compose启动
将配备的资料中 eagle.yml , 拷贝到服务器任意目录
修改对应的ip地址为你服务器的地址
version: '3'
services:
zookeeper:
image: zookeeper:3.4.13
kafka-1:
container_name: kafka-1
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10903:9092
- 10913:10913
environment:
KAFKA_BROKER_ID: 1
HOST_IP: 52.82.98.209
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#docker部署必须设置外部可访问ip和端口,否则注册进zk的地址将不可达造成外部无法连接
KAFKA_ADVERTISED_HOST_NAME: 52.82.98.209
KAFKA_ADVERTISED_PORT: 10903
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=52.82.98.209 -Dcom.sun.management.jmxremote.rmi.port=10913"
JMX_PORT: 10913
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
kafka-2:
container_name: kafka-2
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10904:9092
- 10914:10914
environment:
KAFKA_BROKER_ID: 2
HOST_IP: 52.82.98.209
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 52.82.98.209
KAFKA_ADVERTISED_PORT: 10904
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=52.82.98.209 -Dcom.sun.management.jmxremote.rmi.port=10914"
JMX_PORT: 10914
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
eagle:
image: gui66497/kafka_eagle
container_name: ke
restart: always
depends_on:
- kafka-1
- kafka-2
ports:
- "10907:8048"
environment:
ZKSERVER: "zookeeper:2181"
执行 docker-compose -f eagle.yml up -d
7.3.3 使用说明
访问 : http://52.82.98.209:10907/ke/
默认用户名密码: admin / 123456
如果要删除topic等操作,需要管理token: keadmin
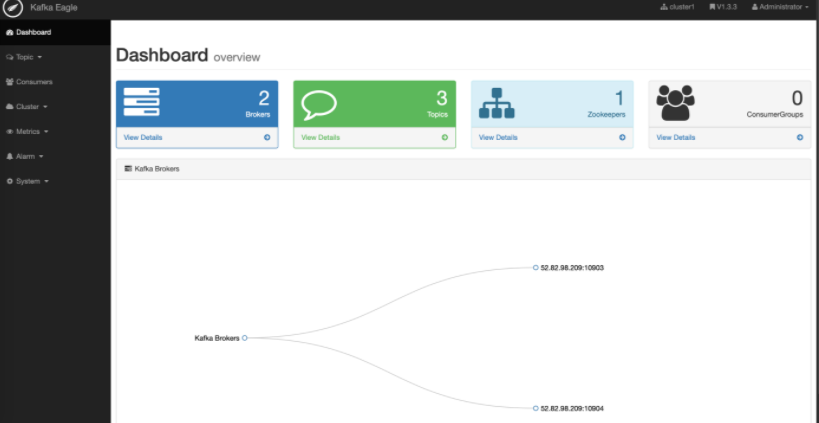
与km到底选哪个呢?根据自己习惯,个人认为:
- 界面美观程度和监控曲线优于km,有登录权限控制
- 功能操作上不如km简单直白,但是km需要配置一定的连接信息
本文由育博学谷狂野架构师发布如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力 转载请注明出处!
- 赞
- 收藏
- 评论
- 分享
- 举报
上一篇:一文说透kafka底层架构
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK