
7

常见分布式应用系统设计图解(十四):日志系统
source link: https://www.raychase.net/7087
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

常见分布式应用系统设计图解(十四):日志系统
典型的互联网应用的日志系统,从功能需求上看主要包括收集,存储和分析,以及展示这样三个部分,因此整个系统我觉得也可以按此思路大致可以分为三个部分:
- 日志收集,从宿主机上采集业务应用的日志,发送给远端的日志系统;
- 日志存储、分析和后期处理;
- 日志查询和分析数据展示。
非功能需求方面,我觉得可以考虑这样几个要点:
- Durability:这是最重要的,尽可能不要丢失日志,到服务端的日志不要丢,在客户端的日志,也是如此,即便服务端不可用或连接断开,客户端的日志也要保存在本地。
- Availability:其次是可用性,要保证高可用。
- Performance:相较来说,日志系统的 performance 主要是吞吐量而非延迟,而且网络带宽需要特别算一下。
- Scalability:业务应用增减引起的 scale 变动会非常频繁。
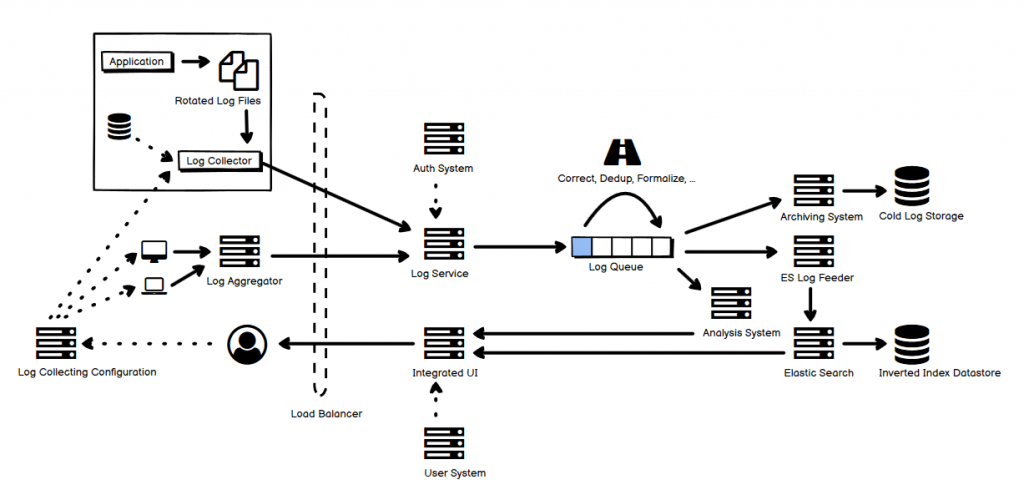
- 图中虚线为控制或辅助的逻辑,实线为实际的日志数据,或处理过的日志数据的流向。
- 客户端日志需要分片,日志的客户端采集和处理策略存储在客户端,可以通过配置文件修改,或者通过一个第三方的系统统一将数据同步过去。
- 本地的分片日志经过部署在客户端宿主机上的 Log Collector 应用来收集,这个应用需要独立进程,尽量避免影响主营业务。
- 日志实时地发给 Log Service,需要数据压缩以减少带宽占用,可以采用 “微批量”(micro-batches)提高效率。
- 特殊情况下,某些区域多个本地客户端可以部署一个 Aggregator 来进行日志实时聚合,聚合后再发给服务端 Log Service。
- Log Service 收集到日志以后放到一个持久化的分布式队列中,比如 Kafka,首先进行错误修正、去重、格式统一化等操作,在一定时间且经过特定的下游系统消费后数据可删除。有多个不同的 consumer 会消费它上面的数据,在介绍分布式实时流处理系统的时候提到过类似的机制,不赘述。
- 图中列出了三大 consumer,分别是日志分析系统、日志压缩存储系统和日志搜索系统。
- 日志压缩系统可以把日志根据策略压缩并存储到一个 “cold storage” 中,这样的存储可能对查询并不友好,但是便宜,比如 S3,甚至 AWS Glacier(它用磁带存储),主要目的是备份和非常低频率的批量访问或主键查询。
- Elastic Search 用来存放供查询的日志,这里需要考虑一个 retention policy,对于过老的日志,根据实际的需要,可以考虑从中移除出去。
- 最后有一个 UI 来帮助日志查询和分析数据的展示,比如 Kibana。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK