

奈飞的数据网格是什么样?
source link: https://www.jdon.com/61883
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

奈飞的数据网格是什么样?
作者:雷波, Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko
背景
实时处理技术(AKA 流处理)是使 Netflix 在娱乐用户的竞争中保持领先地位的关键因素之一。我们的上一代流式管道解决方案Keystone在满足我们多种关键业务需求方面有着良好的记录。然而,随着我们扩展我们的产品并尝试新的想法,越来越需要解锁 Keystone 尚未涵盖的其他新兴用例。在评估选项后,团队决定创建数据网格作为我们的下一代数据管道解决方案。
去年,我们写了一篇关于 Data Mesh 如何帮助我们的 Studio 团队实现数据移动用例的博客文章。一年过去了,Data Mesh 已经达到了它的第一个重要里程碑,并且它的范围不断扩大。随着越来越多的用例加入它,我们有更多的东西要分享。我们将发布一系列文章,涵盖数据网格的不同方面以及我们从旅程中学到的东西。本文概述了该系统。以下将深入探讨它的不同方面。
数据网格概述
数据网格的新定义
之前,我们将数据网格定义为一种完全托管的流式数据管道产品,用于启用变更数据捕获(CDC) 用例。随着系统发展以解决越来越多的用例,我们扩大了其范围,不仅可以处理 CDC 用例,还可以处理更一般的数据移动和处理用例,例如:
- 事件可以来自更通用的应用程序(不仅是数据库)。
- 可用数据库连接器的目录正在增长(例如 CockroachDB,Cassandra)
- 更多处理模式,如过滤、投影、联合、连接等。
因此,今天我们将数据网格定义为通用数据移动和处理平台,用于在 Netflix 系统之间大规模移动数据。
整体架构
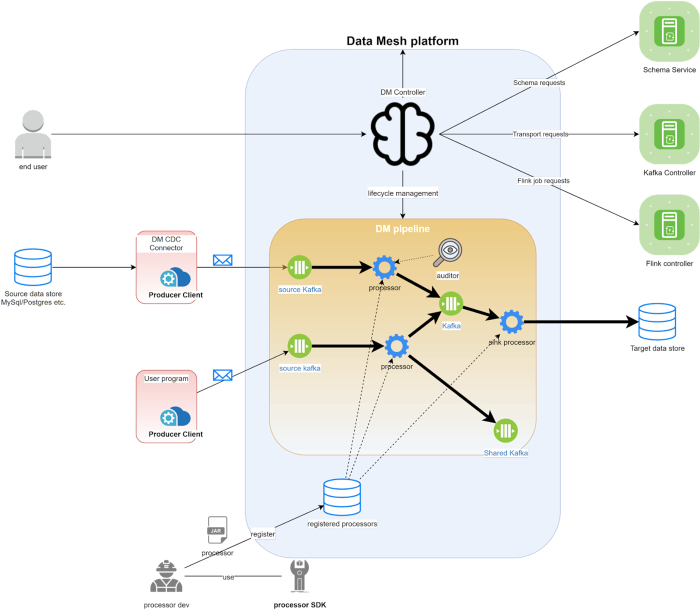
Data Mesh系统可以分为控制平面(Data Mesh Controller)和数据平面(Data Mesh Pipeline)。控制器接收用户请求、部署和编排管道。部署后,管道将执行实际繁重的数据处理工作。供应管道涉及不同的资源。控制器将责任委托给相应的微服务来管理它们的生命周期。
管道

数据网格管道从各种来源读取数据,对传入事件应用转换,并最终将它们接收到目标数据存储中。可以从 UI 或通过我们的声明性 API 创建管道。在创建/更新请求中,控制器计算出与管道相关的资源并为每个资源计算适当的配置。
连接器
源连接器是数据网格托管的生产者。它监控源数据库的 bin 日志,并为面向 Kafka 主题的数据网格源生成 CDC 事件。它能够与数据网格控制器对话以自动创建/更新源。
以前我们只有 RDS 源连接器来使用DBLog 库来监听 MySQL 和 Postgres ;现在我们添加了 Cockroach DB 源连接器和 Cassandra 源连接器。他们使用不同的机制将事件从源数据库中流出。我们将有博客文章深入探讨它们。
除了托管连接器之外,应用程序所有者还可以通过公共库发出事件,该库可用于 DB 连接器尚不可用或偏好在不与 DB 模式耦合的情况下发出域事件的情况。
来源
应用程序开发人员可以在集中的源目录中公开他们的域数据。这允许数据共享,因为 Netflix 的多个团队可能有兴趣接收实体的更改。此外,可以将 Source 定义为一系列处理步骤的结果——例如,具有多个维度(例如Talents列表)的丰富电影实体,可以进一步对其进行索引以实现搜索用例。
处理器
处理器是 Flink Job。它包含一个可重用的数据处理逻辑单元。它从上游传输读取事件并将一些业务逻辑应用于每个事件。中间处理器将数据写入另一个传输。接收器处理器将数据写入外部系统,例如 Iceberg、ElasticSearch 或单独的可发现 Kafka 主题。
我们提供了一个处理器 SDK 来帮助高级用户开发自己的处理器。由我们团队之外的 Netflix 开发人员开发的处理器也可以注册到平台并与管道中的其他处理器一起使用。注册处理器后,平台还会自动设置默认警报 UI 和指标仪表板
传送
我们使用 Kafka 作为互连处理器进行通信的传输层。上游处理器的输出事件被写入 Kafka 主题,下游处理器从那里读取它们的输入事件。
Kafka 主题也可以跨管道共享。管道#1 中保存其上游处理器输出的主题可用作管道#2 中的源。我们经常看到不同消费者需要一些中间输出数据的用例。这种设计使我们能够尽可能地重用和共享数据。我们还实现了跟踪数据沿袭的功能,以便我们的用户可以更好地了解整体数据使用情况。
架构
数据网格在所有管道上强制执行模式,这意味着我们要求通过管道的所有事件都符合预定义的模板。我们使用 Avro 作为我们所有模式的共享格式,因为它简单、强大且被社区广泛采用。
由于以下原因,我们将模式作为数据网格中的一等公民:
- 更好的数据质量:只有符合模式的事件才能被编码。让消费者更有信心。
- 更精细的数据沿袭粒度:该平台能够跟踪不同消费者如何使用字段并将其显示在 UI 上。
- 数据发现:模式描述数据集,使用户能够浏览不同的数据集并找到感兴趣的数据集。
在创建管道时,该管道中的每个处理器都需要定义它使用和生成的模式。该平台处理架构验证和兼容性检查。我们还围绕处理模式演变建立了自动化。如果架构在源头发生变化,平台会尝试自动升级消费管道,无需人工干预。
未来
数据网格最初是作为一个解决我们变更数据捕获需求的项目开始的。在过去的一年里,我们观察到机器学习、日志记录等其他领域对各种需求的需求不断增加。今天,数据网格仍处于早期阶段,还有很多有趣的问题有待解决. 以下是我们路线图中一些高优先级任务的重点。
使数据网格成为数据移动和处理的铺垫路径(推荐解决方案)
如上所述,Data Mesh 旨在成为 Netflix 的下一代实时数据管道解决方案。到目前为止,我们仍然有几个专门的内部系统服务于他们自己的用例。为了简化产品,将这些用例逐渐迁移到数据网格是有意义的。我们目前正在努力确保 Data Mesh 可以实现与 Delta 和 Keystone 的功能对等。此外,我们还希望增加对更多源和接收器的支持,以解锁广泛的数据集成用例。
更多的处理模式和更高的效率
人们不仅使用数据网格来移动数据。他们通常还希望在此过程中处理或转换他们的数据。我们的另一个高优先级任务是为我们的用户提供更常见的处理模式。由于默认情况下处理器是 Flink 作业,因此让每个简单的处理器在自己的 Flink 作业中完成它们的工作可能会降低效率。我们还在探索将多种处理模式合并到一个 Flink 作业中的方法。
更广泛地支持连接器
用户经常问我们,Data Mesh 是否能够从数据存储 X 中获取数据并将其放入数据存储 Y。今天我们支持某些源和接收器,但这还远远不够。对更多类型连接器的需求是巨大的,我们看到了一个巨大的机会,这绝对是我们也想投资的东西。
数据网格是一个复杂而强大的系统。我们相信,随着它的成熟,它将有助于 Netflix 未来的成功。同样,我们仍处于旅程的开始,我们对即将到来的机会感到兴奋。在接下来的几个月中,我们将发布更多讨论数据网格不同方面的文章。敬请期待!
团队
没有团队的辛勤工作和巨大贡献,Data Mesh 是不可能实现的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK