

PNAS最新研究:81%解题率,神经网络 Codex 推开高等数学世界大门
source link: https://www.51cto.com/article/715890.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

PNAS最新研究:81%解题率,神经网络 Codex 推开高等数学世界大门-51CTO.COM
近日,一项新研究发布于PNAS,再次刷新了神经网络的能力。这次神经网络被用来解决了高等数学题,而且还是麻省理工数学课程难度的数学题!
在这项新研究中,研究团队证明了 OpenAI 的 Codex 模型可以进行程序合成从而解决大规模的数学问题,并通过小样本学习自动解决数据集中 81%的数学课程问题,并且 Codex 在这些任务的表现上达到了人类水平。

原文链接:https://www.pnas.org/doi/10.1073/pnas.2123433119
这项研究的出现,颠覆了人们普遍认为神经网络无法解决高等数学问题的共识。研究团队指出,Codex 之所以能做到实现这样的能力,正是因为团队进行了一大创新,过去那些不成功的研究只使用了基于文本的预训练,而此次现身的 Codex 神经网络不仅要基于文本进行预训练,并且还对代码进行了微调。
研究的问题数据集选用来自 MIT 的六门数学课程和哥伦比亚大学的一门数学课程,从七门课程中随机抽取 25 个问题:MIT的单变量微积分、多变量微积分、微分方程、概率与统计概论、线性代数和 计算机科学数学和哥伦比亚大学的 COMS3251 计算线性代数。
同时,研究团队使用了一个用于评估数学推理的最新高级数学问题基准 MATH,用 MATH 来检测OpenAI Codex 的能力,MATH 从6大数学板块:初级代数,代数,计数和概率,中级代数,数论,和初级微积分中各抽取15个问题。

图注:研究中使用的课程问题数据集和MATH基准测试
研究显示,Codex 解决了问题数据集和 MATH 数据集中的 265 个问题,其中有 213 个是自动解决的。
1 创新何所在
在 Transformer 发布后,基于 Transformer 的语言模型在各种自然语言处理 (NLP) 任务,包括在零样本和少样本语言任务中取得了巨大成功。但是因为 Transformer 仅在文本上进行了预训练,所以这些模型基本上不能解决数学问题,GPT-3就是一个典型例子。
后来,通过小样本学习(few-shot learning)和思维链 (Chain-of-thought, CoT) 提示,GPT-3 的数学推理能力得到了提高;然而,在没有代码的情况下,即便有小样本学习和 CoT 提示, GPT-3 在大学水平数学问题和 MATH 基准测试中仍然无能为力。
过去关于解数学题的研究,可能在相对简单的数学水平上有一定成绩。举个例子,基于协同训练输出来验证或预测表达式树的技术,比如MAWPS 和 Math23k,能够以超过 81% 的准确率解决小学级别的数学问题,但是其不能解决高中、奥林匹克数学或大学难度的课程。协同训练与图神经网络 (GNN) 相结合以预测算术表达式树,能够以高达 95% 的准确率解决机器学习中的大学水平问题。但是这项工作也仅限于数字答案,并且产生了过拟合,不能推广到其他课程。
而这项工作的最大创新点之一就是,不仅对Codex 这种Transformer 模型进行了文本上的预训练,还在代码上进行了微调,使得其可以生成大规模解决数学问题的程序。
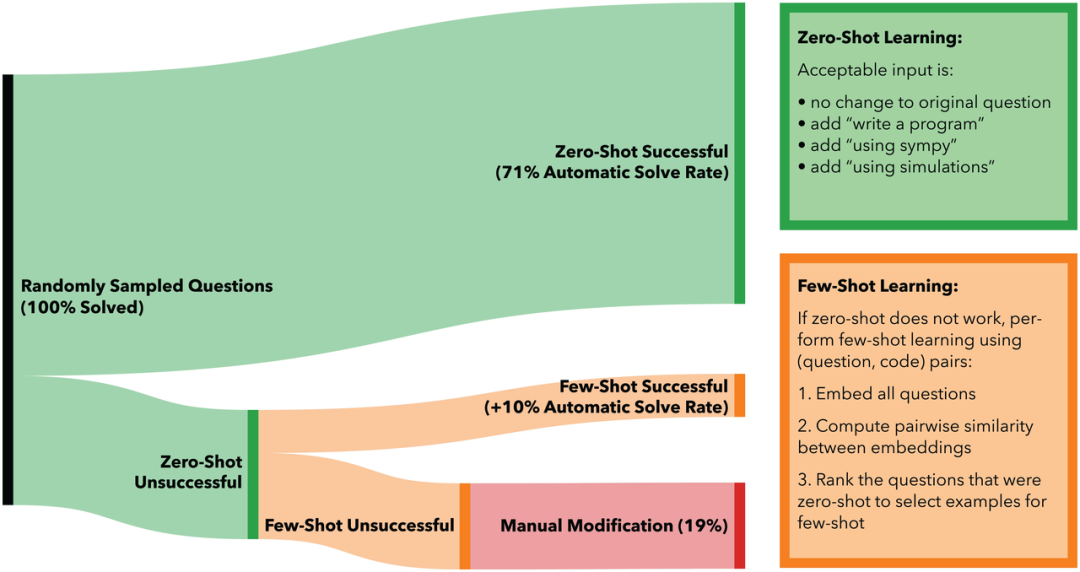
研究团队从数据集中随机选择不需要输入图像或证明的问题样本来进行测试。其中,仅对文本进行预训练的语言模型 (GPT-3 text-davinci-002) 仅自动解决了课程问题中的18%和 MATH基准测试问题中的25.5%。
相比之下,使用零样本学习和对文本进行预训练并在代码上进行微调的神经网络(OpenAI Codex code-davinci-002)合成的程序可以自动解决课程问题中的 71%和 MATH 基准测试问题中的72.2%。
而使用相同的神经网络 Codex 再加上少样本学习,便可自动解决课程中81%的问题和 MATH 基准测试中81.1%的问题。而其余模型无法自动解决的19%的课程问题和18.9%的MATH基准问题,最后通过手动提示解决。
小样本学习方式的补充,则是这项研究的第二大创新点。从上图中可以看出,当零样本学习无法解答问题时,便会使用(问题,代码)对(pair)执行小样本学习:
1) 使用 OpenAI 的 text-similarity-babbage-001 嵌入引擎嵌入所有问题;
2) 使用嵌入的余弦相似度从其课程中计算与未解决问题最相似的已解决问题;
3) 将最相似的问题及其相应的代码作为小样本问题的示例。
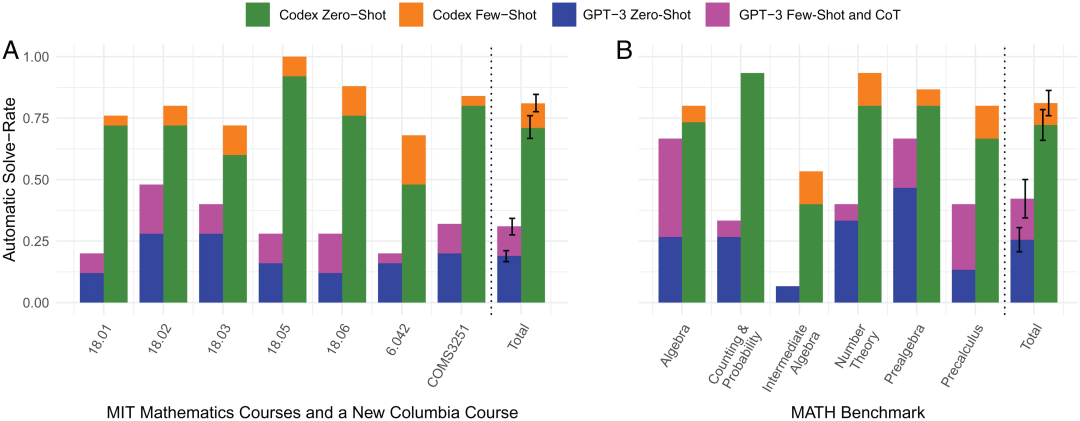
图注:4种方式的自动解题率对比
上图分别是Codex的零样本学习、小样本学习和GPT-3的零样本学习、小样本学习4种方式的自动解题率对比。图上可以看出,橙色条状所代表的小样本学习 Codex 在自动解题率上的优秀表现,基本上在每个数学领域上的表现都强于其他3种方式。
这项研究的第三大创新点,便是提供了一条解决数学问题和解释为何如此解答的管道,下图展示了MIT 5门数学课程中管道的执行流程。

以 18.01 单变量微积分问题为例,给定一个问题和自动生成的前缀“使用 SymPy”,Codex 被提示并输出一个程序。运行程序会产生正确答案的方程式。然后,程序会自动提示再次输入 Codex,从而生成生成的代码解释。
2 问题解决之后
除了解决数学问题和解释答案,Codex 也被用于为每门课程生成新问题。
为了评估生成的问题水平,团队在参加过这些课程或者同水平课程的MIT学生中做了调查,主要是比较机器生成的问题和人工编写问题的质量和难度。
在MIT的6门课程中,每门选择5个人工编写问题和5个模型生成问题混合起来并且随机呈现。对于 60 个问题中的每一个问题,参与调查的学生都需要回答 3 个调查问题:
1)你认为这个问题是人工编写的还是机器生成的?
2)你认为这个问题适合还是不适合特定课程?
3 ) 在 1(最简单)和 5(最难)之间,你认为这个问题的难度级别是多少?
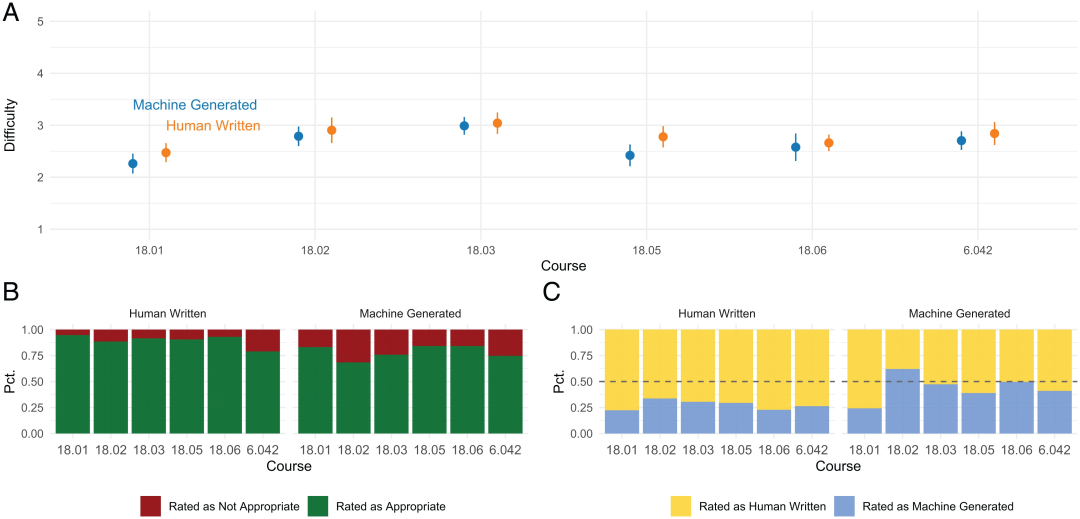
在收回的问卷中,学生调查结果总结如下:
- 机器生成和人工编写的问题难度相似。
- 人工编写的问题比机器生成的问题更适合课程。
- 人工编写的答案很难被识别错,而机器生成的问题被学生认为既可能是机器生成的,也可能是人工编写的。
机器生成的问题已经能让学生无法辨别,说明Codex 在生成新内容方面已达到了人类的表现水平。
但是,该模型也有无法解决的问题,比如,如果问题以图像或其他非文本形式出现,它就无法回答;带有需要证明的解决方案的问题,或者计算上难以解决的问题,比如分解非常大的素数,该模型也无法解决。不过,最后一种问题也不应出现在任何数学课程作业中,因为就算是真人学生也没法回答。


 分享到微信
分享到微信  分享到微博
分享到微博Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK