

关于Web3的那些白日梦,也许都藏在世界上的第一个网页里
source link: https://www.36kr.com/p/1859838966339456
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
“如果说互联网是一场探险,蒂姆·伯纳斯-李(Tim Berners-Lee)相当于麦哲伦,第一个完成了环球航行。”但如今的人们似乎早已将他遗忘。
直到一场名为 Web3 的浪潮袭来,人们叫嚣着要“重建”一个平等且开放的互联网之时,这场航行的起点才被人想起——31 年前的今天,世界上诞生了第一个网页。
2013 年,CERN(欧洲核子研究中心)希望召集全球的工程师来一场“修复计划”。这是为了赶在 2019 年,纪念万维网诞生 30 周年(从 1989 年 3 月 12 日,伯纳斯-李提交Information Management: A Proposal建议书算),重新发布“第一个 Web(网页)浏览器”。
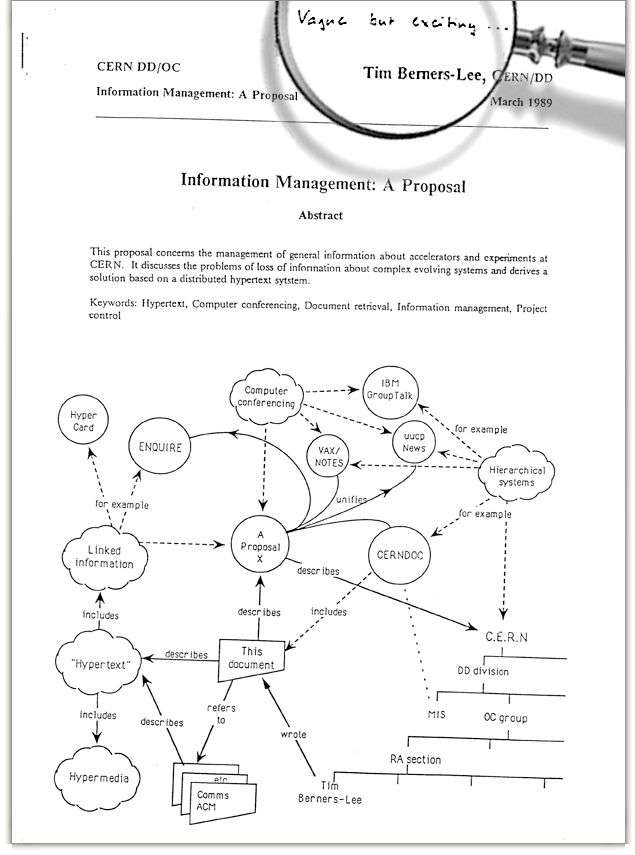
伯纳斯-李提交建议书丨来源 CERN
今天这个 Web 浏览器,依旧能被正常登陆,打开它,你就找到了万维网的“源头”(https://worldwideweb.cern.ch/browser/)。

第一个网页浏览器丨来源浏览器截图
1990 年,万维网作为 CERN 非正式项目启动。伯纳斯-李在一台 NeXT 电脑上,编写万维网的代码,创建了第一个 Web 浏览器,架设了第一个 Web 服务器,之后又上线第一个 Web 页面(1991 年 8 月 6 日)。
那台 NeXT 电脑上面残留的红色墨水笔迹至今仍然可见:“这台电脑是服务器,千万不要关闭电源。”

伯纳斯-李工作的 NeXT 电脑丨来源维基百科
第一个网页诞生 17 天后,来自 CERN 组织以外的人首次访问了这个网页(http://info.cern.ch/hypertext/WWW/TheProject.html)——这是万维网第一次作为互联网上一项公开可用的服务出现,标志着万维网的“真正诞生”。网页中的内容告诉了人们“什么是万维网”。
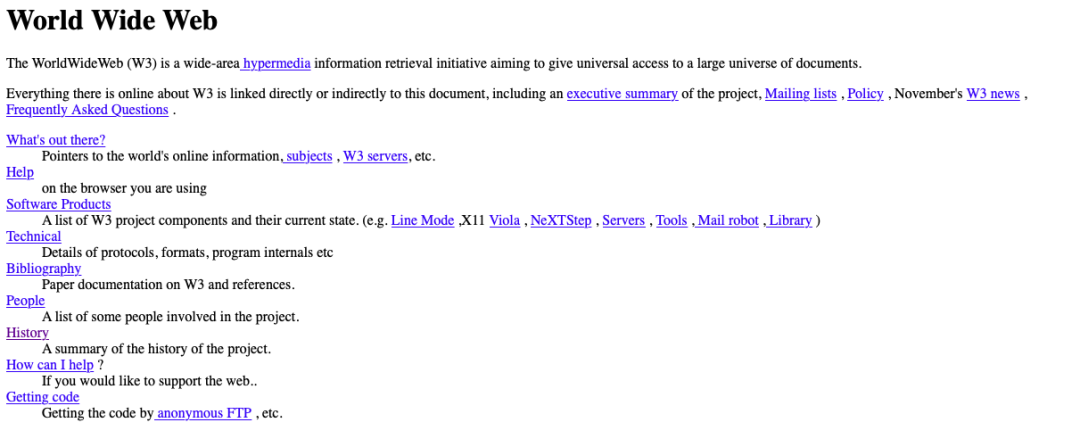
第一个网页丨来源网页截图
如果说 Internet(互联网)是由无数计算机和线缆所连接成的基础设施,实现了“物理层面”的网络连接;World Wide Web(万维网)可以视为互联网上一个“应用”,是一个由许多相互链接的超文本组成的系统。直白一点,就是在一个网页中,点击链接,跳转到另外一个网页,实现“信息层面”的网络。
万维网是第一个将计算机网络和超文本组合在一起的系统。
1980 年代,“超文本”是计算机领域的一大重要创新。Ian Ritchie 创办了一家公司——OWL,为苹果提供本地“超文本工具”。彼时,伯纳斯-李找到 Ritchie 说,“我开发了一个叫做万维网的东西,能实现覆盖全世界的网络。你能帮我开发一个浏览器吗?”
Ritchie 心想,有趣是有趣,但这人口气可真不小。后来 Ritchie 做了一场 TED 演讲,《我拒绝蒂姆·伯纳斯-李的那一天》,并为此感到遗憾。
这种“超网状结构”,不同于从上而下的树状结构,可以使任何地方之间的信息产生联系,联系可以是直接或间接的,单向或双向的。
构建万维网的关键,在于伯纳斯-李制定了三大技术标准,HTML、URL、HTTP。简单来说,HTML 语言规定了超文本如何编写;URL 规定了资源在万维网上的地址格式;浏览器遵循 HTTP 协议向服务器发送请求,服务器返回 URL 指向资源。
早期的“上网”,需要经过一系列复杂的操作,不同的计算机有不同的操作系统和不同的文件结构格式,使得跨平台的信息文件只能相互独立地划成孤岛。“统一标准”的建立,让不同系统的计算机之间分享信息成为可能。
CERN 一度想申请万维网的专利,但最终被伯纳斯-李说服放弃。最终,相关代码进行无版权保护的开源。基于此,Marc Andreessen 等人开发了第一个大受欢迎的图形界面浏览器,让更多普通人使用互联网成为可能。网景(Netscape)公司也因此成立。
但互联网原本是开放的啊!
《名利场》杂志里曾有人这样写道,人们使用网络做什么?他们(那些非学术的人,或者不是技术行业内的人。)使用电子邮件,他们发送文件。万维网将互联网变成一个资源库,这是迄今为止人类最大的信息和知识库。突然之间,人们可以在万维网上查询天气或跟踪股市情况,你可以在万维网上做很多事情。
后面的故事大家都熟悉了。从互联网上流转的信息,从静态,变成动态;从单向,变成交互。先是门户类网站大批涌现,后来我们不仅能够浏览信息,还能参与到信息创造和传递之中。
但慢慢,人们也发现,互联网发展偏离了初衷,自己的行为数据养活出的是一个接一个的科技寡头和资本巨鳄——Facebook 掌握了你的社交网,淘宝拿到了消费偏好,支付宝获取了金融数据。科技公司不需要为此付费,却以此盈利。
用伯纳斯-李的话说,“互联网坏掉了”。三个亟待解决的问题如鲠在喉:虚假信息误导;数据隐私泄露;平台造成的 app 孤岛。
伯纳斯-李出生于 1955 年,与乔布斯和盖茨同年。他的父母曾今参与开发第一款投入市场的计算机,良好家庭氛围的熏陶,加上那个时代给予的“机会”——Internet 已经建立,带图形界面的个人计算机出现,域名系统(DNS)成熟……都为万维网的诞生奠定了基础。
今天,为了互联网回到曾经的那个“乌托邦”,60 多岁的伯纳斯-李又去创业了。
他希望给每个人一个 Pod,存放着用户所有的数据。构建一个“新的标准”,让开发者们基于此构建应用。在用户使用某个应用时,可以短暂地授权某些数据。用户拥有随时拿回数据授权的权利。应用和平台根据数据的类型和多寡,提供不同程度的服务,但不能存储数据。
伯纳斯-李想创造一种透明的数据授权和托管机制,就像当初发明万维网,以及各种技术标准一样。他一直在做“重新去中心化”的努力。但除了技术上的考虑,显然这在今天是更难实现的构想。
Web3.0 一词最初是由伯纳斯-李提出的,将其作为对互联网下一阶段的展望——计算机也能像人一样处理信息和数据,实现人与电脑之间的无障碍沟通。更像是一种基于人工智能驱动的网络形态。

蒂姆·伯纳斯-李丨来源维基百科
虽然今天更加流行的“Web3.0”定义,更贴近以太坊的联合创始人 Gavin Wood 在 2014 年提出的概念,Less trust, more truth(少些信任,多些真相)。人们普遍认为下一代互联网是基于区块链的,去中心化的。
不过今天人们提及下一代互联网的畅想时,总会拿万维网(Web1.0)举例。
万维网本身就是“去中心化”的产物,它是透明、公开的。因为任何万维网上的文章之间都能随意互相链接,它提供了一个自由交流,无权威中心的空间。
1994 年,伯纳斯·李发起 W3C(万维网联盟),致力于成为一个建立具备中立性和兼容性的技术标准的“共识组织”。“对我来说,Web 是人和人连接成的网,而不是机器和机器,或者文档和文档连接成的网。”
他很早之前,就写下一些设想,但到今天都未能实现。
[1] https://zhuanlan.zhihu.com/p/42704329
[2]https://worldwideweb.cern.ch/history/
[3]https://36kr.com/p/1723347714049?channel=copy_url
[4]https://mp.weixin.qq.com/s/nrqZsl9-pjcrOxvgHq8qbw
[5]https://zhuanlan.zhihu.com/p/27494786
[5]https://baijiahao.baidu.com/s?id=1691908401455296941&wfr=spider&for=pc
本文来自微信公众号 “果壳”(ID:Guokr42),作者:沈知涵,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK