

如何优雅的消除系统重复代码?
source link: https://blog.51cto.com/u_15736055/5543281
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

如何优雅的消除系统重复代码?
原创很多同学在工作一段时间之后可能都有这样的困境,大家觉得自己总是在写业务代码,技术上感觉好像没有多大的长进,不知不觉就成为了CURD Boy或者Girl,自己想要去改变但是又不知道该从何处进行入手。有的同学会去学习如何做架构、有的同学可能会去学习各种新技术还有的同学甚至转产品经理来试图解除困境。但是我觉得找到跨出这种困境的途径反而还是要从我们每天写的代码入手。即便当前每天做着CRUD的事情,但是我们自己不能把自己定义为只会CURD的工具人。那么我们到底如何从代码层面入手改变困境呢?我们可以回过头看看自己以前写的代码,或者是当前正在实现的各种各样的需求,反问自己以下5个问题。
1、有没有使用设计模式优化代码结构?
2、有没有利用一些高级特性来简化代码实现?
3、有没有借助框架的能力来扩展应用能力?
4、自己设计的业务模型够不够抽象?
5、代码扩展性强不强,需求如果有变化模块代码能不能做到最小化修改?
通过这样的反问和思考,我们可以不断自我审视自己写的代码。通过在代码上的深耕细作,我们所负责的模块的质量就会比别人更高,出现Bug的概率就会更低,稳定性就会更高,那么未来负责更多业务模块的机会也就会更多,只有这样我们才能真正跨出困境,实现突破。因此本文主要从优化日常工作中经常遇到的重复代码入手,和大家探讨下如何通过一些技巧来消除平台中的重复代码,以消除系统中的重复代码为切入点,提升系统稳定性。
为什么要消除重复代码
在程序猿的日常工作中,不仅要跟随业务侧的发展不断开发新的需求,同时也需要维护老的已有平台。无论是开发新需求还是维护老系统,我们都会遇到同样一个问题,系统中总是充斥着很多重复的代码。可能是由于工期很赶没时间优化,也有可能是历史原因欠下的技术债。无论是什么原因,系统中大量的重复代码非常影响平台整体的可维护性。大神们的谆谆教导Don’t Repeat Yourself 言犹在耳。那么平台中的重复代码会带来怎样的稳定性风险呢?
系统维护成本高
如果项目中出现大量的重复代码,说明系统中这部分业务逻辑并没有进行很好的抽象,因此会导致后期的代码维护面临很多问题。无论是修改原有逻辑还是新增业务逻辑可能需要在不同的文件中进行修改,项目维护成本相当高。另外后期维护的同学看到同样的逻辑写了多遍,不明白这到底是代码的坏味道还是有什么特殊的业务考虑,这也在无形中增加了后期维护者的代码逻辑理解难度。
程序Bug概率高
大家都知道重复代码意味着业务逻辑相同或者相似,假如这些相同或者相似的代码出现了Bug,在修复的过程中就需要修改很多地方,导致一次上线变更的内容比较多,存在一定的风险,毕竟线上问题70%-80%都是由于新的变更引起的。另外如果重复的地方比较多,很有可能出现漏改的情况。因此重复的代码实际就是隐藏在工程中的老炸弹,可能一直相安无事,也可能不知道什么时候就会Bom一声给你惊喜,因此我们必须要进行重复代码消除。
如何优雅的消除重复代码
在消除重复代码之前,我们首先需要确定到底什么是重复代码,或者说重复代码的特征到底是什么。有的同学可能会说,这还不简单嘛,重复代码不就是那些一模一样的但是散落在工程不同地方的代码嘛。当然这句话也没错,但是不够全面,重复代码不仅仅指那些不同文件中的完全相同的代码,还有一些代码业务流程相似但是并不是完全相同,这类代码我们也把它称之为重复代码。重复代码的几个特性:
1、代码结构完全相同
比如工程中好几个地方都有读取配置文件的逻辑,代码都是相同的,那么我们可以把不同地方读取配置文件的逻辑放到一个工具类中,这样今后再有读取配置文件的需要的时候可以直接调用工具类中方法即可,不需要再重复写相同的代码,这也是我们日常工作中最常见的使用方式。
2、代码逻辑结构相似
在项目中经常遇到虽然代码并不是完全相同,但是逻辑结构却非常相似。比如电商平台在进行营销活动的时候,常常通过邀请的方式来进行用户红包领取的活动,但是对于新老用户的红包赠予规则是不同的,同时也会根据邀请用户的数量的不同给予不同的红包优惠。但是无论新老用户都会经历根据用户类型获取红包计算规则,根据规则计算减免的红包,最后付款的时候减去红包数额这样一个业务逻辑。虽然表面看上去代码并不相同,但是实际上逻辑基本是一样的,因此也属于重复代码。
下面就和大家分享几种比较实用的消除重复的代码的技巧,考虑到安全性,代码都进行了脱敏以及简化处理。
统一参数校验
当我们进行项目开发的时候,会编写一些类的实现方法,不可避免的会进行一些参数校验或者业务规则校验,因此会在实现方法中写一些判断参数是否有效或者返回结果是否有效的的的代码。
if(StringUtils.isEmpty(id)) {
return null;
}
OrderDTO order = orderBizService.queryOrder(id);
if(Objects.isNull(Order)) {
return null;
}
...
}
public List<UserDTO> queryUsersByType(List<String> type) {
if(StringUtils.isEmpty(id)) {
return null;
}
...
}
这种参数校验的方式,很多人会喜欢使用@Valid这种注解来进行参数有效性的判断,但是我觉得还是不够方便,它只能进行一些参数的校验,并不能进行业务结果的有效性判断。那么对于这种校验类的代码如何才能消除重复if...else...判断代码呢?因此我一般会统一定义一个Assert断言来进行参数或者业务结果的校验,当然也可以使用Spring框架提供的Assert抽象类来进行判断,但是它抛出的异常是IllegalArgumentException,我习惯抛出自己定义的全局统一的异常信息,这样可以通过全局的异常处理类来进行统一处理。因此我们首先定义一个业务断言类,主要针对biz层出现的参数以及业务结果进行断言,这样可以避免重复写if...else...判断代码。
public static void notEmpty(String param) {
if(StringUtils.isEmpty(param)) {
throw new BizException(ErrorCodes.PARAMETER_IS_NULL, "param is empty or null");
}
}
public static void notNull(Object o) {
if (Objects.isNull(o)) {
throw new BizException(ErrorCodes.PARAMETER_IS_NULL, "object is null");
}
}
public static void notEmpty(Collection collection) {
if(CollectionUtils.isEmpty(collection)) {
throw new BizException(ErrorCodes.PARAMETER_IS_NULL, "collection is empty or null");
}
}
}
我们看下优化后的代码是不是看上去清爽许多。
Assert.notEmpty(id);
OrderDTO order = orderBizService.queryOrder(id);
Assert.notNull(order);
...
}
public List<UserDTO> queryUsersByType(List<String> type) {
Assert.notEmpty(type);
...
}
统一异常处理
以下这类Controller代码在项目中是不是很常见?大家可以翻翻自己的项目工程代码,可能很多工程中Cotroller层都充斥着这样的try{}catch{}逻辑处理,相当于每个接口实现都要进行异常处理,看起来非常冗余写起来也麻烦。实际上我们可以通过定义统一的全局异常处理器来进行优化,避免重复的进行异常捕获。
public ResponseResult<OrderVO> getOrderList(@RequestParam("id")String userId) {
try {
OrderVO orderVo = orderBizService.queryOrder(userId);
return ResponseResultBuilder.buildSuccessResponese(orderDTO);
} catch (BizException be) {
// 捕捉业务异常
return ResponseResultBuilder.buildErrorResponse(be.getCode, be.getMessage());
} catch (Exception e) {
// 捕捉兜底异常
return ResponseResultBuilder.buildErrorResponse(e.getMessage());
}
}
那么我们应该怎么优化这些重复的异常捕捉处理代码呢?首先我们需要定义一个统一的异常处理器,通过它来对Controller接口的异常进行统一的异常处理,包括异常捕获以及异常信息提示等等。这样就不用在每个实现接口中编写try{}catch{}异常处理逻辑了。示意代码只是简单的说明实现方法,在项目中进行落地的时候,大家可以定义处理更多的异常类型。
@ResponseBody
public class UnifiedException {
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
@ExceptionHandler(BizException.class)
@ResponseBody
public ResponseResult handlerBizException(BizException bizexception) {
return ResponseResultBuilder.buildErrorResponseResult(bizexception.getCode(), bizexception.getMessage());
}
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
@ExceptionHandler(Exception.class)
@ResponseBody
public ResponseResult handlerException(Exception ex) {
return ResponseResultBuilder.buildErrorResponseResult(ex.getMessage());
}
}
优化后的Controller如下所示,大量的try...catch...不见了,代码结构变得更加清晰直接。
public ResponseResult<OrderVO> getOrderList(@RequestParam("id")String userId) {
List<OrderVO> orderVo = orderBizService.queryOrder(userId);
return ResponseResultBuilder.buildSuccessResponese(orderVo);
}
优雅的属性拷贝
在实际的项目开发中我们所开发的微服务都是分层的有的是MVC三层,有的按照DDD领域分层是四层。无论是三层还是四层都会涉及不同层级的之间的调用,而每个层级都有自己的数据对象模型,比如biz层是dto,domain层是model,repo层是po。因此必然会涉及到数据模型对象之间的相关转换。在一些场景下模型之间的字段很多都是一样的,有的甚至是完全一模一样。比如将DTO转化为业务模型Model,实际上他们之间很多的字段都是一样的,所以经常会出现以下的这种代码,会出现大量的属性赋值 的操作来达到模型转换的需求。实际上我们可以通过一些工具包或者工具类进行属性的拷贝,避免出现大量的重复赋值代码。
public static TaskDTO taskModel2DTO(TaskModel taskModel) {
TaskDTO taskDTO = new TaskDTO();
taskDTO.setId(taskModel.getId());
taskDTO.setName(taskModel.getName());
taskDTO.setType(taskModel.getType());
taskDTO.setContent(taskModel.getContent());
taskDTO.setStartTime(taskModel.getStartTime());
taskDTO.setEndTime(taskModel.getEndTime());
return taskDTO;
}
}
使用BeanUtils的进行属性赋值,很明显不再有那又长又没有感情的一条又一条的属性赋值语句了,整个任务数据模型对象的转换代码看上去立马舒服很多。
public static TaskDTO taskModel2DTO(TaskModel taskModel) {
TaskDTO taskDTO = new TaskDTO();
BeanUtils.copyProperties(taskModel, taskDTO);
return taskDTO;
}
}
当然很多人会说,BeanUtils会存在深拷贝的问题。但是在一些浅拷贝的场景下使用起来还是比较方便的。另外还有Mapstruct工具,大家也可以试用一下。
核心能力抽象
假设有这样的业务场景,系统中需要根据不同的用户类型计算商品结算金额,大致的计算逻辑有三个步骤,分别是计算用户商品总价格,计算不同用户对应的优惠金额,最后计算出用户的结算金额。我们先来看下原有系统中的实现方式。
普通用户结算逻辑:
//省略代码
...
public Bigdecimal calculate(String userId) {
//计算商品总价格
List<Goods> goods = shoppingService.queryGoodsById(userId);
Bigdecimal total = goods.stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getAmount()))).reduce(BigDecimal.ZERO, BigDecimal::add);
//计算优惠
Bigdecimal discount = total.multiply(new Bigdecimal(0.1));
//计算应付金额
Bigdecimal payPrice = total - dicount;
return payPrice;
}
//省略代码
...
}
VIP用户结算逻辑:
//省略代码
...
public Bigdecimal calculate(String userId) {
//计算商品总价格
List<Goods> goods = shoppingService.queryGoodsById(userId);
Bigdecimal total = goods.stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getAmount()))).reduce(BigDecimal.ZERO, BigDecimal::add);
//计算优惠
Bigdecimal discount = total.multiply(new Bigdecimal(0.2));
//计算应付金额
Bigdecimal payPrice = total - dicount;
return payPrice;
}
//省略代码
...
}
黑卡用户结算逻辑:
//省略代码
...
public Bigdecimal calculate(String userId) {
//计算商品总价格
List<Goods> goods = shoppingService.queryGoodsById(userId);
Bigdecimal total = goods.stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getAmount()))).reduce(BigDecimal.ZERO, BigDecimal::add);
//计算优惠
Bigdecimal discount = total.multiply(new Bigdecimal(0.2));
//计算应付金额
Bigdecimal payPrice = total - dicount;
return payPrice;
}
//省略代码
...
}
在这样的场景下,我们可以发现,在三个类中计算商品总额以及计算最后的应付金额逻辑都是一样的,唯一不同的是每个用户类型对应的优惠金额是不同的。因此我们可以把逻辑相同的部分抽象到AbstractSettleMent中,然后定义计算优惠金额的抽象方法由各个不同的用类型子类去实现。这样各个子类只要关心自己的优惠实现就可以了,重复的代码都被抽象复用大大减少重复代码的使用。
//省略代码
...
public abstact Bigdecimal calculateDiscount();
public Bigdecimal calculate(String userId) {
//计算商品总价格
List<Goods> goods = shoppingService.queryGoodsById(userId);
Bigdecimal total = goods.stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getAmount()))).reduce(BigDecimal.ZERO, BigDecimal::add);
//计算优惠
Bigdecimal discount = calculateDiscount();
//计算应付金额
Bigdecimal payPrice = total - dicount;
return payPrice;
}
//省略代码
...
}

自定义注解和AOP
用过Spring框架的同学都知道,AOP是Spring框架核心特性之一,它不仅是一种编程思想更是实际项目中可以落地的技术实现技巧。通过自定义注解和AOP的组合使用,可以实现一些通用能力的抽象。比如很多接口都需要进行鉴权、日志记录或者执行时间统计等操作,但是如果在每个接口中都编写鉴权或者日志记录的代码那就很容易产生很多重复代码,在项目后期不好维护。针对这种场景 我们可以使用AOP同时结合自定义注解实现接口的切面编程,在需要进行通用逻辑处理的接口或者类中增加对应的注解即可。
假设有这样的业务场景,需要计算指定某些接口的耗时情况,一般的做法是在每个接口中都加上计算接口耗时的逻辑,这样各个接口中就会有这样重复计算耗时的逻辑,重复代码就这样产生了。那么通过自定义注解和AOP的方式可以轻松地解决代码重复的问题。首先定义一个注解,用于需要统计接口耗时的接口方法上。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TimeCost {
}
定义切面实现类:
@Component
public class CostTimeAspect {
@Pointcut(value = "@annotation(com.mufeng.eshop.anotation.CostTime)")
public void costTime(){ }
@Around("runTime()")
public Object costTimeAround(ProceedingJoinPoint joinPoint) {
Object obj = null;
try {
long beginTime = System.currentTimeMillis();
obj = joinPoint.proceed();
//获取方法名称
String method = joinPoint.getSignature().getName();
//获取类名称
String class = joinPoint.getSignature().getDeclaringTypeName();
//计算耗时
long cost = System.currentTimeMillis() - beginTime;
log.info("类:[{}],方法:[{}] 接口耗时:[{}]", class, method, cost + "毫秒");
} catch (Throwable throwable) {
throwable.printStackTrace();
}
return obj;
}
}
优化前的代码:
public ResponseResult<List<OrderVO>> getOrderList(@RequestParam("id")String userId) {
long beginTime = System.currentTimeMillis();
List<OrderVO> orderVo = orderBizService.queryOrder(userId);
log.info("getOrderList耗时:" + System.currentTimeMillis() - beginTime + "毫秒");
return ResponseResultBuilder.buildSuccessResponese(orderVo);
}
@GetMapping("/item")
public ResponseResult<OrderVO> getOrderById(@RequestParam("id")String orderId) {
long beginTime = System.currentTimeMillis();
OrderVO orderVo = orderBizService.queryOrderById(orderId);
log.info("getOrderById耗时:" + System.currentTimeMillis() - beginTime + "毫秒");
return ResponseResultBuilder.buildSuccessResponese(orderVo);
}
优化后的代码:
@TimeCost
public ResponseResult<List<OrderVO>> getOrderList(@RequestParam("id")String userId) {
List<OrderVO> orderVo = orderBizService.queryOrder(userId);
return ResponseResultBuilder.buildSuccessResponese(orderVo);
}
@GetMapping("/item")
@TimeCost
public ResponseResult<OrderVO> getOrderList(@RequestParam("id")String orderId) {
OrderVO orderVo = orderBizService.queryOrderById(orderId);
return ResponseResultBuilder.buildSuccessResponese(orderVo);
}
引入规则引擎
大家在做业务开发的时候,可能会遇到这样的场景,业务中充斥着各种各样的规则判断,同时这些业务规则还可能经常发生变化。即便是我们用了策略模式等设计模式来优化代码结构,但是还是不能避免代码中出现大量的if...else...判断代码,一旦增加或者修改规则都需要在原来的业务规则代码中进行修改,维护起来非常不方便。
假设设有这样的业务,销售人员的奖励根据实际的利润进行计算,不同的利润计算奖励的规则并不相同。使用规则引擎之前,可能会有这样的代码结构,需要根据实际利润所处的区间来计算最终的奖励金额,不同区间范围对应的返点规则是不一样的,因此会有很多的if...else...判断。另外规则有可能随着业务的发展还会经常变化,因此后期可能面临不断修改这部分的计算奖励的代码的情况。
if(profit < 1000) {
return profit * 0.1;
} else if(1000 < profit && profit< 2000) {
return profit * 0.15;
} else if(2000 < profit && profit < 3000) {
return profit * 0.2;
}
return profit * 0.3;
}
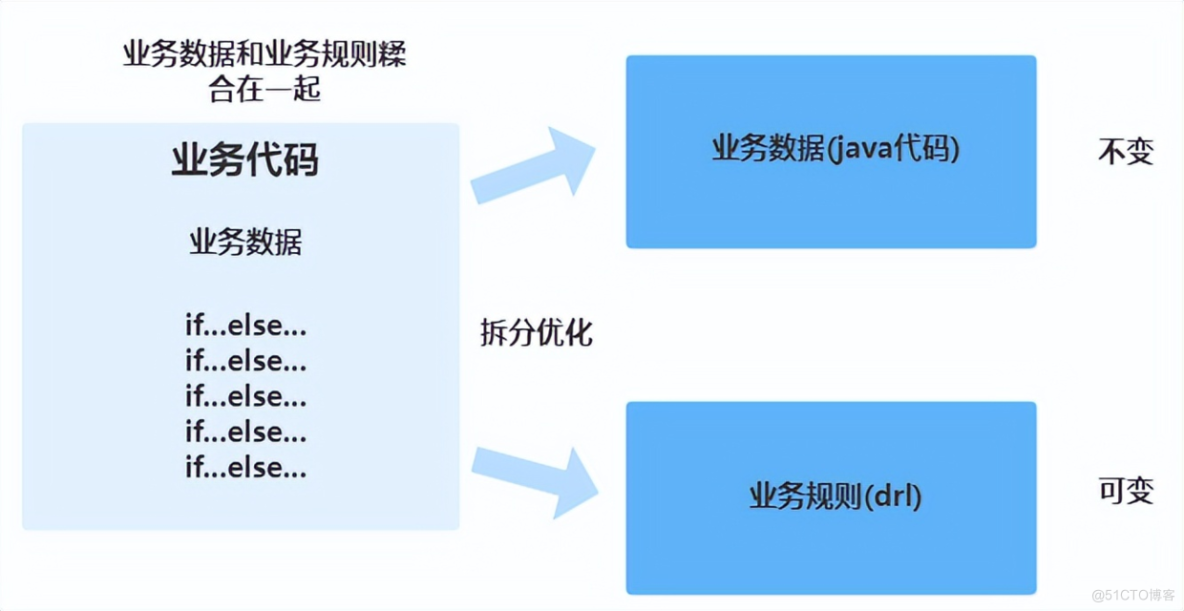
如果遇到这种业务场景,我们就可以考虑使用规则引擎。通过引入规则引擎,我们可以实现业务代码与业务规则相分离,将各种业务判断规则从原有的平台代码中抽离出来,以后规则的修改都在规则文件中直接修改就可以了,避免代码本身的变更,从而大大提升代码的扩展性。这里简单介绍下常用的规则引擎Drools是如何实现规则扩展管理的。
使用Drools之后:
使用规则引擎优化之后,所有的规则也就是所有的if...else...都会放在规则文件reward.drl中,因此代码中不会再有各种重复的if...else...代码,真正实现了业务规则与业务数据相分离。
package reward.rule
import com.mufeng.eshop.biz.Reward
// rule1:如果利润小于1000,则奖励计算规则为profit*0.1
rule "reward_rule_1"
when
$reward: Reward(profit < 1000)
then
$reward.setReward($reward.getProfit() * 0.1);
System.out.println("匹配规则1,奖励为利润的1成");
end
// rule2:如果利润大于1000小于2000,则奖励计算规则为profit*0.15
rule "reward_rule_2"
when
$reward: Reward(profit >= 1000 && profit < 2000)
then
$reward.setReward($reward.getProfit() * 0.15);
System.out.println("匹配规则2,奖励为利润的1.5成");
end
// rule3:如果利润大于2000小于3000,则奖励计算规则为profit*0.2
rule "reward_rule_3"
when
$order: Order(profit >= 2000 && profit < 3000)
then
$reward.setReward($reward.getProfit() * 0.2);
System.out.println("匹配规则3,奖励为利润的2成");
end
// rule4:如果利润大于等于3000,则奖励计算规则为profit*0.3
rule "reward_rule_4"
when
$order: Order(profit >= 3000)
then
$reward.setReward($reward.getProfit() * 0.3);
System.out.println("匹配规则4,奖励为利润的3成");
end
在代码中只要将待判断的数据插入到规则引擎的工作内存中,然后执行规则就可以获取到最终的结果,是不是很方便的实现业务规则的解耦,在实际的Java代码中也不用看到各种if...else...判断。
定义规则引擎实现:
private KieHelper kieHelper;
public DroolsEngine() {
this.kieHelper = new KieHelper();
}
public void executeRule(String rule, Object unit, boolean clear) {
kieHelper.addContent(rule, ResourceType.DRL);
KieSession kieSession = kieHelper.getKieContainer().newKieSession();
//插入判断实体
kieSession.insert(unit);
//执行规则
kieSession.fireAllRules();
if (clear) {
kieSession.dispose();
}
}
}
public class Profit {
public double calculateReward(Reward reward) {
String rule = "classpath:rules/reward.drl";
File rewardFile = new File(rule);
String rewardDrl = FileUtils.readFile(rewardFile, "utf-8");
DroolsEngine engine = new DroolsEngine();
engine.executeRule(rewardDrl, reward, true);
return reward.getReward();
}
}
通过引入Drools规则引擎,代码中不再有各种规则判断的重复的if...else...判断语句,而且如果后期要修改奖励规则,代码不用修改,直接更改规则即可,系统的扩展性以及可维护性进一步提升。
消除重复代码方法论
上文中给大家介绍了几种消除重复代码的实战小技巧,不知道大家有没有发现虽然具体落地实操的手段各不相同,无论是提取公用逻辑作为工具类、使用AOP进行面向切面编程还是进行通用逻辑抽象,又或者是借助规则引擎分离实现与规则。实际它们的核心思想本质上都是一致的,都是通过抽离或者抽象相似代码逻辑后进行统一处理。将这种核心思想放在微服务内部就是在系统中的消除重复业务逻辑,如果放在架构层面来看其实和中台思想的本质也是相通的,将用户、支付这种各个平台都会用到的服务抽象为中台,实际就是一种混乱到有序的软件复杂度治理过程以及一种万物归一的思想。
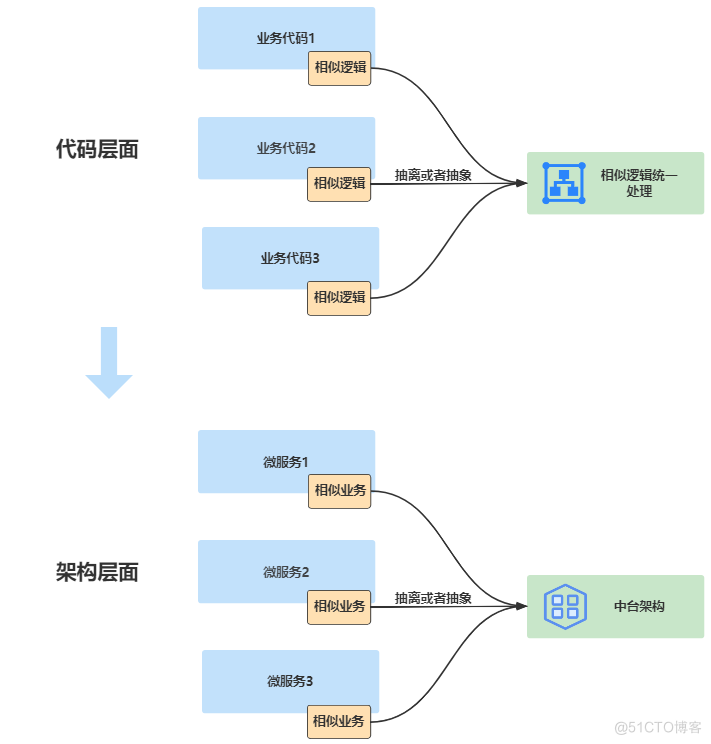
那么在日常的实际项目中我们应该怎么落地实践消除重复代码呢?这里总结了通过上述文章对于重复代码的处理,我们来试图来提炼消除重复代码的方法论。
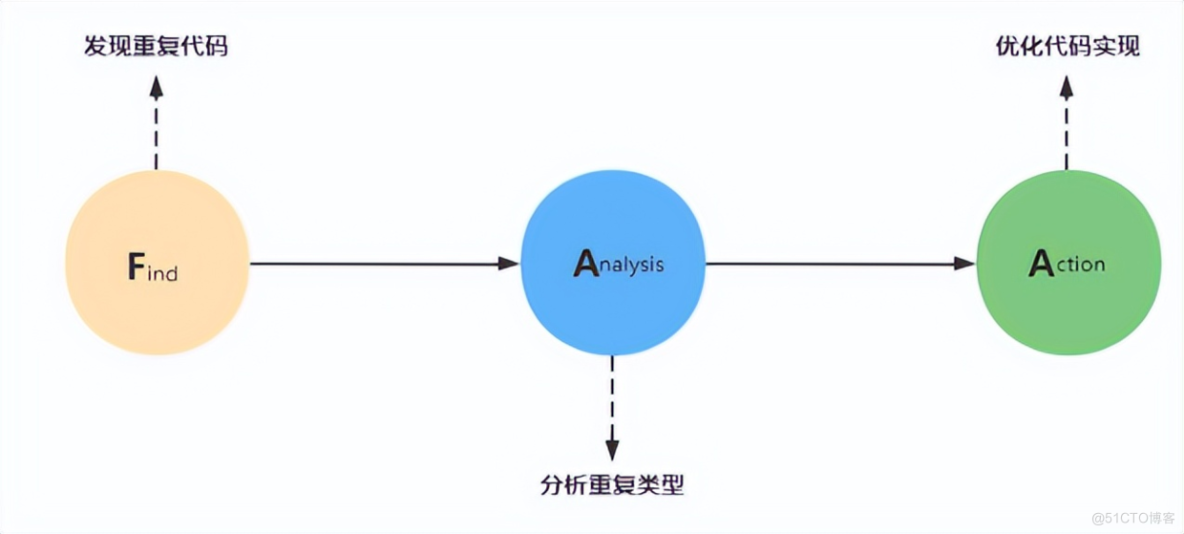
**Find:**技术同学需要有一双可以发现重复代码的眼睛,能够将表面上的重复我代码以及隐藏的重复代码识别出来。重复代码不仅仅是表示长得一模一样的代码,那些核心业务逻辑一样实际也是一种重复代码。
**Analysis:**当我们找到了重复代码之后,就要考虑该如何进行优化了,如果只是工具类型的重复代码,那么直接提取作为一个工具类就可以了,也不用考虑太多。但是如果是涉及业务流程可能需要进一步的进行抽象。
**Action:**根据不同的重复代码的类型,我们需要制定不通过的优化重复代码的方案。根据不同的方案实现通过引入规则引擎还是模板方法进行抽象。
今天和大家主要分享了几种项目中消除重复代码的实践方案,同时沉淀了如何优雅消除代码重复的方法论,希望通过这样的沉淀以及总结可以在大家遇到同样的问题的时候可以有所帮助,通过实际的优化代码落地来提升平台的可维护性。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK