

20B-parameter Alexa model sets new marks in few-shot learning
source link: https://www.amazon.science/blog/20b-parameter-alexa-model-sets-new-marks-in-few-shot-learning
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

With an encoder-decoder architecture — rather than decoder only — the Alexa Teacher Model excels other large language models on few-shot tasks such as summarization and machine translation.
Most major advances in AI have come from supervised learning, in which machine learning models are trained on annotated data. But as commercial AI models continue to increase in scale, relying on data annotation is becoming unsustainable.
At Alexa AI, we are moving to the new paradigm of generalizable intelligence, in which models can learn new concepts and transfer knowledge from one language or task to another with minimal human input. Such models allow us to efficiently develop new features and improve Alexa on multiple languages at the same time.
As part of this move, we have introduced Transformer-based large-scale multilingual language models we call Alexa Teacher Models (AlexaTM). Given only a few examples of a task in a new language, AlexaTM can transfer what it knows to the new language with no extra human supervision.
In a paper we’re presenting at this year’s Knowledge Discovery and Data Mining Conference (KDD), we showed that 10-billion- and two-billion-parameter AlexaTM models can improve on state-of-art cross-lingual transfer learning and increase Alexa’s accuracy in different locales.
In a follow-up paper, which we're publishing on arXiv later today, we have taken this line of research a step further, with a 20-billion-parameter generative model called AlexaTM 20B. The experiments reported in the paper — which use only publicly available data — show that AlexaTM 20B can not only transfer what it learns across languages but also learn new tasks from just a handful of examples (few-shot learning).
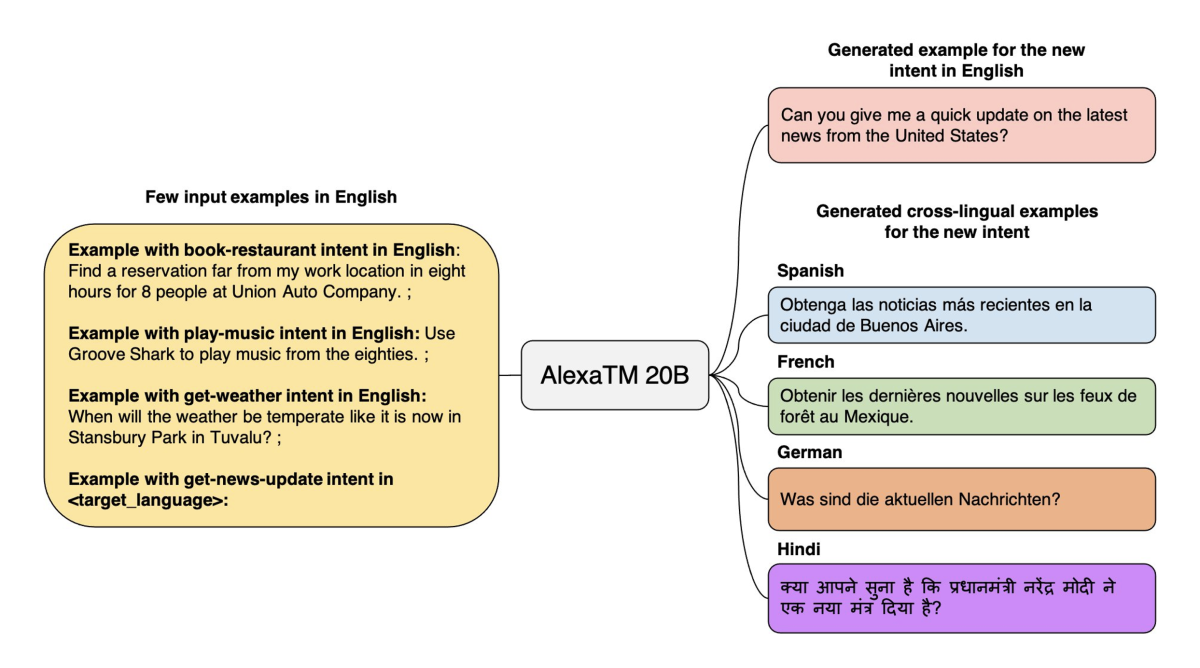
In the example below, the model is provided with three examples of different intents, or tasks that the customer wants executed: book-restaurant, play-music, and get-weather. The model can generalize from these to the unfamiliar intent get-news-update and generate utterances corresponding to that intent in different languages. This allows us to develop new features more rapidly, and in multiple languages, simultaneously.
Our work is inspired by the recent work by OpenAI and development of GPT-3 model. However, where other large language models use decoder-only architectures, AlexaTM 20B model is a sequence-to-sequence (seq2seq) encoder-decoder.
In an encoder-decoder architecture, the encoder produces a representation of an input text using a bidirectional encoding, and the decoder uses that representation to perform some task — historically, generating translation of the input.
By contrast, the decoder-only model uses left-to-right (unidirectional) encoding of the input text. This works well for language modeling, in which the task is to predict the next token in a sequence based on those that precede it, but it’s less effective for machine translation and text summarization, the tasks on which AlexaTM 20B outperforms GPT-3.
AlexaTM 20B also tops GPT-3 by being multilingual, supporting Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu. And its carbon footprint during training is only one-fifth of GPT-3’s, thanks to its lower parameter count and internal improvements to our training engine.
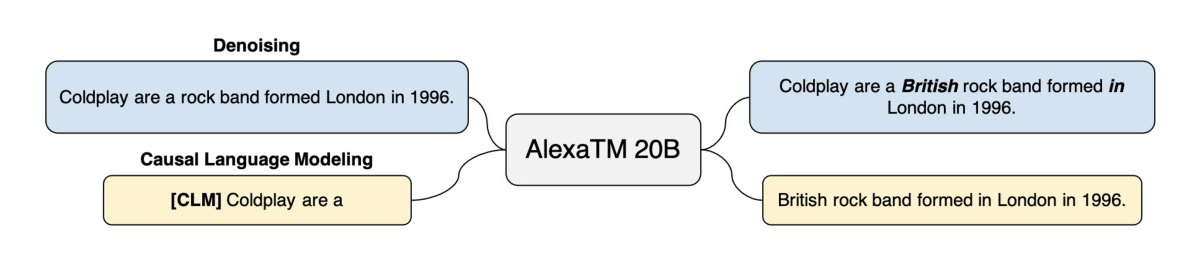
To train AlexaTM 20B, we break with convention, training on a mix of denoising and causal-language-modeling (CLM) tasks. On the denoising task, the model is required to find dropped spans and generate the complete version of the input. This is similar to how other seq2seq models like T5 and BART are trained. On the CLM task, the model is required to meaningfully continue the input text. This is similar to how decoder-only models like GPT-3 and PaLM are trained.
Training on a mix of these two pretraining tasks enables AlexaTM 20B to generalize based on the given input and generate new text (the CLM task), while also performing well on tasks that seq2seq models are particularly good at, such as summarization and machine translation (the denoising task).
For example, we demonstrated that, given a single article-summarization pair, AlexaTM 20B can generate higher-quality summaries in English, German, and Spanish than the much larger PaLM 540B can (see example, below).
Moreover, AlexaTM 20B achieves state-of-the-art performance in few-shot machine translation (MT) across almost all language pairs supported by the model on the Flores-101 dataset. The gains in translating to and from low-resource languages like Marathi, Tamil, and Telugu are particularly significant (e.g., 21.8 Arabic-to-Tamil sentence-piece BLEU score compared to 0.9 for the supervised M2M-124 615M model).
These results suggest that large-scale seq2seq-style pretraining, as formulated in our work, improves MT for languages with few training pairs, especially when a large amount of monolingual data is available for the target language. AlexaTM 20B has no difficulty translating directly from different languages, in contrast to many-to-many MT systems that require parallel translation data for training.

AlexaTM 20B is the largest multilingual seq2seq model to date that is also capable of few-shot learning. We will be releasing the model publicly for non-commercial use to aid the development and evaluation of multilingual large language models (LLMs). We have also implemented a function to enable loading the model on up to eight GPUs with limited GPU memory for running inference on instances of Amazon Web Services’ EC2 computation service. This provides a more flexible way for researchers to use AlexaTM 20B in their own work.
In an analysis reported in our paper, we found that AlexaTM 20B, like other LLMs, has some likelihood of reproducing toxic language, social biases, and harmful stereotypes found in its training data. Therefore, we recommend that users conduct a full task-specific fairness-and-bias analysis before using the model to fully understand and address any potential harm that might arise from its use. Depending on the downstream application that AlexaTM 20B is being applied to, one or several of the prior techniques from the literature might be used to detoxify and debias the model. We reiterate the importance of task-specific fairness auditing and emphasize the need for more research on bias measurement and mitigation from the community.
All in all, we demonstrated in our work that the proposed style of pretraining enables seq2seq models that outperform much larger decoder-only LLMs across different tasks, both in a few-shot setting and with fine-tuning. We hope our work presents a compelling case for seq2seq models as a powerful alternative to decoder-only models for LLM training.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK