

高性能计算与存储
source link: https://qiankunli.github.io/2022/07/28/hpc_storage.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

高性能计算与存储
2022年07月28日面向高性能计算场景的存储系统解决方案高性能计算场景存储需求的总结
| 高性能计算 | 接口 | 吞吐 | 延时 | IO类型 |
|---|---|---|---|---|
| 传统HPC | POSIX | 数十 GB/s 甚至数百 GB/s | 数百us | 以大文件为主,大量随机写,读写性能均重要 |
| AI HPC | POSIX,少量对象存储等接口 K8s CSI,GDS |
数十 GB/s 甚至数百 GB/s | 数百us | 大量的读 I/O,如果样本都很小,就是大量的小 I/O |
| 大数据 HPC | HDFS 或兼容 Hadoop 的存储接口HCFS | 数十 GB/s 甚至数百 GB/s | 对延时不是特别的敏感 | 以大文件为主,顺序读写,读写性能均重要 |
- 存储底座,整个高性能计算的过程实际上是分为很多个环节的,假如不同环节的数据分散在不同的存储系统上的话,对使用效率和使用方便程度上来讲,是一个比较大的挑战。所以百度内部使用了一个统一的存储底座来简化数据的管理和流转。存储底座的核心能力是高可靠、低成本、高吞吐。在这个统一存储底座的基础之上,会去支持一些高性能计算常用的接口需求,包括POSIX 文件接口以及 HCFS 大数据接口。一些对性能有更高要求的一些业务,愿意去做一些定制开发的话,它可以直接用存储底座提供的 SDK。
- 运行时存储,是近计算部署的,主要目的是为了让它们能够达到最好的 I/O 性能。解决和对象存储数据湖/底座之间的高效数据流转的问题,以及在调度平台上如何更简单地使用它们的问题。数据访问入口在 PFS或RapidFS,用户自己其实是不需要去关心数据到底是在对象存储还是在 PFS 里面。
AI HPC 中的存储问题
- AI HPC 实际上跟传统 HPC 相似的地方在于一个典型的计算也是分为很多轮。在每一轮计算中,不同的计算节点会去从存储系统把数据先预读上来,进行一些预处理,预处理完了之后由 GPU 来进行运算。在这个读的过程中,每个计算的节点其实只是负责了整个大的训练样本集合中的一小部分。这个读取工作实际上是通过训练框架内置的 Data Loader 机制来完成。整个过程中存在大量的读 I/O,如果样本都很小,就是大量的小 I/O。
- 在大规模的训练中,训练任务会周期性地做一些状态的保存,叫做 checkpoint,这里状态的保存主要起到故障恢复的作用。如果一个训练的耗费的时间非常长,在训练中间遇到一些机器故障重新做计算的代价就会很高。假如说有一些已经保存好的状态可以加载上来,接着这个状态把丢失掉的数据重新算一遍,这样会比完全重新计算要快很多。因此,在训练过程中产生的 checkpoint,可以减少需要故障恢复的数据量。这个过程以写 I/O 为主,在训练中的占比较小。
尽管越来越多的框架开始支持对象存储等接口类型,但这些接口形式使用门槛较高,被广泛接受还需要时间。文件接口依然是这个领域最主流的接口形式,被数据科学家、平台工程师、用户熟悉。在 GPU 训练中,读写存储系统工作通常是由操作系统内核来完成的。具体落实的时候是内核使用 CPU 先将数据拷贝到内存里,GPU 使用数据的时候再拷贝到显存中。硬件厂商如 NVIDIA 在探索的一个优化是让 GPU 直接去读取存储系统,从而减少 CPU 和 GPU 间的这一次拷贝开销,同时降低 CPU 使用率。这个技术叫 GPU Direct Storage(GDS),如果能够支持它的话,能够让 GPU 训练在数据读写速度方面有更好的表现。不过目前这个技术在业界使用得并不广泛,在未来它的发展前景怎么样,我们还有待观察。AI HPC 对存储接口的需求是 POSIX、K8s CSI,可选支持 GDS。
接口层面之外,不同的 AI 训练在负载方面有不同的特点,但是很多的 AI 训练会有海量小文件的需求。例如,在一些图片相关的训练中,每一个图片都很小,但是整个图片的样本集,假如展开来看的话会有非常多的小文件,一个样本集文件数多达几百万上千万都是有可能的。在整个的训练过程中,实际上对于那些样本集里的图片数据是不会做任何修改的,所以它对存储系统的 I/O 需求实际上是以读为主的。跟 HPC一样,为了读取的高效率,需要满足高吞吐和低延时的要求。此外,部分训练涉及到海量小文件的问题,海量小文件的特点就是元数据请求占比较高,存储系统的元数据性能至关重要。
- 首先在性能方面,我们会发现,这些计算对存储的需求,绝大部分情况下是发生在一批计算前面数据加载的阶段,和最后的数据保存阶段,这两个阶段如果存储性能跟不上的话,会导致 GPU、CPU 在那里等待,无事可做,空转浪费算力。GPU、CPU 在成本上来说是远高于存储成本的,存储一定要减少它们的等待时间。这些场景共性的要求是高吞吐,对一些 HPC 或者 AI HPC 的场景,还有额外的低延时要求。
- 第二点是文件大小的方面。这里面 AI HPC 场景比较特殊,它有海量小文件的需求,海量小文件实际上对整个存储系统的扩展性以及元数据性能方面的挑战是比较大的。
- 第三点是接口方面。到目前为止,POSIX 文件接口还是最主流的。HCFS 是 POSIX的一个子集,满足了 POSIX 要求后很容易开发 HCFS SDK。HPC 比较特殊,除了完整的 POSIX 兼容性之外,还需要去适配 MPI-I/O 框架。
- 第四点是对于所有存储系统的一个通用需求。对于非常重要的数据,我们有数据持久化要求,确保数据不会丢失。对于一些特殊的计算场景,这个要求可以放松,在一些多轮计算中,部分结果是中间生成的临时结果,这些临时结果可以通过计算重新生成。对于这些临时的结果,可以选择使用一些临时存储空间来存放,以换取更高的运算速度,更低的成本。这种临时存储空间需求在 HPC 和 AI HPC 中比较普遍,存储系统可以使用单副本来满足。
百度内部的高性能存储实践
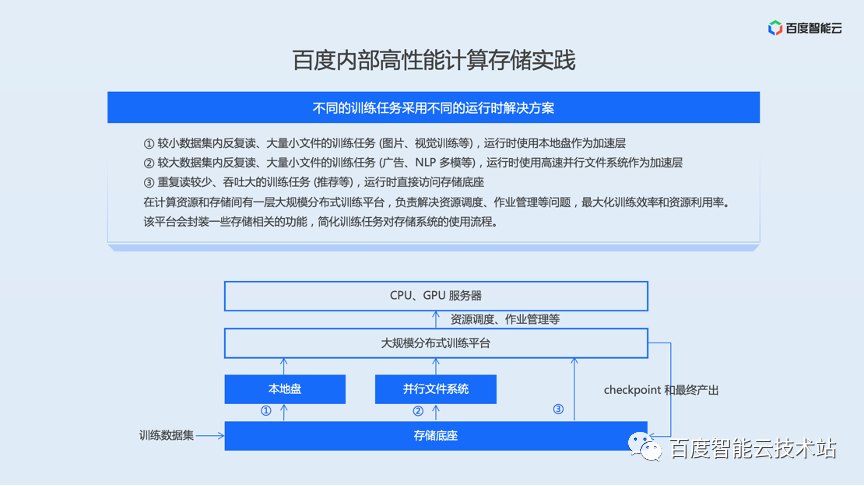
百度内部实践经验中,最核心的一点就是有一个统一的存储底座来做数据的流转中心。大家可以想一下,整个高性能计算的过程实际上是分为很多个环节的。比如说自动驾驶,要从很多的全国的道路采集路况信息,数据收集完了需要做一些预处理,例如给行人、机动车、交通标示牌做标注之类的。做完标注之后,才是真正的训练过程,训练完了之后会产生一些需要部署到生产系统上的模型,所以还要去做模型的管理、模型的部署。假如这些数据分散在不同的存储系统上的话,对使用效率和使用方便程度上来讲,是一个比较大的挑战。所以百度内部使用了一个统一的存储底座来简化数据的管理和流转。在这个统一存储底座的基础之上,会去支持一些高性能计算常用的接口需求,包括POSIX 文件接口以及 HCFS 大数据接口。一些对性能有更高要求的一些业务,愿意去做一些定制开发的话,它可以直接用存储底座提供的 SDK。
到了关键的训练环节,也就是计算环节,百度内部采用了不同的运行时解决方案来满足业务多样化的诉求,主要分为两类:
- 第一类解决方案解决 AI 训练中存在的海量小文件问题。对于存储底座来说,它首先要保证的是高吞吐和低成本,会采用一些相对比较廉价的存储介质,虽然单个设备的能力较差,但规模上来之后就有了规模效应,可以提供很大的吞吐。但这也导致它在处理小文件的时候,在元数据方面以及 I/O 方面的性能是不太理想的,这个时候就需要有一些速度更快的解决方案作为弥补。在百度内部,根据数据集的大小,业务可以有两种选择,包括本地盘和并行文件系统。
- 如果数据集比较小,计算节点的本地盘足够放下整个数据集,那训练任务完全就可以把数据先存到本地盘上,然后基于本地盘来做计算。
- 在另外一些场景下面,本地盘的大小远远不够存放下整个数据集,那这个时候就需要一个规模更大的共享文件系统来做这个事情,这是并行文件系统要解决的问题。这个并行文件系统会有自己独立的集群,多租户共享,支持 RDMA 网络、NVMe SSD,软硬件都做了很多的优化,来保证在海量小文件场景下,能够有比较好的元数据性能和 I/O 性能。
- 第二类解决方案针对那些训练时长非常长、重复较少的一些训练,这类训练主要的要求是能够把数据源源不断地从存储底座读取出来,吞吐比延时更重要。这个时候很多业务的选择就是去直接访问存储底座,利用存储底座比较好的高吞吐能力,来服务计算。
在整个使用过程中,还面临一些关键的使用问题。例如,数据怎么在不同系统(存储底座和并行文件系统、存储底座和本地盘)之间做流转;在使用的过程中,怎么简化不同类型存储的挂载、卸载和初始化、容量分配等工作。
在百度内部实践的基础上,孵化出了百度沧海存储在高性能计算领域的整体解决方案。由大容量、高吞吐、低成本的存储底座,和更快的运行时存储 PFS、RapidFS 组成。
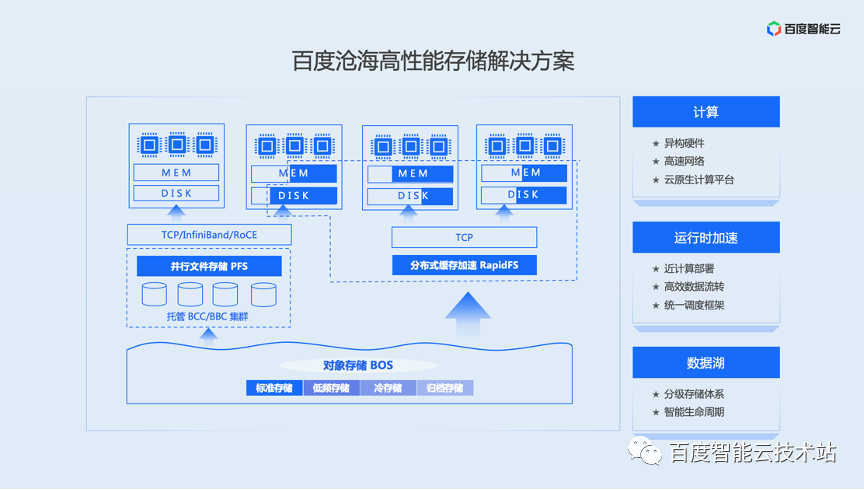
- 对象存储作为存储底座:对象存储已经是业界共识的云上数据湖的事实标准,满足存储底座的所有条件,百度智能云的对象存储 BOS 还具备分级存储和智能生命周期能力。这两个能力可以让数据根据访问频次等条件,自由地在不同成本的层级间流转,达到整体成本最优的状态。举个例子,现在经常要使用的一些数据可以放到标准存储里面,这样的话它在访问的时候速度是比较快的,随着这些数据逐渐转冷,可能很长时间都不会再用到,那就可以把这些数据通过生命周期策略,自动地往更低频、更廉价的存储分级去沉降,最后可以一直沉降到磁带介质的归档存储上,以此来达到一个访问性能、成本之间比较好的均衡。
运行时存储 PFS、RapidFS 的最大特点就是这两个产品是近计算部署的,主要目的是为了让它们能够达到最好的 I/O 性能。
- PFS 是一个典型的并行文件系统,和业界的 Lustre、GPFS 这些系统在架构上是比较接近的。系统主要的一个特点就是整个 I/O 路径会非常的短,请求从内核态客户端出来之后,根据它的类型的,是元数据的请求还是 I/O 的请求,直接发给对应的元数据节点 MDS 或者数据节点 OSS 处理。这样,对于读 I/O 来说,I/O 路径只有一跳。这个是软件架构上的性能保证,在硬件上我们同样有一些保证。PFS 采用托管架构将系统部署到用户 VPC 的虚机或物理机上,让它在整个物理网络上和计算节点离得非常近,这里的物理网络可能是 RDMA 或高速 TCP。PFS 通过这些软硬件上的多重保证,来确保整个系统的性能是比较高的。
- RapidFS的定位是一个缓存加速系统,原理是将用户计算节点上的冗余资源,组织成一个小的 P2P 缓存来加速计算。RapidFS 加速的能力主要来自于两个方面:
- 第一个加速效果来自层级命名空间(namespace)。命名空间在存储系统里负责组织文件和目录之间的关系以及保存属性信息,文件系统的元数据也是指这一部分。层级命名空间是 POSIX 使用的命名空间形式,就像一棵倒挂着生长的树,从根目录开始,每一个文件或目录都属于一个父目录。平坦命名空间是对象存储使用的命名空间,文件和目录彼此是平等独立的,不存在父子关系,这个设计可以让命名空间的扩展性能更好。对于用户来说,想要通过 POSIX 的方式(这是很常见的用法)去访问对象存储,会有很大的元数据操作的放大。为了解决这个问题,RapidFS 内置了一个高效的层级命名空间,来做 BOS 命名空间的缓存。
- 第二个加速效果来自数据缓存。针对于 BOS 上数据访问比较慢的问题,RapidFS 将比较热的数据缓存到用户提供的冗余内存和磁盘上面,这样等用户去访问的时候,访问路径很短。
有了这两类运行时存储之后,需要解决怎么在这两个系统和存储底座之间做数据流转的问题。实际上我们是通过两种机制来满足的:
- 第一种机制是生命周期,在一些场景如 HPC 中,业务的整个访问入口主要是文件系统,也就是 PFS。很多数据在 PFS 里产生之后,逐渐转冷,PFS 可以通过生命周期的功能,把近期内不再使用的数据,自动地转移到对象存储里面,让用户能够把成本降下来。用户去访问的时候,PFS 又把数据自动地给加载回来。这样用户自己其实是不需要去关心数据到底是在对象存储还是在 PFS 里面,他只需要关心哪些目录需要开启生命周期功能。在我们的规划里,RapidFS 后续将推出的 Block 模式也具备类似的能力,访问入口在 RapidFS,热数据缓存在计算节点本地,数据的持久化和冷数据由对象存储负责。PS:数据访问入口在 PFS或RapidFS
- 另外一个机制是 Bucket Link。Bucket Link 的数据流走向跟生命周期正好是反向的。很多情况下,用户的数据实际上已经在对象存储里面了,例如自动驾驶这样的业务,它的数据是线下采集的一些路测数据,这些数据通过对象存储服务提供的工具上会传到对象存储里,训练时候的数据源实际上就是对象存储。但如果想要用 PFS 或者 RapidFS 来支撑训练,就需要高效地把数据搬过来。Bucket Link 要解决的就是这个问题,它本质上是将数据搬运的能力内置到了存储系统里面,用户只要通过一个很简单的命令,或者说一个界面的操作,就能够把 PFS 的一个目录或者 RapidFS 的一个命名空间,和对象存储里面的一个路径做一个绑定,这个绑定就是 Bucket Link。绑定后,PFS 和 RapidFS 可以自动地帮用户完成数据的加载,以及数据的预热。这样等到用户训练真正开始运行的时候,PFS 和 RapidFS 里的数据已经准备好了,任务直接可以运行。
- 统一调度,业界有一个开源项目叫 Fluid,它可以将整个训练的过程分成了两个阶段,一个阶段是用来做数据加载,另外一个阶段才是用来做真正的训练。这两个阶段拆分之后,在不同的任务之间 pipeline 并发起来。举个简单的例子,整个系统可能只有四张 GPU 卡,A 训练跟 B 训练都需要去用这四张卡来做训练,那在 A 训练跑 GPU 任务的时候,完全可以让 B 训练提前做数据预加载的工作,将数据提前预热到 PFS 或者 RapidFS 里。等到 A 训练任务完成的时候,就直接可以让调度器把 B 训练跑起来了。整体上看到的效果就是 B 的数据加载阶段被隐藏掉了,加载过程跟计算过程分阶段 pipeline 化了。对于那些训练任务很多的用户,GPU 等待时间变少了,利用率得到了很大的提高。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK