

操作系统之虚拟内存总结 - 之一Yo
source link: https://www.cnblogs.com/zhiyiYo/p/16539771.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

操作系统为每个进程提供了一个假象:它拥有属于自己的大量的私有内存,可以有巨大的连续地址空间放入自己的代码和数据。用户程序中访问的地址都是虚拟地址,需要经过操作系统和硬件的协同工作将这个虚拟地址翻译为物理地址,找到想要的信息。之所以提供这样的假象,是为了隔离和保护,没有人会希望一个恶意进程随意修改别的进程的代码和数据。
动态重定位
在介绍现代操作系统使用的地址转换机制之前,我们先来看一个简单的地址转换方法——动态重定位。这个简单的方法建立在一些假设之上:
- 用户的地址空间必须连续地放在物理内存中
- 地址空间不是很大,具体来说,小于物理内存的大小
- 每个地址空间的大小完全一样
后面会逐步放宽这些假设,不过为了让动态重定向工作起来,我们先勉为其难地接受这些假设。
动态重定位也称为基址加界限机制,这么叫的原因是,每个 CPU 需要两个硬件寄存器(放在内存管理单元 MMU 中):基址寄存器和界限寄存器,让我们能够将地址空间放在物理内存的任何位置,同时又能确保进程只能访问自己的地址空间。我们编译出来的程序虚拟地址空间从 0 开始,但是当程序跑起来的时候,操作系统会将程序的地址空间加上由基址寄存器所保存的偏移量,比如基址寄存器的值为 32KB,程序访问的虚拟地址为 1KB,那么实际访问的物理地址会是 33KB。我们接着假设物理内存为 64KB,每个进程的虚拟内存大小为 16KB,那么界限寄存器既可以存虚拟内存的大小 16KB,也可以存进程在物理地址空间的结束位置,如下图所示的 48KB。当程序中访问的虚拟内存超过界限寄存器规定的范围时,会引发越界错误,操作系统可以杀死该进程。

现在站在一个高层次来观察动态重定位,它其实就是将物理内存进行 N 等分出 N 个大小为虚拟内存大小的槽,每个进程会对应一个槽。这种方法的优点很明显,就是简单且快速。但是缺点也很明显,如果我们程序实际只占用了 4KB 的空间(堆和栈之间有一大段空间没被使用),你却给他分配了 16KB,这就造成内部碎片,有 12KB 的物理内存被白白浪费了,而别的进程却无法使用。
为了解决动态重定位中的内部碎片问题,我们放宽第一个假设,不再要求用户的地址空间必须连续地放在物理内存中。我们对虚拟地址空间进行分段,比如代码、堆和栈各一段,如下图所示,每个段只占用了 2KB,进程只占用了 6KB 的物理内存:

为了支持分段,MMU 中现在不止一对基址加界限寄存器,而是需要三组。这种分段方法带来了一个问题:给定一个虚拟地址,如何判断该地址所属的段?如果我们不知道所属的段,就无法访问正确的基址寄存器和界限寄存器。一种可行的判断方法,是对虚拟地址进行切分,比如虚拟地址 4200,它处于堆中,我们将地址的高二位解释为地址所属段的编号(00 为代码,01 为堆,10 为栈),剩下的位就是在段内的字节偏移量:
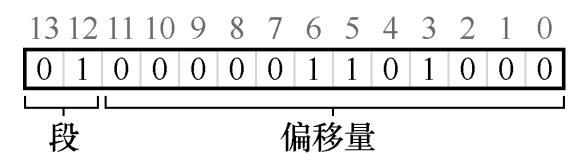
分段方法比较好地解决了内部碎片的问题,却又带来了一个新问题:每个进程的各个段大小可以不同,随着物理内存的不断切分,可能会出现许多较小的空闲空间,这些空间太小以至于无法被别的段所使用,即使所有空闲空间的总和大于段大小,也无法被利用,这种问题称为外部碎片。
分段中外部碎片的起因就是各个段的大小不一,如果我们同样对地址空间进行分割,分割出来的每个页(或者称为块)固定大小,比如 4KB,这样就不会有外部碎片的问题了。然后我们在虚拟内存页和物理内存页之间建立一个映射关系,比如下图中(虚拟页 0→物理帧 3)、(VP 1→PF 7)、(VP 2→PF 5)和(VP 3→PF 2),我们将每个进程的这种映射关系保存在一个数据结构中,称为页表。

有了页表之后,每次要想知道虚拟内存在哪,只要去内存中查下表就行了(页表地址由 CR3 寄存器给出),听起来貌似很简单,但是和分段类似,为了知道虚拟页对应的物理帧的编号记录在页表的哪个条目上,我们需要对虚拟地址进行切分。
如下图所示,虚拟内存大小为 64B(6 位),物理内存大小为 128B(7 位),每个虚拟页的大小为 16B,所以我们可以将虚拟内存分为 4 页,对每个虚拟页进行编号需要 2位,每个页 16B 需要 4 位的偏移量来描述,加起来正好 6 位。所以我们将虚拟地址的高二位解释为虚拟页号(VPN),剩下 4 位解释为页内偏移量。
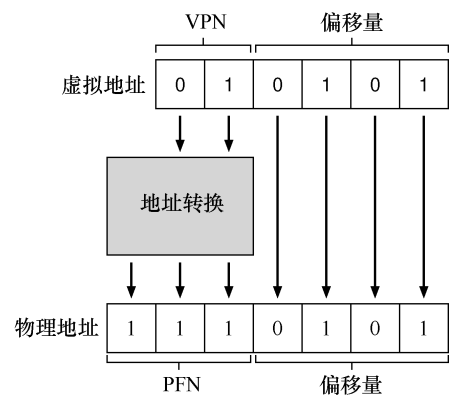
现在假设我们的页表只是一个线性数组,我们使用 VPN 对该数组进行索引,得到一个页表条目(PTE),一个 32 位 x86 页表条目结构如下图所示:

每个条目会有几位对应物理页号(PPN 或 PFN),回到我们的例子中就是会有 3 位对应物理页号(0b111),将 0b111 和偏移量 0101 进行拼接就得到了物理地址 0b1110101。
分页机制虽然好用,但是也存在着一些问题。
第一个问题就是页表大小。假设我们虚拟地址 32 位,页大小为 4KB,我们就需要将虚拟内存切为 232/212=220232/212=220 个虚拟页,为了保存这些页的映射关系,我们的页表的长度也得是 220220,如果每个 PTE 的大小是 4B,光是保存一个进程的页表就得占用 222222 字节(4MB),如果有 100 个进程就得占用 400MB 的物理内存,这显然是无法接受的。
第二个问题就是翻译速度。由于页表保存在内存中,每次对虚拟地址的转换(包括指令获取、数据载入和保存)都得进行一次内存访问,程序执行速度变成了原来的一半。
先来解决第二个问题,参考缓存的思想,我们可以将经常访问的映射关系放在一个特殊的缓存硬件中,每次进行地址转换的时候都先去查询 VPN 对应的 PFN 在不在缓存硬件里面,在的话就皆大欢喜,不在就得老老实实去找页表要了。
这样的一个硬件称为地址转换旁路缓冲存储器,简称 TLB。TLB 中保存的每个条目结构为 VPN | PFN | 其他位,其他位中可以包括有效位、保护位、脏位和地址空间标识符,各个位的含义这里不再赘述。
接着解决第一个问题,页表太大的原因,在于我们将所有映射关系保存在一个页表中,即使有的映射关系并不存在,也得在页表中占一个位置。如果我们能对一个页表进行拆分,拆成一个页目录和多个实际保存映射关系的页表,页目录中的每一个条目指向一个页表,不存在实际映射关系的页表可以不被分配内存,这样就能节省很多空间,如下图右侧所示。
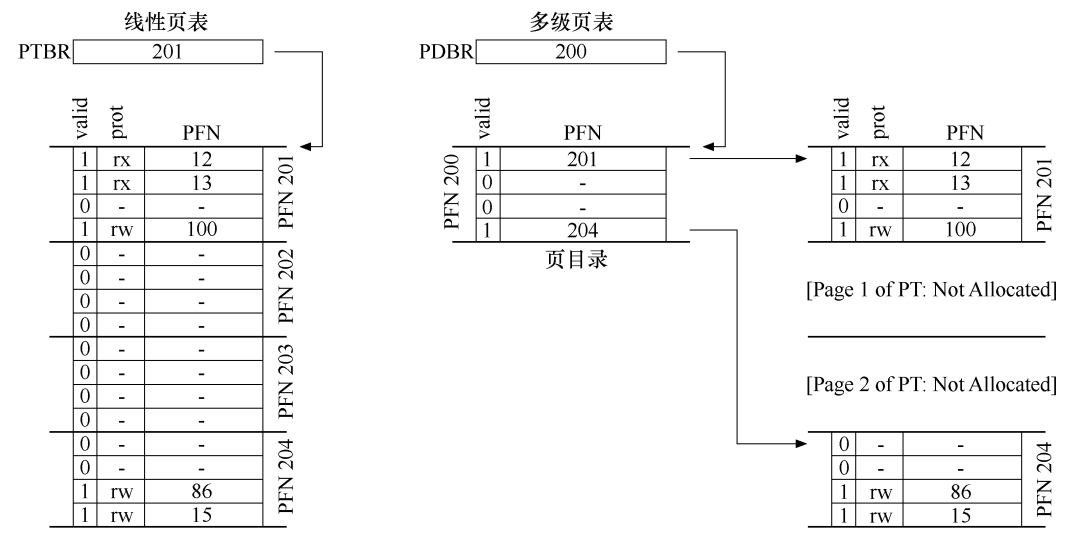
为了支持二级页表,我们需要对虚拟地址的 VPN 部分进行细分。假设我们的虚拟地址空间为 16KB(14 位),页大小为 64B,PTE 大小为 4B,为了完成映射,线性页表中需要有 214/26=256214/26=256 个 PTE,共占用 1KB 空间。现在每个页可以容纳 64/4=1664/4=16 个 PTE,如果将页表拆成 256/16=16256/16=16 个小页表,对这些小页表进行编号需要 4 位,每个小页表中保存的 PTE 编号也需要 4 位,剩下 6 位作为页内偏移量。
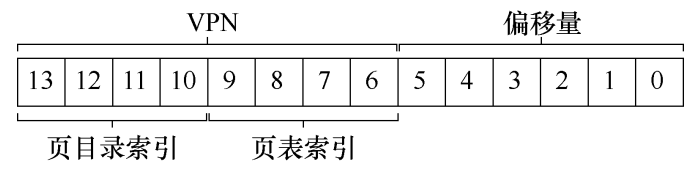
假设虚拟地址为 0b11111110000000,由于前四位为 0b1111,所以对应的页表编号为 15(最后一个页表),接下来四位为 0b1110,说明 PTE 在此页表的倒数第二个,假设这个 PTE 告诉我们 PFN 为 55(0b110111),由于偏移量数 0,那么物理地址就是 0b00110111000000。
现在来思考一个问题:如果系统有许多个进程,他们把物理内存给榨干了,这时候又来了一个新的进程,它要求系统给它分配几个页来保存代码,但是现在内存满了,该怎么办?
解决这个问题的思路,就是在硬盘上开辟一部分空间,称为交换空间,用于物理页的移入和移出。需要从物理页中挑出一个受害者,把它暂时保存到交换空间中,这样才能腾出空间给新进程。等到进程要用到这个被换出的页时,就从硬盘中重新加载它。挑选受害者的方法有很多,比如先入先出、随机挑选和 LRU 算法,由于 LRU 算法需要维护的信息比较多,所以可以采用时钟替换算法来近似,这里不再赘述。
虚拟内存还有许多知识点这里没有写到,大家可以阅读《操作系统导论》中的相关章节来自行学习。《操作系统导论》采用循序渐进的写法,由易到难,将虚拟内存的面纱一层层解开,比起《深入理解计算机系统》中直接抛出一大堆虚拟内存概念而言,《操作系统导论》的写法更符合人类的认知过程,因此墙裂推荐这本书,以上~~
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK