

关于Request复用的那点破事儿。研究明白了,给你汇报一下。 - why技术
source link: https://www.cnblogs.com/thisiswhy/p/16539739.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

关于Request复用的那点破事儿。研究明白了,给你汇报一下。
你好呀, 我是歪歪。
之前不是发布了这篇文章嘛:《千万不要把Request传递到异步线程里面!有坑!》
说的是由于 Request 在 tomcat 里面是复用的,所以如果在一个 Request 的生命周期完成之后,在异步线程里面调用了相关的方法,会导致这个 Request 被污染,然后在下一个请求中观察到一些匪夷所思的场景。
但是文章的评论区里面出现了个问题,还一下把我问住了:

由于我那篇文章关注的重点是把 Request 传递到异步线程这个骚操作,并没有特别的关注 Request 到底是怎么复用的。
我只是通过打印日志的方式去观察到了复用的这个现象:
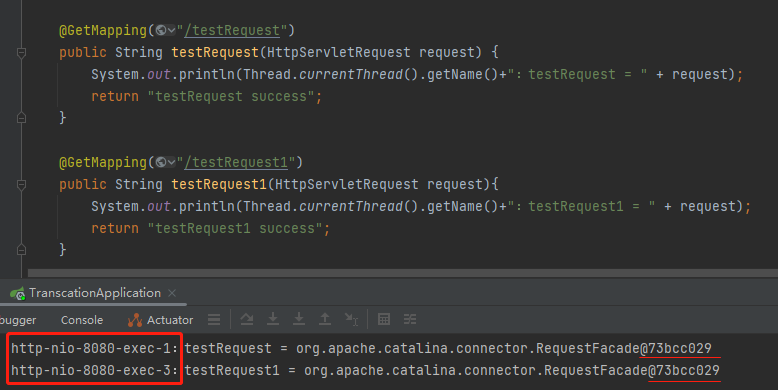
把项目启动起来之后,分别访问 testRequest 和 testRequest1,从控制台的输出来看,Request 对象确实是一个对象。
但是从前面的线程名称来看,这是线程池里面两个完全不同的线程。
所以,虽然我还啥都没分析呢,基于日志就至少能看出这个问题的答案:
复用的request是和线程绑定的吗?
不是,没有绑定关系。
如果不是和线程绑定,那么问题就随之而来了:
如何决定哪个线程每次复用哪个request呢?
这是个好问题,我也不知道答案,所以我决定来盘一盘它。
但是在盘它之前,我们先想个问题:假设 Request 和请求线程绑定在一起了,这是一个合理的设计吗?
肯定不是的。
线程就应该是单纯的线程,不应该给它“绑定”一个 Request。这种绑定让线程不单纯了,线程和请求耦合在一起了。
好一点的设计应该是 Request 放在一个“池子”里面,来一个线程就从池子里面去取可以用的 Request。
这样可以实现线程和请求之间解耦的效果。
当然,这也只是我在进行探索之前的一个假设而已,先放在这里,最后看看这个猜想是否正确。
看这篇文章不需要你对 Tomcat 有多少了解,会用它就行,很多东西都是可以基于源码推理出来的。
对了,说一下 Tomcat 源码版本:9.0.58。
第一个断点
要找到问题的答案肯定得去翻源码,但是从哪里开始翻呢?
或者换个问题:第一个断点打在哪呢?
遇到这个问题我的第一反应还是从日志里面看看能不能找到相关的线索,从而找到打第一个断点的位置。
但是我分别把日志调整到 DEBUG 级别和 TRACE 级别,均没有发现有价值的信息,所以日志这条路感觉走不通了,怎么办?
不慌,这个时候就要冷静分析一下了。

悄悄的问自己一句:我可以把断点打在方法入口处吗?
当然可以了,这也是能想到的一个非常常规的手段:

但是如果把断点打在这里,相当于从业务代码的第一行反向去推源码,把路绕的稍微远了一点。
那么还可以把断点打在哪里呢?
我这里不是输出了 Request 这个对象的全类名吗:
http-nio-8080-exec-2:testRequest1 = org.apache.catalina.connector.RequestFacade@5db48dd3
RequestFacade,这个类能用,必然有一个 new 它的地方,而要 new 它,必定要调用它的构造方法。
那我是不是只要在其对应的构造方法上打个断点,当程序创建这个类的时候,不就是我要找的源头吗?
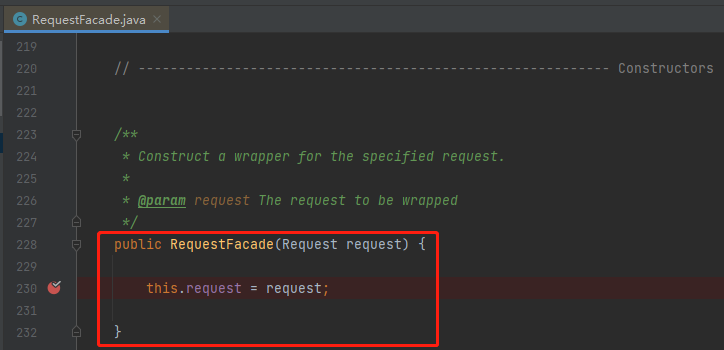
所以,我把第一个断点打在了 RequestFacade 的构造方法上。
从构造方法入手,这也是我的一个调试小技巧,送给你,不客气。
有的小伙伴就要问了:如果一个类有多个构造方法怎么办呢?
很简单,大力出奇迹,每个构造方法都打上断点,一定会有一个地方触发的。

找到第一个断点的位置了,接下来就是把项目重启,发起调用了。
我连续发起了两次调用,从程序的表现上我就知道这个断点打对了。
我先给你上个动图,你就知道我为什么这么说了:

项目启动之后,第一次调用在断点的地方停下来了,接着第二次调用并没有在断点的地方停下来。
说明第二次确实没有新建 RequestFacade 对象,而是复用了第一次调用时产生的 RequestFacade 对象。
验证了断点打的位置没毛病之后,就可以开始慢慢的调试了。
首先,我们关注一下这个 RequestFacade 对象创建的地方:
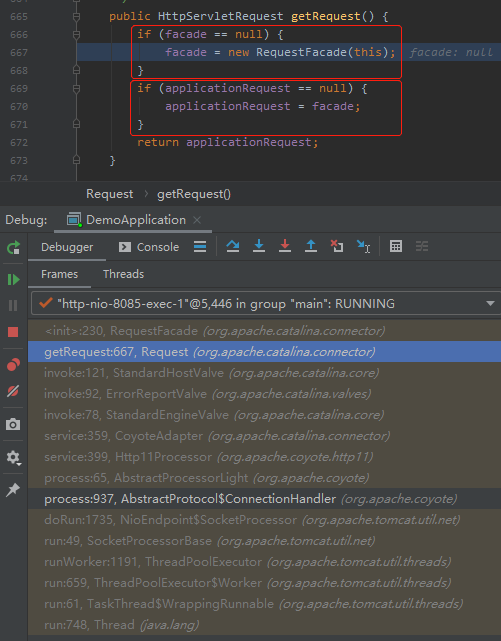
有两个 if 判断。
第一个是判断 facade 是否为 null,不为 null 就 new。
第二个是把 facade 赋值给 applicationRequest 对象,接着返回 applicationRequest 对象。
第二个 if 其实很有意思,你想啊,这里直接返回 facade 也可以呀,为什么要用 applicationRequest 来承接一下呢?
这是一个好问题。
这两个 if 的关键在于 facade 和 applicationRequest 是否为空。
第一次访问的时候肯定是空。那么后续什么时候又会变为空呢?
就是在一次请求结束,执行 recycle 方法的时候:
org.apache.catalina.connector.Request#recycle
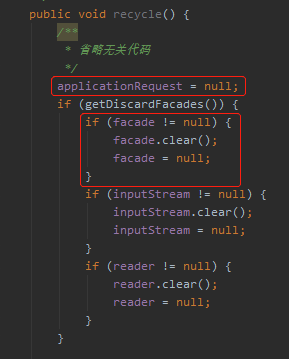
从源码中可以看到 applicationRequest 是直接设置为 null 的。
但是这个 facade 设置为 null 有个前提,getDiscardFacades 方法返回为 true。
这是个什么玩意?
看一眼就知道了:
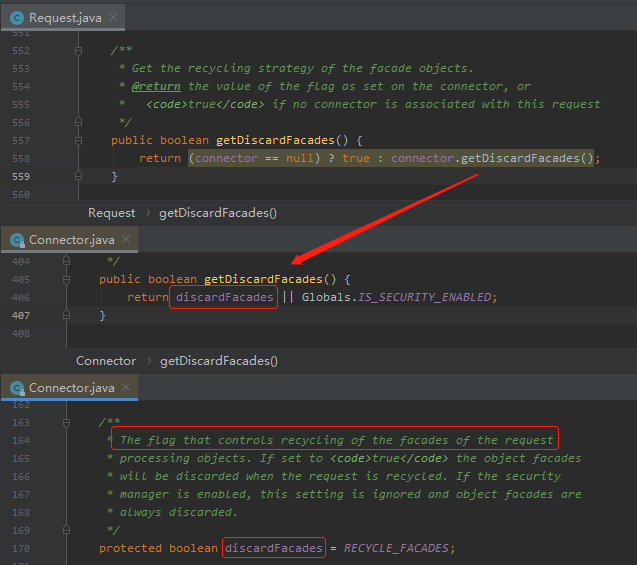
意思是 RECYCLE_FACADES 这个参数控制着是否循环使用 facade 这个对象,如果设置为 true 会提高安全性,而这个参数默认是 false。


也就是说我这个地方如果把这个参数修改为 true,facade 对象就会在每次调用完成之后进行回收。
可以通过启动参数JAVA_OPTS来配置:
-Dorg.apache.catalina.connector.RECYCLE_FACADES=true
从前面的源码中可以知道,在默认的情况下,applicationRequest 会在每次请求完成之后设置为 null,而 facade 会保留下来。
因此下一次请求过来的时候,facede 并不为空,直接复用 facade。把 facade 赋值给 applicationRequest。
所以我们在日志里面观察到的现象是两次请求输出的 facade 对象是一样的。
接着,我们继续看调用堆栈。
看创建 facade 的这个 getRequest 请求到底是谁在调用:

发现是一个 Request 对象在调用 getRequest 方法。
所以接下来要找的就是 Request 对象最开始是从哪个方法开始作为入参传递的。
顺着调用堆栈,可以找到下面这个地方:
org.apache.coyote.http11.Http11Processor#service
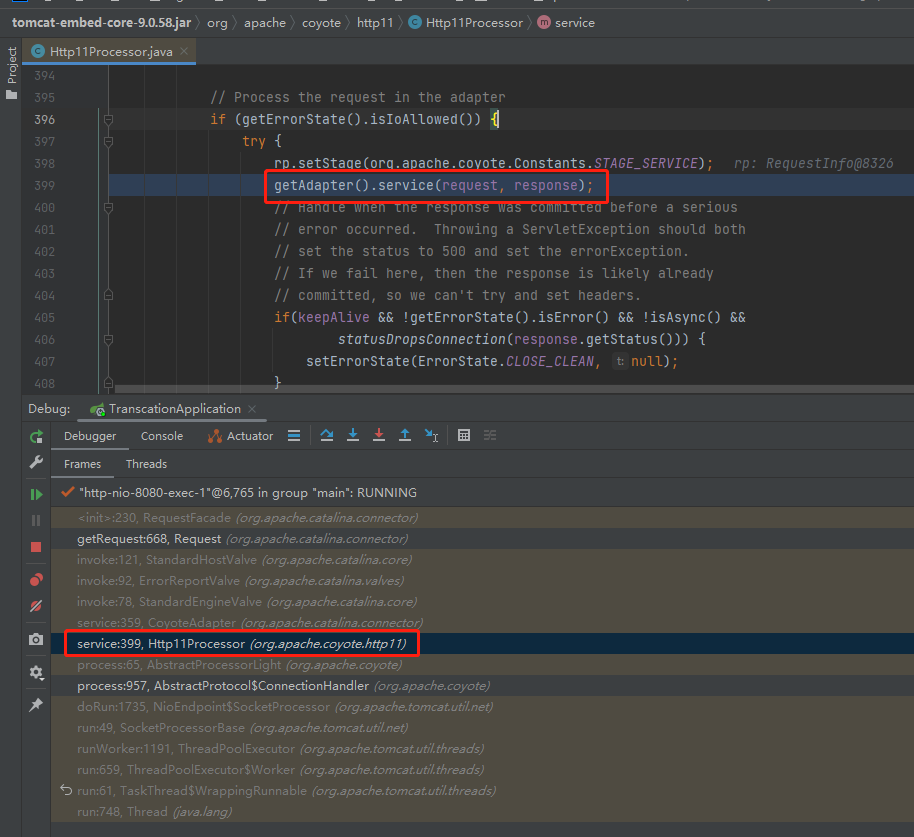
这就是 Request 对象最开始作为入参传递的地方。
那么这个 Request 对象是怎么产生的呢?
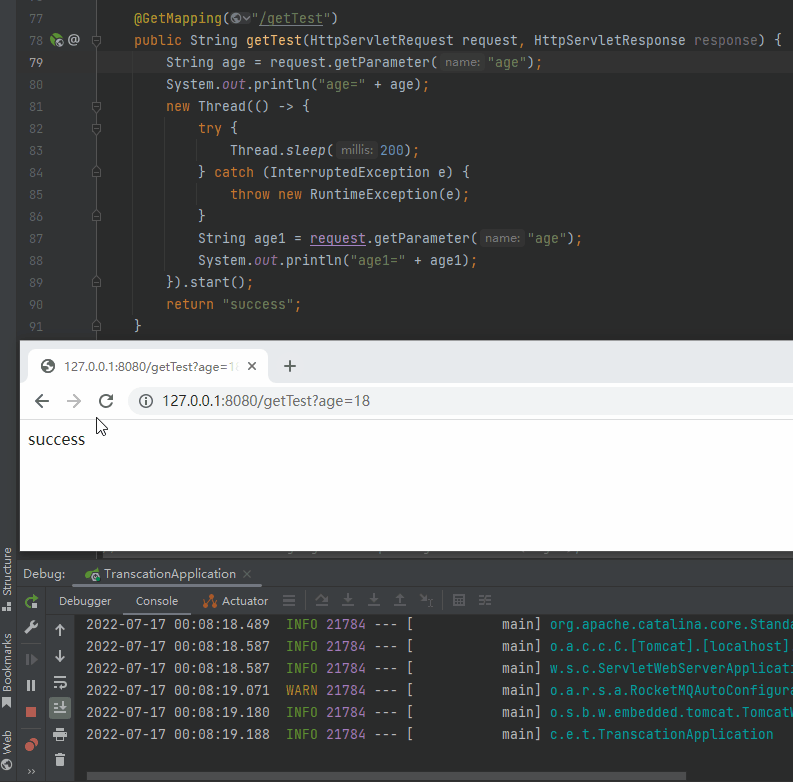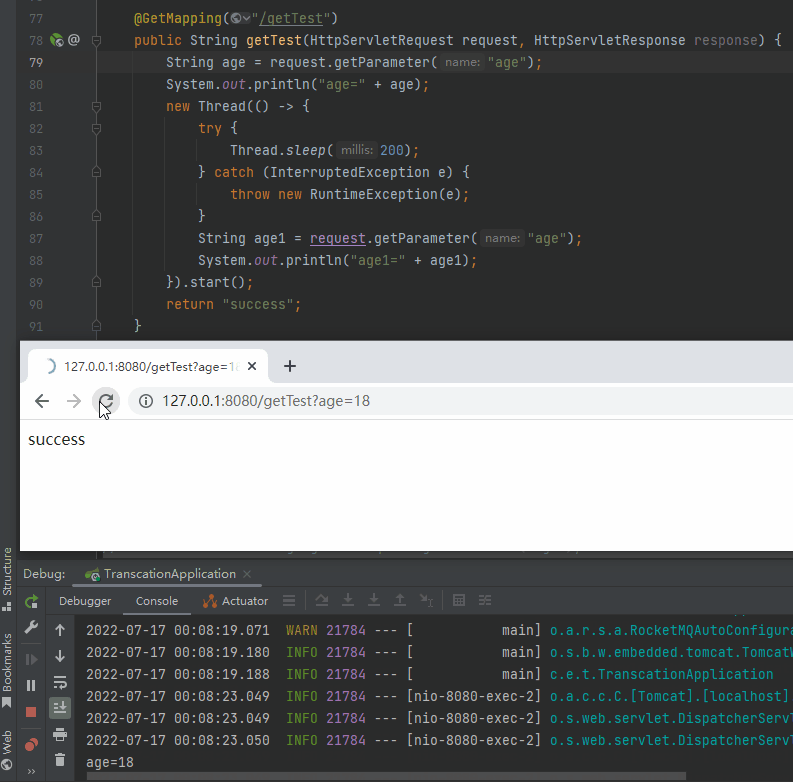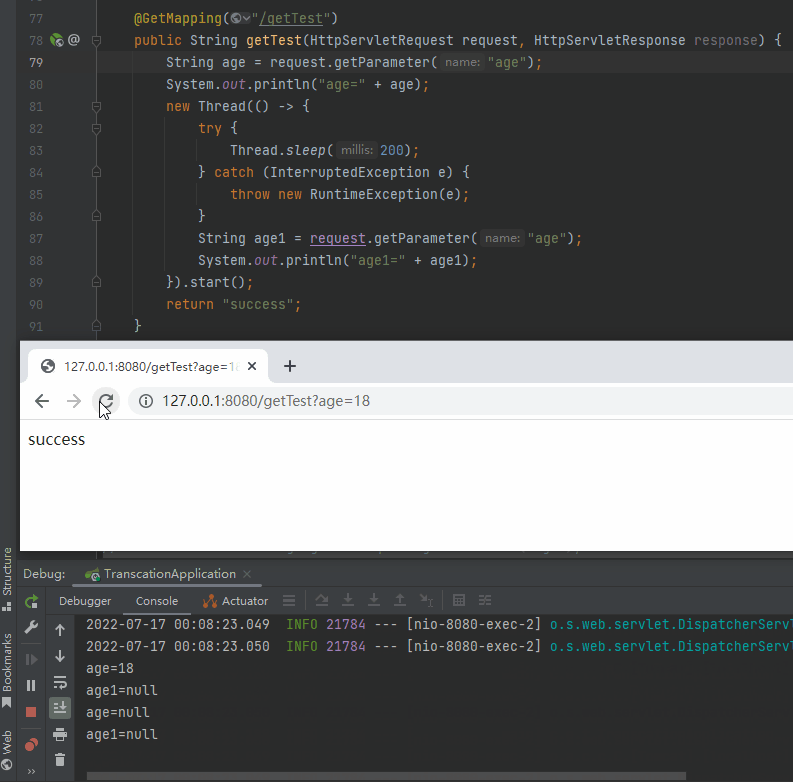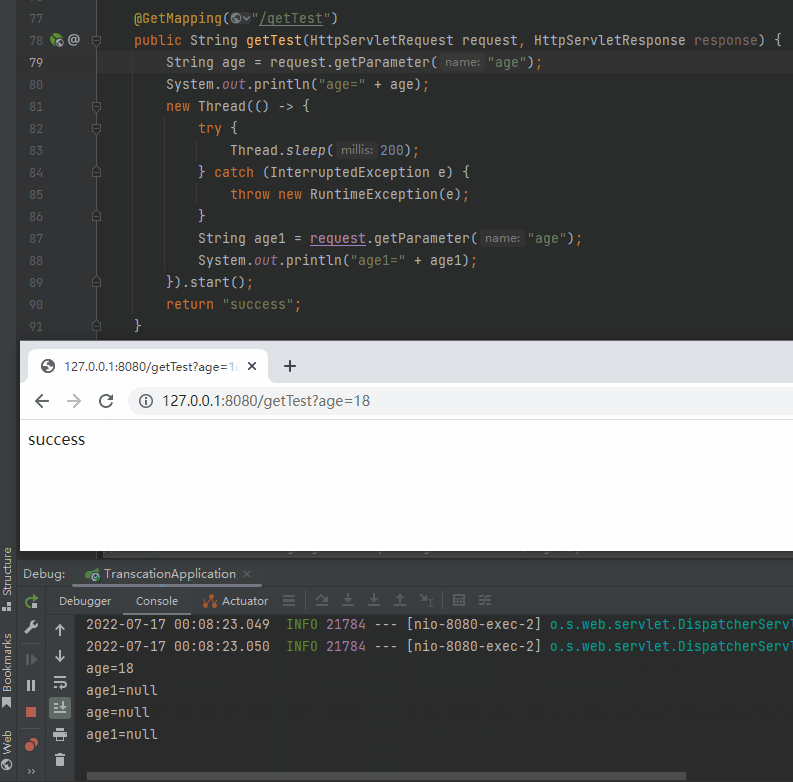
我也不知道。
所以,要知道这个问题的答案,第二个断点打的位置也就呼之欲出了:
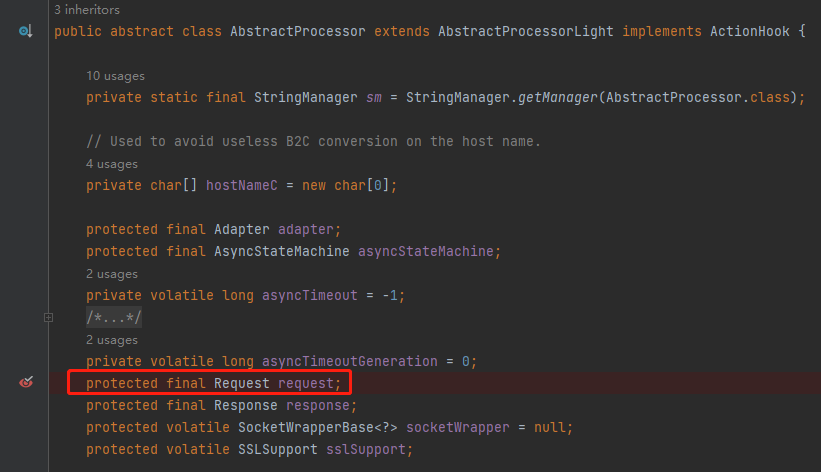
重启项目,发起请求,发现 Debug 停在了 AbstractProcessor 类的构造方法,这就是 request 最开始产生的地方,同时我们又收获了一个调用堆栈:
org.apache.coyote.AbstractProcessor#AbstractProcessor(org.apache.coyote.Adapter, org.apache.coyote.Request, org.apache.coyote.Response)

这个 Request 是怎么来的呢?
new 出来的:

为什么要执行这个 new 方法呢?
因为这个地方在 createProcessor:
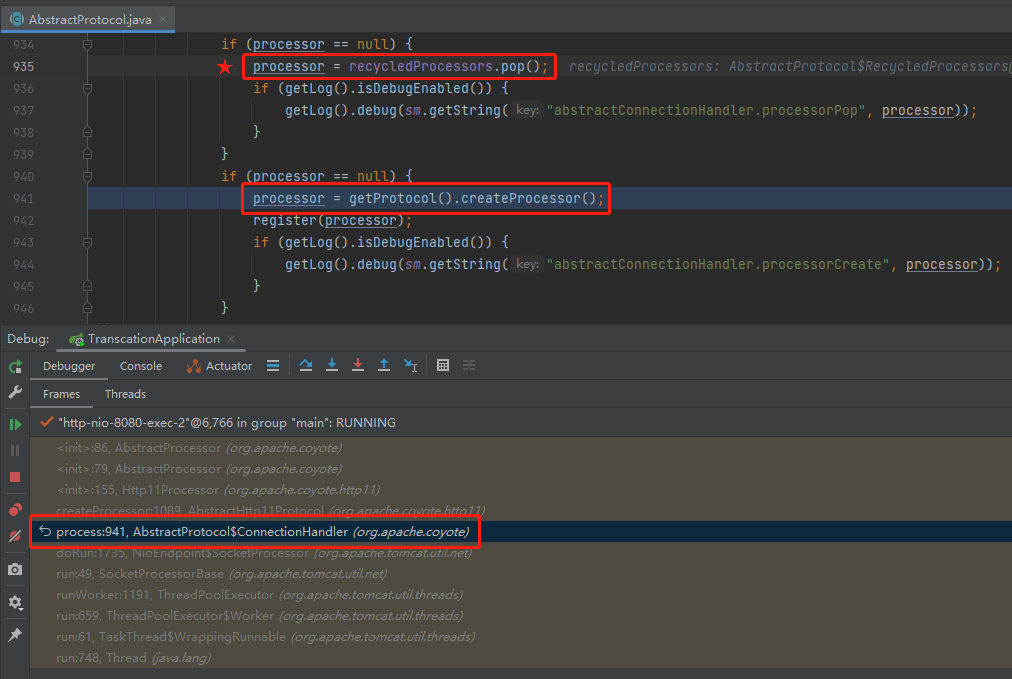
而我们要寻找的问题的答案,就藏在上面这个截图中。
准确的说,就藏在上面截图中,标记了五角星的地方:
processor = recycledProcessors.pop();
从代码的片段看,如果从 recycledProcessors 里面 pop 出的 processor 对象不为空,则不会调用 createProcessor 方法。
而从调试的角度看,不调用 createProcessor 方法,也就不会创建 RequestFacade 对象。
所以,recycledProcessors,这个玩意是华点、是真正的突破口。

这一小节,主要是分享一下我找到这个突破口的一个过程,两个关键的断点是基于上面考虑设置的。
其实你回想一下,这是一个非常顺其自然的事情,带着问题去调试源码是一件比较简单的事情。
不要怂,就是翻。
recycledProcessors
你看这个对象的名称,recycled + Processors,一看就知道里面有故事,有关于对象复用的故事。
org.apache.coyote.AbstractProtocol.RecycledProcessors
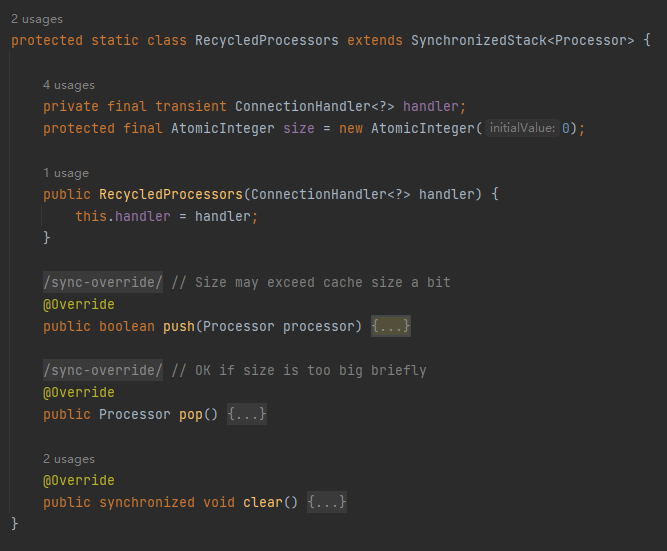
这个类的方法也特别简单,就三个方法:push、pop、clear。
继承至 SynchronizedStack 对象,就是一个标标准准的栈结构,只不过是用 Synchronized 修改了对应的方法:
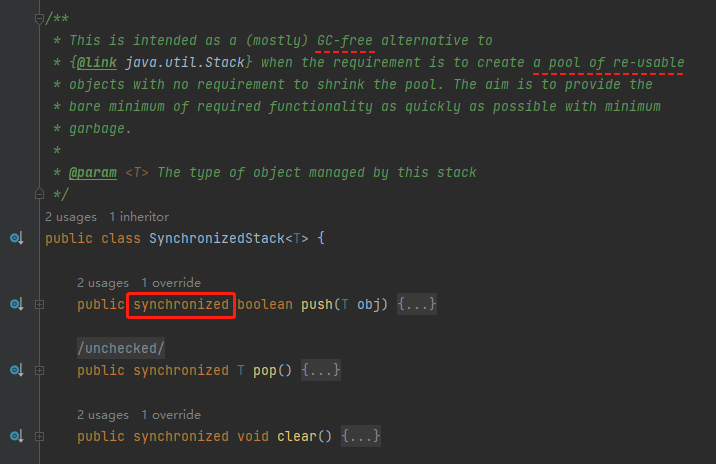
在 SynchronizedStack 类的注释上提到了这是一个对象池、这个对象池不需要缩容、目的是为了减少垃圾对象,释放 GC 压力。
现在我们找到了这个对象池,也找到了调用这个对象池 pop 的地方。
那么什么时候往这个对象池 push 呢?
我也不知道。
所以第三个断点就来了,可以打在 push 方法上:
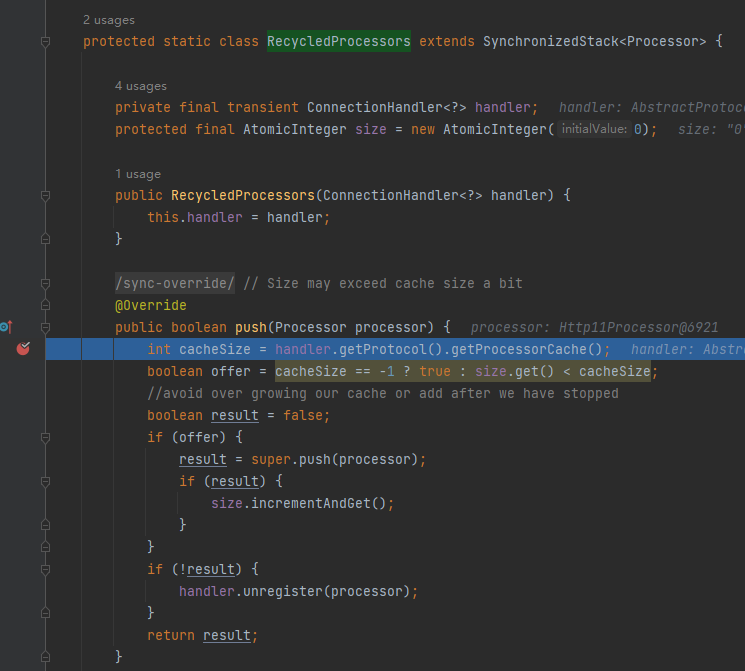
然后发起调用,发现是在请求处理完成,release 当前 processor 的时候,就把这个 processor 放到 recycledProcessors 里面去,等着下一次请求使用:
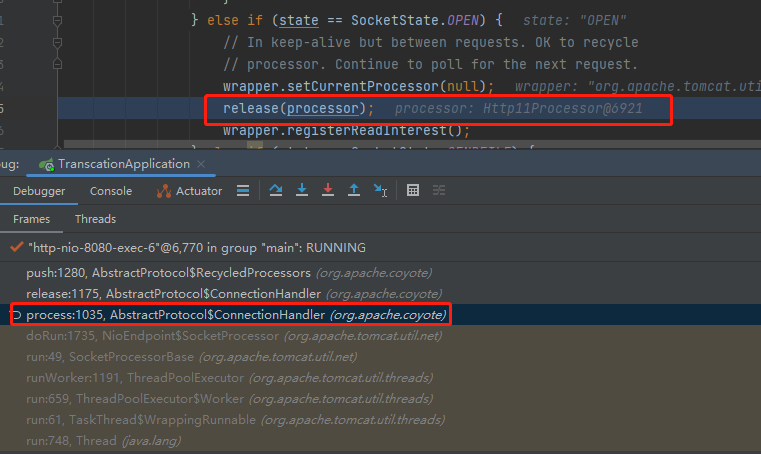
此时我们已经掌握了这样的一个闭环:
当请求来了之后,先看 recycledProcessors 这个栈结构里面有没有可用的 processor,没有则调用 createProcessor 方法创建一个新的,接着在请求结束之后,将其放入到栈结构里面。
而在调用 createProcessor 方法的时候,会构建一个新的 Request 对象,最终这个 Request 对象会封装为 RequestFacade 对象。
所以我现在想要验证 Processor、Request 和 RequestFacade 三者之间有这样的一个对应关系。

怎么验证呢?
打印日志。
注意,接下来又是一个调试小技巧了。

我想要在选定 processor 之后,加入一行输出语句:
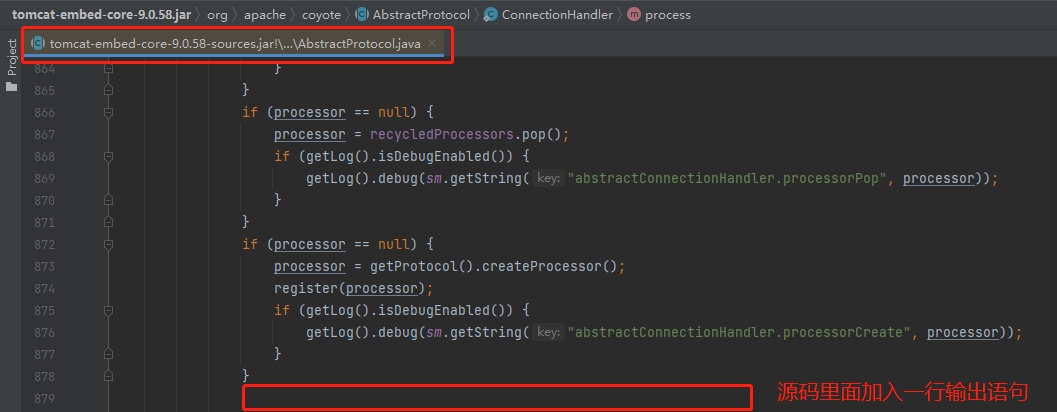
怎么加呢?
在自己的项目里面创建一个和源码一样的包路径,然后把对应的类直接粘贴过来:
因为是在自己的项目里面,你想怎么改都行:
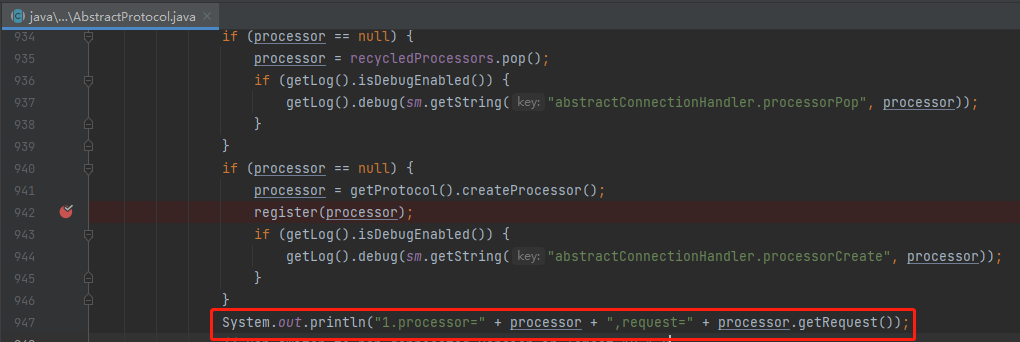
比如我加入这个输出语句,打印出 processor 和里面的 request。
发起请求之后你会发现确实生效了,但是 reuqest 的输出是这样的:
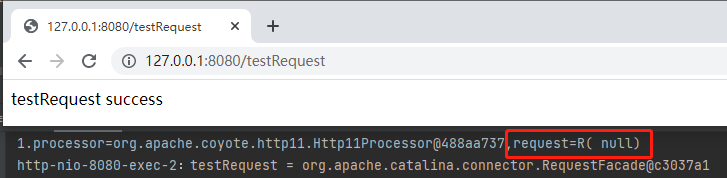
为什么呢?
因为在源码里面,这个类的 toString 方法被重写了:

改源码啊,刚刚才教你了的:
修改之后发起调用,就可以在控制台看到对应的预期的输出了:
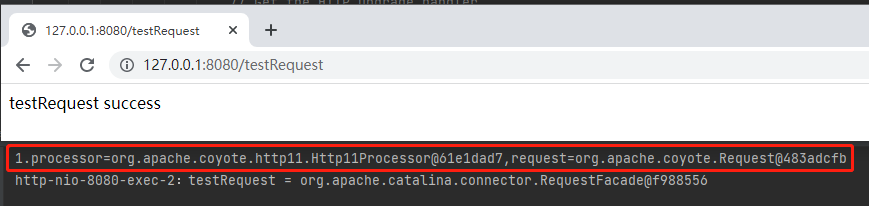
你看,processor 里面有个 request。现在我要找的是 request 和 RequestFacade 之间的关系。
很简单,在 getRequest 方法这里也输出一行:

发起调用之后,发现,完犊子了:

这两个 Request 根本就不是同一个玩意啊:
org.apache.coyote.Request@667cbb30
org.apache.catalina.connector.Request@9ffc697
不要慌,冷静下来细嗦一下,虽然这是两个不同的 Request,但是它们之间一定有着千丝万缕的联系。

先看一下 org.apache.catalina.connector.Request 是怎么来的,老规矩,构造方法上打断点:

基于这个调用堆栈,往前找一点点,就能看到一个值得注意的地方:
org.apache.catalina.connector.CoyoteAdapter#service
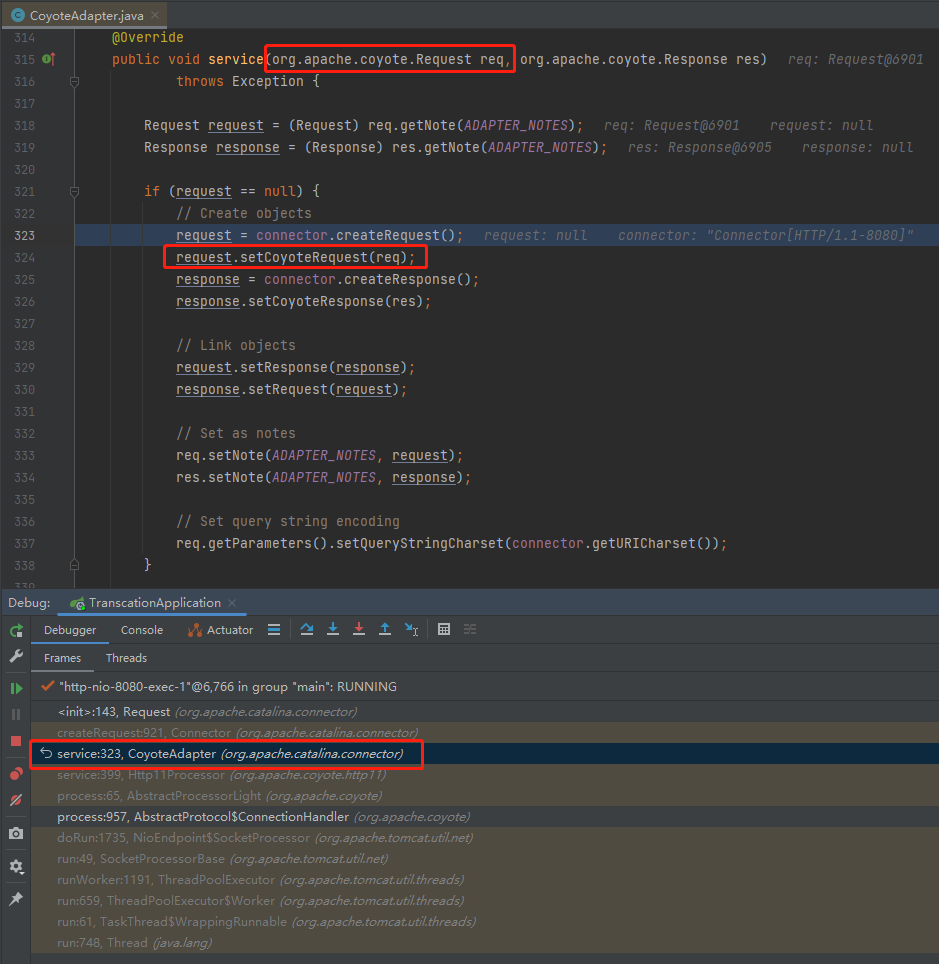
在上面截图的这个方法中,有一行这样的代码:
request.setCoyoteRequest(req);
其中 request 是 org.apache.catalina.connector.Request 对象。
而 req 是 org.apache.coyote.Request 对象。

也就是说,我这里的这个输出语句应该是这样的才对:
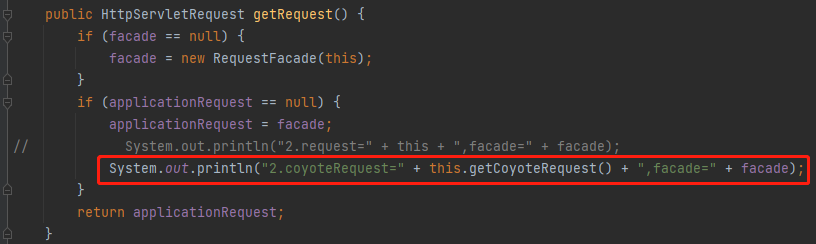
修改之后,再次发起调用,输出日志是这样的:

如果你还没看出点什么的话,我给你加工一下:
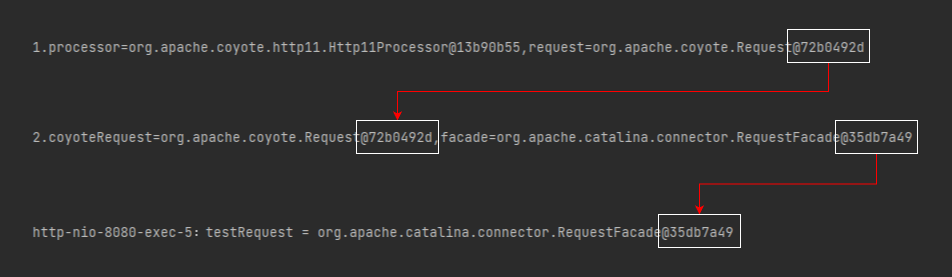
意思就是 Processor 和 RequestFacade 确实是一一对应的。
回到文章最开始的这个截图,为什么我发起两次请求,RequestFacade 对象是同一个呢?
因为两次请求用的是同一个 Processor 呀。
你看我再发起两次请求,都是 Http11Processor@26807016 在处理:

所以,表面上看是同一个 RequestFacade,实质上是用的同一个 Processor。
换句话说:要是两个请求用的是不同的 Processor,就不会存在复用的情况。
怎么验证一下呢?
我想到了下面的这个验证方式:

我可以先请求 sleepTenSeconds,然后在 10s 内请求 testRequest。这样,我就能观察到两个不同的 Processor:
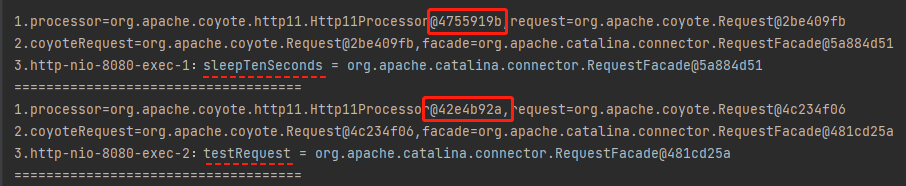
为了更加直观的看到这个现象。
我决定在操作 recycledProcessors 的 pop 方法之前和 push 方法之后,输出一下 recycledProcessors 里面的内容:
org.apache.coyote.AbstractProtocol.RecycledProcessors
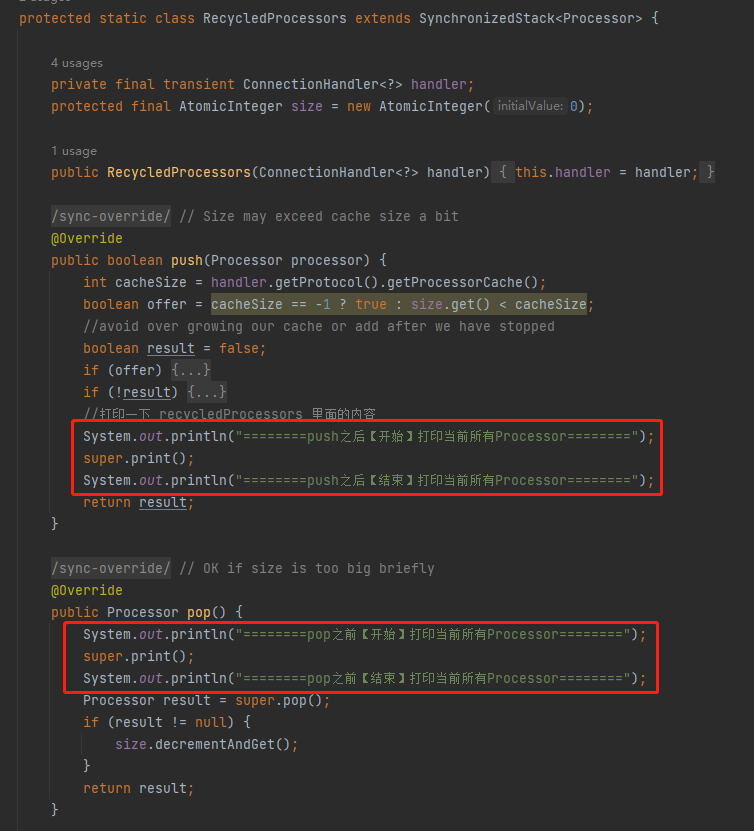
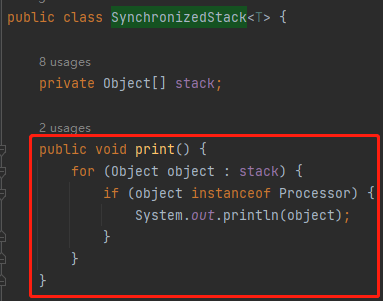
但是你按照我这样写的时候会发现: RecycledProcessors 的父类,也就是 SynchronizedStack 类并没有提供 print 方法,怎么办呢?
很简单嘛,源码我都可以拿到,加一个方法,还不是手到擒来的事情?
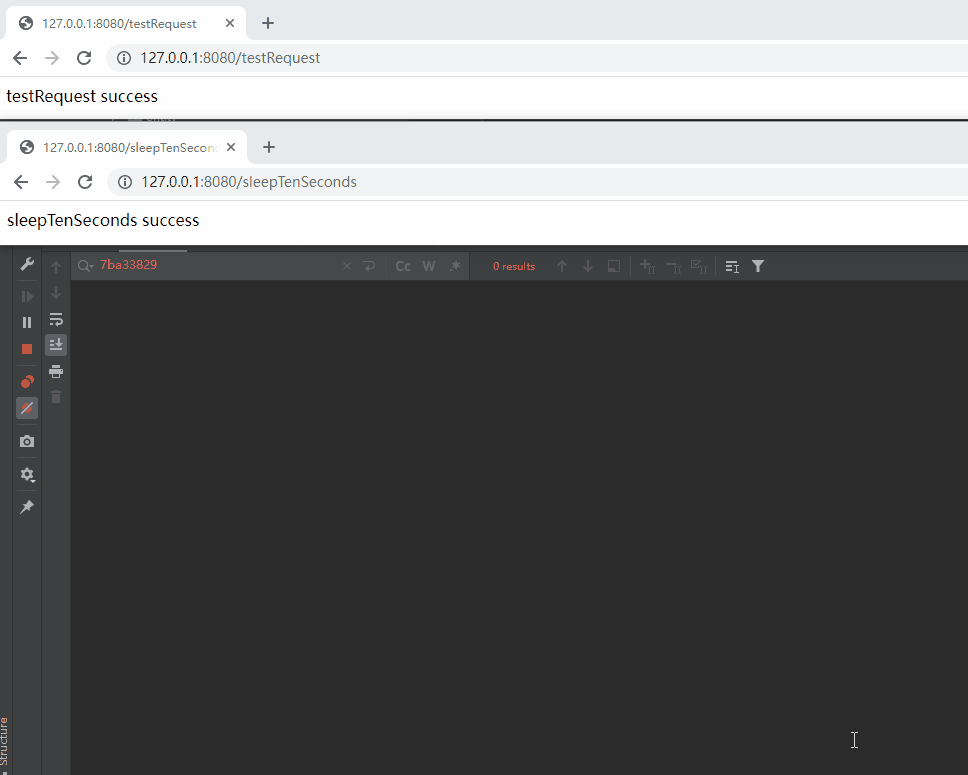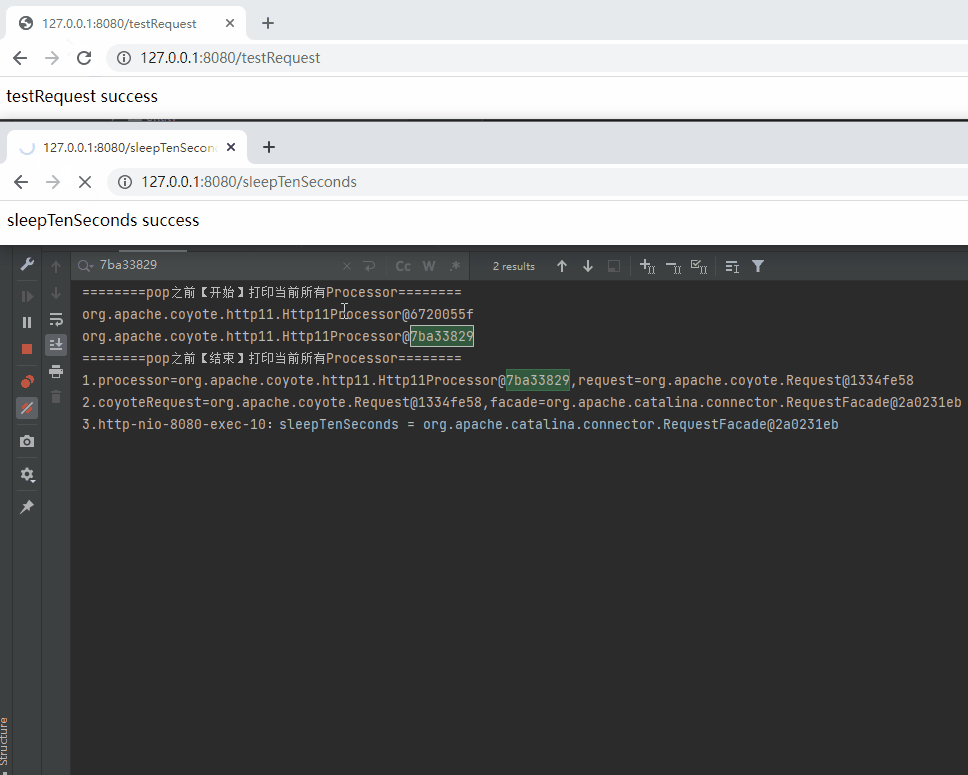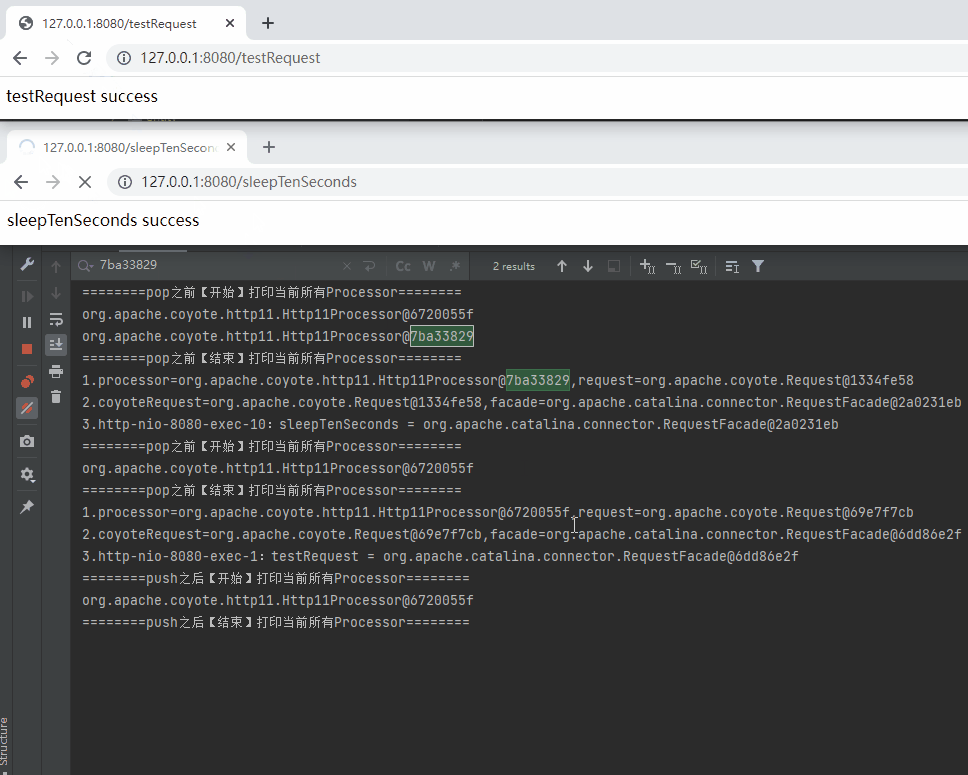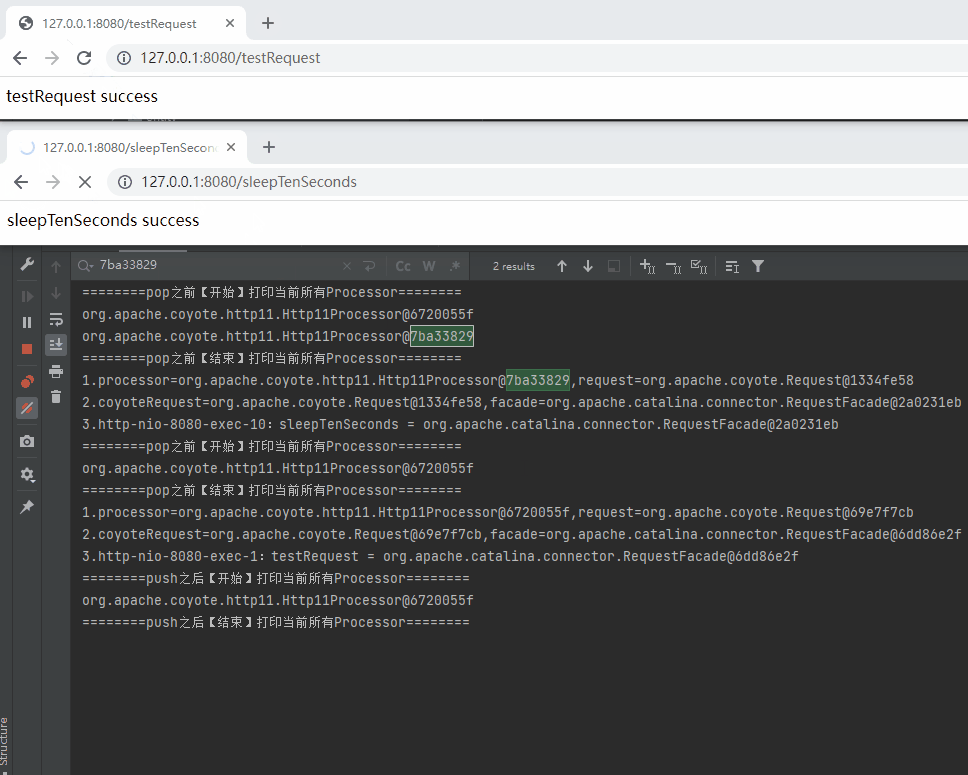
接着,我还是按照先访问 sleepTenSeconds 再访问 testRequest 方法的顺序发起请求,日志是这样的:
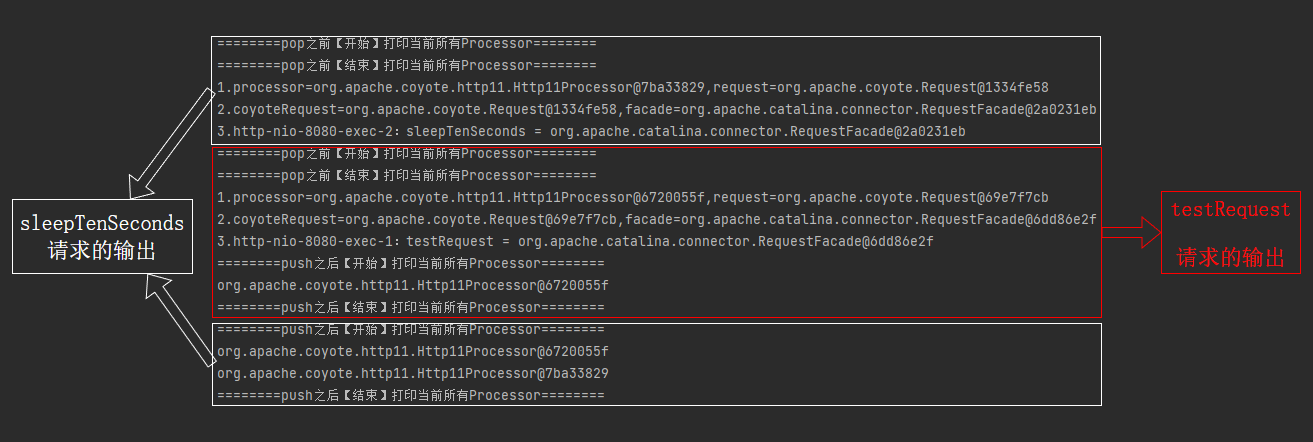
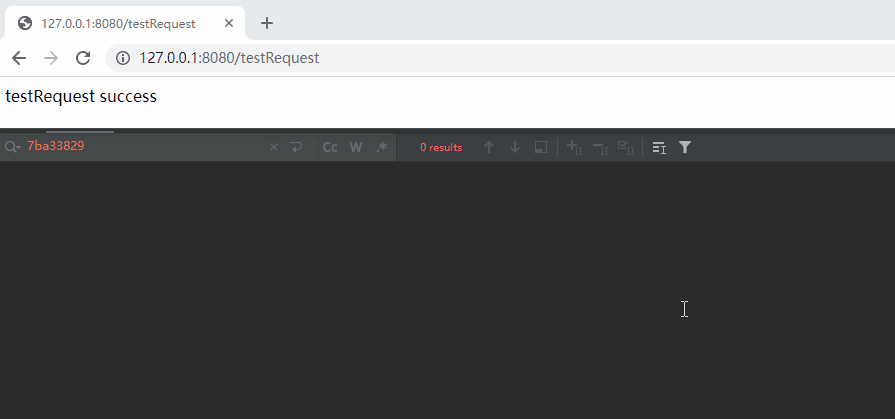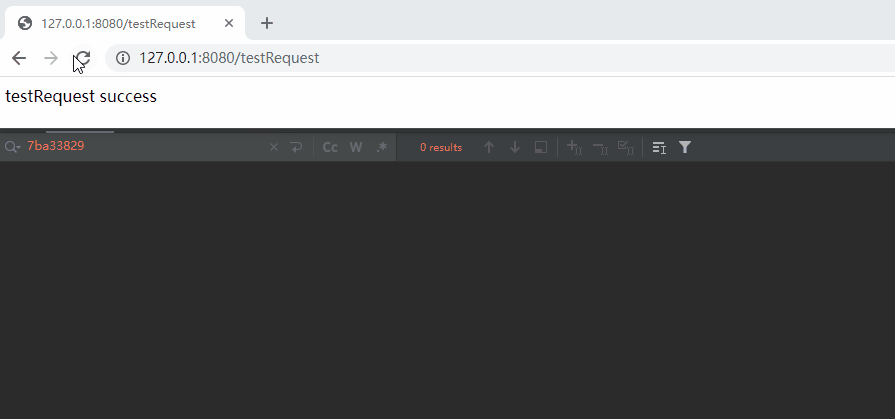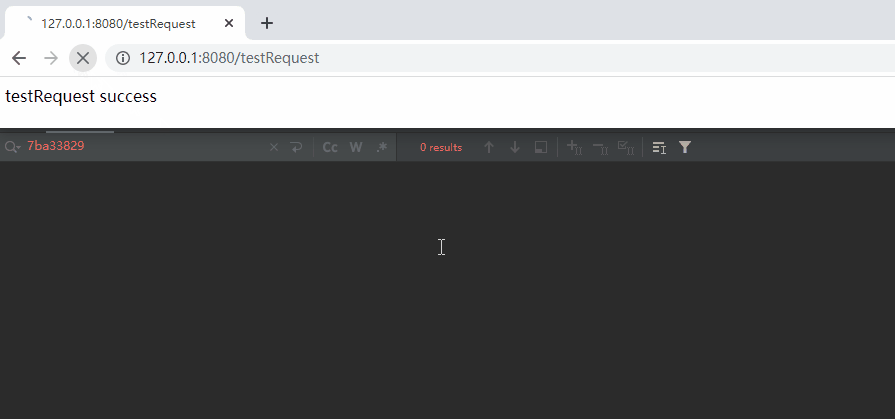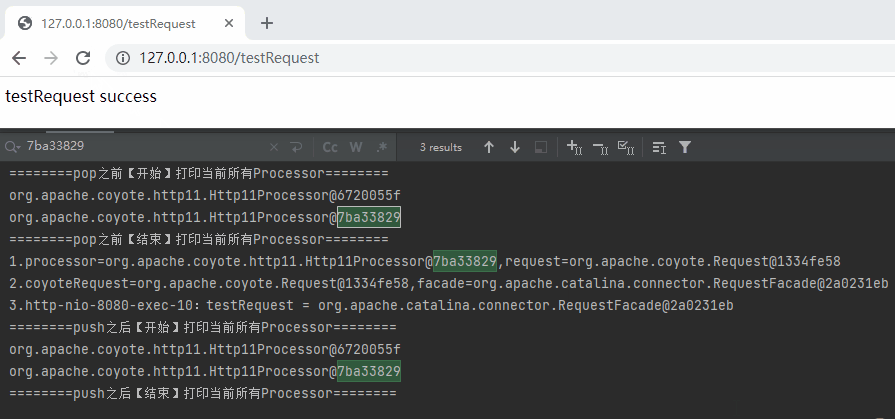
单独拿出来,testRequest 整个请求完成之后,对应的日志是这样的,
========pop之前【开始】打印当前所有Processor========
========pop之前【结束】打印当前所有Processor========
1.processor=org.apache.coyote.http11.Http11Processor@6720055f,request=org.apache.coyote.Request@69e7f7cb
2.coyoteRequest=org.apache.coyote.Request@69e7f7cb,facade=org.apache.catalina.connector.RequestFacade@6dd86e2f
3.http-nio-8080-exec-1:testRequest = org.apache.catalina.connector.RequestFacade@6dd86e2f
========push之后【开始】打印当前所有Processor========
org.apache.coyote.http11.Http11Processor@6720055f
========push之后【结束】打印当前所有Processor========
而 sleepTenSeconds 整个请求完成之后,对应的日志是这样的:
========pop之前【开始】打印当前所有Processor========
========pop之前【结束】打印当前所有Processor========
1.processor=org.apache.coyote.http11.Http11Processor@7ba33829,request=org.apache.coyote.Request@1334fe58
2.coyoteRequest=org.apache.coyote.Request@1334fe58,facade=org.apache.catalina.connector.RequestFacade@2a0231eb
3.http-nio-8080-exec-2:sleepTenSeconds = org.apache.catalina.connector.RequestFacade@2a0231eb
========push之后【开始】打印当前所有Processor========
org.apache.coyote.http11.Http11Processor@6720055f
org.apache.coyote.http11.Http11Processor@7ba33829
========push之后【结束】打印当前所有Processor========
也就是说,此时 recycledProcessors 里面有两个 Processor:
========push之后【开始】打印当前所有Processor========
org.apache.coyote.http11.Http11Processor@6720055f
org.apache.coyote.http11.Http11Processor@7ba33829
========push之后【结束】打印当前所有Processor========
那么问题就来了:你说我接下来再次发起一个请求,哪个 Processor 会来承接这个请求呢?
虽然我还没有发起请求,但是我知道,一定是 Http11Processor@7ba33829 来进行处理。
因为我知道它将是下一个被 pop 出来的 Processor 对象。
不信,你就看这个动图:
在上面的动图中,我先是 testRequest 这个请求。
如果我先访问 sleepTenSeconds,再访问 testRequest 呢?
虽然我还没有发起请求,但是我知道,一定是这样的对应关系来处理这两次请求:
sleepTenSeconds->Http11Processor@7ba33829
testRequest->Http11Processor@6720055f
因为 sleepTenSeconds 请求来的时候,recycledProcessors 里面会 pop 出 Processor@7ba33829 这个对象,来处理这个请求。
所以在 10 秒内,也就是 sleepTenSeconds 请求未完成的时候,访问 testRequest 请求,recycledProcessors 里面接着 pop 出来的 就是 Http11Processor@6720055f 这个对象。
不信的话,你再看这个动图:
所以,现在我们是不是找到这个问题的答案了:
如何决定哪个线程每次复用那个request呢?
请求线程和 request 之间没有关联关系。每次请求使用哪个 request 取决于使用哪个 Processor。而每次请求使用哪个 Processor,取决于 recycledProcessors 类里面缓存了哪些 Processor。请求过来的时候,pop 出来哪个,就是哪个。
recycledProcessors 既然是一个缓存,它的大小,一定程度上决定了项目的性能。
而它的默认值是 200:
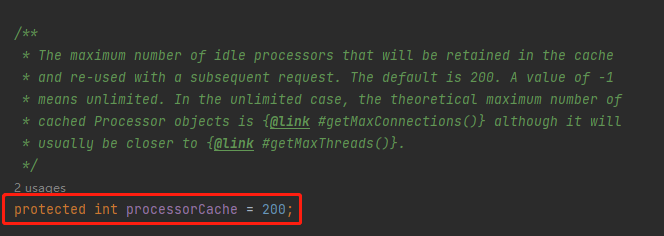
为什么是 200 呢?
因为 tomcat 线程池的最大线程数默认就是 200:
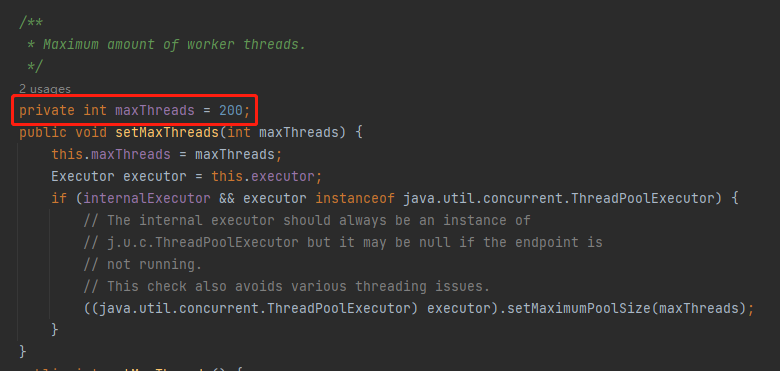
这个能想明白吧?
虽然线程和 Processor 之间没有绑定关系,但是从逻辑上讲一个线程对应一个 Processor。因此,好一点的做法是让线程数和 Processor 的数量保持一致。
如果我把 processorCache 这个参数修改为 1:
server.tomcat.processor-cache=1
你说高并发的时候会发生什么事情呢?
很多请求 push 的时候会 push 不进去,从而走到 handler.unregister(processor) 的逻辑里面去:
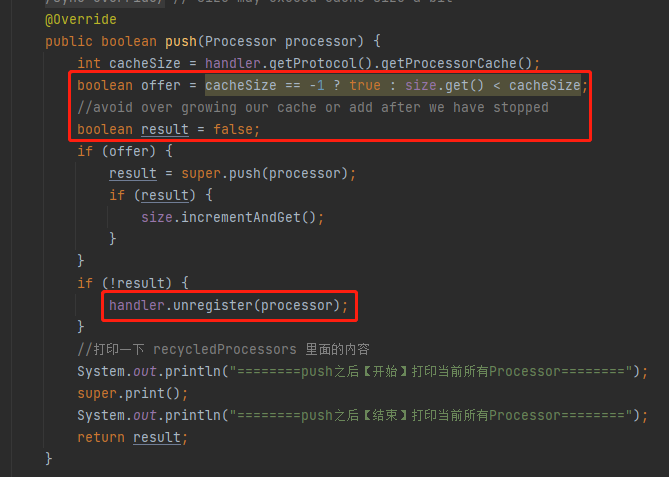
而这个 unregister 方法,对应的还有一个 register 方法,我一起给你看看:
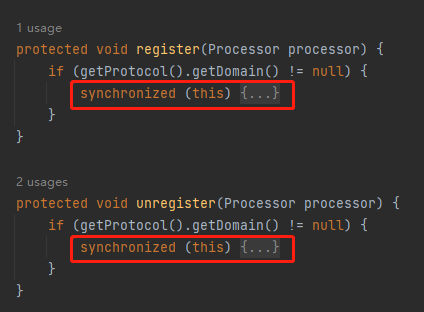
它们持有的是同一笔 synchronized 锁,说明它们之间有竞争。
我们知道,一个请求结束之后会调用 RecycledProcessors 的 push 方法,而 push 的时候会调用 unregister 方法。
那么问题就来了:register 什么时候调用呢?
其实前面已经出现过了:

一个请求来了,创建完 processor 之后。
所以,当我把 processorCache 设置为 1,高并发的情况下,在不停的调用 register 和 unregister,锁竞争频繁,性能下降。
这个结论,就是我通过翻阅源码得出来的结论,而不是在其他的某个书上或者视频里面得到的一个现成的结论。
这就是翻阅源码的快乐和意义。

写到这里的时候,我不由的想起了我在《千万不要把Request传递到异步线程里面!有坑!》这篇文章中踩到的坑。
再看一下这个动图,主要关注两次调用的时候控制台对应的输出:
就是因为在 Request 的生命周期之外使用了它,导致复用的时候出现了问题。
当时我给出的正确方案是使用 Request 的异步编程,也就是 startAsync 和 AsyncContext.complete 方法那一套。
但是这篇文章写完之后,我又想到了两个骚操作。
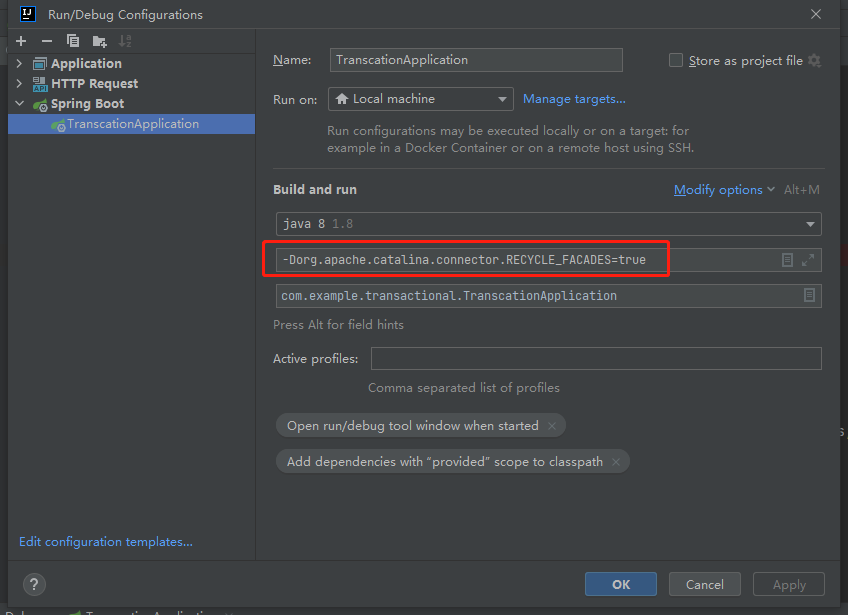
第一个方法,就藏在我前面说的 RECYCLE_FACADES 这个配置中。
从官方文档上的描述来看这个参数如果设置为 true 会提高安全性,但是它默认是 false。
它怎么提高安全性呢?
就是每次把 RequestFacade 也给回收了。
那我把它改成 true 试一试,看看啥效果:
-Dorg.apache.catalina.connector.RECYCLE_FACADES=true
启动项目,发起调用:
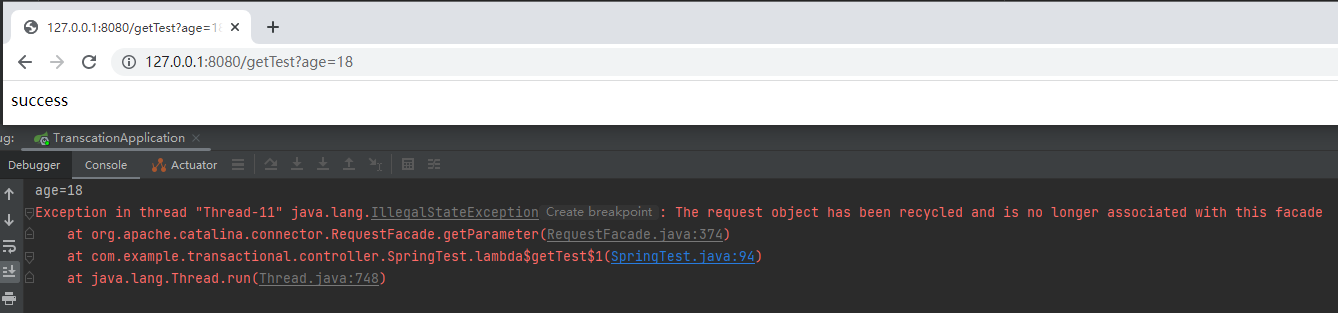
抛出了一个异常。
看到这个异常的时候,我一下就明白了官方文档里面说的“安全性”是什么意思了:你的用法错误了,我给你抛个异常,给你提醒一下,这里需要进行修改,提升安全性。
而第二个是这样的:
server.tomcat.processor-cache=0
你明白我意思吧?
我直接不让你复用了,每次都用新的,绕过复用这个“坑”:

先别管它好不好用,有没有性能问题,你就说在彻底理解了底层逻辑之后,这个操作骚不骚吧。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK