

再续面向跨语言的操作系统日志异常检测技术研究与实现
source link: https://netsecurity.51cto.com/article/715066.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

再续面向跨语言的操作系统日志异常检测技术研究与实现-51CTO.COM
日志异常检测相关概念定义
定义1-1:原始日志。如图1.1所示,原始日志由操作系统的日志打印语句输出,由常量和变量部分组成,其中常量部分是指程序代码中定义的用于描述当前程序的行为或功能的固定的关键词,如start、fail、success、port等,变量部分是指程序运行过程中产生的用于描述系统运行状态的变量参数等,例如,IP地址、文件路径、端口号、uid等参数。

图 1.1 原始日志
定义1-2:日志模板。日志模板是使用日志解析技术将原始日志中的变量部分用占位符<*>标识,常量部分保留后形成的结构化文本信息。
定义1-3:模板编号。模板编号(𝐼𝐷)是用来标识日志模板的唯一标识符,值是除0以外的任意一个自然数通常用日志模板的索引下标表示,同类型的日志模板对应同一标识符,模板标号相同。
定义1-4:日志序列(Log Sequences)。日志序列由按执行时间先后顺序排列的日志组成,日志序列的长度指该日志序列中所含日志的数量。
定义1-5:日志异常。偏离正常执行模式的日志序列被称为异常日志序列。
定义1-6:序列分割。由于日志序列是一段时间内所有日志按照时间顺序形成的长序列,需要按照某种序列划分方式将长日志序列切割为短序列。常用的序列分割方式有三种,分别是会话窗口(Session Window)、固定窗口(Fixed Window)和滑动窗口(Sliding Window)[1]。如图1.2所示,会话窗口把属于同一主体的日志划分到同一个会话中,例如,使用会话窗口的方式对HDFS数据集进行切割时,就将属于同一个块(Block)的日志切分为一组。固定窗口和滑动窗口都是以时间段对日志进行切割,固定窗口默认将一个时间周期Δ𝑇内的所有日志作为一组序列,但是这种方法会导致同一个序列内日志时间跨度过大,降低了序列内日志的关联性。滑动窗口在设计时增加了一个步长Δ𝑡,先对序列按照Δ𝑇划分出一个子序列,再以Δ𝑡为步长向后滑动在整个序列上进行切割,当Δ𝑡 = Δ𝑇时,滑动窗口方法便等同于固定窗口方法。
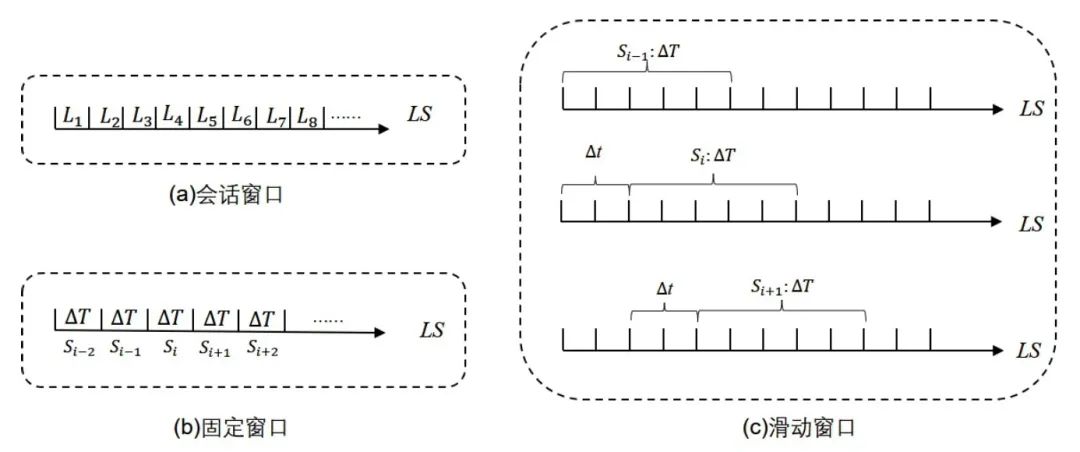
图1.2日志序列分割方式,(a)为会话窗口,(b)为固定窗口,(c)为滑动窗口
日志收集技术
现有的日志收集方法在对日志数据进行采集时,主要包括推送和拉取两种采集方式[2]。拉取方式是指在日志收集服务器按照相关协议规定的传输方式,拉取客户端的日志数据到服务端进行存储分析等工作;推送方式是指在客户端在开启相应的网络端口后使用对应的传输协议将日志推送到日志收集服务器上进行后续的存储分析等工作。
Drain日志解析算法
本节对比了14种日志解析方法的性能,包括AEL[3]、Drain[4]、IPLoM[5]、LenMA[6]、LFA[7]、LKE[8]、LogCluster[9]、LogMine[10]、LogSig[11]、MoLFI[12]、NuLog[13]、SHISO[14]、SLCT[15]、SPELL[16]。上述算法对2000条日志处理性能对比如表1.3所示,2000条日志应被解析为118个日志模板。
表1.3日志解析算法性能对比
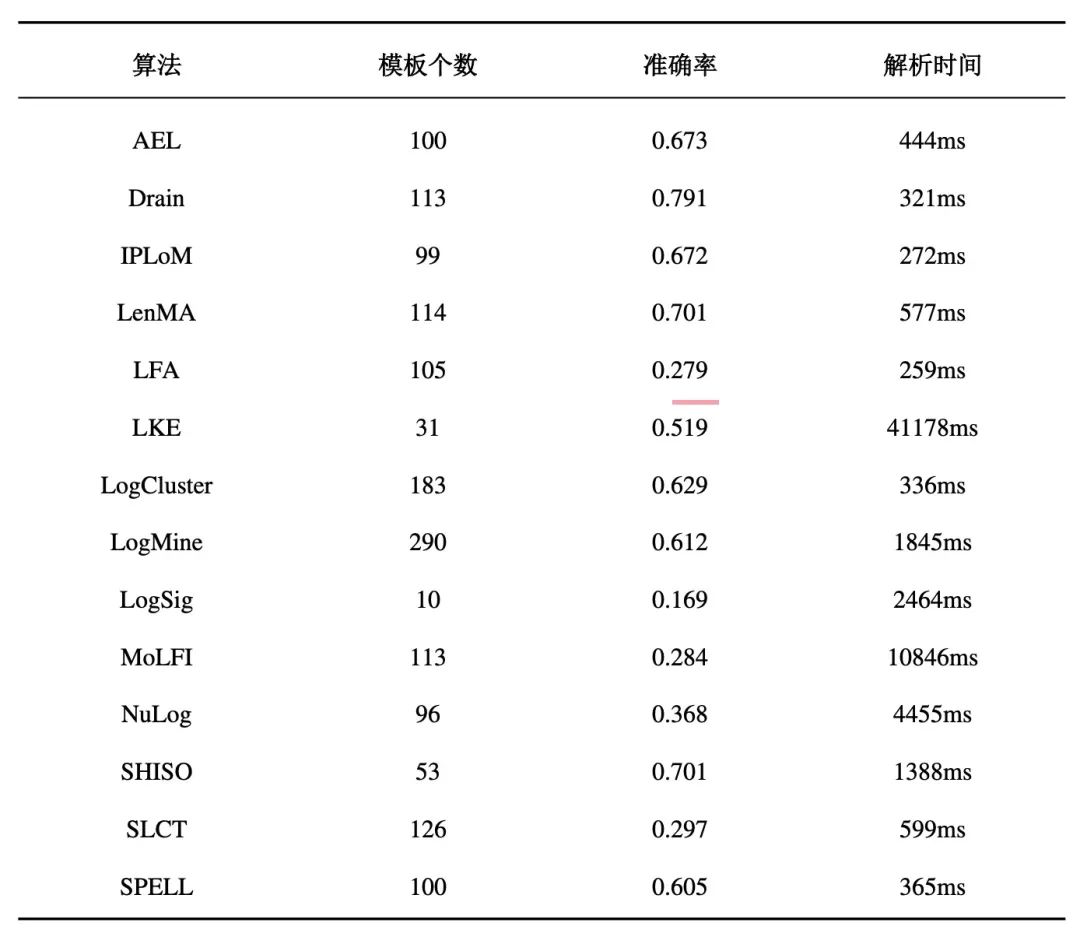
从表中可以看出,Drain的算法准确率最好,解析速度位于前三名,结合国产操作系统日志的特点,本文最终采用了Drain的解析思想对日志进行模板抽取。
LaBSE预训练模型
LaBSE模型由两个共享参数的12层堆叠双向Transformer编码器组成,包括 768个隐藏层和一亿一千万个参数组成,主要是基于注意力机制实现的。
(1)自注意力机制
注意力机制(Attention Mechanism,AM)附加在神经网络的隐藏层之上,它可以了解隐藏层的输出单元中各个值的重要性,并动态的地调整它们的权重。将注意力机制应用于序列编码时,具体步骤如下。第一步是将每个编码器输入向量与三个权重矩阵(W(Q)、W(K)、W(V))进行矩阵相乘运算,得到三个向量: 键向量(Key)、查询向量(Query)和值向量(Value)。第二步是将当前输入的查询向量(Q)与其他输入的键向量(K)相乘。在第三步中将上述计算结果除以键向量的平方根。接下来,用softmax函数对计算被查询的词的所有注意力权重,将值向量(V)与上一步经过softmax计算的向量相乘。在最后一步中,将在上一步中得到的加权值向量相加,得到给定单词的自注意力输出。
(2)Transformer
Transformer实现了编码器-解码器(Encoder-Decoder)模块,其完全依赖于每个编码器和解码器中的多头自注意力机制,已经被证明在解决句法解析和语言翻译等自然语言处理领域方面表现出色。
(3)模型预训练
LaBSE使用CommonCrawl1和Wikipedia2作为单语训练数据集,使用双文本挖掘系统构建的语料库经过对比数据选择(Contrastive Data Selection,CDS)评分模型过滤后作为双语训练数据集。LaBSE执行的语言建模遵循两种不同的策略:掩码语言模型(Mask Language Model,MLM)和翻译语言模型(Translation Language Model,TLM)。
双向长短时间记忆网络
为了解决RNN在训练过程中会出现梯度消失或者梯度爆炸的问题,长短期记忆网络(Long Short-Term Memory Network, LSTM)[17]引入了遗忘门机制,遗忘门由学习的权重和一个类似于激活函数的函数组成,该函数决定要记住或忘记什么,实现长期记忆功能,LSTM 的网络结构如图1.4所示。
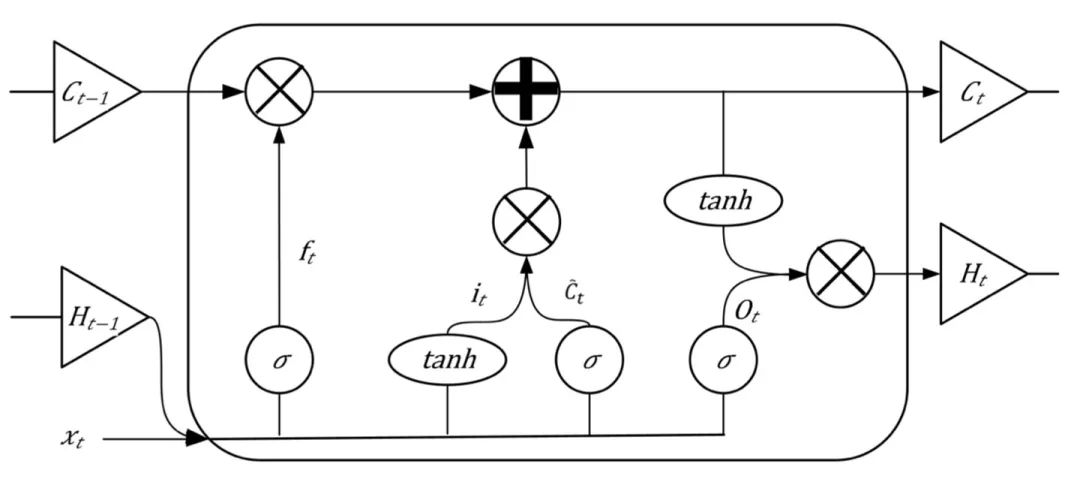
图1.4 LSTM神经单元

双向长短期记忆网络(Bi-Directional Long Short-Term Memory Network,Bi- LSTM)基于LSTM的网络组织结构,其网络结构如图1.5所示。在Bi-LSTM中,输入序列信息不仅能向前传递,还能向后传递,最终网络输出的向量是对两个LSTM层向量进行加法运算、均值运算或拼接的方式得到的。
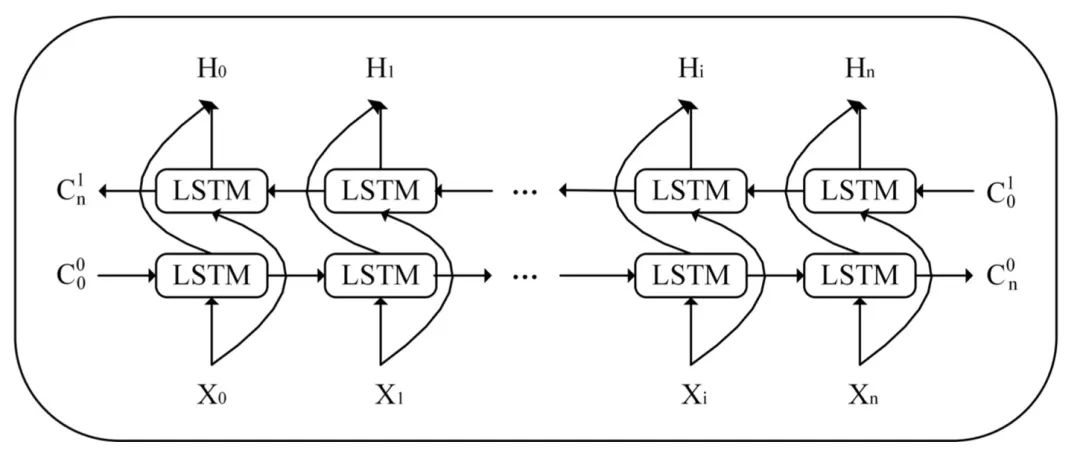
图1.5 Bi-LSTM 结构
层级注意力机制
注意力机制提出之后,被广泛应用于深度学习的各个领域中。在自然语言处理任务中,注意力机制可以捕获句子中长距离的相互依赖,学习在同一个句子内各个单词间产生的联系,获得句子在单词级别的注意力权重。文本是由句子构成的,而句子是由单词构成的,单层注意力机制无法获得句子级别的注意力权重。因此,层级注意力模型(Hierarchical Attention Network,HAN)利用分层次的注意力机制来构建文本向量表示,其整体结构如图1.6所示。
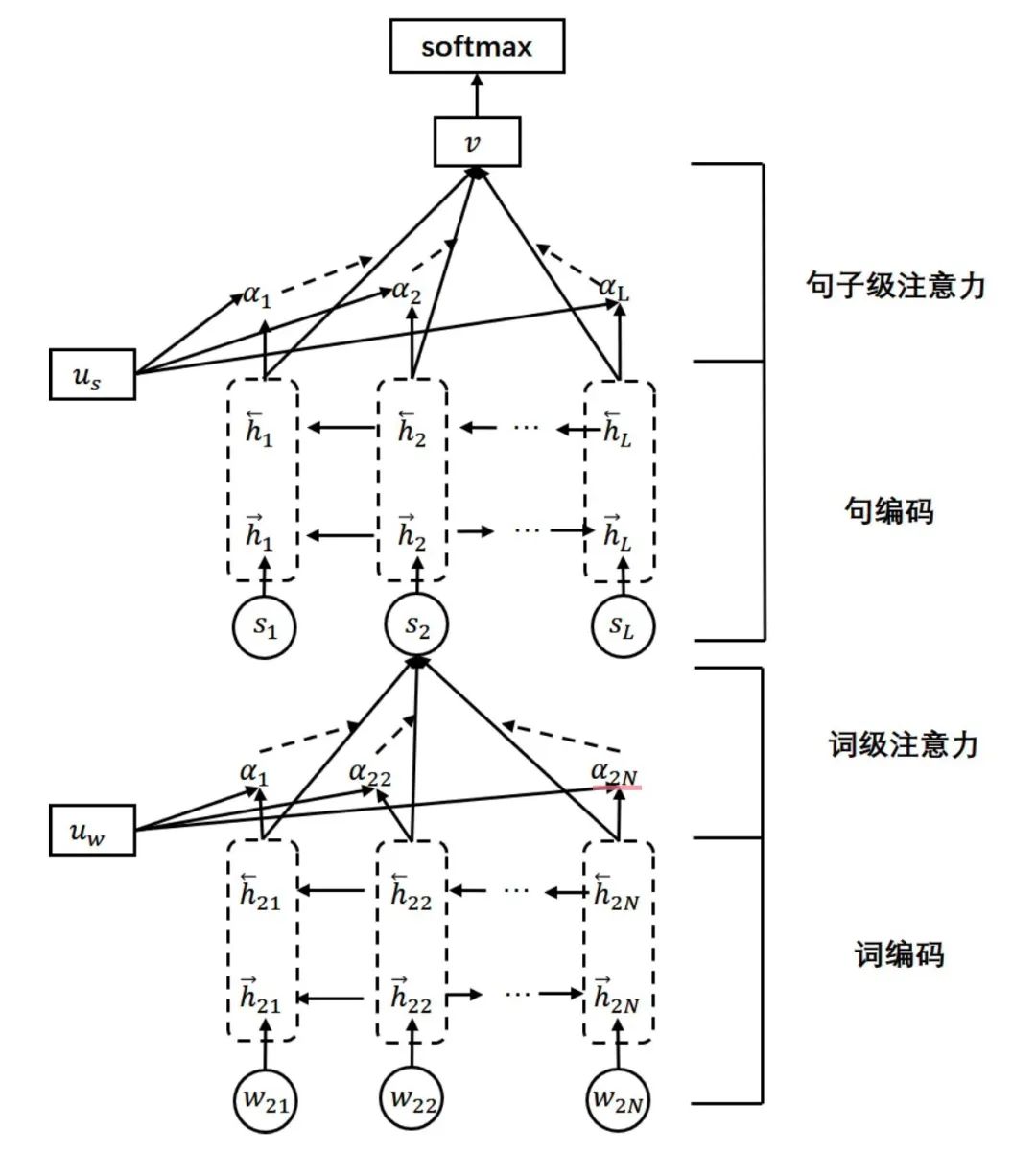
图1.6层级注意力机制
对于日志序列异常检测任务来说,本文把一条日志模板视为一个自然句,将一个时间窗口内的日志序列视为由多个日志模板组成的文本,将层级注意力机制应用于对日志序列的二分类任务中。
[1]张宏业.基于局部信息抽取和全局稀疏化Transformer的日志序列异常检测 [EB/OL].哈尔滨工业大学, 2021.DOI:10.27061/d.cnki.ghgdu.2021.000611.
[2]Chuvakin A, Schmidt K, Phillips C. Logging and log management: the authoritative guide to understanding the concepts surrounding logging and log management [M]. Newnes, 2012.
[3]Xu W, Huang L, Fox A, et al. Detecting large-scale system problems by mining console logs [C]//Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. 2009: 117-132.
[4]He P, Zhu J, Zheng Z, et al. Drain: An Online Log Parsing Approach with Fixed Depth Tree [C]//2017 IEEE International Conference on Web Services (ICWS). Honolulu, HI, USA: IEEE, 2017: 33-40.
[5]Makanju A A, Zincir-Heywood A N, Milios E E. Clustering event logs using iterative partitioning [C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining - KDD ’09. Paris, France: ACM Press, 2009: 1255.
[6]Shima K. Length matters: Clustering system log messages using length of words [EB/OL]. 2016. arXivpreprintarXiv:1611.03213.
[7]NandiA,MandalA,AtrejaS,etal.Anomaly detection using program control flow graph mining from execution logs [C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016: 215-224.
[8]Fu Q, Lou J G, Wang Y, et al. Execution Anomaly Detection in Distributed Systems through Unstructured Log Analysis [C]//2009 Ninth IEEE International Conference on Data Mining. Miami Beach, FL, USA: IEEE, 2009: 149-158.
[9]VaarandiR,PihelgasM.LogCluster-A data clustering and pattern mining algorithm for event logs [C]//2015 11th International Conference on Network and Service Management (CNSM). Barcelona, Spain: IEEE, 2015: 1-7.
[10] Hamooni H, Debnath B, Xu J, et al. LogMine: Fast Pattern Recognition for Log Analytics [C]//Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. Indianapolis Indiana USA: ACM, 2016: 1573-1582.
[11] Tang L, Li T, Perng C S. LogSig: generating system events from raw textual logs [C]// Proceedings of the 20th ACM international conference on Information and knowledge man- agement - CIKM ’11. Glasgow, Scotland, UK: ACM Press, 2011: 785.
[12] MessaoudiS,PanichellaA,BianculliD,etal.Asearch-based approach for accurate identification of log message formats [C]//2018 IEEE/ACM 26th International Conference on Program Comprehension (ICPC). IEEE, 2018: 167-16710.
[13]ZhuJ,HeS,LiuJ,etal.Toolsandbenchmarksforautomatedlogparsing[C]//2019IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2019: 121-130.
[14] Mizutani M. Incremental mining of system log format [C]//2013 IEEE International Conference on Services Computing. IEEE, 2013: 595-602.
[15] Nagappan M, Vouk M A. Abstracting log lines to log event types for mining software system logs [C]//2010 7th IEEE Working Conference on Mining Software Repositories (MSR 2010). IEEE, 2010: 114-117.
[16]DuM,LiF.Spell:StreamingParsingofSystemEventLogs[C]//2016 IEEE 16th International Conference on Data Mining (ICDM). Barcelona, Spain: IEEE, 2016: 859-864.
[17] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [J]. Advances in neural information processing systems, 2017, 30.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK