

数据采集与预处理课设——人在回路的气温数据动态处理与可视化 - 流白李
source link: https://www.cnblogs.com/liubaili/p/16303901.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据采集与预处理课设——人在回路的气温数据动态处理与可视化
本次研究旨在通过python网络爬虫技术,获得中国各城市近90天的气象数据,运用HTML、Xpath、jieba、counter等技术对数据进行处理,绘制动态可视化图、词云图等,结合@chenjiandongx等人提供的pyecharts技术将其具现在地图上的同时,采用LSTM时间序列分析技术实现基于历史数据的天气预测。我们希望通过实现全国城市气象数据的可视化,把握异常气候影响范围与程度。相较于传统的图片可视化,本研究采用网页动态展示,通过实现地图中城市链接到对应网页,网页控件关联数据表数据视图、图表类型以及窗口范围,大大增加了交互性,方便了研究与使用。
大数据时代的到来为气象研究提供了大量的数据支撑,如何高效地获取与使用现有的大量数据已成为重要的研究课题。但由于数据过于分散,没有公开的大型气象信息可视化平台,日常研究受到数据数量以及工具的限制。
本研究试通过对全国数据整合分析,实现数据全览的可视化分析网页平台搭建,基于当前易获取数据做出对于大数据的情况的合理规划与尝试,设计了滑动窗口与数据缩放,并提供了基于LSTM时间序列分析的气象预测数据,为气象学者研究气候学做出切实可行的尝试,有利于对水电等重要资源进行合理规划与调度。
如表1-1,在天气网导航页中记录了各个城市历史天气信息的网址索引链接。通过访问导航页面,采用xpath访问./@href的值,获得各个城市历史信息的网址。
表1-1 拟爬取网页信息表
|
全国所有城市信息 |
https://www.tianqishi.com/lishi/ |
|
单个城市近90天天气数据 |
https://www.tianqishi.com + city.xpath('./@href') |
如表1-2,访问页面获取各个城市的数据,得到图1中的历史天气信息表格,通过加注数据标签设置省市名称,备注网站URL,添加数据标签转存到csv文件中,并以省市名称命名文件。
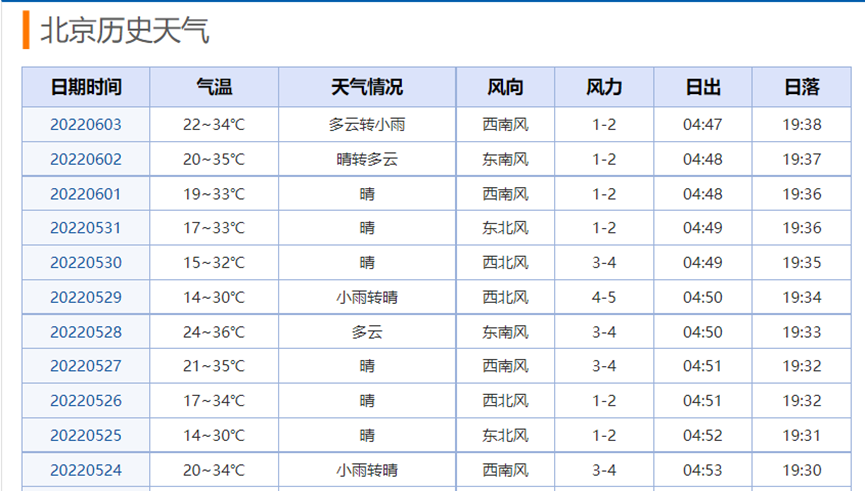
图1 网页中历史天气数据信息
程序中用到的城市天气信息数据如表1-2。
表1-2 城市天气信息数据采集表
|
字段名称 |
数据类型 |
数据说明 |
|
provinceName |
||
|
city_name |
||
|
city_url |
城市对应网页地址 |
|
|
List[Str,Str,Str,Str,Str,Str] |
城市单日天气数据 |
如图2,首先采用python网络爬虫技术获取网页数据信息,通过文本预处理,采用正则表达式提取城市信息、对日期信息进行数据类型转换、此外将其他数据进行收集与文字编码后存储至csv文件中。通过访问csv文件,将“天气情况”数据使用逗号拼接为文本,而后调用jieba库进行中文分词、采用counter进行词频统计。
调用pyecharts实现中国城市地图具象在网页中,而后在每个城市对应控件后的value中存储其url的值。对每个城市存储在csv的信息进行动态可视化与词云图绘制,实现line表和bar表的切换,同时设置对最高温和最低温的堆叠、平铺功能切换,设置区域缩放以及窗口自调整功能。通过Page.SimplePageLayout布局形式将其居中显示在网页中间,更好地适应用户使用以及屏幕大小的改变。
最后在map图中添加鼠标响应,对value值进行调用,改变map中属性的值实现每个城市控件的高亮显示,以及通过window.open实现新窗口的打开。
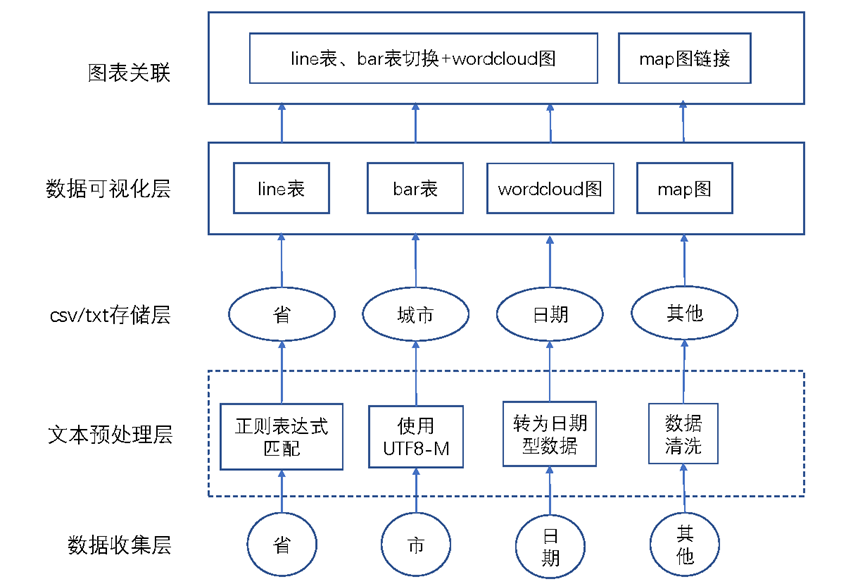
图2 软件架构图
采集策略与预处理模型
数据采集流程图
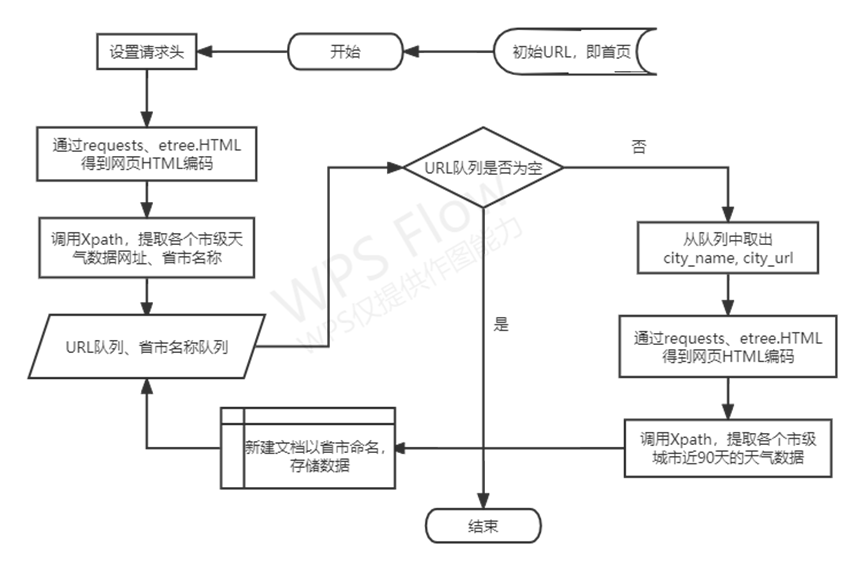
图3 数据采集流程图
关键数据采集与预处理策略
(1)通过xpath访问ul结点,存储每个结点下的HTML内容,然后同样采用xpath爬虫技术,通过url_head + city.xpath('./@href') 的方式,获得城市页面的网址,然后记录省市作为标签,调用get_WeatherMessage方法获取数据,此外调用time包,采用time.sleep的方式控制爬虫速度,防止被网站服务器发现并停止爬虫进程。
(2)由分析的URL来分别爬取近90天全国各省市的天气数据,包括日期时间、气温、天气情况、风向、风力、日出、日落等六项数据,获取到的数据会以指定格式存放。由于采用. CSV 文件能够使数据交换更加容易,故采用 CSV的形式进行存储[1]。使用open(fr'D:/dataSave/{provinceName}{city_name}.csv', 'a', encoding='utf-8')创建文件并以省市命名csv文件以及sheet,将已读取的数据列表以续写的打开方式,采用编码为utf-8写入方便后续调用研究使用该数据。
(3)采用os.listdir访问文件夹,获得文件夹中全部的文件名,记入dirs。然后通过字符拼接获得所有文件访问的路径。此外,通过正则表达式"历史天气(.*?).csv"获取文件目录中的城市名,便于后续在地图中对应分析。此外,对于日期时间信息进行格式转化,将其通过pd.to_datetime()转为日期型数据,再通过dt.date删去多余的精度,有利于后续对于单个城市的可视化建图。然后在通过遍历表格得到关于天气情况的txt文本,使用jieba和counter进行词频统计。
dirs = os.listdir('D:/dataSave') for filename in dirs: path = 'D:/dataSave/' + filename city = re.findall(r"历史天气(.*?).csv", path)[0] data = pd.read_csv(path, encoding='utf-8')
data['日期时间'] = data['日期时间'].apply(lambda x: pd.to_datetime(x, format="%Y%m%d")) data['日期时间'] = data['日期时间'].dt.date
text = "" for i in data['天气情况']: text = text + ',' + i words = [x for x in jieba.lcut(text) if x != ','] words_count = Counter(words).most_common(40)
数据分析与可视化
数据可视化
为了使得课题研究数据结果更加清晰明显,决定将对数据图进行可视化制作,由于本次课题主要是为了研究各地的天气波动,于是尝试将该数据在地图上采用html的形式展示。
(1)采用来自麻省理工大学的@chenjiandongx等人制作的pyecharts.map中国地图可视化json文件,并针对可视化需要进行修改。在初始模板中,没有提供可视化实现方式,仅提供市级区分,以及对应的数据填写位置,但其对于数据只提供了数字以及字符串类型的解析支持,想要完成外链需要自己另外寻找解决方案。通过调试,在每个城市对应的按键中以字符串形式存储了URL地址,实现了仅支持实现单个区域选中并涂色处理。而后尝试了通过在map中新增方法实现URL的触发,但由于其不支持HTML文本解析,即使外部导入HTML库也无法完成该功能;而后尝试通过在外部添加pyautogui库实现鼠标事件的获取,但由于目标数量过多且处于动态变化,无法对应地添加控件时间监视器,故pyautogui库也无法实现该功能。
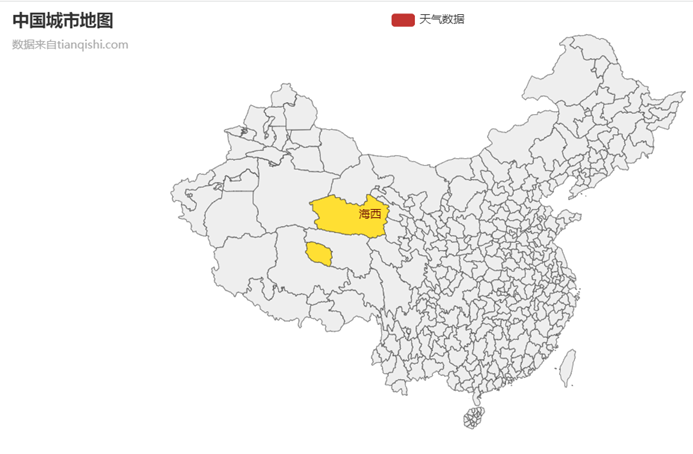
图4 经过初步调试的中国城市地图
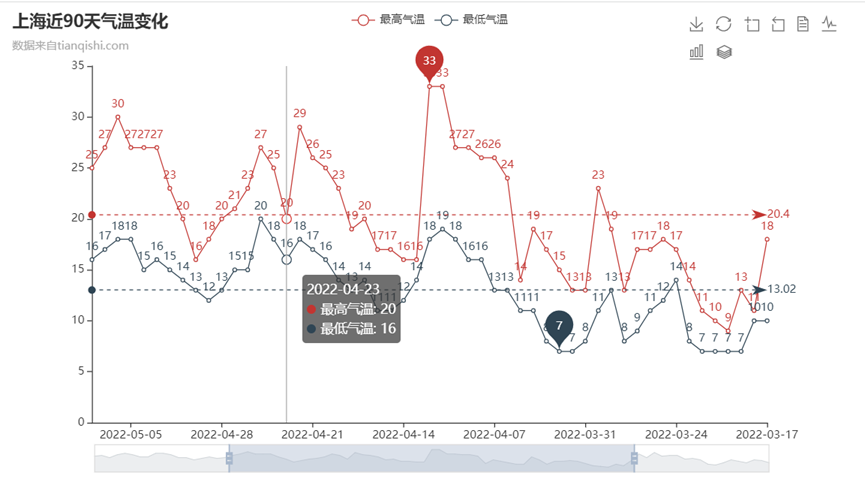
(2)同样采用@chenjiandongx等人提供的网页line表绘制,通过查阅资料自己定义属性值,更改数据显示方式,页面框架,动画渲染,实现了动态切换折线图与柱状图、保存图片为.png格式查看与更改表格数据、下方设置拉伸条,调整时间条的同时解决了数据密度较大的情况下可能出现的问题,通过标注表示最高温、最低温,以及每日最高温的平均值、最低温的平均值,可以通过鼠标移动查看每个日期所带数据,可以选择隐藏最高气温/最低气温,仅观察一项,此外设置区间缩放功能以及撤回功能。由此实现直观、流畅、界面简洁、展示效果好的可交互式可视化,供研究使用。
(3)通过调取数据表中“天气情况”列数据进行文本分析,通过调用jieba库实现中文分词,而后采用counter库进行词频统计,最后调用wordcloud生成词云图,该图表可以实现对近日天气情况频率的分析。此外利用网页的优势,添加了鼠标事件动态响应标签,更好地补全了网页展示的信息。

图11 天气情况词云图
(4)通过直接查看与修改网页前端代码,学习相关JavaScript知识。先是尝试了使用JQ选择器,获取网页事件并通过标签调用实现URL获取,但由于网页标签不够详细,无法实现URL的精确定位,故无法解决(1)中的遗留问题;最后选择在网页中自行添加鼠标事件获取响应信息,解析pramas获得URL地址,而后通过window.open实现新网页页面的打开。
(5)采用LSTM时间序列分析,基于已有数据训练得到新的数据。长短期记忆(Long short-term memory, LSTM)相比普通的RNN,LSTM能够在更长的序列中有更好的表现,故而在面对日益增长的天气数据时,LSTM能发挥更好的作用。以安徽安庆数据为例,将前十天的日最低气温作为训练集,而后对新一天的最低温进行预测,得到新的一天的真实数据后加入训练集进行增强训练,最终预测结果如图10所示:可以看到预测结果趋势与真实值一致,预测效果较为理想。
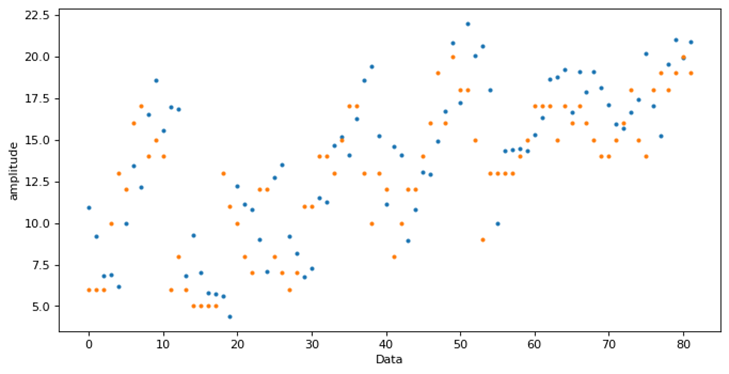
图12 时间序列分析预测结果对比图(橙:实际值,蓝:预测值)
本文通过使用python网络爬虫获取天气网的天气状况,实现丰富多样的数据可视化,帮助使用者在运用相关的专业知识实现对以往数据的横向和纵向、大尺度和小尺度的比较[1];再者,通过分析气温的变化规律,可以得到局部对流空气对我国天气的影响情况;通过某地区天气情况词频统计可以判断城市的宜居程度以及提供旅游时间参考。
可视化中提供了滑动窗口、视图缩放,在数据预测分析中采用了LSTM神经网络,能够很好地适应数据量增大的情况。总体上,本研究对于构建全国城市大数据气象信息平台做出了切实可行的尝试,不论是对气象学研究还是全国各城市的能源的合理调度分配工作都具有重要意义。
[1] 霍瑛,李海峰,王冲. 基于天气指数的数据分析_霍瑛[J]. 哈尔滨商业大学学报(自然科学版), 2018, 34(4): 440-446.
[2] 于学斗,柏晓钰. 基于Python的城市天气数据爬虫程序分析_于学斗[J]. 办公自动化, 2022, 27(7): 10-13, 9.
相较最终版有省略
制作:BDT20040
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK