

DeiT:注意力也能蒸馏 - ZOMI酱酱
source link: https://www.cnblogs.com/ZOMI/p/16496326.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

DeiT:注意力也能蒸馏
DeiT:注意力也能蒸馏
《Training data-efficient image transformers & distillation through attention》
ViT 在大数据集 ImageNet-21k(14million)或者 JFT-300M(300million) 上进行训练,Batch Size 128 下 NVIDIA A100 32G GPU 的计算资源加持下预训练 ViT-Base/32 需要3天时间。
Facebook 与索邦大学 Matthieu Cord 教授合作发表 Training data-efficient image transformers(DeiT) & distillation through attention,DeiT 模型(8600万参数)仅用一台 GPU 服务器在 53 hours train,20 hours finetune,仅使用 ImageNet 就达到了 84.2 top-1 准确性,而无需使用任何外部数据进行训练。性能与最先进的卷积神经网络(CNN)可以抗衡。所以呢,很有必要讲讲这个 DeiT 网络模型的相关内容。
下面来简单总结 DeiT:
DeiT 是一个全 Transformer 的架构。其核心是提出了针对 ViT 的教师-学生蒸馏训练策略,并提出了 token-based distillation 方法,使得 Transformer 在视觉领域训练得又快又好。
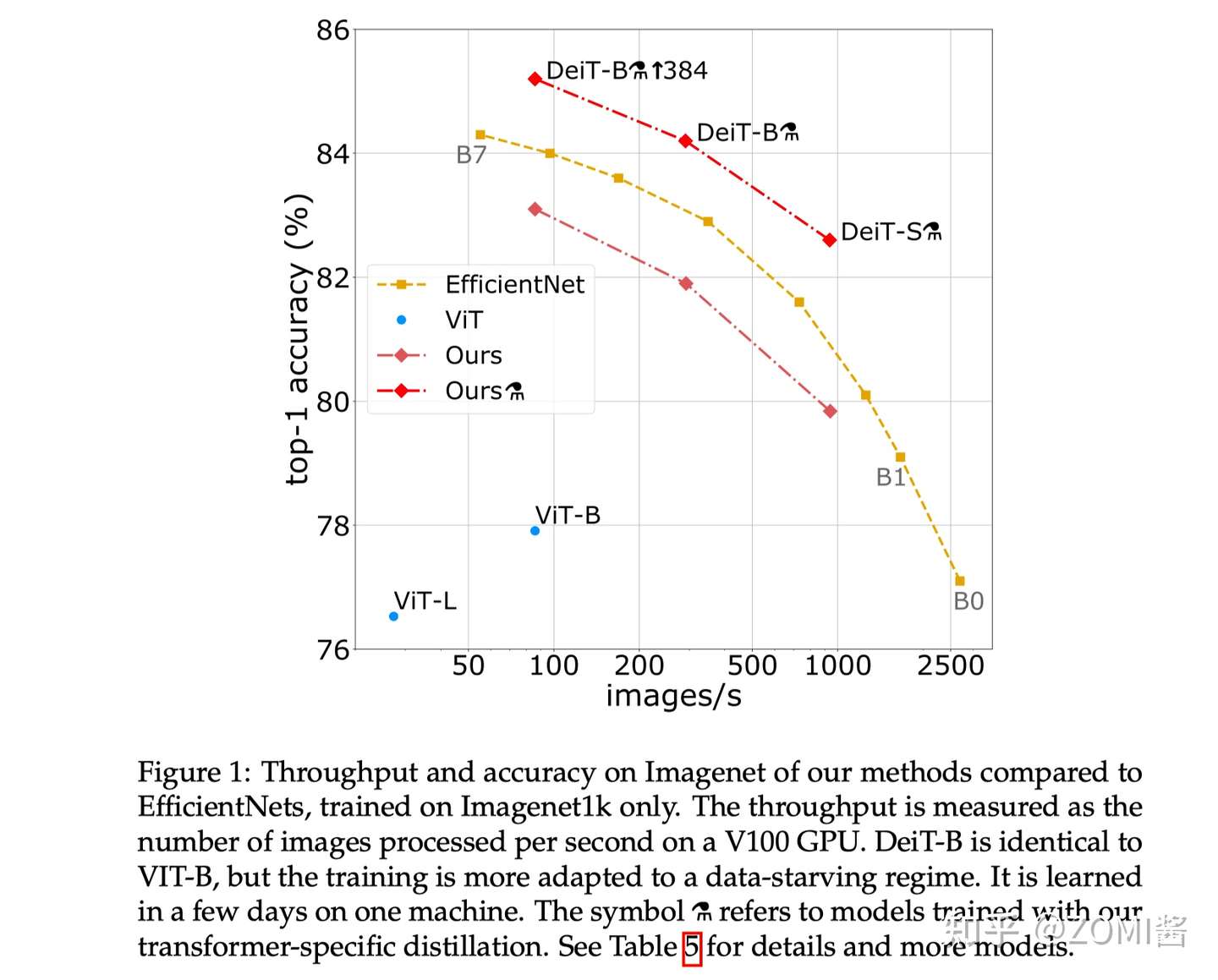
DeiT 相关背景
ViT 文中表示数据量不足会导致 ViT 效果变差。针对以上问题,DeiT 核心共享是使用了蒸馏策略,能够仅使用 ImageNet-1K 数据集就就可以达到 83.1% 的 Top1。
那么文章主要贡献可以总结为三点:
- 仅使用 Transformer,不引入 Conv 的情况下也能达到 SOTA 效果。
- 提出了基于 token 蒸馏的策略,针对 Transformer 蒸馏方法超越传统蒸馏方法。
- DeiT 发现使用 Convnet 作为教师网络能够比使用 Transformer 架构效果更好。
正式了解 DeiT 算法之前呢,有几个问题需要去了解的:ViT的缺点和局限性,为什么训练ViT要准备这么多数据,就不能简单快速训练一个模型出来吗?另外 Transformer 视觉模型又怎么玩蒸馏呢?
ViT 的缺点和局限性
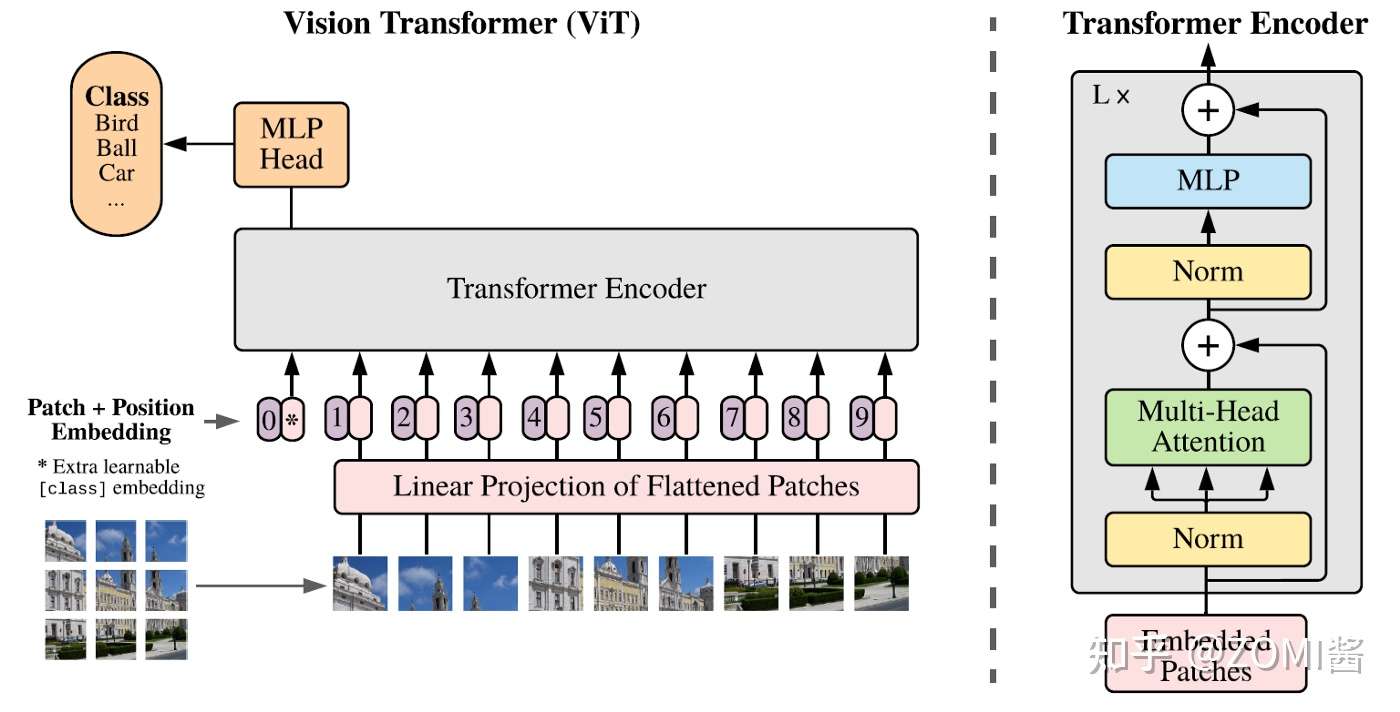
Transformer的输入是一个序列(Sequence),ViT 所采用的思路是把图像分块(patches),然后把每一块视为一个向量(vector),所有的向量并在一起就成为了一个序列(Sequence),ViT 使用的数据集包括了一个巨大的包含了 300 million images的 JFT-300,这个数据集是私有的,即外部研究者无法复现实验。而且在ViT的实验中作者明确地提到:
"That transformers do not generalize well when trained on insufficient amounts of data."
意思是当不使用 JFT-300 大数据集时,效果不如CNN模型。也就反映出Transformer结构若想取得理想的性能和泛化能力就需要这样大的数据集。DeiT 作者通过所提出的蒸馏的训练方案,只在 Imagenet 上进行训练,就产生了一个有竞争力的无卷积 Transformer。
ViT 相关技术点
Multi-head Self Attention layers (MSA):
首先有一个 Query 矩阵 Q 和一个 Key 矩阵 K,把二者矩阵乘在一起并进行归一化以后得到 attention 矩阵,它再与Value矩阵 V 相乘得到最终的输出得到 Z。最后经过 linear transformation 得到 NxD 的输出结果。
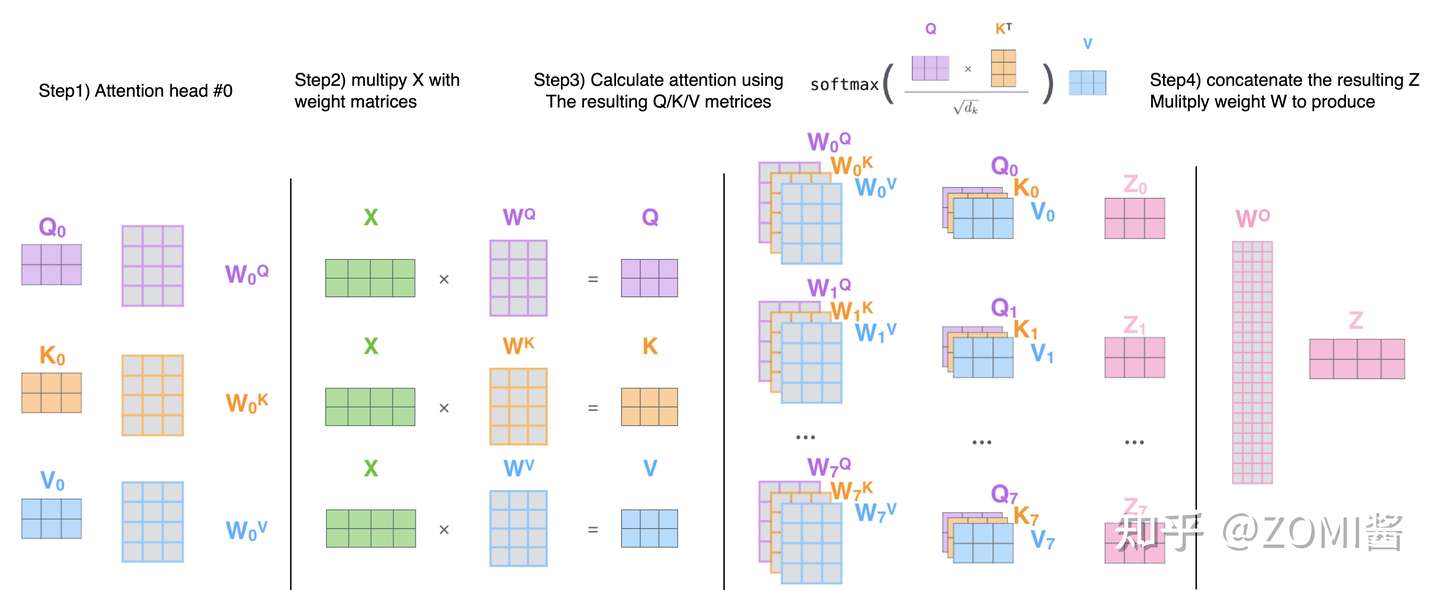
Feed-Forward Network (FFN):
Multi-head Self Attention layers 之后往往会跟上一个 Feed-Forward Network (FFN) ,它一般是由2个linear layer构成,第1个linear layer把维度从 D 维变换到 ND 维,第2个linear layer把维度从 ND 维再变换到 D 维。
此时 Transformer block 是不考虑位置信息的,基于此 ViT 加入了位置编码 (Positional Encoding),这些编码在第一个 block 之前被添加到 input token 中代表位置信息,作为额外可学习的embedding(Extra learnable class embedding)。
Class token:
Class token 与 input token 并在一起输入 Transformer block 中,最后的输出结果用来预测类别。这样一来,Transformer 相当于一共处理了 N+1 个维度为 D 的token,并且只有第一个 token 的输出用来预测类别。
知识蒸馏介绍
Knowledge Distillation(KD)最初被 Hinton 提出 “Distilling the Knowledge in a Neural Network”,与 Label smoothing 动机类似,但是 KD 生成 soft label 的方式是通过教师网络得到的。
KD 可以视为将教师网络学到的信息压缩到学生网络中。还有一些工作 “Circumventing outlier of autoaugment with knowledge distillation” 则将 KD 视为数据增强方法的一种。
虽然在一般情况下,我们不会去区分训练和部署使用的模型,但是训练和部署之间存在着一定的不一致性。在训练过程中,我们需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
- 推理速度和性能慢
- 对部署资源要求高(内存,显存等)
在部署时,对延迟以及计算资源都有着严格的限制。因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题,而“模型蒸馏”属于模型压缩的一种方法。
知识蒸馏使用的是 Teacher—Student 模型,其中 Teacher 是“知识”的输出者,Student 是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练 "Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
论文中,Hinton 将问题限定在分类问题下,或者其他本质上属于分类问题的问题,该类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。知识蒸馏时,由于已经有了一个泛化能力较强的Net-T,我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。
其中KD的训练过程和传统的训练过程的对比:
- 传统training过程 Hard Targets: 对 ground truth 求极大似然 Softmax 值。
- KD的training过程 Soft Targets: 用 Teacher 模型的 class probabilities作为soft targets。
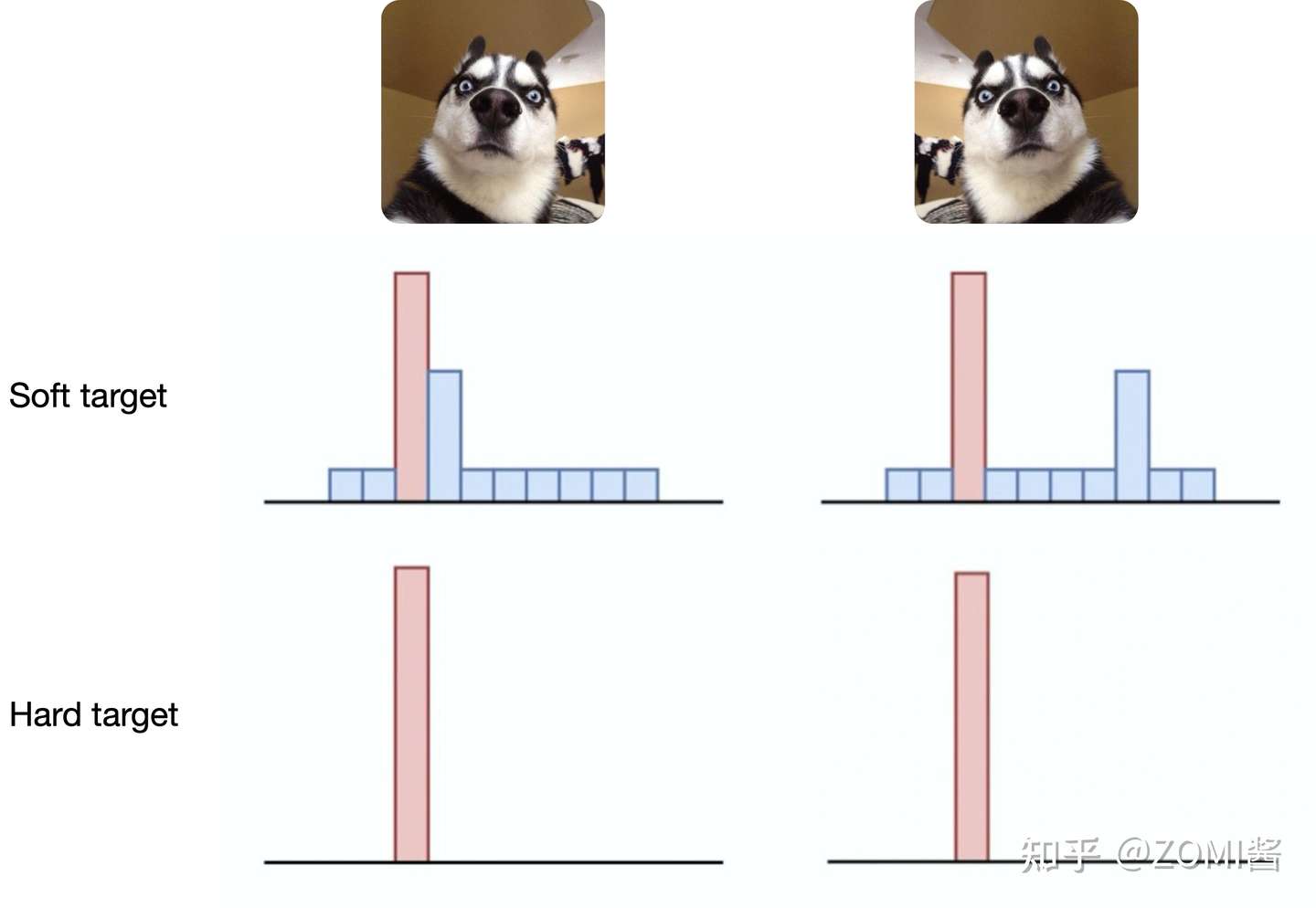
这就解释了为什么通过蒸馏的方法训练出的 Net-S 相比使用完全相同的模型结构和训练数据只使用Hard Targets的训练方法得到的模型,拥有更好的泛化能力。
第一步是训练Net-T;第二步是在高温 T 下,蒸馏 Net-T 的知识到 Net-S。
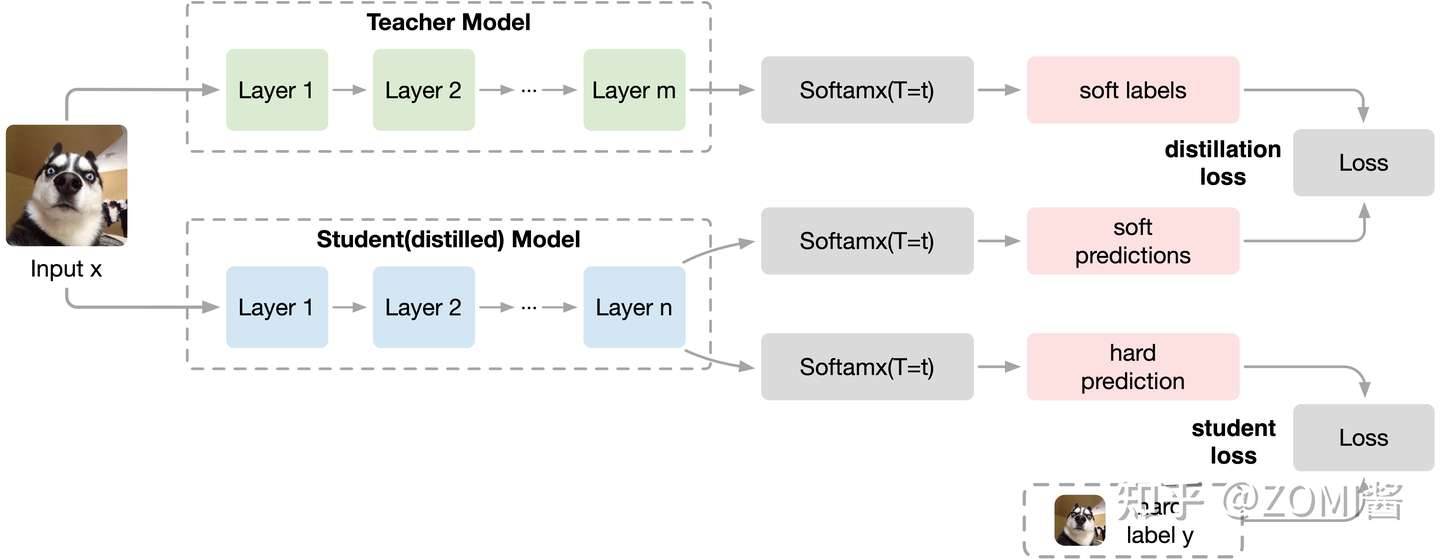
训练 Net-T 的过程很简单,而高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到:
Deit 中使用 Conv-Based 架构作为教师网络,以 soft 的方式将归纳偏置传递给学生模型,将局部性的假设通过蒸馏方式引入 Transformer 中,取得了不错的效果。
DeiT 具体方法
为什么DeiT能在大幅减少 1. 训练所需的数据集 和 2. 训练时长 的情况下依旧能够取得很不错的性能呢?我们可以把这个原因归结为DeiT的训练策略。ViT 在小数据集上的性能不如使用CNN网络 EfficientNet,但是跟ViT结构相同,仅仅是使用更好的训练策略的DeiT比ViT的性能已经有了很大的提升,在此基础上,再加上蒸馏 (distillation) 操作,性能超过了 EfficientNet。
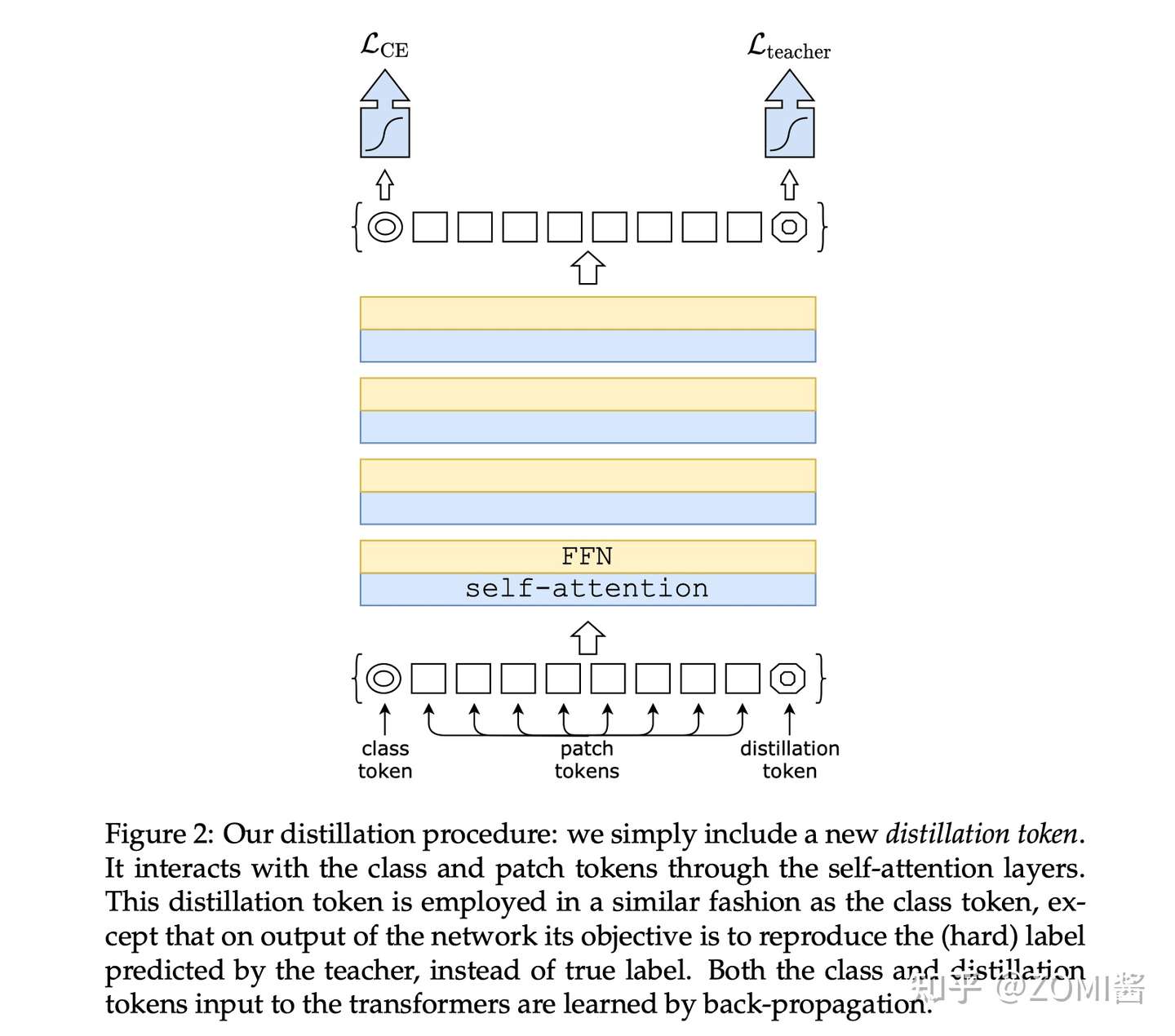
假设有一个性能很好的分类器作为teacher model,通过引入了一个 Distillation Token,然后在 self-attention layers 中跟 class token,patch token 在 Transformer 结构中不断学习。
Class token的目标是跟真实的label一致,而Distillation Token是要跟teacher model预测的label一致。
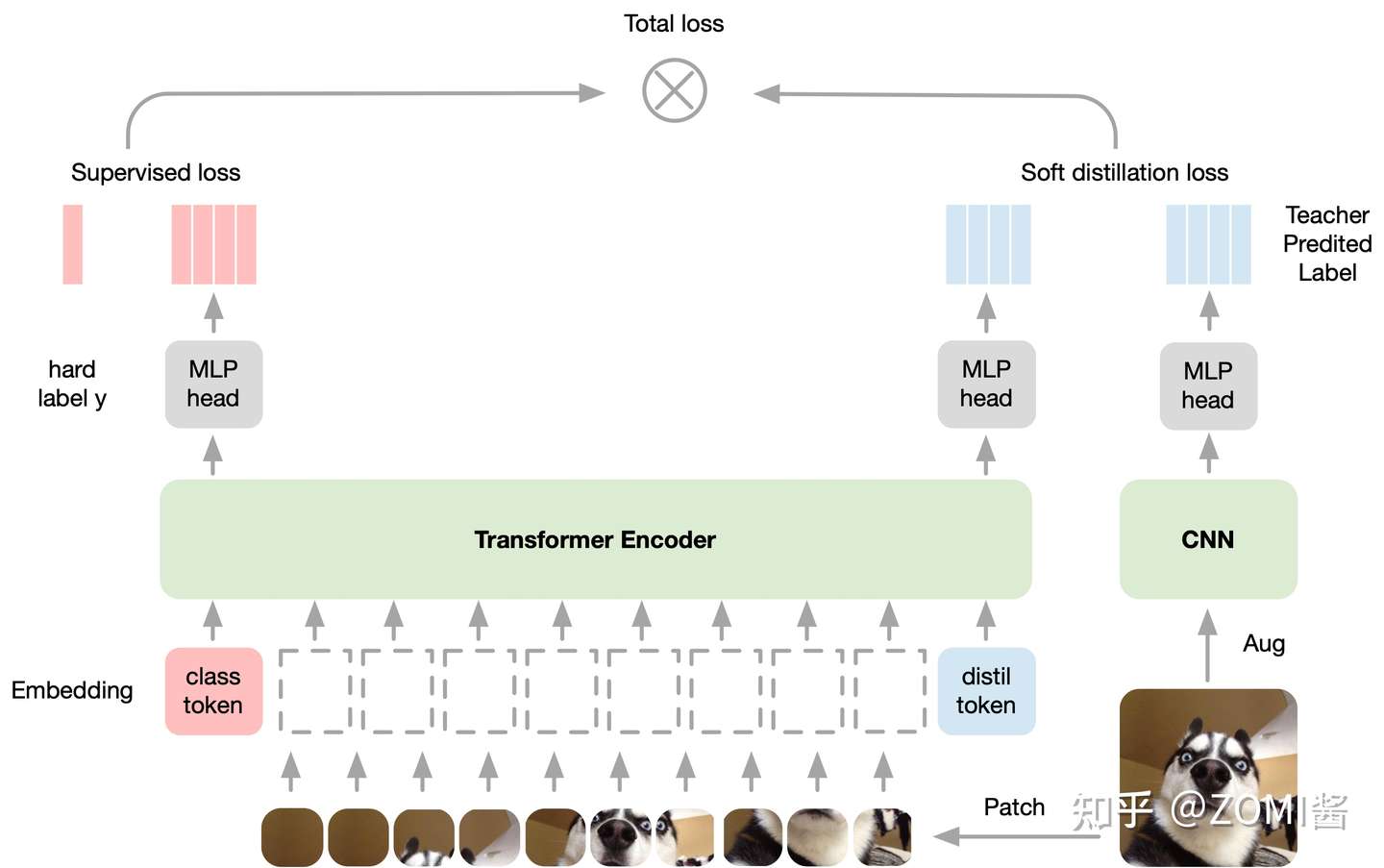
对比 ViT 的输出是一个 softmax,它代表着预测结果属于各个类别的概率的分布。ViT的做法是直接将 softmax 与 GT label取 CE Loss。
而在 DeiT 中,除了 CE Loss 以外,还要 1)定义蒸馏损失;2)加上 Distillation Token。
- 定义蒸馏损失
蒸馏分两种,一种是软蒸馏(soft distillation),另一种是硬蒸馏(hard distillation)。软蒸馏如下式所示,Z_s 和 Z_t 分别是 student model 和 teacher model 的输出,KL 表示 KL 散度,psi 表示softmax函数,lambda 和 tau 是超参数:
硬蒸馏如下式所示,其中 CE 表示交叉熵:
学生网络的输出 Z_s 与真实标签之间计算 CE Loss 。如果是硬蒸馏,就再与教师网络的标签取 CE Loss。如果是软蒸馏,就再与教师网络的 softmax 输出结果取 KL Loss 。
值得注意的是,Hard Label 也可以通过标签平滑技术 (Label smoothing) 转换成Soft Labe,其中真值对应的标签被认为具有 1- esilon 的概率,剩余的 esilon 由剩余的类别共享。
- 加入 Distillation Token
Distillation Token 和 ViT 中的 class token 一起加入 Transformer 中,和class token 一样通过 self-attention 与其它的 embedding 一起计算,并且在最后一层之后由网络输出。
而 Distillation Token 对应的这个输出的目标函数就是蒸馏损失。Distillation Token 允许模型从教师网络的输出中学习,就像在常规的蒸馏中一样,同时也作为一种对class token的补充。
DeiT 具体实验
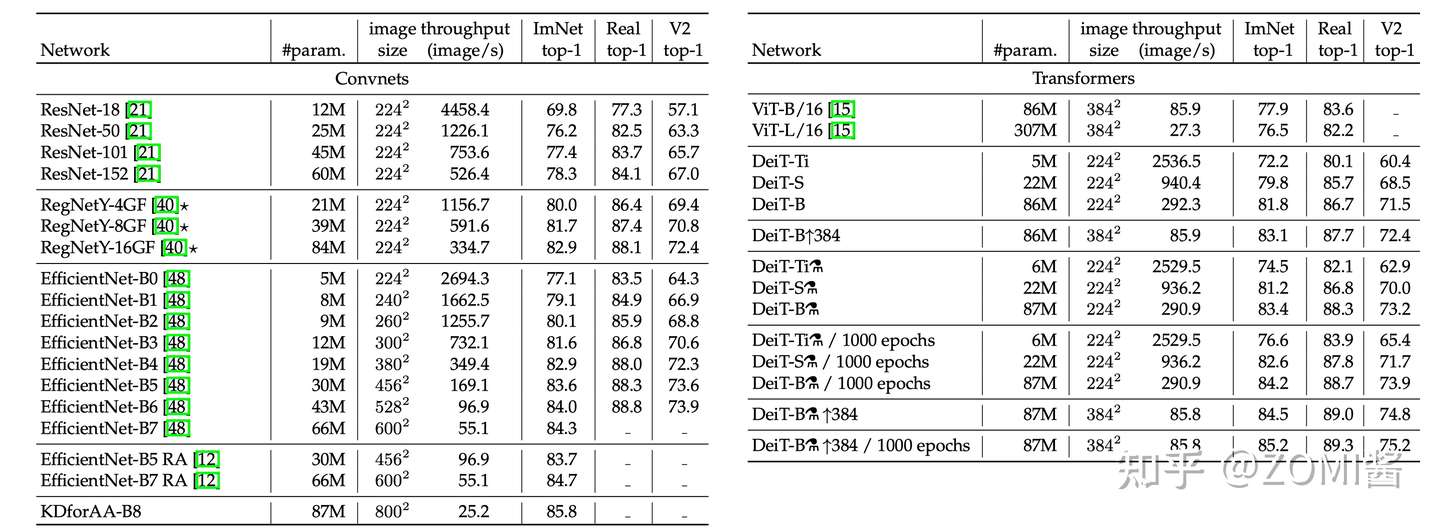
实验参数的设置:图中表示不同大小的 DeiT 结构的超参数设置,最大的结构是 DeiT-B,与 ViT-B 结构是相同,唯一不同的是 embedding 的 hidden dimension 和 head 数量。作者保持了每个head的隐变量维度为64,throughput是一个衡量DeiT模型处理图片速度的变量,代表每秒能够处理图片的数目。

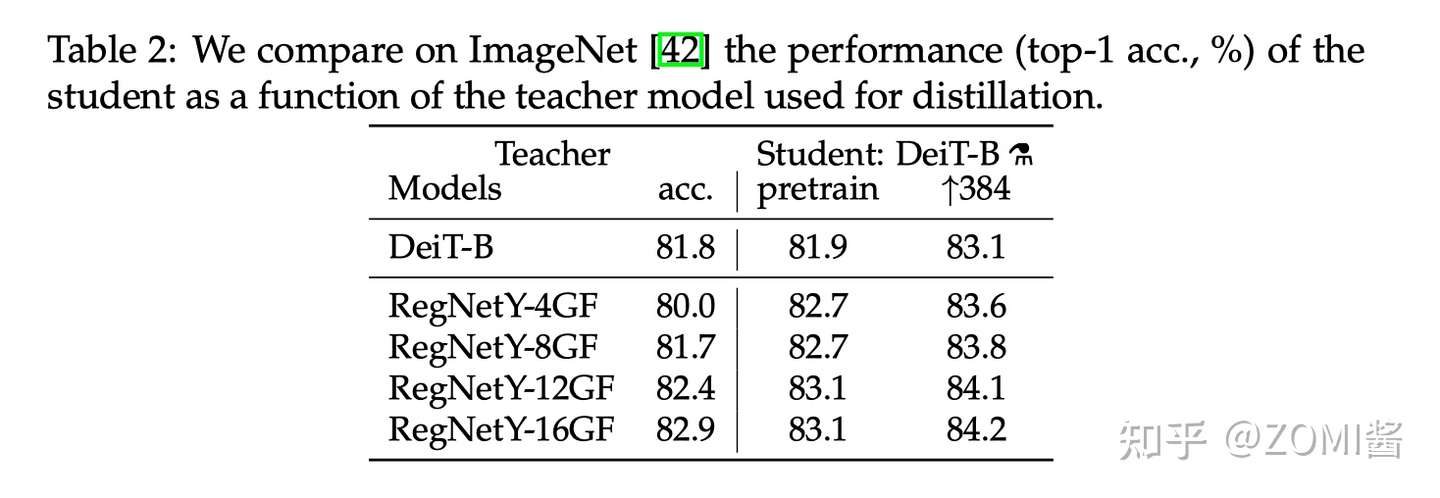
- Teacher model对比
作者首先观察到使用 CNN 作为 teacher 比 transformer 作为 teacher 的性能更优。下图中对比了 teacher 网络使用 DeiT-B 和几个 CNN 模型 RegNetY 时,得到的 student 网络的预训练性能以及 finetune 之后的性能。
其中,DeiT-B 384 代表使用分辨率为 384×384 的图像 finetune 得到的模型,最后的那个小蒸馏符号 alembic sign 代表蒸馏以后得到的模型。
- 蒸馏方法对比
下图是不同蒸馏策略的性能对比,label 代表有监督学习,前3行分别是不使用蒸馏,使用soft蒸馏和使用hard蒸馏的性能对比。前3行不使用 Distillation Token 进行训练,只是相当于在原来 ViT 的基础上给损失函数加上了蒸馏部分。
对于Transformer来讲,硬蒸馏的性能明显优于软蒸馏,即使只使用 class token,不使用 distill token,硬蒸馏达到 83.0%,而软蒸馏的精度为 81.8%。
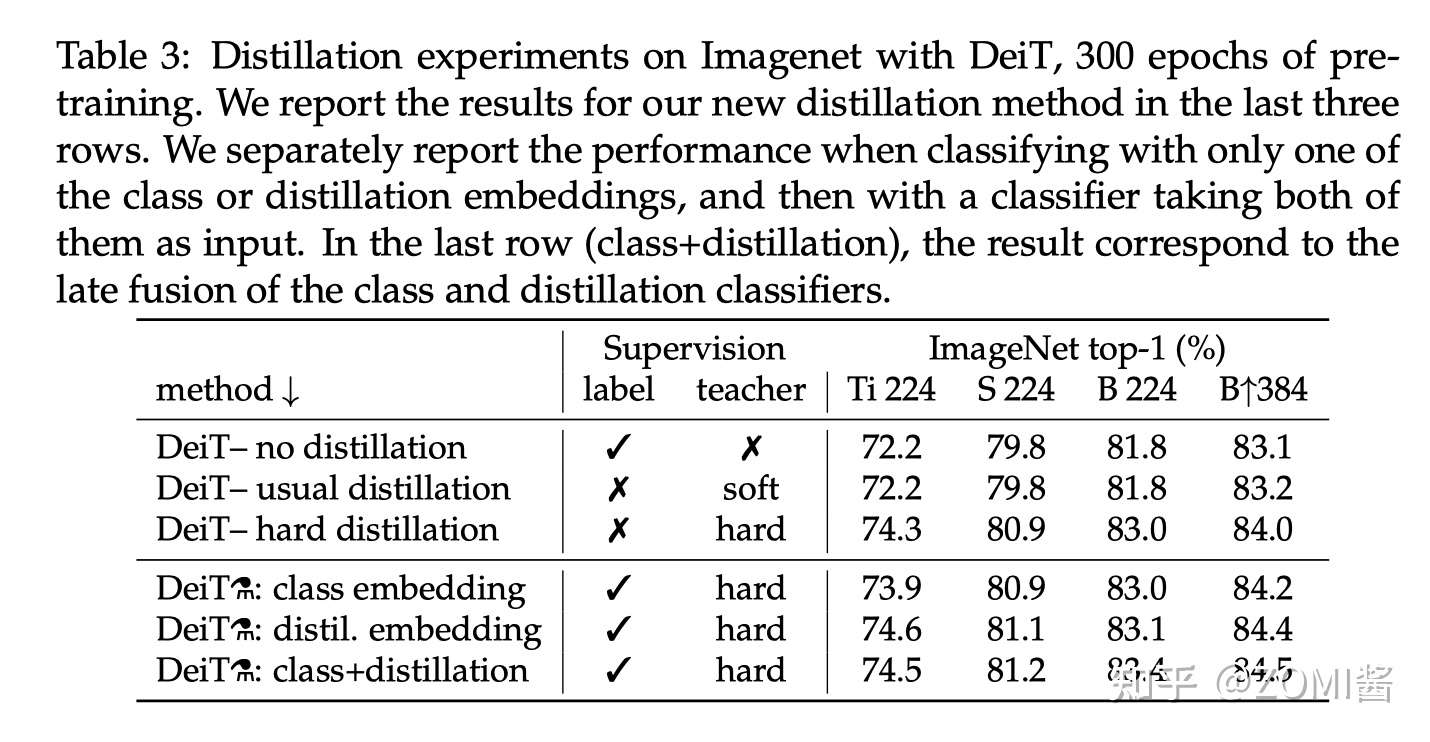
从最后两列 B224 和 B384 看出,以更高的分辨率进行微调有助于减少方法之间的差异。这可能是因为在微调时,作者不使用教师信息。随着微调,class token 和 Distillation Token 之间的相关性略有增加。
除此之外,蒸馏模型在 accuracy 和 throughput 之间的 trade-off 甚至优于 teacher 模型,这也反映了蒸馏的有趣之处。
下面是不同模型性能的数值比较。可以发现在参数量相当的情况下,卷积网络的速度更慢,这是因为大的矩阵乘法比小卷积提供了更多的优化机会。EffcientNet-B4和DeiT-B alembic sign的速度相似,在3个数据集的性能也比较接近。
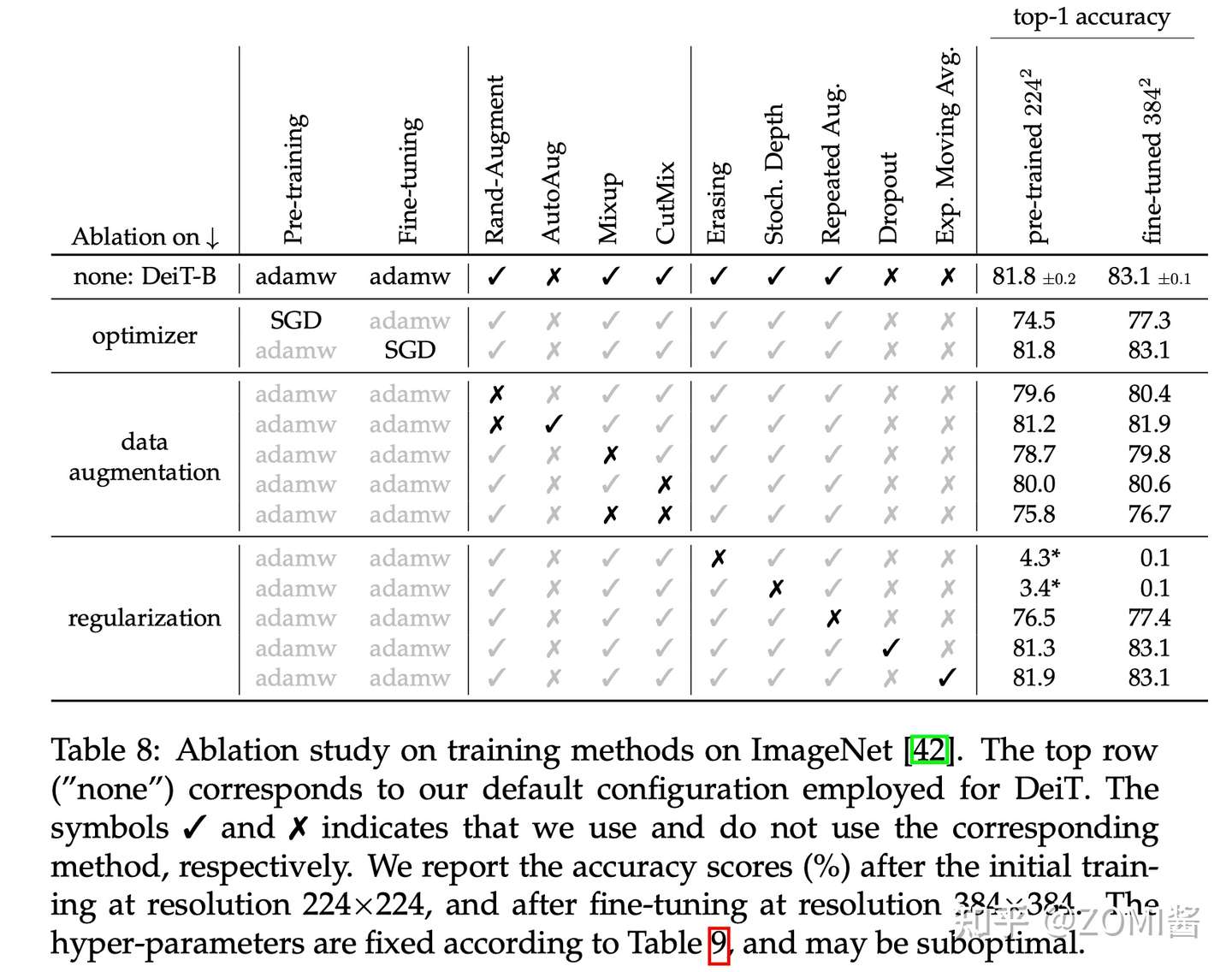
作者还做了一些关于数据增强方法和优化器的对比实验。Transformer的训练需要大量的数据,想要在不太大的数据集上取得好性能,就需要大量的数据增强,以实现data-efficient training。几乎所有评测过的数据增强的方法都能提升性能。对于优化器来说,AdamW比SGD性能更好。
此外,发现Transformer对优化器的超参数很敏感,试了多组 lr 和 weight+decay。stochastic depth有利于收敛。Mixup 和 CutMix 都能提高性能。Exp.+Moving+Avg. 表示参数平滑后的模型,对性能提升只是略有帮助。最后就是 Repeated augmentation 的数据增强方式对于性能提升帮助很大。
DeiT 模型(8600万参数)仅用一台 GPU 服务器在 53 hours train,20 hours finetune,仅使用 ImageNet 就达到了 84.2 top-1 准确性,而无需使用任何外部数据进行训练,性能与最先进的卷积神经网络(CNN)可以抗衡。其核心是提出了针对 ViT 的教师-学生蒸馏训练策略,并提出了 token-based distillation 方法,使得 Transformer 在视觉领域训练得又快又好。
[1] https://zhuanlan.zhihu.com/p/349315675
[2] DeiT:使用Attention蒸馏Transformer
[3] https://zhuanlan.zhihu.com/p/102038521
[4] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 2.7 (2015).
[5] Touvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention." International Conference on Machine Learning. PMLR, 2021.
[6] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[7] Wei, Longhui, et al. "Circumventing outliers of autoaugment with knowledge distillation." European Conference on Computer Vision. Springer, Cham, 2020.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK