

Spark SQL for Relational Databases
source link: https://www.analyticsvidhya.com/blog/2022/07/spark-sql-for-relational-databases/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

This article was published as a part of the Data Science Blogathon.
Introduction
.jpg)
However, the scale has always been an issue with relational databases. Most businesses in the 21st century are loaded with rich data stores and repositories and want to make the most of their big data for actionable insights. Relational databases may be popular, but they don’t scale very well if we don’t invest in the right big data management strategy. This includes thinking about potential data sources, data volumes, constraints, schemas, extract-transform-load (ETL), query approaches and patterns, and much more!
-
Motivations and challenges with scaling relational databases
- Understanding of Spark SQL & DataFrames
- Objectives
- Architecture and features
- Performance
Motivations and Challenges to Scale Relational Databases for big data
- Building ETL pipelines to and from various data sources can lead to the development of a large amount of specific custom code, increasing technical debt over time
- Ability to perform both traditional business intelligence (BI)-based analytics and advanced analytics (machine learning, statistical modelling, etc.), challenging to achieve in relational systems.
Since then, several frameworks and systems such as Hive, Pig, and Shark (which evolved into Spark SQL) have provided rich relational interfaces and declarative query mechanisms to big data stores. However, the challenge remained that these tools were either relational or procedural, and we couldn’t have the best of both worlds.
Understanding Spark SQL and DataFrames
- It provides a DataFrame API that allows you to perform large-scale relational operations on external data sources and Spark’s built-in distributed collections.
- To support a wide variety of different data sources and algorithms in Big Data, Spark SQL introduces a new extensible optimizer called Catalyst, which makes it easy to add data sources, optimization rules, and data types for advanced analytics like machine learning.
Objectives
- Deliver high performance using established DBMS techniques
- Easily support new data sources, including semi-structured data and external databases for query federation
- Enable extensions with advanced analytics algorithms such as graph processing and machine learning
Architecture and Features
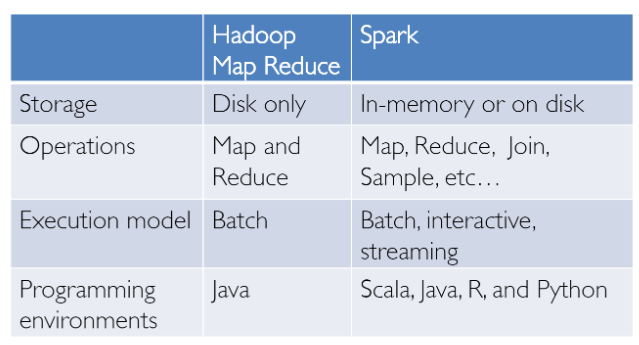
The Spark ecosystem
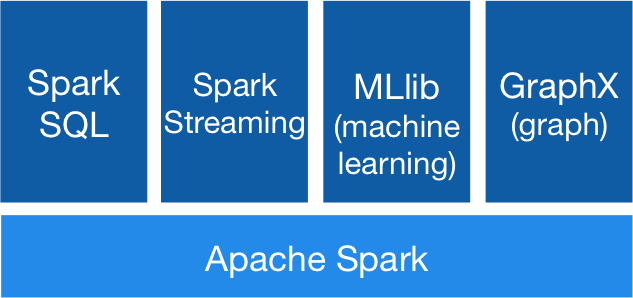
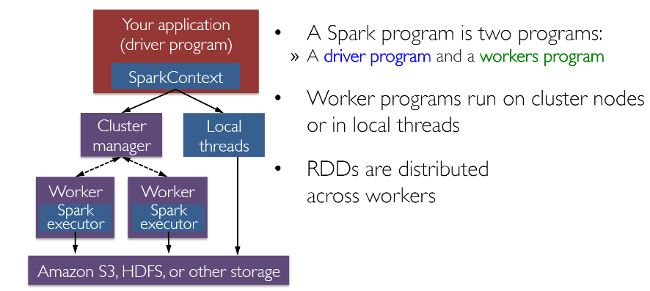
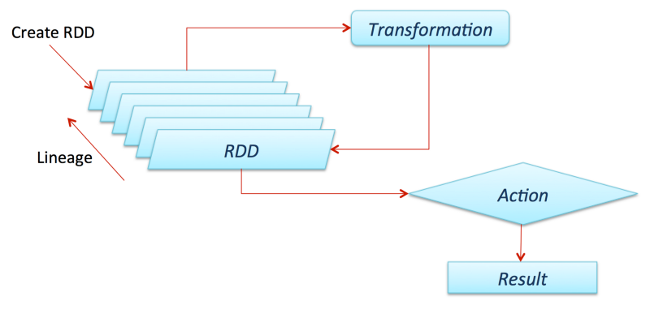
Spark works with drivers and workers. You can usually create RDDs by loading data from files, databases, existing parallelizing collections, or transformations. Transformations are generally operations that can transform data into different aspects and dimensions depending on how we want to handle and process the data. Unfortunately, they are also lazily evaluated, meaning that even if you define a transformation, the results won’t be calculated until you use an action, which usually requires the development to be returned to the driver program (and it will then calculate any transformations applied!).
Thanks to fellow data scientist and friend Favio Vázquez and his excellent article “Deep Learning With Apache Spark, ” I got some great ideas and content, including the previous image. Look at it!
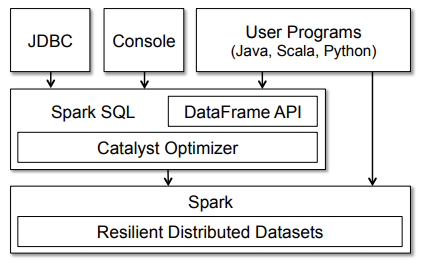
The figure clearly shows the various SQL interfaces that can be accessed via JDBC/ODBC or the command-line console and the DataFrame API integrated into Spark’s supported programming languages (we’ll be using Python). The DataFrame API is robust and allows users to mix procedural and relational code! Advanced functions such as UDFs (User Defined Functions) can also be exposed in SQL that BI tools can use.
A Spark DataFrame is a distributed collection of rows (row types) with the same schema. It’s a Spark dataset organised into named columns. It should be noted here that datasets are an extension of the DataFrame API that provides a type-safe, object-oriented programming interface. So they’re only available in Java and Scala, so we’ll focus on DataFrames.
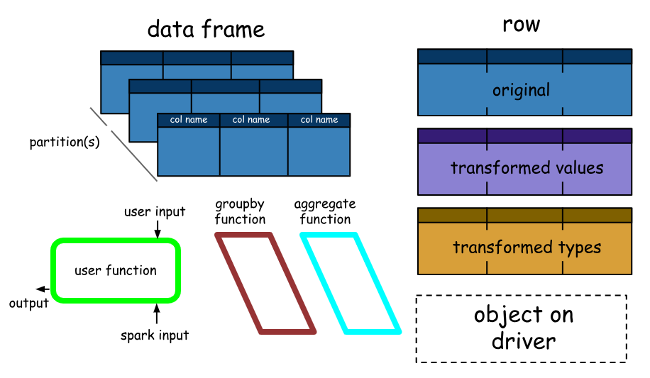
- DataFrames can be constructed from tables, like existing Hive tables in your Big Data infrastructure, or even from existing RDDs.
- DataFrames can be manipulated using direct SQL queries and DataFrame DSL (domain-specific language), where we can use various relational operators and transformers like where and groupBy.
- Each DataFrame can also represent an RDD of row objects, allowing users to call procedural Spark APIs such as maps.
- Finally, given, but always remember, unlike traditional data frame APIs (Pandas), Spark’s data frames are lazy because each DataFrame object represents a logical plan for computing a dataset. Still, no execution occurs until the user calls a special “output operation” such as saving.
Performance
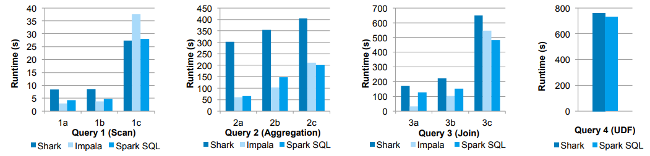
Performance comparisons in these experiments, they compared the performance of Spark SQL against Shark and Impala using the AMPLab Big Data benchmark, which uses a web analytics workload developed by Pavle et al. The model includes four query types with different parameters performing a scan, aggregation, join, and UDF-based MapReduce job. The dataset contained 110 GB of data after compression using the Parquet columnar format. We see that in all queries, Spark SQL is significantly faster than Shark and generally competitive with Impala. The most significant gap from Impala is in Query 3a, where Impala chooses a better join plan because query selectivity makes one of the tables very small.
Conclusion
In addition to being an open source project, Spark SQL has begun to gain mainstream industry adoption. It has already been deployed in massive environments. Facebook has an excellent case study on “Apache Spark @Scale: 60 TB+ Production Use Case.”
-
Relational data stores are easy to create and query. However, users and developers often prefer to write quickly interpretable declarative queries in a human-readable language such as SQL.
- RDD is perhaps the most significant contributor to all Spark success stories. It is essentially a data structure or a distributed memory abstraction.
- A Spark Data Frame is a distributed collection of rows (row types) with the same schema. It’s a Spark dataset organized into named columns.
Reference:
Image Source:
- https://en.wikipedia.org/wiki/Apache_Spark
- https://spark.apache.org/docs/2.1.2/streaming-programming-guide.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK