

I Scraped 30,000 Stocks From eToro — Here’s How
source link: https://medium.com/@ajay_613/i-scrapped-30-000-stocks-from-etoro-heres-how-1f26608084a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


I Scraped 30,000 Stocks From eToro — Here’s How
You may be wondering — What possessed me to do such a thing in the first place?!
Well, for the past few weeks I have been working on launching my first Google Chrome extension (you can read about the saga here).
I named the extension — ‘Finviz Screener X eToro’.
I couldn’t think of a better name but it gets the job done.
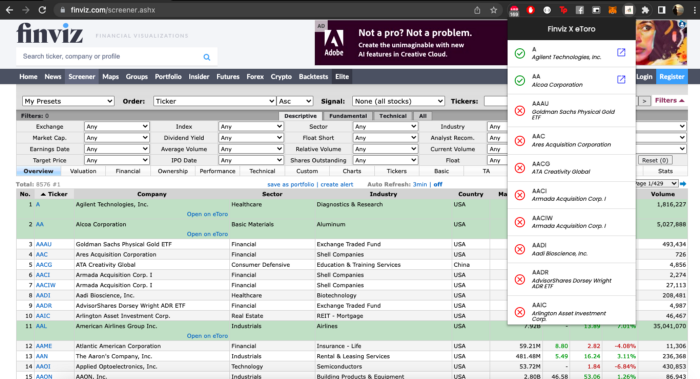
With the help of this extension, you can instantly check if a particular stock on Finviz actually exists on eToro or not. This way you eliminate the whole process of manually checking eToro stock by stock.
For this concept to work, I had to find a way to query eToro’s data based on the results shown on the Finviz Stock Screener.
Unfortunately, eToro didn’t have a production ready API that I could’ve used for this.
So I decided to take matters into my own hands and build my own API. And for that, I had to scrape eToro for the stock data that I need.
The Game Plan
My first instinct was to use PHP cause that’s what I’m most familiar with but it wasn’t the right tool for the job.
Reason being, eToro groups the stocks by industry, and the index for each industry can only be accessed if you’re logged in.
So to get around this, I decided to use PuppeteerJS instead.
PuppeteerJS is basically a Node library that allows you to programmatically run a Chrome / Chromium instance (I honestly don’t know the difference between the two), and you can use it to automate testing, web scraping, etc.
So my high level game plan:
- Set up the node / puppeteer project
- Figure out a way to log into eToro programmatically
- Navigate to the categories page, and scrape the stock tickers, name, and price
- Save the data in a DB
As always, I’m going to focus on functionality and not reusability / structure. So I’m gonna put on my chef’s hat, and cook up this spaghetti code that’s going to make my life easier.
1. Setting up the project
Here’s all you need to get started:
I had this all installed, so I just went ahead and created my project folder, ran npm init (pressed enter all the way through), and I created a file called index.js via the terminal (command: touch index.js).
I then ran this command in the terminal:
npm i puppeteer
Once npm did its thing, I just copied over the example code (from the documentation) over to my index.js file (made a slight alteration), and I executed the file with node (type this in your terminal: node index.js).
Result:

Worked like a charm. I can navigate to the login page without any issues.
I can now start amending the code. I can get rid of the screenshot part, and I’m also going to comment out the browser.close() line while I figure things out.
2. Log in programmatically
To be honest, I tried figuring out the documentation by myself but it was quite overwhelming. Even after years of being a developer, I still struggle with relying solely on documentation.
So I went over to YouTube, and came across this video from Tom Baranowicz, and he did an amazing job introducing PuppeteerJS, and how how it works.
The general gist of it:
- find a selector
- Use puppeteer’s methods to manipulate the selector. The most common methods I used to get this done:
- page.type(selector, text, options) // Allows you to type a text into an input field
- page.click(selector, options) // click an element. good for submitting forms etc.,
- page.waitForNavigation(); // if the page redirects, just wait for the new page to load
- page.goto(url) // if you know the url, just navigate to the url
- page.waitForTimeout(1000) // pause execution for some time
Next I went over to eToro, right-clicked and selected the Inspect Element option to see how the HTML was structured.
All the HTML elements on eToro have an automation-id that you could simply reference, and that makes things so much easier.
E.g: selector for the username input box = input[automation-id=”login-sts-username-input”]

Switch windows to my VSCode, and I started typing away in the index.js file.
I used the page.goto method to navigate to the login page.
Then, I used the page.type method to enter the email & password, and the page.click method to press the button.
const browser = await puppeteer.launch({
headless: false,
});const page = await browser.newPage();console.log('going to the login page'); // Navigate to the login page
await page.goto('<https://etoro.com/login>');await page.waitForSelector('input[automation-id="login-sts-username-input"]');console.log(`Typing the email: ${email}`); await page.type('input[automation-id="login-sts-username-input"]', email, {
delay: 25
}); console.log(`Typing the password: ${password}`); await page.type('input[automation-id="login-sts-password-input"]', password, {
delay: 25,
});console.log('wait for .5 seconds before finding the login button');
await page.waitForTimeout(1000);
console.log('click the login button');
await page.click('button[automation-id="login-sts-btn-sign-in"]');
Result:
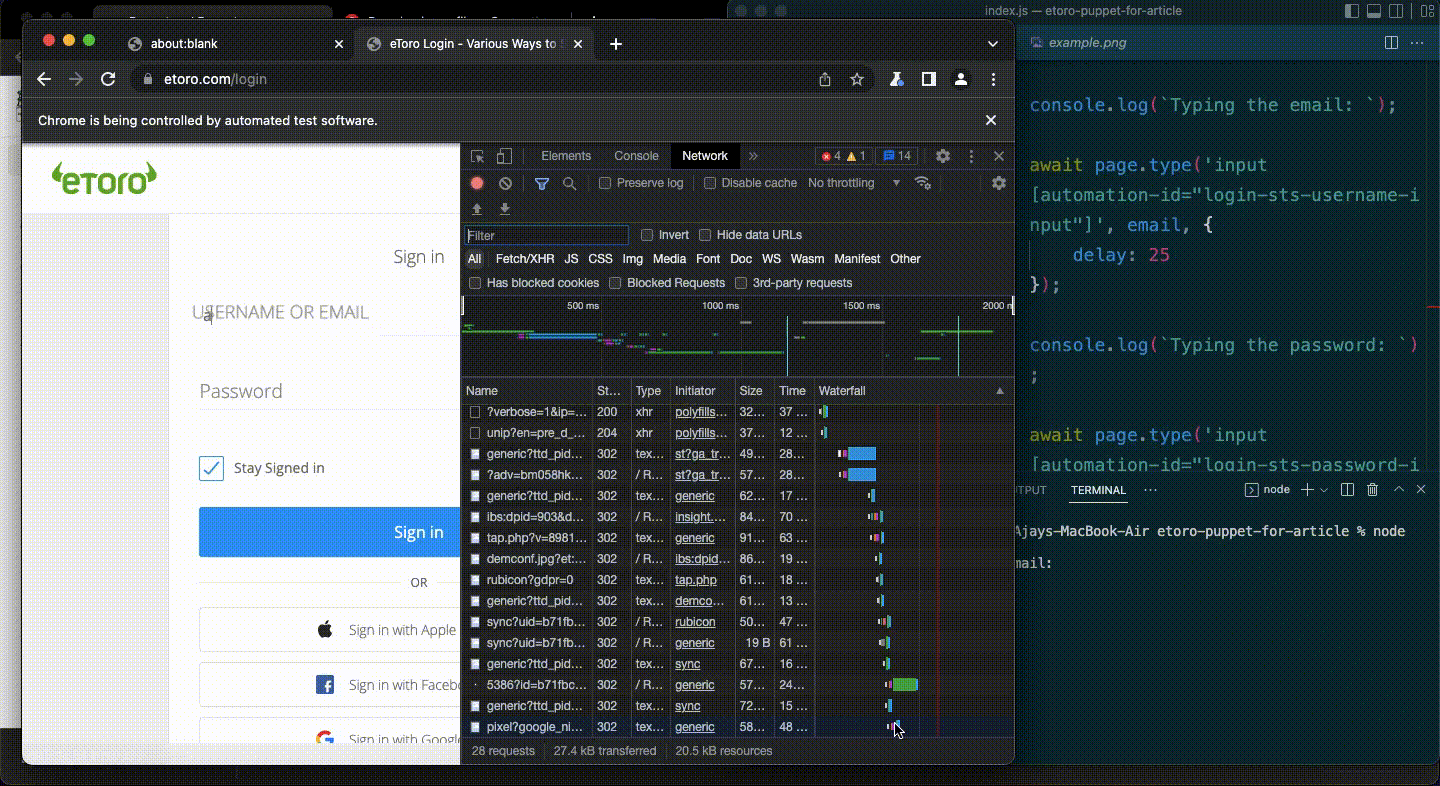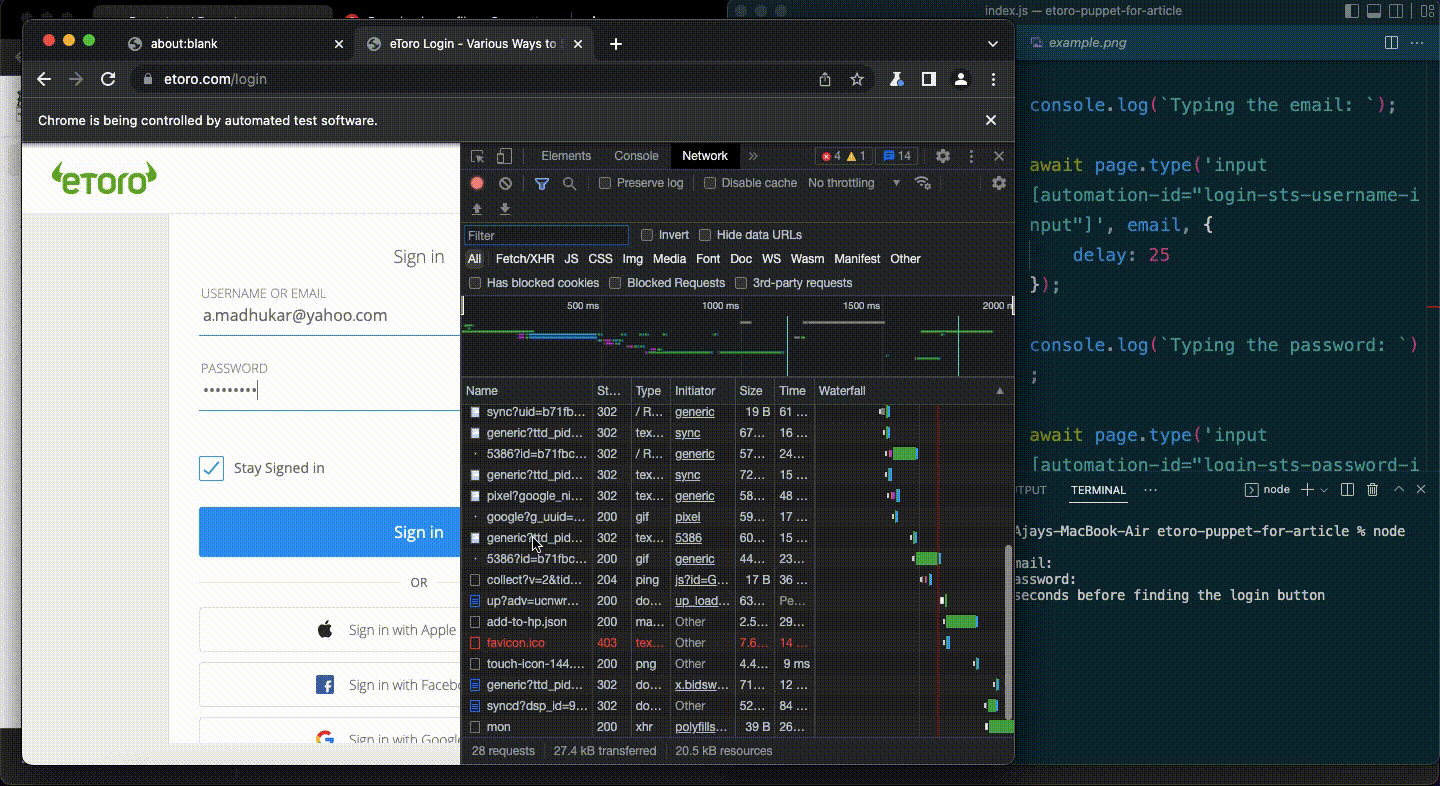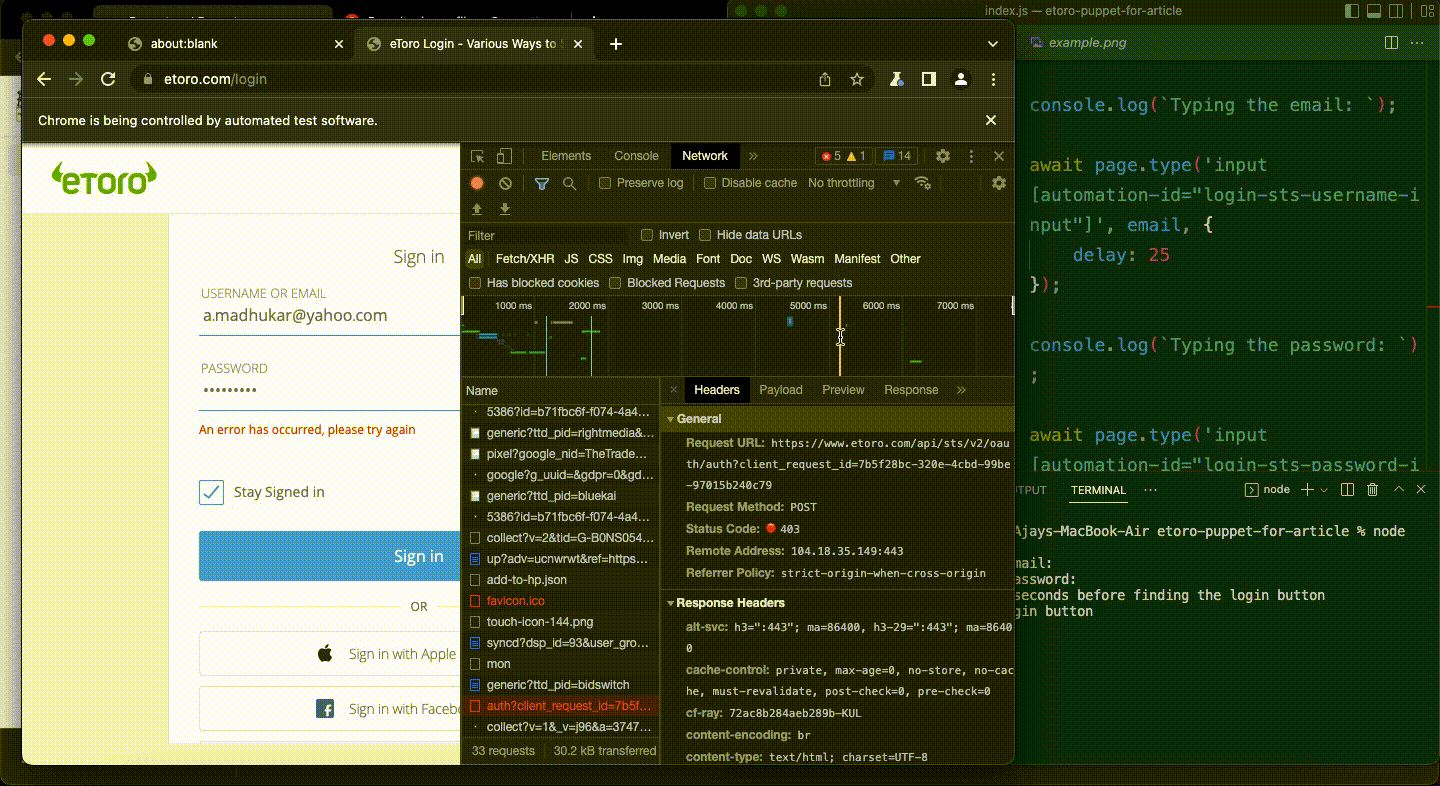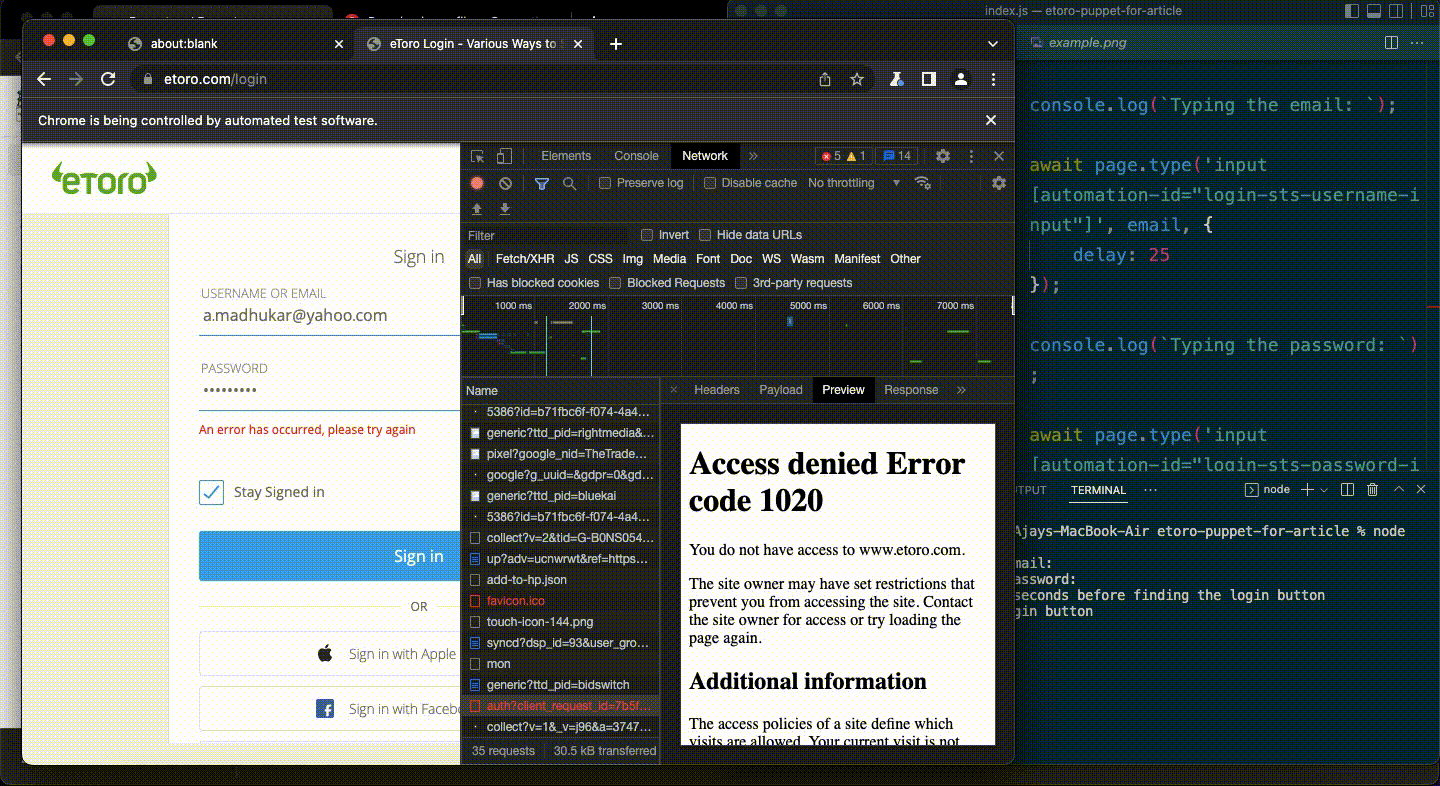
And then boom.
I was greeted with an error message — ”An error has occurred, please try again”
I had zero idea of what this message actually meant.
So I headed over to Stackoverflow to find a workaround.
Turns out the issue was eToro had some mechanisms in place to keep bots (like me) away from their system.
So the solution was to camouflage the bot as a human by pulling in 2 new packages via npm.
I updated my code like so:
const puppeteer = require('puppeteer-extra');(async () => {
// Add stealth plugin and use defaults (all tricks to hide puppeteer usage)
const StealthPlugin = require('puppeteer-extra-plugin-stealth')
puppeteer.use(StealthPlugin()) const browser = await puppeteer.launch({
headless: false,
});
const page = await browser.newPage();
await page.goto('<https://etoro.com/login>');
// await page.screenshot({ path: 'example.png' }); await page.waitForTimeout(1000); const email = '[email protected]';
const password = 'insertyourownpassword'; console.log(`Typing the email: `); await page.type('input[automation-id="login-sts-username-input"]', email, {
delay: 25
}); console.log(`Typing the password: `); await page.type('input[automation-id="login-sts-password-input"]', password, {
delay: 25,
}); console.log('wait for .5 seconds before finding the login button'); await page.waitForTimeout(1000); console.log('click the login button'); await page.click('button[automation-id="login-sts-btn-sign-in"]'); // await browser.close();
})();
And then boom. I was in.
Result:

Moving on to the fun stuff…
3. Scraping the stock tickers, name, and price
At this point, all I had to do was find a list of stocks on eToro that were categorised by industry. I took a leap of faith, went over to google, and typed in “eToro tech industry”.
Voila! The first link took me straight to Technology industry’s stocks on eToro. They had about 369 results, so I figured, I’d scrape this data first, and then tackle the other industries (in the dropdown).
I right-clicked on the first result, and selected the inspect element option, and I made a note of the selector I’d need to use ⇒ et-instrument-trading-row.

In the same index.js file, I used the page.goto method first, and then page.$$eval method (equivalent to the document.querySelectorAll method) to get an array of rows.
The code:
let etoroUrl = '<https://www.etoro.com/discover/markets/stocks/industry/technology>'; console.log('Navigating to ' + etoroUrl); await page.goto(etoroUrl);console.log('wait for 1 second');await page.waitForTimeout(1000);console.log('wait for selector on the page');await page.waitForSelector('et-instrument-trading-row');const instrumentTradingRows = await page.$$eval('et-instrument-trading-row', (rows) => {
console.log('rows', rows[0], rows[1]);
});
Result:

Simple enough.
Next, I amended the page.$$eval method like so to return an object of attributes that I could save to the DB.
const instrumentTradingRows = await page.$$eval('et-instrument-trading-row', (rows) => { return rows.map(row => {
let attributes = row.children[0].innerText.split('\\n') console.log('attributes', attributes); return {
ticker: attributes[0],
name: attributes[1],
sellPrice: attributes[5] * 100,
buyPrice: attributes[7] * 100,
link: '<https://www.etoro.com/markets/>' + attributes[0]
};
'});});
Finally, I just followed this guide to save the array of results into the DB: https://www.w3schools.com/nodejs/nodejs_mysql.asp
And with that, I had the basic flow up and running. All that was left was to wrap everything in a for loop (created an object with all the urls), and I sat back and watched eToro get scraped 30,000 times.
Key Lessons Learnt
This lesson is a must.
Always open up the url in the incognito mode to properly check if the page is actually protected by an authentication layer.
Cause if it’s not, you can just scrape the url right away without worrying about the authentication.
In my case, I skipped this step, and I assumed I had to login. And so I spent a significant amount of time getting the automated login part working/
That being said, it wasn’t all a waste of time.
I did learn about the Puppeteer-extra package & the StealthPlugin, both of which are very handy.
Overall Development Experience
One word — Great!
After watching Tom Baranowicz’s video on YouTube, it all made sense, and it got me past the initial struggle of finding my way via the documentation.
All in all, Puppeteer’s API is super intuitive, and if you can memorise just a few methods, you’ll be quite productive the next time you take up a project.
In summary, I think I enjoy the overall process of scraping other people’s web apps to help resolve a problem that I was personally facing.
Let me know if you’d like me to write about scraping a different web app!
And that’s enough programming for this week.
Also Read: How I Revamped And Officially Launched My First Chrome Extension
Also if you enjoy my work and you’d like to support what I do, you could consider buying me a coffee here.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK