

ICRA 2022 | 基于多模态变分自编码器的任意时刻三维物体重建
source link: https://zhuanlan.zhihu.com/p/483906051
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ICRA 2022 | 基于多模态变分自编码器的任意时刻三维物体重建
论文题目:Anytime3D Object Reconstruction Using Multi-Modal Variational Autoencoder
论文地址:https://arxiv.org/abs/2101.10391
论文来源:IEEERobotics and Automation Letters (accepted with ICRA2022 options)
作者:夏初 文章来源:微信公众号「3D视觉工坊」
摘要
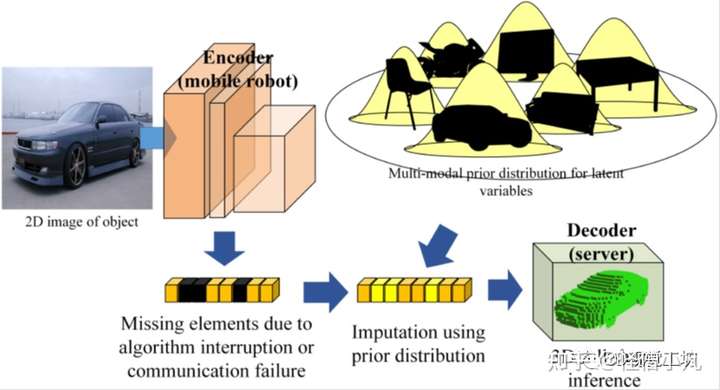
对于有效的人-机器人团队,机器人能够与人类操作员分享他们的视觉感知是很重要的。在苛刻的远程协作环境中,可以利用autoencoder等数据压缩技术以紧凑的形式获取和传输潜在变量的数据。此外,为了确保即使在不稳定的环境下也能获得实时运行性能,需要一种能够从不完整信息中重建完整内容的随时估计方法。在此背景下,研究人员提出了一种方法来插补部分缺失元素的潜在变量。为了在只有几个变量维度的情况下实现anytime属性,利用类别级别的先验信息至关重要。在变分自动编码器中使用的先验分布被简单地假设为各向同性高斯分布,而与每个训练数据点的标签无关。这种类型的平坦先验使得难以从类别水平分布进行插补。研究人员通过在潜在空间中利用特定类别的多模态先验分布来克服这一限制。通过根据剩余元素找到特定模态,可以对部分传输数据中缺失的元素进行采样。由于该方法旨在使用部分元素进行任何时间的估计,因此也可用于数据过压缩。基于ModelNet和Pascal3D数据集上的实验,所提出的方法与自编码器(AE)和变分自编码器(VAE)相比表现出一致的优越性能,数据丢失率高达70%。
研究贡献
1.使得三维重建中具有随时可用的属性:为了只使用编码向量的部分元素完全执行重建,研究人员引入了缺失元素插补方法。研究人员的方法不仅考虑了整个训练数据点的潜在空间,还考虑了缺失数据插补任务的特定类别分布。研究人员在AE结构上验证了研究人员的方法,因为大多数3D-3D或2D-3D网络可以通过使用中间输出作为潜在变量实现AE。在AE(或VAE)的情况下,研究人员可以按分类顺序收集从训练数据中获得的潜在变量;可以获得每个类别的模态。因此,在训练后,可以找到最接近丢失的潜在变量的模态,以表示潜在向量的标签。通过从该模式中采样缺失元素,可以进行缺失数据插补。
2.利用特定类别多模态先验的思想来实现VAE:该方法可以保障潜在空间按类别很好地分开,使得通过传输向量的剩余元素找到相应类别的模态。假设每个维度在潜在空间中是独立的,并且每个元素都被训练为投影到特定于类别的多模态分布上,即训练网络进行元素分类聚类。通过寻找包含不完全潜在变量部分元素的正确模式,从插补的过程中恢复潜在向量。这些恢复的潜在变量可以由解码器转换为完全重建的三维形状。3.可应用于鲁棒的三维形状估计,既可以防止由于不稳定网络造成的数据丢失,也可以防止由于任意压缩导致的部分丢弃。
研究方法
A. Priorof AE and VAE for Element Imputation
对于对象表示,让I和x分别表示观察到的2D或3D感官数据及其3D形状;设z为从编码器传输的N维潜在向量。针对由于算法突然中断而丢失z的某些元素,以及AE中缺失足够的先验信息,在这种情况下,通过对不完整的潜在变量从p(z)中采样来检索缺失元素,由于先验分布定义为各向同性,采样的潜在变量的平均值接近于零向量。然后,可以大概地对缺失元素的潜在变量进行数据插补,如下所示:
B. Category-SpecificMulti-Modal Prior for Element Imputation
为了获得类别或实例的先验知识,从而保证每个模态都遵循高斯分布且彼此远离,研究人员根据每个对象的类别标签,利用了具有多模态先验分布的VAE。这个先验知识可以表示:
其中,µ函数作为先验网络实现。先验网络用于自动查找每个模态的参数。在训练的一开始,参数被随机初始化。这些参数是网络根据类别的输出,可以通过训练进行更新;在KL散度损失下,先验分布中的每一个模态获取潜在变量,并且也跟随潜在变量。在附加限制损失的情况下,每个模态都被强制遵循高斯分布,并且彼此移动得很远,以便相互区分。训练结束后,研究人员只需在实际运行时间之前将特定参数输入到经过训练的先验网络,即可获得每个类别。根据平均场理论,研究人员可以假设潜在向量的每个元素遵循独立的高斯分布。因此,研究人员可以选择只有部分潜在变量元素的最接近模式,并按如下方式进行插补:
C. ModalSelection
提取不完全向量的关键是找到与原始潜变量对应的先验模态。根据平均场定理,可以假设每个维度都是独立的。因此,对于不完整的潜变量z,可以通过以下元素方式比较先验模态,找到与原始z对应的最佳标签l:
分类中仅使用潜在变量和多模态先验元素执行,其中潜在变量没有丢失。由于假设先验的每个模态都是高斯的,所以计算并比较了元素距离的总和。为了使这种方法保持不变,潜在空间中先验分布的每一个模态应该通过一定的距离阈值或更大的距离彼此分离。为了满足这个条件,研究人员在训练多模态VAE时,在两个不同的标签之间增加了一个约束:
潜在空间的每个维度遵循独立的多模态分布,每个模态根据标签变得可区分。因此,仅使用潜在变量的一些非缺失元素就可以找到目标模式,并且可以从所选模式中实现元素级插补。
D.Dropout for Element Pruning
研究人员的方法是只使用数据点的部分元素进行任何时间的鲁棒重建,或采用其他方案。这些方法的目的是不同的,因为它们不执行插补,常应用于语音识别或分类。但上下文是相似的,因为它们使用部分元素或部分网络。因此,在研究人员的方法中,可以在训练期间采用elementpruning或elementmasking,以便执行元素插补和重建。因此,即使在向量的某些元素被裁剪时,解码器也会被训练来执行重建,从而可以实现更健壮的随时重建算法。
E.Decoder and Prior Distribution
在训练完全收敛后,研究人员可以找到不完全变量的特定类别的模态,并进行补充。随后,解码器可以实现鲁棒的三维重建。然而,由于变分似然在实际中很难精确地逼近先验,因此使解码器适应先验分布也可以灵活地处理插补过程中的潜在变量。因此,研究人员将期望项替换为:
实验
为了验证所提出的方法,研究人员使用ModelNet40数据集进行三维对象观察、传输和三维重建,使用Pascal3D数据集进行二维图像中的对象检测、传输和三维估计。ModelNet40中每个类别包含40个类和大约300个实例,Pascal3D中每个类别包含10个类和10个实例。研究人员将Pascal3D和ModelNet40的潜在维度设置为64。在传输潜在变量时,由于意外中断或压缩率过高,某些元素可能会被拒绝传输。因此,在本实验中,元素的失败率设置为30%、50%、70%和90%。对于三维形状信息,研究人员将CAD模型转换为643个具有二进制变量的体素网格。由于Pascal3D数据集中也有多对象场景的图像,研究人员使用边界框对图像进行裁剪。
A.Classification
对于ModelNet40,与基于AE和VAE的方法相比,本研究方法显示出更高的准确率。在研究中,假设维度相互独立,每个元素遵循一维多模态先验,因此即使在潜在变量的大部分元素丢失的情况下,分类任务也能相对较好地执行。此外,dropout通常会提高AE和VAE的性能,但不会对本研究中的方法产生一定的影响。
对于Pascal3D+,本研究中的方法性能更好,但与ModelNet40相比,没有显示出高性能差距。研究人员认为Pascal3D+只有10个类,因此与ModelNet40有40个类的情况相比,它更容易执行分类。此外,Pascal3D+具有高分辨率RGB图像作为输入,与低分辨率的3D模型相比,更容易提取功能丰富的信息。
B.Reconstruction
在ModelNet40中,除AE和VAE外的所有方法都显示出更好的重建性能,在保持与插补前相同的精度的情况下,实现了较高的效果。在Pascal3D+中,本研究中的方法显示了显著改善。
总结
在恶劣环境或低带宽通信网络下的人-机器人协作环境中,实时目标观测和传输可能会中断或失败,因此只能传输压缩数据的部分元素。为了在不稳定环境下支持鲁棒的实时人-机器人协作,研究人员提出了一种考虑特定类别多模态分布的随时重构方法。虽然AE和VAE已被用作压缩和解码数据的关键结构,但由于其先验分布的简单性,基于丢失元素进行重建仍然是一项挑战。为了实现类别级的插补和完整的三维形状重建,研究人员利用了潜在空间的多模态先验分布思想。与普通VAE不同,该方法中的每个模态都是在训练时自动确定的,并且包含特定类别的信息。利用这种先验分布,研究人员仅利用潜在空间中的传输元素来确定潜在变量的模式。通过从所选模型中输入采样变量,研究人员可以稳健地实现潜在向量检索和三维形状重建。本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:dddvision,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK