

CVPR2021| 基于自监督学习的多视图立体匹配
source link: https://zhuanlan.zhihu.com/p/509191956
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
CVPR2021| 基于自监督学习的多视图立体匹配
Self-supervised Learning of Depth Inference for Multi-view Stereo (CVPR2021)
代码地址:Github: https://github.com/JiayuYANG/Self-supervised-CVP-MVSNet
Self-sup CVP-MVSNet
作者:Todd-Qi |来源:https://mp.weixin.qq.com/s/B-BYtorum_JJHR0360AwUg
简介尽管近年来基于深度学习的多视图立体匹配(Multi-view Stereo, MVS)取得了显著的进展,但是这些方法通常依赖于大量标注的数据,然而多视图深度估计的真值标签数据获取是比较具有挑战性的。因此文本提出一种适用于多视图立体匹配的自监督学习框架,此框架采用了两阶段的训练策略。具体地,第一阶段基于图像重建损失进行网络模型的无监督学习,第二阶段是基于伪标签的自监督学习,生成的伪标签是通过多视图深度估计进行融合得到的。实验结果表明,Self-sup. CVP-MVSNet在无监督学习方法中的重建性能最好,并取得了与有监督方法性能相当的重建效果。
预备知识1: CVP-MVSNet网络回顾Cost Volume Pyramid Based Depth Inference for Multi-view Stereo (CVPR2020)
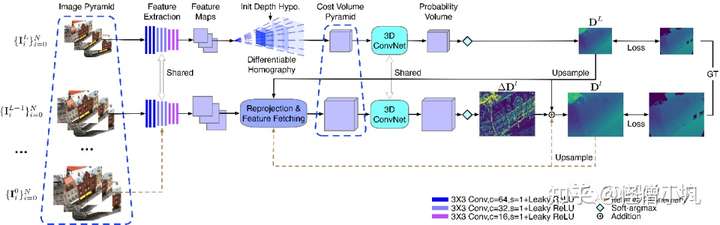
图1 CVP-MVSNet网络架构图CVP-MVSNet为基于coarse-to-fine的多视图深度估计网络架构,首先对参考图像和源图像进行下采样得到图像金字塔,然后利用共享权重的特征提取网络为所有尺度的图像进行特征提取,提取的特征通过单应变换构建代价体。通过最低分辨率的代价体回归出低分辨率的深度图,然后在后续的阶段通过代价体预测深度图的残差。CVP-MVSNet中用于代价体正则化的3D ConvNet在不同尺度间是特征的,并且支持使用低分辨率图像训练,高分辨率图像测试。
预备知识2: 无监督/自监督学习的MVS方法回顾Learning Unsupervised Multi-view Stereopsis via Robust Photometric Consistency (CVPRW2019)以UnsupMVS方法为例,无监督的多视图立体匹配是指在没有ground-truth深度图的情况下,利用多视图的光度一致性进行监督的方法。具体地,在网络训练过程中借助了图像重建损失:基于网络预测的深度图,将源图像投影至参考视图下,计算参考图像与投影变换后的源图像之间的光度差异,多视图图像之间的光度差异即为网络训练的监督信号。考虑到多视图之间可能存在遮挡,因此在计算光度损失的时候采用了TopK的策略。即计算M=6幅源图像之间的光度损失,但是只选取K=3幅最小的误差计算损失项。
图2 鲁棒的光度一致性损失计算
预备知识3: DTU数据集的预处理流程DTU数据集提供了带有法向信息的点云,MVSNet论文在数据预处理阶段对点云进行表面重建,得到表面网格模型,又因为DTU数据集提供了每幅视角下相机位姿,因此可以将表面网格渲染至每幅视图下得到对应的深度图,渲染得到的深度图即为网络训练的ground-truth。
图3 自监督学习的CVP-MVSNet算法框架
Self-sup CVP-MVSNet方法部分第一阶段:利用无监督学习对网络进行初始化
在自监督学习的第一阶段,利用多视图的光度一致性进行初始深度图的估计。以CVP-MVSNet为骨干网络,采用了基于概率的图像合成方式进行图像重建损失的计算。通过概率体P和图像intensity volume进行视图合成。计算合成图像与参考图像之间的光度差异。无监督学习采用了视图合成损失用于保证参考图像和合成图像之间的光度一致性以及预测深度图的平滑性。无监督学习的光度一致性损失为:式中为图像梯度损失,为图像结构相似性损失,为图像感知损失,为深度图的光滑性损失,用于调整不同损失项的权重。
图4 基于概率的图像合成
第二阶段:基于伪标签的自监督迭代训练
图5 伪标签生成流程示意图利用高分辨率的图像进行深度图预测,利用多视图几何一致性对初始深度图进行过滤,将过滤后的深度图进行点云融合,得到三维空间中的点云,再通过泊松表面重建,得到重建点云的表面网格模型,然后通过渲染得到每幅视角下的深度图。渲染得到的深度图即为网络模型自监督训练的伪标签。
实验结果
通过本文两阶段的自监督训练策略得到的网络模型Self-sup. CVP-MVSNet取得了和有监督学习方法性能相当的性能,在DTU和Tanks and Temples数据集的重建效果如下表所示。
参考文献
1、Self-supervised Learning of Depth Inference for Multi-view Stereo, CVPR20212、Cost volume pyramid based depth inference for multi-view stereo, CVPR20203、Learning unsupervised multi-view stereopsis via robust photometric consistency, CVPRW20194、Mvsnet: Depth inference for unstructured multi-view stereo, ECCV2018
基于深度学习的多视图立体匹配(Multi-view Stereo, MVS)算法汇总 https://github.com/XYZ-qiyh/Awesome-Learning-MVS
备注:作者也是我们「3D视觉从入门到精通」
特邀嘉宾:一个超干货的3D视觉学习社区本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:http://3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:dddvision,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK