

作为前端工程师,还不会用redis嘛
source link: https://jelly.jd.com/article/62c7a5b13c111b019d66573f
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文会从四个角度进行介绍,Redis是什么,概述,应用场景以及在前端监控平台的应用:

Redis是什么?--典型的Nosql数据库

1.Nosql发展背景
1.1 单机Mysql的年代
纵观历史,互联网的发展,最开始就是单机Mysql的年代。
图中的APP可以看作是网站应用,它不是直接访问我们的mysql,它会通过一些方法,也就是DAL(数据库访问层),之后才会进入我们Mysql的实例。这是我们最早的一个模型。
90年代,一个基本的网站访问量一般不会太大,单个数据库完全足够!大家可以想一下,那个时候用互联网的人一共才有有多少呢。
那个时候,人们更多的去使用静态网页html~(例如 http://www.hao123.com/ 网站),我觉得大家一定知道hao123的网站吧,hao123并不是一个大型网站,而是一个导航网站,它把所有网站的链接聚焦起来,形成一个平台。所以说这样的网站,服务器根本没有太大的压力!单机Mysql就足够用了!
思考一下,这种情况下:网站的瓶颈是什么?
1)数据量如果太大,一个机器放不下了!况且现在是大数据的时代!
2)数据的索引,我们知道mysql的索引,单表超过300万,就一定要建立索引了,不建立索引的话,相对来说查询会比较慢。索引太多的话,一个机器的内存也放不下。
3)数据库的访问量比较大,最开始是读写混合的,它是一体的,会造成性能问题,服务器承受不了
只要我们的网站出现了上面的三种情况之一,我们就一定要晋级升级!

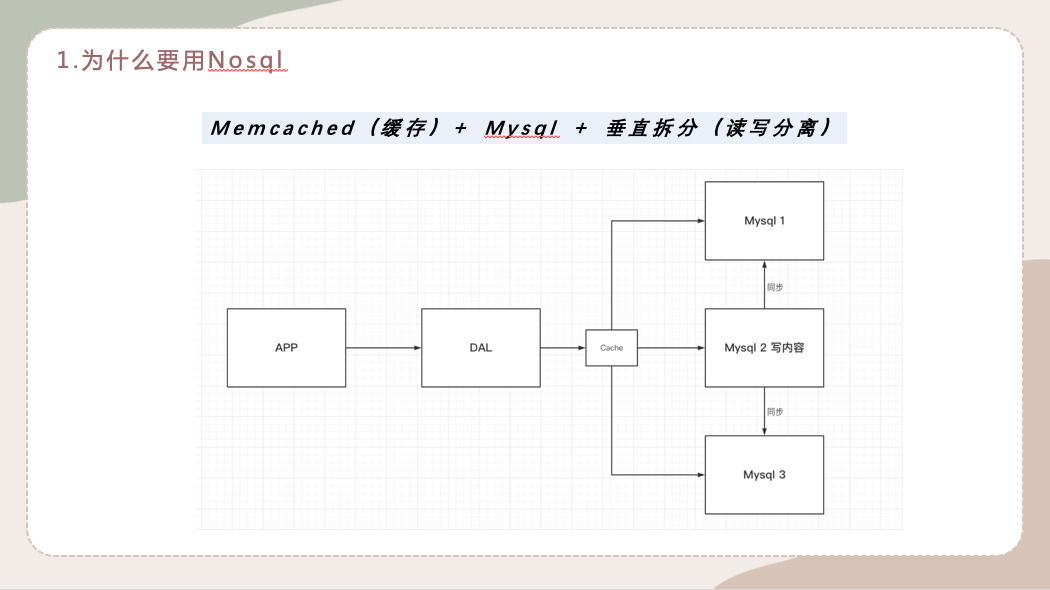
1.2 Memcached(缓存) + Mysql + 垂直拆分(读写分离)的方式
就是说一台服务器不够用了,以图中举例,这里我们变成三台服务器。首先我们要保证三台服务器数据是一致的,我们2号数据库负责来写文件,1号和3号数据库负责把2号数据库写的内容同步过去。
说白了就是把所有写的操作都放在2号数据库上,我们的1和3只是为了数据的同步,那么我们真正要读的时候就从1和3中去读,这就叫读写分离。
然后我们得知道一种现象,网站80%的情况都是在读,每次都要去查询数据库的话就会十分的麻烦!举个最简单的例子,比如说张三去查1号商品,李四又来查这个1号商品,本来就是同一个sql,我两次都去执行。效率会特别低下。那么我们就想哈,在1号商品不变的情况下,能不能做一份缓存,用户去调用的话,我们直接从缓存中取出来。
所以说我们希望减轻数据的压力,可以通过使用缓存来保证效率!图中的cache缓存我们用什么技术都无所谓,我们重点是要知道在这里加一层缓存来解决这个问题。
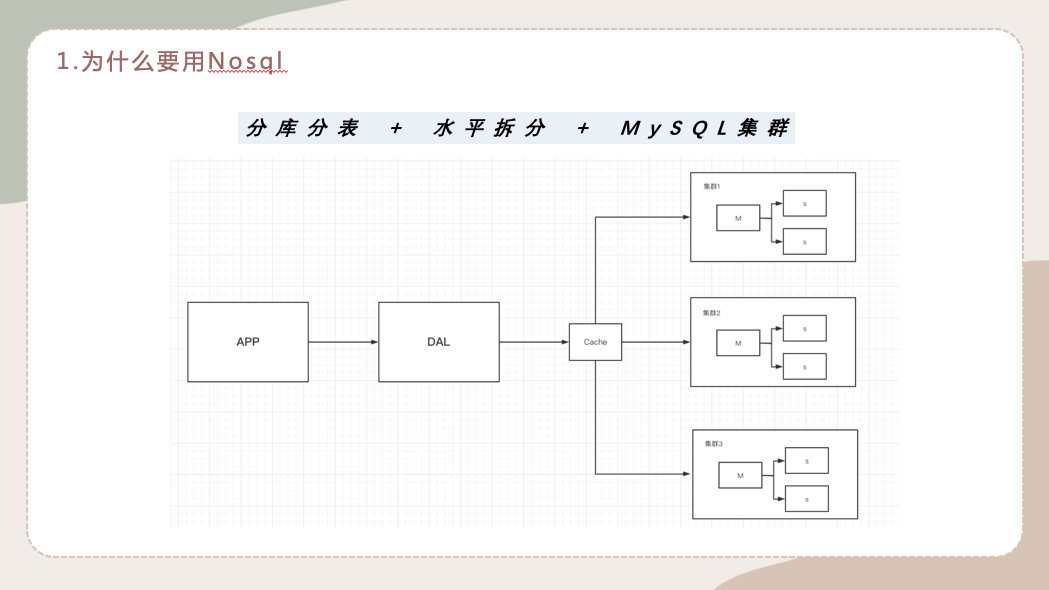
1.3 分库分表 + 水平拆分 + Mysql集群
之后又演变成了分库分表,因为库装不下了,一个表数据太多了,所以要分库分表。然后水平拆分,说白了就是mysql集群。
那么集群是怎么实现的呢,举个例子说哈,我要查一个用户信息,用户进来先从缓存中去查,缓存没有的话,就从集群里去查。图中一共有三个集群,每个集群放用户的三分之一的数据,加起来就是一个完整的用户数据。通过集群的机制,我们就知道数据存在哪个地方,从而提高效率。
1.4 如今的年代
在如今的年代,从2010-2020十年之间,世界已经发生了翻天覆地的变化。就比如说定位,它其实是一种数据,再比如说音乐,抖音热榜,微博热榜,也是一种动态实时的刷新非常快速的数据。
那么再来想一下这些还能在这些最基础的mysql集群中来做么,是不是就很费劲了呀。这里我再举个例子,有的文章浏览量直接爆款10万+,他们是如何做到这一点的呢,你会认为用户每一次浏览完都会写进mysql关系型数据库里么,或者持久化到本地么,这肯定是不可能的。他们做的第一件事情,就肯定是把它放到缓存里面,过一段固定的时间,比如说1个小时,两个小时再把它持久化一下,这样可以保证更安全滴。否则刷个文章都能把人家服务器给刷崩了。
所以说Mysql等关系型数据库就不够用了,因为现在数据量很大,且变化很快。但如果能有一类数据库专门能处理这些数据的话,是不是就会分担Mysql的压力了呢?那么下面就到了Nosql闪亮登场了~

2.什么是Nosql
Nosql不仅仅是sql,泛指非关系型数据库。
关系型数据库,大家知道比如说表格,有行和列。但是有很多的数据类型,例如上面提到的用户的个人信息,社交网络,地理位置等。这些数据类型的存储不需要一个固定的格式!也就是说不需要多余的操作就可以横向扩展的。
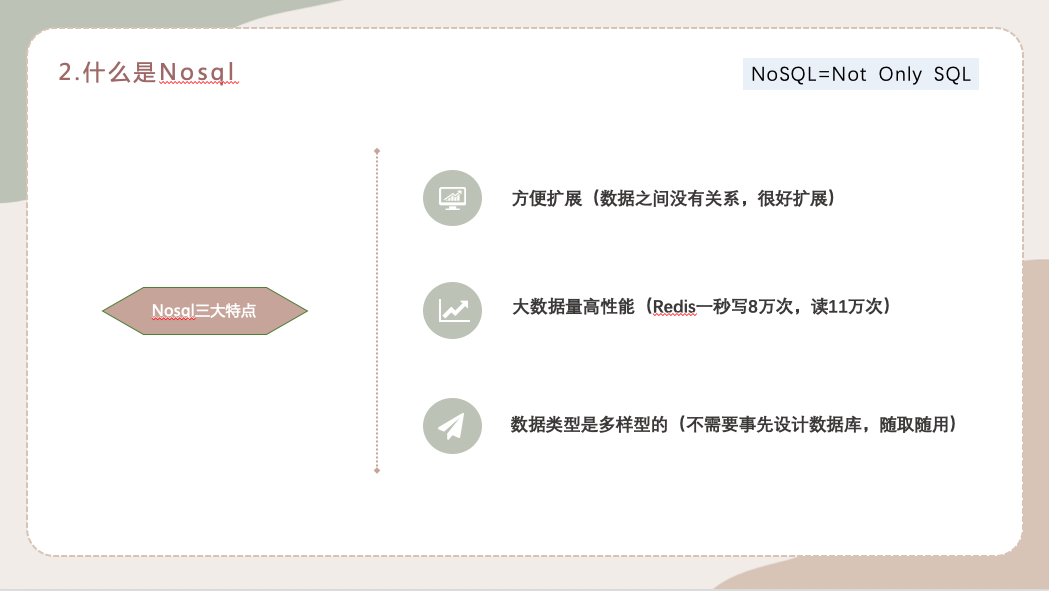
这也就接下来我这边提到的Nosql的三大特点,
第一个就是方便扩展,数据之间没有关系,很好扩展。
第二个特点,大数据量高性能,后面要讲解的Redis一秒写8万次,读11万次。
第三个特点,数据类型是多样性的,后面也会介绍到,比如说redis有五大基础数据类型,三大特殊类型。它不需要像mysql那样事先设计数据库,可以随取随用
Redis概述?-- 特性、安装和数据类型

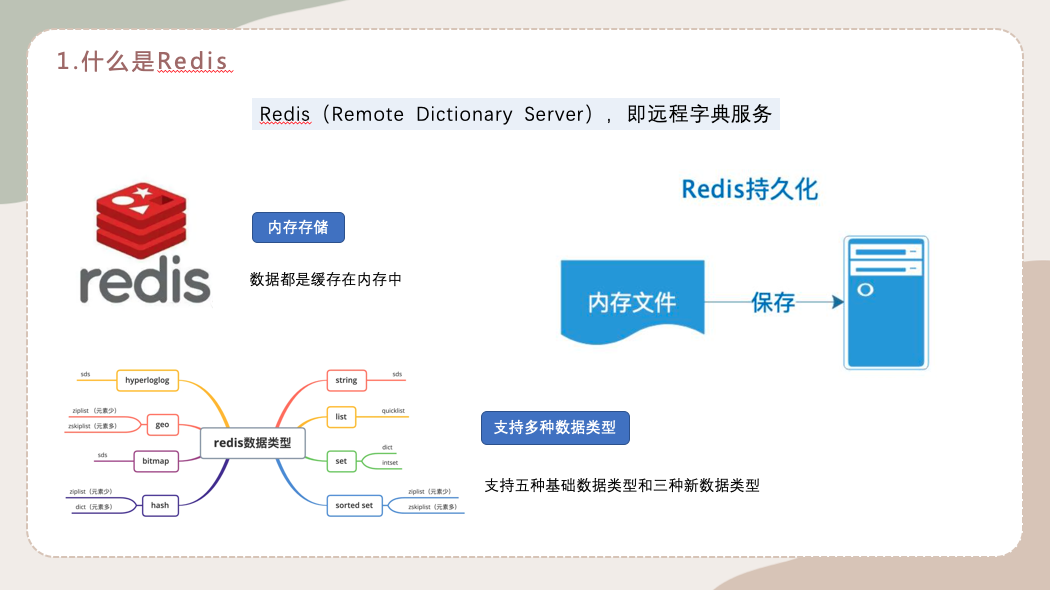
1.什么是Redis
Redis也叫Remote Dictionary Server,即远程字典服务,那么redis都有哪些特性呢?
第一个是内存存储,与 memcached一样,为了保证效率,数据都是缓存在内存中。区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
第二个是持久化的能力,因为Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器的进程退出,服务器中的数据库状态也会消失。所以便提供了持久化的功能,在指定的时间间隔内将内存中的数据集快照写入磁盘。
第三个就是支持多种数据类型,五种常用的数据类型,字符串,列表,Set集合,Hash哈希和Zset有序集合。三种新数据类型,Bitmaps,HyperLogLog去重的数据类型,Geographic关于地理位置的数据类型。
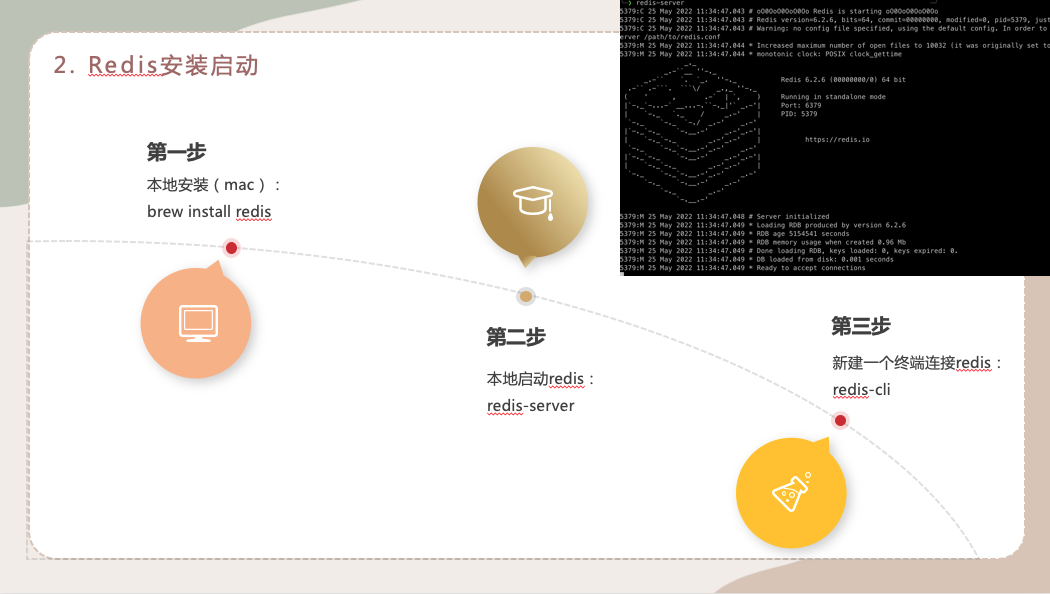
2.Redis的安装启动
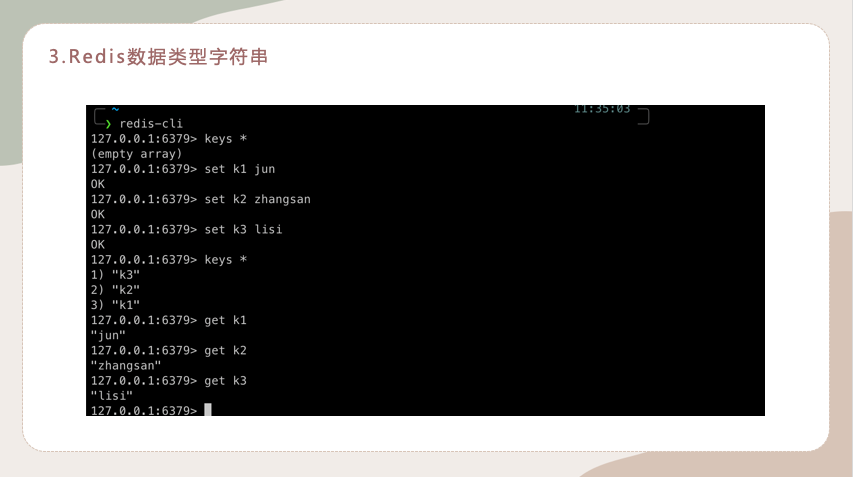
3.Redis数据类型字符串
因为后面会讲到通过分布式锁来解决高并发的问题,这里最底层也就是用到了Redis数据类型字符串,这个其实非常简单,大家先自行看一下~
先通过redis-cli连接上:
用到的指令如下:
set <key><value>:添加键值对**.
keys *:查看当前库所有 key
get <key>:查询对应键值
Redis应用场景?-- 分布式锁
1.分布式锁是什么?
首先给大家解释一下分布式锁是什么?它能解决什么问题,我给大家说明一下。
锁是什么?其实非常好理解,就好比代码中的lock,代码中加了一层lock判断,运行的时候自然就不会运行被lock包裹的代码。只有达到某种条件,把lock锁释放掉了,被lock包裹的代码才可以重新运行。

大家接下来来看我图中的这段描述,原本我们都用单体单机进行部署,比如我们之前操作中加入一个锁,里面其他操作会进行等待,等我这个锁释放之后,其他操作就可以进行了。但是随着我们业务的发展,咱们的单机应用往往变成了分布式或者集群的系统。
那在分布式或者集群系统中就有问题了,比如说我们现在有三个集群,现在我们给第一个机器加了一把锁。那么这个锁只针对当前机器,其他这两把机器并不能得到这把锁。所以说这把锁对于其他机器并不是都有效。这也是里面我描述到的,单体应用中我们设置锁可以生效,当你是分布式集群之后,这个锁不能生效,这里边我们的JVM不能跨系统进行锁的控制。现在就需要一把锁让所有系统机器都认识,也就是我们通俗说的共享锁。
不知道大家理解没有,说白了,就是一把共享锁所有机器都生效。当我上锁之后,无论你下一个操作,是在当前机器,还是其他那两个机器,识别出来都只能等待。只有把锁释放之后,其他操作才能进行。这就是分布式锁!!
2.基于Redis实现分布式锁
接下来我们聊一下分布式锁在redis中最简单的使用
这里我们可以通过一个不是很恰当的例子来说明一下,比如说你去上厕所,你打开门进入是不是得上把锁啊,外面再有人来看见上锁是不是得等待啊,你解决完之后开锁出去其他人进来也得再上锁,就这样以此类推的这个过程。也就是我们这实现的原理。
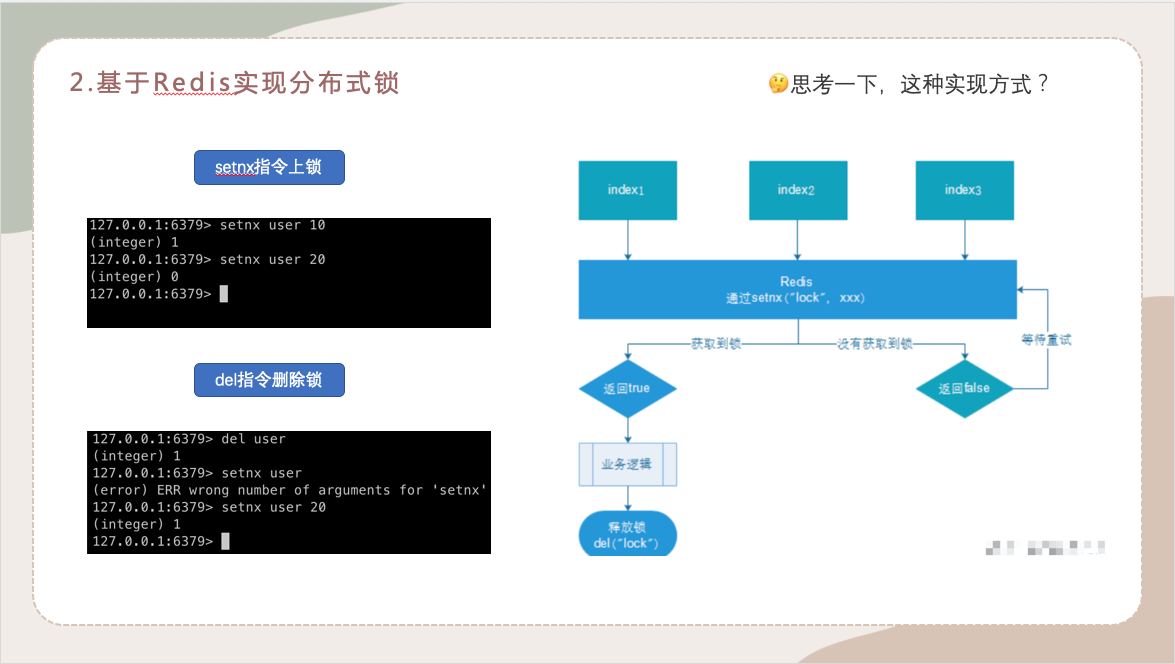
这个时候思考一下,这种实现方式有什么问题么?
就比如说,这个人去上厕所,他把锁锁上了,但是不小心他在里面睡着了,睡了得有1 - 2天,这个锁是不是一直锁着啊,别人就一直进入不了。那么这就是一个不正确的场景。
那么我们怎么解决呢?大家可以想一下!!
3.优化分布式锁
其实很简单,我们在给锁上锁之后,给锁设置一个过期时间,在这个人去厕所的期间,如果5分钟以内没有反应,可以做一些特殊操作,比如自动释放锁等,把人弹出来这种。
然后我通过指令的方式给大家演示一下:
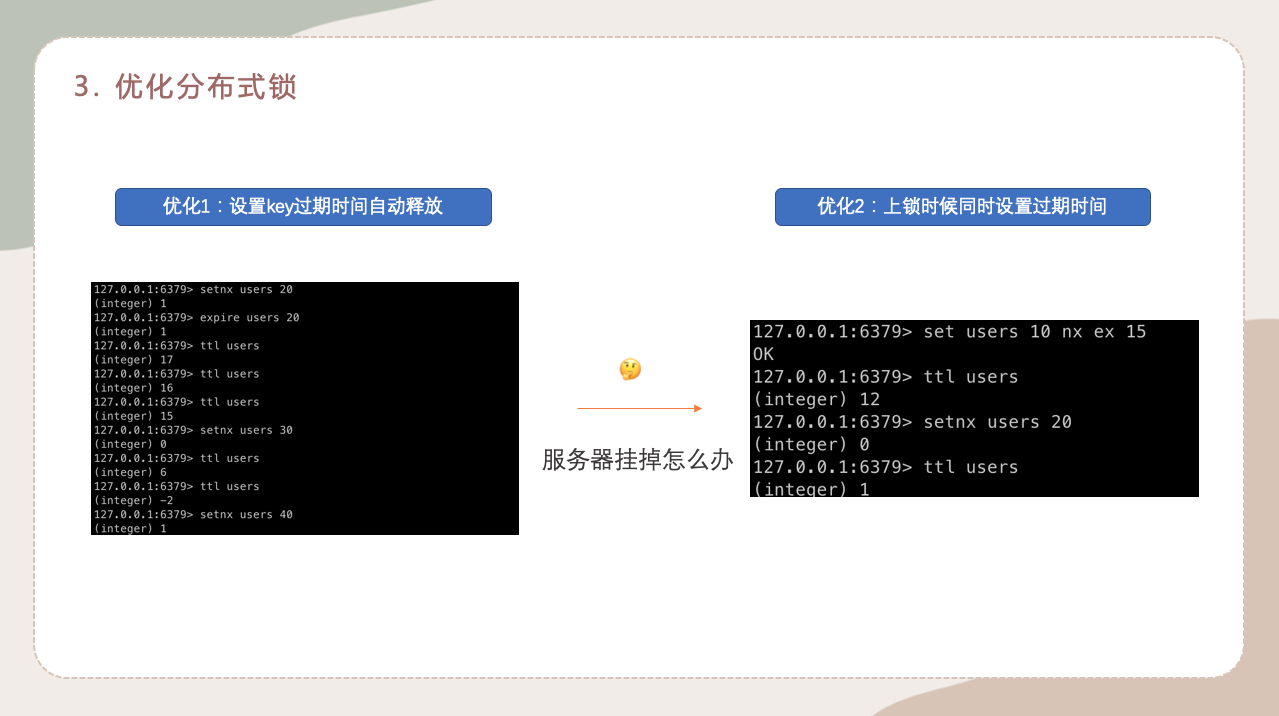
这个过程中里面其实还有一个问题,给大家提一个新概念叫原子操作,什么是原子操作,就是两个指令一起进行。大家想一下,如果我在设置expire过期时间之前,服务器突然挂掉了,那咱的过期时间是不是就不能设置了呀。这样是不是就会出现问题了呢。
解决办法其实也很简单,就是上锁的时候同时设置过期时间,让他们同步进行就可以解决了。
这就是我们对分布式进行了一系列优化的操作,这么听下来这个底层原理是不是还蛮简单的,接下来就是在实战项目前端监控平台watchtower中,我们通过这个redis的分布式锁原理来解决高并发请求的问题。
Redis在前端监控平台的应用?-- 分布式锁解决高并发请求

1.Watchtower -- PV统计页面需求
这个页面是一个关于具体指定的项目在一段时间内的pv统计折现图,当前指定的项目在具体某一天用户进来访问一次,当天的pv统计数量就会加一。
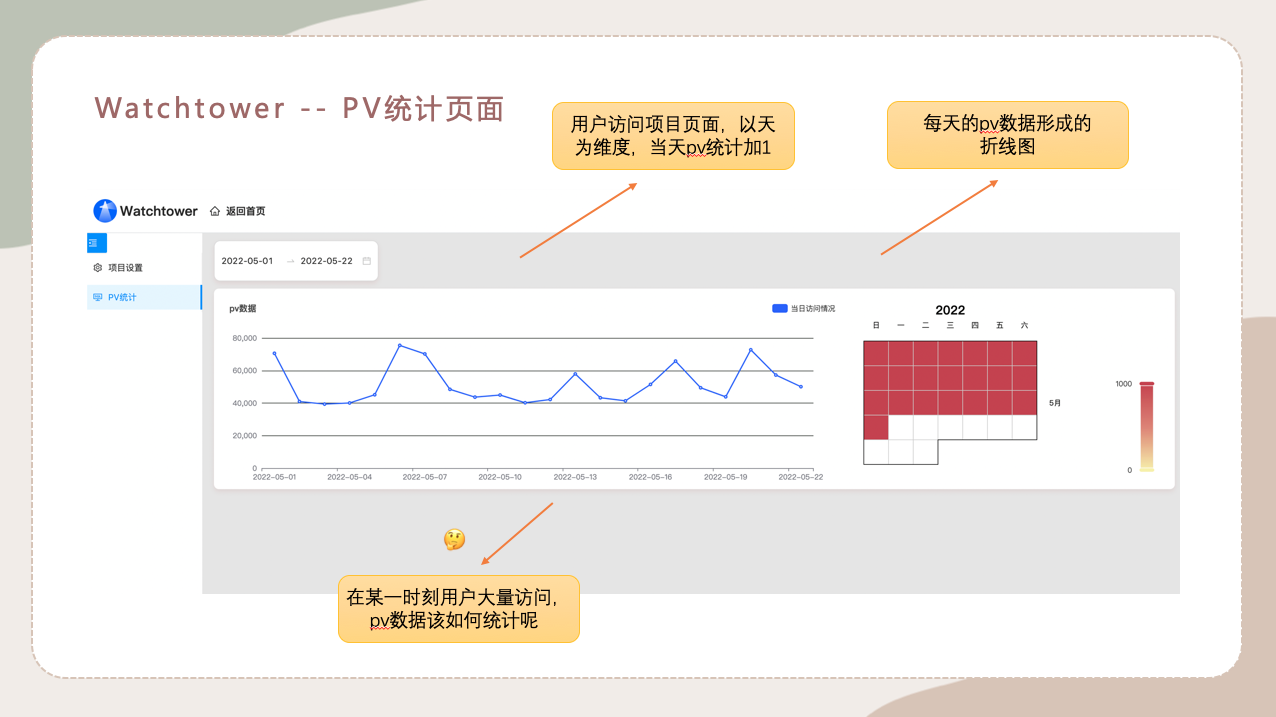
整体实现还是很清晰的,用户每访问一次,会调用一次接口,后台会根据接口取出对应数据库里的值并加一。但是这时会有一个问题,倘若在某一时刻用户大量并发访问,当前取数据加数据的操作一定会出现问题,那么我们又是如何去解决的呢?
2.流程图和代码演示
这个时候我们就采用上面介绍的Redis的分布式锁来处理这种高并发的问题,保证数据的正常统计。
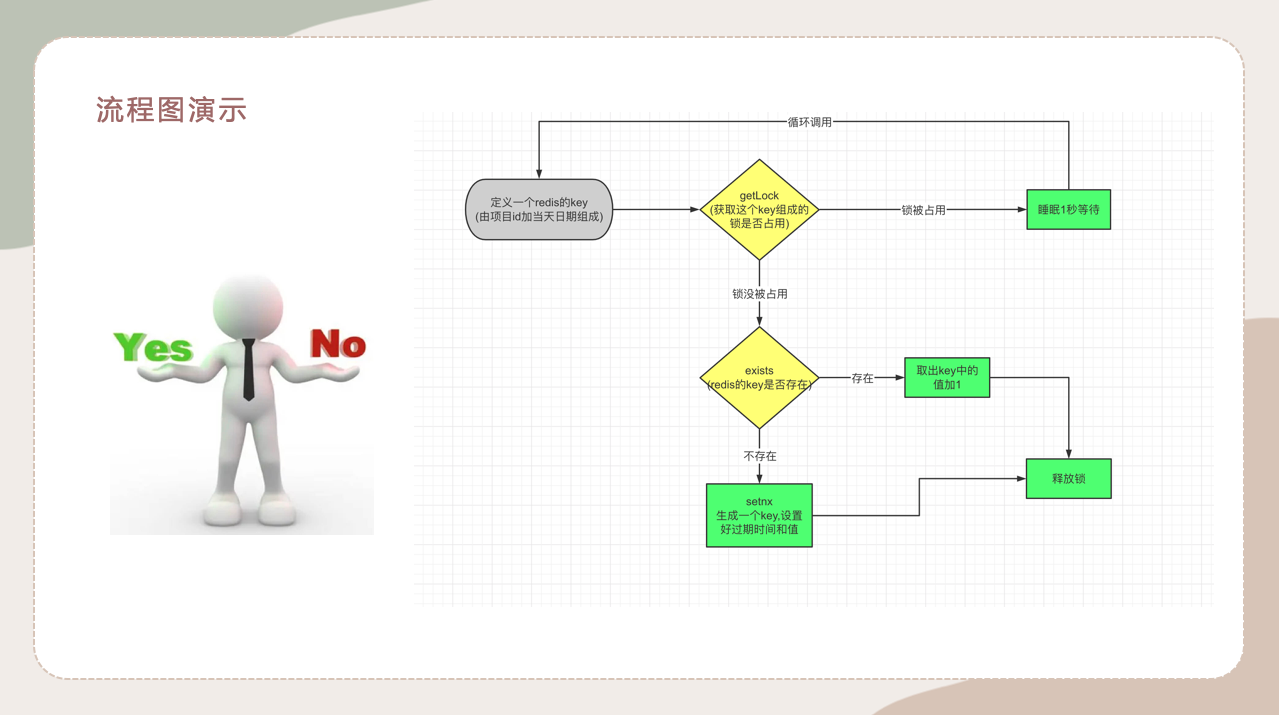
首先定义一个redis的key,由项目id和日期组成,确保key的唯一性。之后通过getLock来确认key是否被占用,如果锁被占用,则等待一秒循环调用。如果锁没被占用,再来判断定义的key是否还存在,即有没有过期。如果key存在,则取出数据库的数据加1,倘若不存在,则通过key初始化值为1,且设置好过期时间。最后再统一释放锁。
注意:这里用的jimbClient是我们京东内部的一个redis的包,大家使用的话可以使用redis的npm包,详细地址参考: https://github.com/redis/node-redis

本文通过nosql到redis,再到具体的项目应用,带大家认识到了redis最常用的分布式锁的方法。其实对于redis还有其他很多好玩以及好用的功能,得靠大家自己先一点点去摸索前进,后续我也会给大家持续分享的。这里还是得提一下之前分享给大家的一句话:学习技术的过程,是从接纳和记忆知识开始的,但绝不仅仅是接纳和记忆知识,而是需要深入思考,并自己总结和沉淀的。最后希望大家的技术都可以突飞猛进!
https://redis.io/docs/getting-started/
https://www.kuangstudy.com/bbs?searchKey=redis&cid=&pageNo=1&pageSize=15
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK