

强化学习-学习笔记2 | 价值学习 - climerecho
source link: https://www.cnblogs.com/Roboduster/p/16444062.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Value-Based Reinforcement Learning : 价值学习
2. 价值学习
2.1 Deep Q-Network DQN
其实就是用一个神经网络来近似 Q∗Q∗ 函数。
agent 的目标是打赢游戏,如果用强化学习的语言来讲,就是在游戏结束的时候拿到的奖励总和 Rewards 越大越好。
a. Q-star Function
问题:假设知道了 Q∗(s,a)Q∗(s,a) 函数,哪个是最好的动作?
显然,最好的动作是a∗=argmaxaQ∗(s,a)a∗=argmaxaQ∗(s,a) ,
Q∗(s,a)Q∗(s,a)可以给每个动作打分,就像一个先知,能告诉你每个动作带来的平均回报,选平均回报最高的那个动作。
但事实是,每个人都无法预测未来,我们并不知道Q∗(s,a)Q∗(s,a)。而价值学习就在于学习出一个函数来近似Q∗(s,a)Q∗(s,a) 作决策。
- 解决:Deep Q-network(DQN),即用一个神经网络 Q(s,a;w)Q(s,a;w)来近似 Q∗(s,a)Q∗(s,a) 函数。
- 神经网络参数是 w ,输入是状态 s,输出是对所有可能动作的打分,每一个动作对应一个分数。
- 通过奖励来学习这个神经网络,这个网络给动作的打分就会逐渐改进,越来越精准
- 玩上几百万次超级玛丽,就能训练出一个先知。
b. Example
对于不同的案例,DQN 的结构会不一样。
如果是玩超级玛丽
- 屏幕画面作为输入
- 用一个卷积层把图片变成特征向量
- 最后用几个全连接层把特征映射到一个输出的向量
- 输出的向量就是对动作的打分,向量每一个元素对应一个动作的分值,agent 会选择分值最大的方向进行动作。
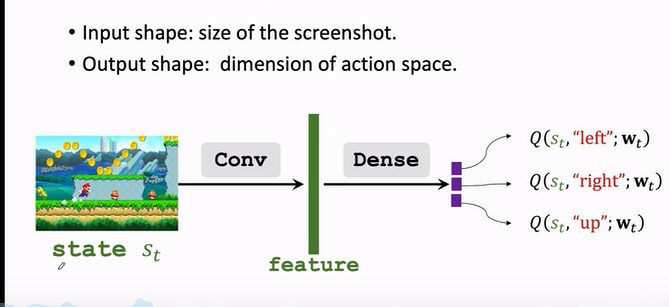
c. 用 DQN 打游戏
DQN 的具体执行过程如下:

分步解释:
- st→atst→at:当前观测到状态 stst,用公式 at=argmaxaQ∗(s,a)at=argmaxaQ∗(s,a) 把 stst 作为输入,给所有动作打分,选出分数最高的动作 atat 。
- agent 执行 atat 这个动作后,环境会改变状态,用状态转移函数 p(⋅|st,at)p(⋅|st,at) 随机抽样得出一个新状态 st+1st+1。
- 环境还会告诉这一步的奖励 rtrt ,奖励就是强化学习中的监督信号,DQN靠这些奖励来训练。
- 有了新的状态 st+1st+1,DQN 继续对所有动作打分,agent 选择分数最高动作 at+1at+1。
- 执行 at+1at+1 后,环境会再更新一个状态 st+2st+2,给出一个奖励 rt+1rt+1。
- 然后不断循环往复,直到游戏结束
2.2 TD 学习
如何训练 DQN ?最常使用的是 Temporal Difference Learning。TD学习的原理可以用下面这个例子来展示:
a. 案例分析
要开车从纽约到亚特兰大,有一个模型Q(w)Q(w)预测出开车出行的开销是1000分钟。这个预测可能不准,需要更多的人提供数据来训练模型使得预测更准。
- 问题:需要怎样的数据?如何更新模型。
-
出发之前让模型做一个预测,记作qq,q=Q(w)q=Q(w),比如q=1000q=1000。到了目的地,发现其实只用了860分钟,获取真实值 y=860y=860。
-
实际值yy与预测值qq有偏差,这就造成了 loss 损失
-
loss 定义为实际值与预测值的平方差:L=12(q−y)2L=12(q−y)2
-
对损失 LL关于参数ww求导并用链式法则展开:
∂L∂w=∂q∂w⋅∂L∂q=(q−y)⋅∂Q(w)∂w∂L∂w=∂q∂w⋅∂L∂q=(q−y)⋅∂Q(w)∂w
-
梯度求出来了,可以用梯度下降来更新模型参数 w :wt+1=wt−α⋅∂L∂w|w=wtwt+1=wt−α⋅∂L∂w|w=wt
缺点:这种算法比较 naive,因为要完成整个旅程才能完成对模型做一次更新。
那么问题来了:假如不完成整个旅行,能否完成对模型的更新?
可以用 TD 的思想来考虑这件事情。比如我们中途路过 DC 不走了,没去亚特兰大,可以用 TD 算法完成对模型的更新,即
-
出发前预测:NYC -> Atlanta 要花1000分钟,这是预测值。
到了 DC 时,发现用了 300 分钟,这是真实观测值,尽管它是针对于部分的。
-
模型这时候又告知,DC -> Atlanta 要花 600 分钟。
-
模型原本预测:Q(w)=1000Q(w)=1000,而到 DC 的新预测:300 + 600 = 900,这个新的 900 估值就叫 TD target 。
这些名词要记住,后面会反复使用,TD target 是使用了 TD算法的道德整体预测值。
-
TD target y=900y=900虽然也是个估计预测值,但是比最初的 1000 分钟更可靠,因为有事实成分。
-
把 TD target yy 就当作真实值:L=12(Q(w)−y)2L=12(Q(w)−y)2, 其中Q(w)−yQ(w)−y称为TD error。
-
求导:∂L∂w=(1000−900)⋅∂Q(w)∂w∂L∂w=(1000−900)⋅∂Q(w)∂w
-
梯度下降更新模型参数 w :wt+1=wt−α⋅∂L∂w|w=wtwt+1=wt−α⋅∂L∂w|w=wt
b. 算法原理
换个角度来想,TD 的过程就是这样子的:
模型预测 NYC -> Atlanta = 1000, DC -> Atlanta = 600,两者差为400,也就是NYC -> DC = 400,但实际只花了300分钟预计时间与真实时间之间的差就是TD error:δ=400−300=100δ=400−300=100。
TD 算法目标在于让 TD error 尽量接近 0 。
即我们用部分的真实 修改 部分的预测,而使得整体的预测更加接近真实。我们可以通过反复校准 可知的这部分真实 来接近我们的理想情况。
c. 用于 DQN
(1) 公式引入
上述例子中有这样一个公式:TNYC→ATL≈TNYC→DC+TDC→ATLTNYC→ATL≈TNYC→DC+TDC→ATL
想要用 TD 算法,就必须要用类似这样的公式,等式左边有一项,右边有两项,其中有一项是真实观测到的。
而在此之前,在深度强化学习中也有一个这样的公式:Q(st,at;w)=rt+γ⋅Q(st+1,at+1;w)Q(st,at;w)=rt+γ⋅Q(st+1,at+1;w)。
公式解释:
- 左边是 DQN 在 t 时刻做的估计,这是未来奖励总和的期望,相当于 NYC 到 ATL 的预估总时间。
- 右边 rtrt是真实观测到的奖励,相当于 NYC 到 DC 。
- Q(st+1,at+1;w)Q(st+1,at+1;w) 是 DQN 在 t+1 时刻做的估计,相当于 DC 到 ATL 的预估时间。
(2) 公式推导
为什么会有一个这样的公式?
回顾 Discounted return: Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+⋯
提出 γγ 就得到 =Rt+γ(Rt+1+γRt+2+γ2Rt+3+⋯)=Rt+γ(Rt+1+γRt+2+γ2Rt+3+⋯)
后面这些项就可以写成Ut+1Ut+1,即 =Rt+γUt+1=Rt+γUt+1
这样就得到:Ut=Rt+γ⋅Ut+1Ut=Rt+γ⋅Ut+1
直观上讲,这就是相邻两个折扣算法的数学关系。
(3) 应用过程
现在要把 TD 算法用到 DQN 上
- t 时刻 DQN 输出的值 Q(st,at;w)Q(st,at;w) 是对 UtUt 作出的估计 E[Ut]E[Ut],类似于 NYC 到 ATL 的预估总时间。
- 下一时刻 DQN 输出的值 Q(st+1,at+1;w)Q(st+1,at+1;w) 是对 Ut+1Ut+1 作出的估计 E[Ut+1]E[Ut+1],类似于 DC 到 ATL 的第二段预估时间。
- 由于 Ut=Rt+γ⋅Ut+1Ut=Rt+γ⋅Ut+1
- 所以 Q(st,at;w)≈E[Ut]≈E[Rt+γ⋅Q(st+1,at+1;w)≈E[Ut+1]]Q(st,at;w)⏟≈E[Ut]≈E[Rt+γ⋅Q(st+1,at+1;w)⏟≈E[Ut+1]]
- Q(st,at;w)prediction=rt+γ⋅Q(st+1,at+1;w)TD targetQ(st,at;w)⏟prediction=rt+γ⋅Q(st+1,at+1;w)⏟TDtarget
有了 prediction 和 TD target ,就可以更新 DQN 的模型参数了。
-
t 时刻模型做出预测 Q(st,at;wt)Q(st,at;wt);
-
到了 t+1时刻,观测到了真实奖励 rtrt 以及新的状态 st+1st+1,然后算出新的动作 at+1at+1。
-
这时候可以计算 TD target 记作 ytyt,其中yt=rt+γ⋅Q(st+1,at+1;w)yt=rt+γ⋅Q(st+1,at+1;w)
-
t+1 时刻的动作 at+1at+1怎么算的?DQN 要对每个动作打分,取分最高的,所以等于Q 函数关于a求最大化:yt=rt+γ⋅maxaQ(st+1,a;wt)yt=rt+γ⋅maxaQ(st+1,a;wt)
-
我们希望预测Q(st,at;w)Q(st,at;w)尽可能接近 TD target ytyt ,所以我们把两者之差作为 Loss :
Lt=12[Q(st,at;w)−yt]2Lt=12[Q(st,at;w)−yt]2
-
做梯度下降:wt+1=wt−α⋅∂L∂w|w=wtwt+1=wt−α⋅∂L∂w|w=wt更新模型参数 w,来让 Loss 更小
2.3 总结
-
价值学习(本讲是DQN)基于最优动作价值函数 Q-star :
Q∗(st,at)=E[Ut|St=st,At=at]Q∗(st,at)=E[Ut|St=st,At=at]
对 UtUt 求期望,能对每个动作打分,反映每个动作好坏程度,用这个函数来控制agent。
-
DQN 就是用一个神经网络Q(s,a;w)Q(s,a;w)来近似Q∗(s,a)Q∗(s,a)
- 神经网络参数是 w ,输入是 agent 的状态 s
- 输出是对所有可能动作 a∈Aa∈A 的打分
-
TD 算法过程
-
观测当前状态 St=stSt=st 和已经执行的动作 At=atAt=at
-
用 DQN 做一次计算,输入是状态 stst,输出是对动作 atat 的打分
记作qtqt,qt=Q(st,at;w)qt=Q(st,at;w)
-
反向传播对 DQN 求导:dt=∂Q(st,at;w)∂w|w=wtdt=∂Q(st,at;w)∂w|w=wt
-
由于执行了动作 atat,环境会更新状态为 st+1st+1,并给出奖励rtrt。
-
求出TD target:yt=rt+γ⋅maxaQ(st+1,at;w)yt=rt+γ⋅maxaQ(st+1,at;w)
-
做一次梯度下降更新参数 w , wt+1=wt−α⋅(qt−yt)⋅dtwt+1=wt−α⋅(qt−yt)⋅dt
-
更新迭代...
-
x. 参考教程
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK