

全链路压测:影子库与影子表之争
source link: https://developer.51cto.com/article/712451.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者 | 葛天萌(智云)
一、业界盛传的全链路压测是什么
全链路压测诞生于阿里巴巴双 11 备战过程,如果说双 11 大促是阿里业务的“期末考试”,全链路压测就是大考前的“模拟考试”,诞生后被誉为双 11 稳定性保障的“核武器”。全链路压测通过在生产环境对业务大流量场景进行高仿真模拟,获取最真实的线上实际承载能力、执行精准的容量规划,确保系统可用性。分布式架构和业务快速发展给业务系统带来了不确定性。分布式环境的任意节点都可能成为瓶颈/短板/问题,同时系统可用性随着业务的快速增长,面临更严峻的挑战和不确定性。比如:
- 单链路压测缺少外部干扰和各种资源竞争,单链路压测的结果普遍比较乐观,不能反映真实的系统承载能力。
- 某些问题只有在真正的大流量下才会暴露,比如网络带宽、系统间影响、基础依赖等等。
- 全链路压测不仅仅是做压测,更多的是进行一次真实的大促预演,预案演练、限流验证、破坏性演练等高可用方案的统一验收。
其中全链路压测的常见问题就是如何做到生产环境的数据隔离:在生产环境进行写压测时,需要保证在压测进行的同时不影响线上业务的正常运行,那么就需要考虑将压测产生的数据与生产的真实数据隔离存储,避免脏数据对线上业务产生影响。阿里云的全链路压测平台除了提供了影子表方案之外,还提供了影子库的数据隔离方案。在生产环境实施全链路压测的过程中,针对上文谈到的两种方案,又面临着数据隔离方案的选择问题,本文首先针对影子库、影子表两种方案进行介绍和对比,然后针对常见的场景,给出方案的选择建议。
二、全链路压测数据隔离方案的选择
目前全链路压测平台提供了影子库、影子表等解决方案。应该如何选择适合自己的方案呢?本文首先针对两种方案的原理进行阐述,然后从性能、稳定性、成本三个考量指标进行对比。
1.方案一:影子库
如图 1 所示,针对影子库方案,是在同一个实例上建立对应的影子库。用户服务挂载的全链路压测探针获取到流量标之后进行相应的旁路处理,如果是影子流量,那么会从影子连接池中获取影子连接供业务侧使用,从而将压测流量产生的数据旁路到对应的影子库中,以此达到数据和生产库隔离的效果,从而避免了压测流量产生的数据对生产库造成污染。
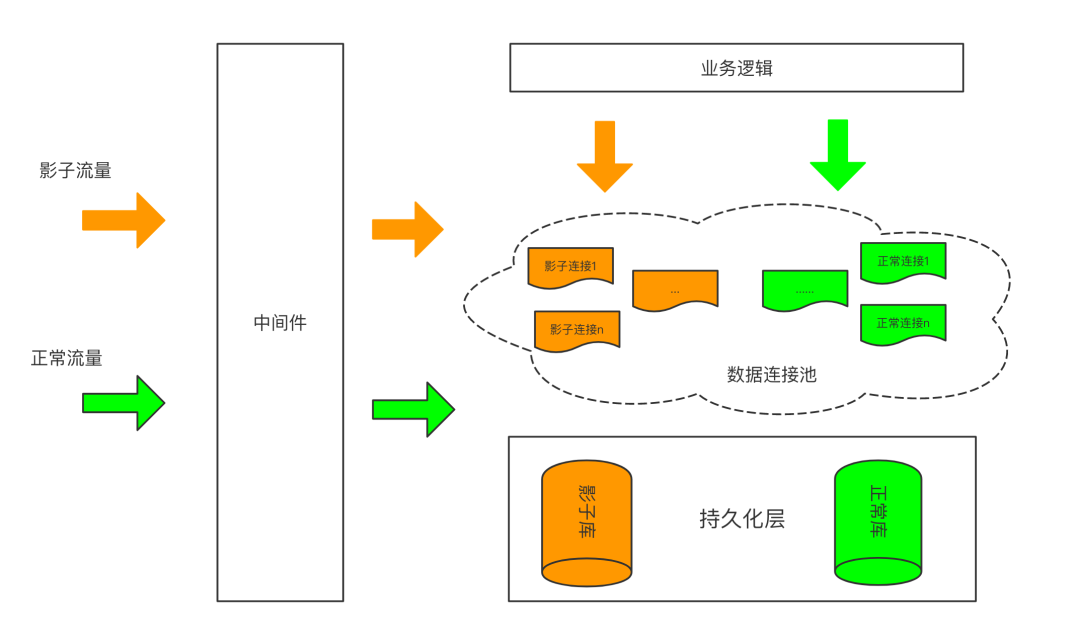
图 1:影子库方案基本原理
2.方案二:影子表
如图 2 所示,类似影子库方案,针对影子表方案,是在同一个实例上的同一个数据库上建立对应的影子表。用户服务挂载的全链路压测探针获取到流量标之后进行相应的旁路处理,如果是影子流量,那么,探针会针对本次的 DB 调用进行 SQL 解析和替换,从而将压测流量产生的数据旁路到对应的影子表中。
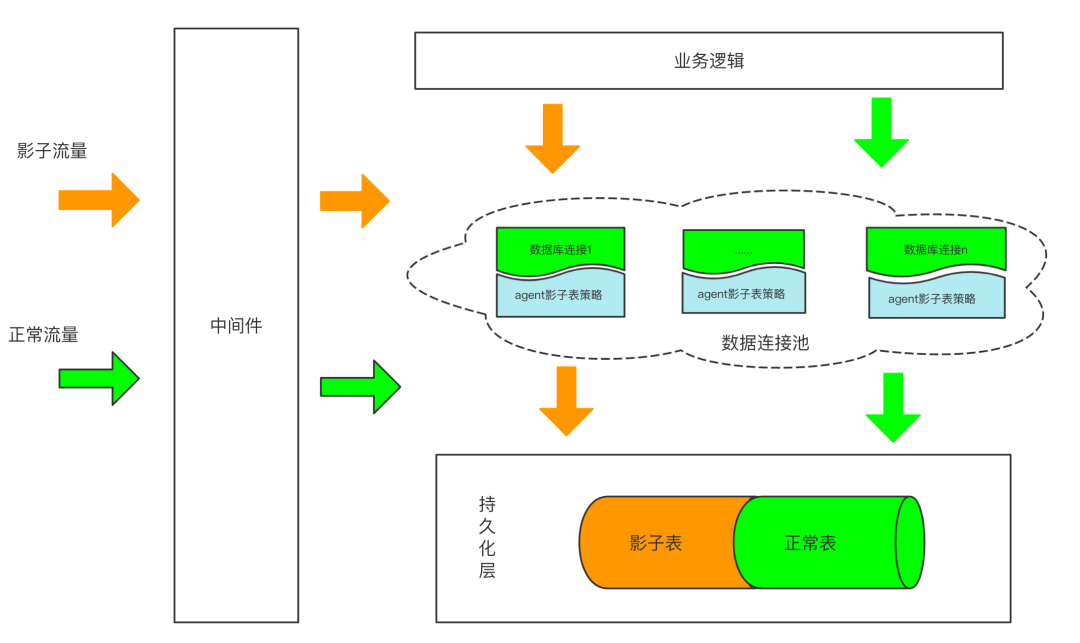
图 2:影子表方案基本原理
三、方案对比
本文主要从性能、稳定性、成本三个方面来阐述两种方案的优缺点。
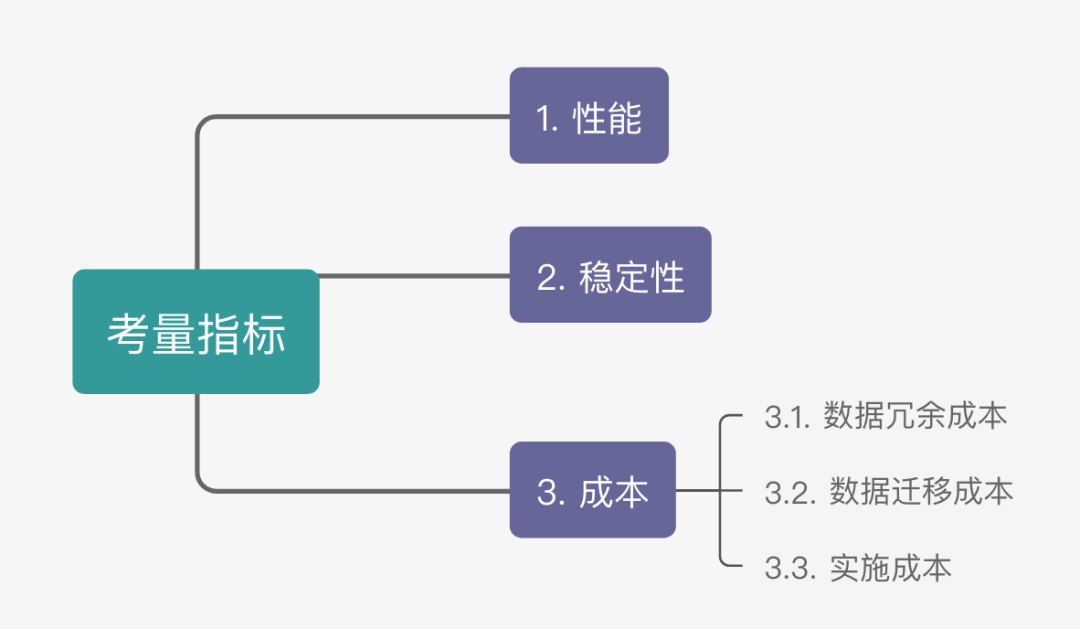
图 3:方案对比
机器规格:4c8g并发规格:需同时模拟正常和压测流量两种类型的流量,这里以 2:8 的比例进行划分,以便于模拟业务流量低峰期进行生产环境全链路压测。
- 正常流量:200 并发
- 压测流量:800 并发
这里主要从服务所在的主机和所用的数据库实例两方面的监控去分析。其中,应用监控主要以 CPU、内存和平均 RT 三个指标分析。数据库实例监控从连接数、QPS 两个指标的维度进行分析。

从以上两种方案不同维度的指标对比可以看出,影子表方案对 CPU 的消耗略高,这和该方案的实现方式有关。
2.稳定性
谈到稳定性,可以从数据源实例的连接数规格、容量规格、IOPS、网络流量等方面进行分析。

以上指标,这里以连接数为例进行说明,具体如下:针对影子库方案。由于是在同一个实例上建立不同的数据库,所以如果不考虑数据库实例能够达到最大连接数上限,理论上影子连接和正常连接时相互独立的,执行时互不影响。针对影子表方案,由于是在同一个实例上的同一个数据库上建立了不同的数据表,那么这里就要考虑业务侧的连接池配置了,因为影子流量涉及到的 DB 操作和正常流量涉及到的 DB 操作,所用的数据库连接,均来源于同一个连接池,所以如果压测量级较大的时候,是比较容易出现连接池连接瓶颈的。
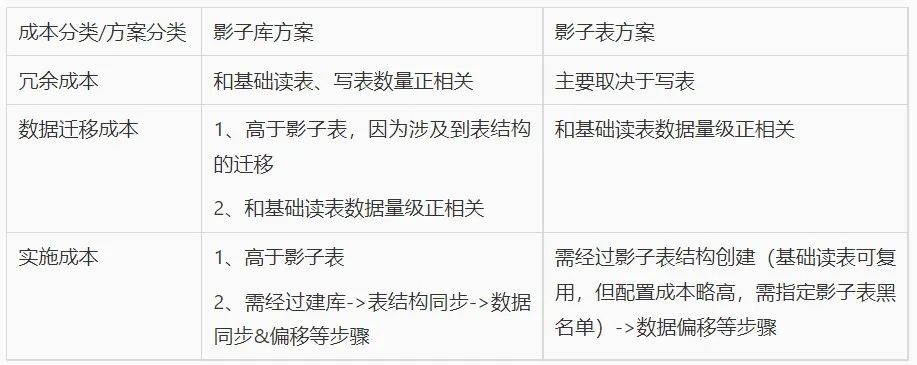
根据表格中的内容,这里主要以冗余成本和数据迁移成本进行说明,具体如下:
针对影子库方案,为了保证全链路压测评估结果的精准度,我们需要在同一个实例上做全量的库迁移操作,包括表结构和表数据,这会带来一个比较明显的问题,成本比较高,所有的基础只读表(此类型的表不会有写操作)均要冗余一份,无法达到复用的目的,所以对于中大型企业来说,是难以接受的。针对影子表方案,是在同一个实例上的同一个数据库上建立影子表。那么就可以复用生产库中的基础只读表,只需对写表进行建立影子表即可。影子表方案在一定程度上降低了数据冗余所带来的成本消耗。
- 数据迁移成本
从压测的主流程来说,分为压测前、压测中、压测后。其中,数据准备是处于压测前这一阶段的,压测成功与否,和数据准备这一环节密切相关。数据迁移的过程需要将某张数据表所关联的其他表字段同时做迁移,这一过程是比较复杂和耗费精力的。所以,具体选择哪种方案,需要结合业务数据的复杂程度来评估。04
综上,具体选择以上两种方案中的哪一种,其实仅靠一个指标判断是不够的,要结合以上多个指标以及具体的业务场景来进行综合评估的。下面针对两种典型的场景来说明应该如何选择适合自己方案,以下意见仅供参考。
场景 1:在涉及到的读表比例高于写表、并且整库迁移成本较高的情况下,推荐选择影子表方案,在一定程度上可以减少复杂的数据迁移带来的成本。场景 2:在涉及到的写表比例高于读表,同时生产库实例容量较为充足的情况下,推荐选择影子库方案,在一定程度上降低了梳理、配置的成本。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK