

高度可扩展,EMQX 5.0 达成 1 亿 MQTT 连接
source link: https://blog.51cto.com/u_15204296/5399477
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

高度可扩展,EMQX 5.0 达成 1 亿 MQTT 连接
原创物联网设备连接和部署规模的不断扩大,对物联网消息平台的可扩展性和健壮性提出了更高的要求。为了确认云原生分布式 MQTT 消息服务器 EMQX 的性能表现可以充分满足当今物联网连接规模的需求,我们在 23 个节点的 EMQX 集群上建立了 1 亿个 MQTT 连接,对 EMQX 的可扩展性进行了压力测试。
在本测试中,每个 MQTT 客户端订阅了一个唯一的通配符主题,这比直接主题需要更多的 CPU 资源。消息发布时,我们选择了一对一的发布者-订阅者拓扑模型,每秒处理消息可达 100 万条。此外,我们还比较了在使用两个不同的数据库后端——RLOG DB 和 Mnesia 时,最大订阅率如何随着集群大小的增加而变化。本文将详细介绍测试情况以及在此过程中面临的一些挑战。
EMQX 是一个高度可扩展的分布式开源 MQTT 消息服务器,基于 Erlang/OTP 平台开发,可支持数百万并发客户端。因此,EMQX 需要在集群节点之间持久化和复制各种数据,如 MQTT 主题及其订阅者、路由信息、ACL 规则、各种配置等等。为满足此类需求,从发布起,EMQX 就一直采用 Mnesia 作为数据库后端。
Mnesia 是基于 Erlang/OTP 的嵌入式 ACID 分布式数据库,使用全网状点对点 Erlang 分发来进行事务协调和复制。这一特性使其在水平扩展方面存在困难:节点越多,复制的数据就越多,写入任务协调的开销就越大,出现脑裂场景的风险也越大。
在 EMQX 5.0 中,我们尝试通过一个新的数据库后端类型——RLOG(Replication Log)来缓解此问题,其采用 Mria 实现。作为 Mnesia 数据库的扩展,Mria 定义了两种类型的节点来帮助其进行水平扩展:一种是核心节点,其行为与普通的 Mnesia 节点一样,参与写入事务;另一种是复制节点,不参与事务处理,将事务处理委托给核心节点,同时在本地保留数据的只读副本。因为参与其中的节点较少,这使得脑裂风险大大降低,并且减少了事务处理所需的协调。同时,由于所有节点都可以本地读取数据,可以实现只读数据的快速访问。
为了能够默认使用这个新的数据库后端,我们需要对其进行压力测试,验证其确实能够很好地进行水平扩展。我们建立了一个 23 节点的 EMQX 集群,保持 1 亿个并发连接,在发布者和订阅者之间平分,并以一对一的方式发布消息。此外,我们还将 RLOG DB 后端与传统的 Mnesia 后端进行了比较,并确认了 RLOG 的到达率的确比 Mnesia 更高。
我们使用了 AWS CDK 来进行集群测试的部署和运行,其可以测试不同类型和数量的实例,还可以尝试使用 EMQX 的不同开发分支。感兴趣的读者可以在这个 Github 仓库中查看我们的脚本。我们在负载生成器节点(简称“loadgens”)中使用了我们的 emqtt-bench 工具生成具有各种选项的连接/发布/订阅流量,并使用 EMQX 的 Dashboard 和 Prometheus 来监控测试的进度和实例的健康状况。
我们用不同实例类型和数量进行了逐一测试。在最后几次测试中,我们决定对 EMQX 节点和 loadgen 使用 c6g.metal 实例,对集群使用”3+20”拓扑,即 3 个参与写入事务的核心节点,以及 20 个为只读副本并将写入委托给核心节点的复制节点。至于 loadgen,我们观察到发布者客户端需要的资源要远多于订阅者。如果仅连接和订阅 1 亿个连接,只需要 13 个 loadgen 实例;如果还需要进行发布,则需要 17 个。

在这些测试中未使用任何负载均衡器,loadgen 直接连接到每个节点。为了让核心节点专门用于管理数据库事务,我们没有建立到这些核心节点的连接,每个 loadgen 客户端都以均匀分布的方式直接连接到每个节点,因此所有节点的连接数和资源使用情况大致相同。每个订阅者都订阅了 QoS 为 1 的 bench/%i/# 形式的通配符主题,其中 %i 代表每个订阅者的唯一编号。每个发布者都以 QoS 1 发布了 bench/%i/test 形式的主题,其中 %i 与订阅者的 %i 相同。这确保了每个发布者都只有一个订阅者。消息中的有效负载大小始终为 256 字节。
在测试中,我们首先连接了所有订阅者客户端,然后才开始连接发布者。只有在所有发布者都连接后,它们才开始每 90 秒进行一次消息发布。在本文报告的 1 亿连接测试中,订阅者和发布者连接到 broker 的速率为 16000 连接/秒,不过我们相信集群可以保持更高的连接速率。
测试中遇到的挑战
在对如此量级的连接和吞吐量进行试验的过程中,我们遇到了一些挑战并据此进行了相关调查,使性能瓶颈得到了改善。system_monitor 为我们跟踪 Erlang 进程中的内存和 CPU 使用情况提供了很大帮助,它可以称得上是“BEAM 进程的 htop”,让我们能够找到具有长消息队列、高内存和/或 CPU 使用率的进程。在集群测试期间观察到情况之后,我们利用它在 Mria 中进行了一些性能调优[1] [2] [3]。
在使用 Mria 进行的初始测试中,简单地说,复制机制基本上是要将所有事务记录到由复制节点订阅的一个隐藏的表中。这实际上在核心节点之间产生了一些网络开销,因为每个事务本质上都是“复制的”。在我们 fork 的 Erlang/OTP 代码中,我们添加了一个新的 Mnesia 模块,使我们能够更轻松地捕获所有提交的事务日志,不需要“复制”写入,大大减少了网络使用,让集群保持更高的连接和事务处理速率。在进行了这些优化后,我们进一步对集群进行了压力测试,并发现了新的瓶颈,需要进一步的性能调优[4] [5] [6]。
即使是我们的招牌测试工具也需要进行一些调整才能处理如此大量的连接和连接速率。为此我们进行了一些质量改进[7] [8] [9] [10]和性能优化[11] [12]。在我们的发布-订阅测试中,甚至专门建立了一个分支(不在当前的主干分支中),以便进一步降低内存的使用。
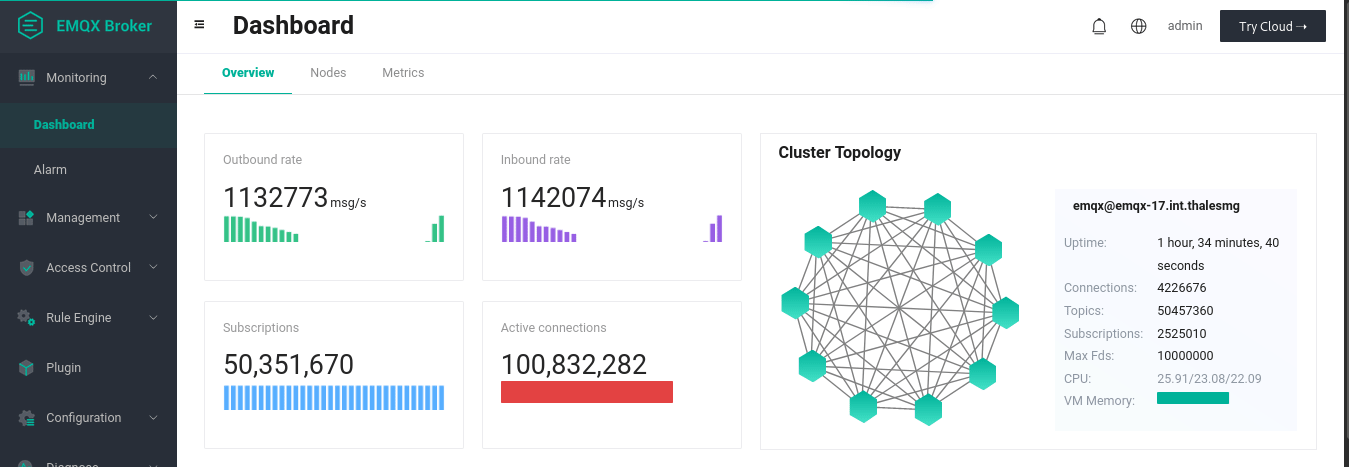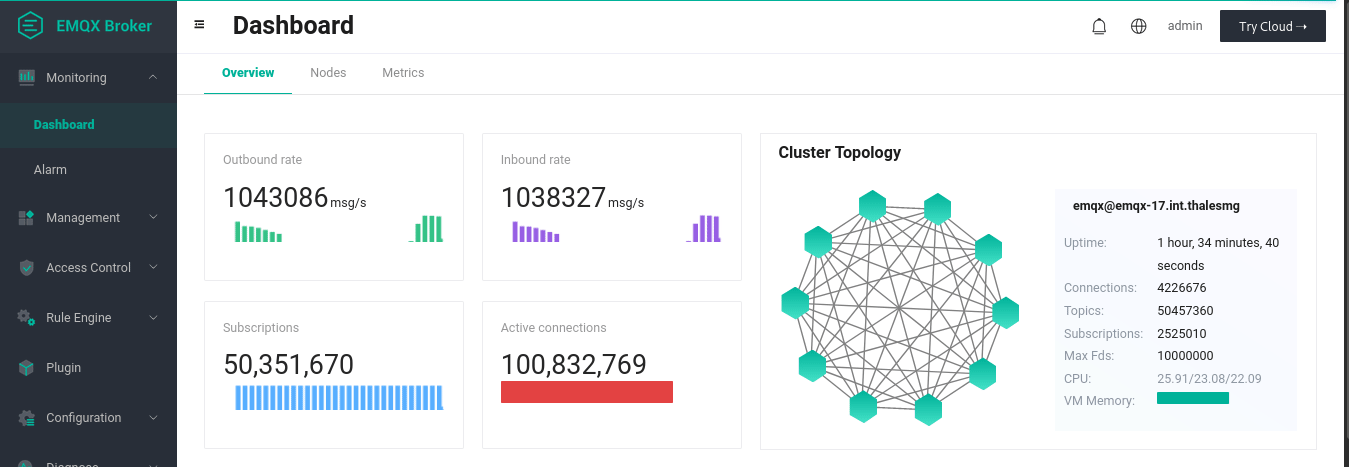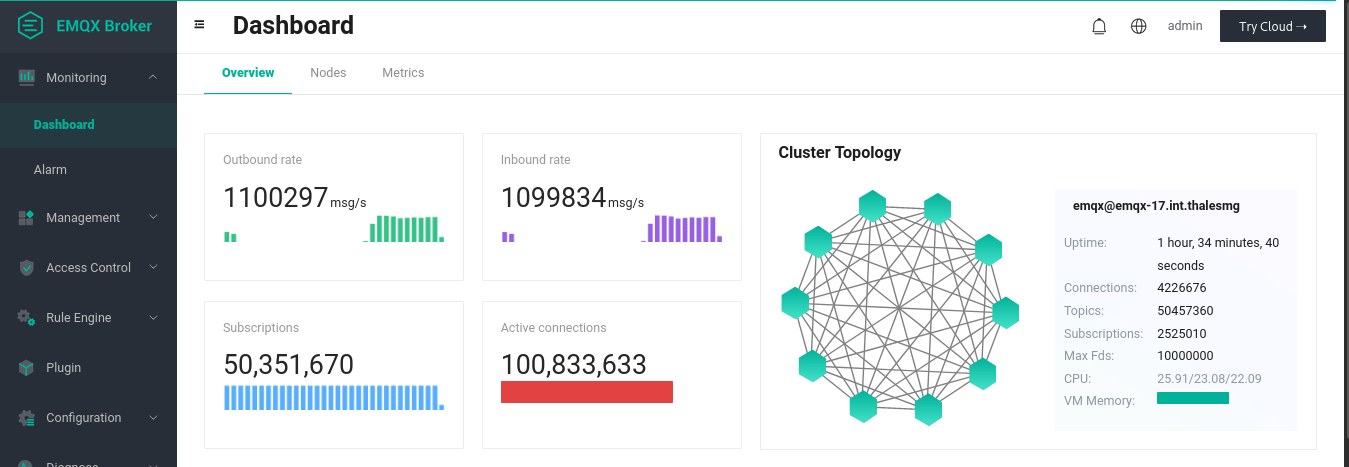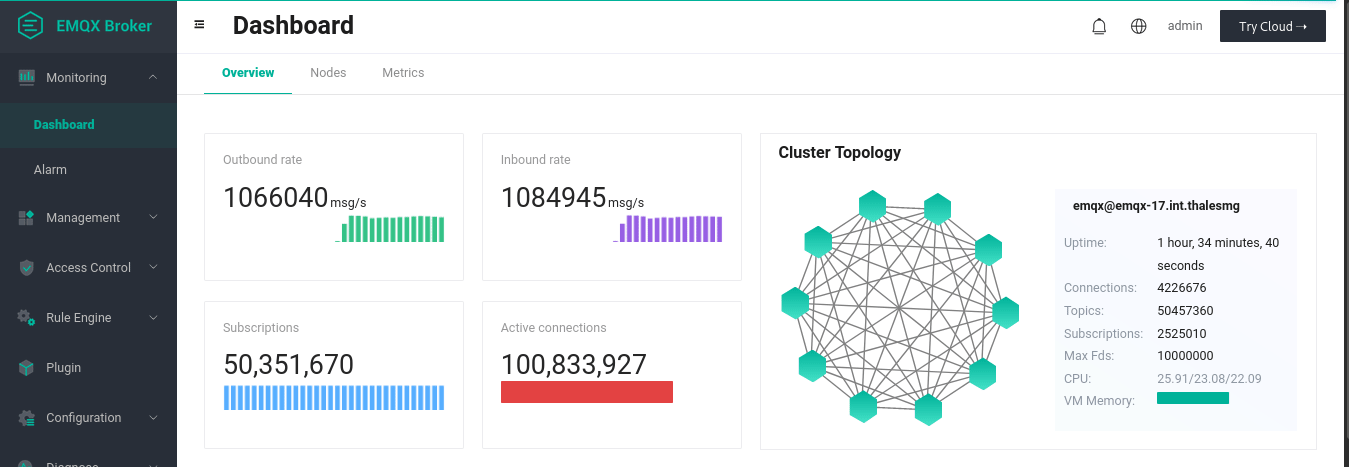
上面的动画展示了一对一发布-订阅测试的最终结果。我们建立了 1 亿个连接,其中 5000 万是订阅者,另外 5000 万是发布者。通过每 90 秒发布一次消息,我们可以看到平均入站和出站速率达到了每秒 100 万条以上。在发布高峰期,20 个复制节点(这些节点是连接的节点)中的每一个节点在发布过程中平均用到90% 的内存(约 113GiB)和约 97% 的 CPU(64 个 arm64 内核)。处理事务的 3 个核心节点使用 CPU 较少(使用率不到 1%),并且只使用了 28% 的内存(约 36GiB)。256 字节有效负载的发布过程中需要的网络流量在 240MB/s 到 290 MB/s 之间。在发布高峰期,loadgen 需要几乎全部内存(约 120GiB)和整个 CPU。
注意:在这个测试中,所有配对的发布者和订阅者碰巧都在同一个 broker 中,这并不是一个十分接近现实用例的理想场景。目前 EMQX 团队正在进行更多的测试,并将持续更新进展。

测试期间 EMQX 节点对 CPU、内存和网络使用情况的 Grafana 截图
为了将 RLOG 集群与等效的 Mnesia 集群进行比较,我们使用了另一种总连接数较少的拓扑:RLOG 使用 3 个核心节点+7 个复制节点,Mnesia 集群使用 10 个节点,其中 7 个节点进入连接。我们以不同速率进行连接和订阅,不进行发布。
下图展示了我们的测试结果。对于 Mnesia,连接和订阅节点的速度越快,观察到的“扁平化”行为就越多,即集群无法达到目标最大连接数,在这些测试中,目标最大连接数为 5000 万。而对于 RLOG,我们可以看到它能够达到更高的连接速率,而集群不会表现出这种扁平化行为。由此我们可以得出结论,使用 RLOG 的 Mria 在连接速率较高的情况下比我们过去采用的 Mnesia 后端性能表现更好。

经过一系列测试并获得这些令人满意的结果之后,我们认为 Mria 提供的 RLOG 数据库后端可在 EMQX 5.0 中投入使用。它已经成为当前主分支中的默认数据库后端。
References
[1] - fix(performance): Move message queues to off_heap by k32 · Pull Request #43 · emqx/mria
[3] - fix(mria_status): Remove mria_status process by k32 · Pull Request #48 · emqx/mria
[4] - Store transactions in replayq in normal mode by k32 · Pull Request #65 · emqx/mria
[5] - feat: Remove redundand data from the mnesia ops by k32 · Pull Request #67 · emqx/mria
[6] - feat: Batch transaction imports by k32 · Pull Request #70 · emqx/mria
[7] - feat: add new waiting options for publishing by thalesmg · Pull Request #160 · emqx/emqtt-bench
[8] - feat: add option to retry connections by thalesmg · Pull Request #161 · emqx/emqtt-bench
[9] - Add support for rate control for 1000+ conns/s by qzhuyan · Pull Request #167 · emqx/emqtt-bench
[10] - support multi target hosts by qzhuyan · Pull Request #168 · emqx/emqtt-bench
[11] - feat: bump max procs to 16M by qzhuyan · Pull Request #138 · emqx/emqtt-bench
[12] - feat: tune gc for publishing by thalesmg · Pull Request #164 · emqx/emqtt-bench
版权声明: 本文为 EMQ 原创,转载请注明出处。
原文链接: https://www.emqx.com/zh/blog/reaching-100m-mqtt-connections-with-emqx-5-0
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK