

一个算子在深度学习框架中的旅程
source link: https://blog.csdn.net/OneFlow_Official/article/details/125289349
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一个算子在深度学习框架中的旅程

撰文|赵露阳
算子即Operator,这里简称op。op是深度学习的基础操作,任意深度学习框架中都包含了数百个op,这些op用于各种类型的数值、tensor运算。
在深度学习中,通过nn.Module这样搭积木的方式搭建网络,而op就是更基础的,用于制作积木的配方和原材料。
譬如如下的一个demo网络:
从结构来看,这个网络是由各种nn.Module如Linear、ReLU、Softmax搭建而成,但从本质上,这些nn.Module则是由一个个基础op拼接,从而完成功能的。这其中就包含了Matmul、Relu、Softmax等op。 在OneFlow中,对于一个已有op,是如何完成从Python层->C++层的调用、流转和执行过程?本文将以
output = flow.relu(input)为例,梳理一个op从Python -> C++执行的完整过程。首先,这里给出一个流程示意图:
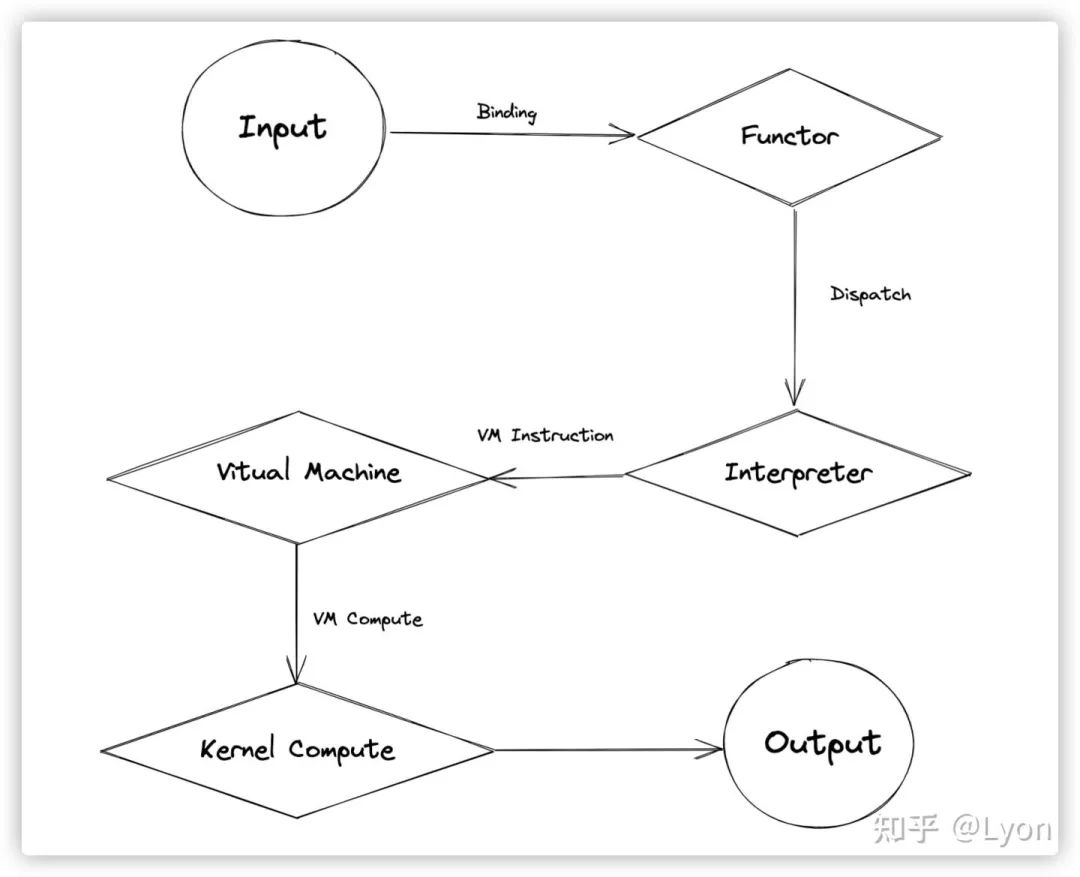
下面,将分别详细从源码角度跟踪其各个环节。
1
Binding
这里,binding是指Python和C++代码的绑定。通常,我们用Python搭建网络,训练模型,调用函数完成各种操作。实际上,这些函数通常在Python层只是一层wrapper,底层实现还是通过C++代码完成的,那么Python -> C++是如何调用的?这就需要用到Python和C++的绑定。
在深度学习框架的实现中,即可以用Python原生的C API,也可以通过pybind11来完成函数绑定,在OneFlow中,二者均有使用,譬如:
-
oneflow/api/python/framework/tensor.cpp
-
oneflow/api/python/framework/tensor_functions.cpp
中涉及到的 tensor.xxx 方法都是通过Python C API完成了函数绑定;
-
oneflow/core/functional/functional_api.yaml
中定义的诸多 flow.xxx 方法则是通过pybind实现的绑定。这里关于Python C API和pybind不做过多介绍,具体用法可以参考相应文档:
-
https://docs.python.org/zh-cn/3.8/c-api/index.html
-
https://pybind11.readthedocs.io/en/stable/index.html
下面我们回到flow.relu方法,我们在Python层调用的flow.relu实际是调用了在
python/oneflow/__init__.py中定义的oneflow._C.relu。 _C表示其实现位于底层C++。和PyTorch类似,我们也基于.yaml定义了一套接口导出及code gen的规则,譬如在 functional_api.yaml 中,我们可以看到Relu的导出接口的函数签名:
从yaml定义可以看出,flow._C.relu 接收两个参数,tensor和一个bool值,其绑定了C++的Relu方法,函数返回值也是tensor。实际上,在OneFlow编译时,会通过执行
tools/functional/generate_functional_api.py这个文件,对 functional_api.yaml 进行解析和代码生成,动态生成C++的.h和.cpp文件。
-
build/oneflow/core/functional/functional_api.yaml.h
-
build/oneflow/core/functional/functional_api.yaml.cpp
并在.cpp文件中调用相应的functor完成C++层面的函数调用。这里,还是以flow._C.relu为例,其对应的functor定义位于oneflow/core/functional/impl/activation_functor.cpp:
ReluFunctor通过
完成functor的注册,注册成functional接口后,在Python层flow._C.relu就完成了和“Relu”的绑定。同时,这个函数在C++中也可以通过functional::Relu直接调用。
2
Functor
Functor不仅是Python -> C++交互的核心,也是op调用、输入参数推导和检查的第一站。通常,各种op在functor层需要完成对输入tensor的shape、dtype、维度、元素个数等各种check,以及对op特有的逻辑进行解析和处理。Relu Functor代码如下:
可以看见,ReluFunctor是比较简单的,其定义了一个私有变量
std::shared_ptr<OpExpr> op_;这个op_即需要执行的Relu op,通过OpBuilder进行构建;functor的operator()内部,根据是否inplace走到2个不同分支,并最终通过OpInterpUtil::Dispatch()将op、输入tensor和参数派发至Interpreter处理。
3
Dispatch
各种op在functor中完成check和逻辑处理后,大多需要通过OpInterpUtil::Dispatch() 进行派发,其目的地是Interpreter。在Interpreter中,将会对op进行更进一步的处理。在oneflow/core/framework/op_interpreter/op_interpreter_util.h 中,我们可以看见多种重载的Dispatch模板代码:
这些重载,是为了应对不同的输入、输出以及OpExprInterpContext的情况。譬如这个OpExprInterpContext是op在Interpreter中所需的上下文,可能携带op计算所需要的属性(如conv2d op所需要的kernel_size、padding等)、device、sbp、parallel等描述信息。这些重载的Dispatch最终都会走到:
Dispatch至此,剩下的就要交给Interpreter了。
4
Interpreter
Get Interpreter
这里先看看GetInterpreter,这里其实就是获取所需的Interpreter,来负责op接下来的执行。省略check相关的逻辑,主要代码如下:oneflow/core/framework/op_interpreter/op_interpreter_util.cpp
通过上面的逻辑可以看出,Interpreter大体上分为Eager Interpteter和Lazy Interpreter;其中Eager Interpteter又根据Eager Mirrored和Eager Consistent有所区别。具体就是以下3种子类实现:
-
EagerMirroredInterpreter
-
EagerConsistentInterpreter
-
LazyInterpreter
普通的Eager mode下(无论是单卡还是DDP的情况)都会走到 EagerMirroredInterpreter 的逻辑;在普通Eager Mode之外,为输入tensor设置了sbp、placement则会进入到EagerConsistentInterpreter的逻辑;在Lazy Mode时(使用nn.Graph),则会进入到LazyInterpreter。
下面,我们看下这3种Interpreter的构建:
可见,这3种Interpreter构建完成后,都会以私有变量internal的形式,参与AutogradInterpreter的构建,并最终返回AutogradInterpreter。
Apply()
通过上面我们知道,EagerMirroredInterpreter、EagerConsistentInterpreter和LazyInterpreter都将为其包裹上AutogradInterpreter的壳,通过AutogradInterpreter触发Apply的调用。顾名思义,AutogradInterpreter的作用主要是和autograd相关,其主要为eager mode下前向的op节点插入对应的用于反向计算grad的节点。
我们看看这部分代码,关键部分的作用在注释里给出:
上面一坨逻辑有点多,让我们看一下重点,对于简单的Relu op,我们只需关注这部分代码:
这里,还是以上面的flow.relu为例,由于是简单的Eager Mode,所以实际会走到EagerInterpreter的Apply方法:
这里,通过宏定义APPLY_IF,增加了对不同类型op的分支处理。对于大多数用户来说,用到的op都是UserOp类型,所以这里实际上会走到这个分支中:
再看看EagerMirroredInterpreter::ApplyImpl,位于
oneflow/core/framework/op_interpreter/eager_mirrored_op_interpreter.cpp:
其最终实现是NaiveInterpret。
NaiveInterpret
NaiveInterpret简单来说,主要用于做以下几件事:
-
check input tensor的device是否一致
-
生成output tensor
-
为output tensor推导和检查shape/stride/dtype
-
构建op执行指令,并派发至vm
简化版的代码如下:
Interpreter的终点是虚拟机(vm)。vm部分,是OneFlow比较独特的设计,内容很多,这里暂不展开了:) 可以简单理解,派发至vm后,此op将进入一个任务执行的队列,将会等待其vm的调度、执行。
5
Compute
在Interpreter将op执行指令派发至vm后,经过调度逻辑处理后,将会在
oneflow/core/eager/opkernel_instruction_type.cpp被触发执行,核心代码如下:
operand->user_opkernel()->Compute(compute_ctx, state, cache);将触发op kernel的实际执行。通常来说,op的kernel实现根据device的不同,会派发到不同的实现,其一般都位于:
oneflow/user/kernels/xxx_kernel.cpponeflow/user/kernels/xxx_kernel.cu这里的Relu op相对比较特殊,是用primitive实现的(primitive也是oneflow中一种独特的设计,有着良好的抽象和可组合性),具体这个UnaryPrimitive就是elementwise unary的模板+UnaryFunctor的组合。其调用链如下:

UnaryPrimitiveKernel
ep::primitive::ElementwiseUnary
UnaryFunctor
这个UnaryFuntor根据不同的Unaray op类型,特化出不同的具体functor实现,具体到Relu op,其实现位于
oneflow/core/ep/common/primitive/unary_functor.h:
至此,我们已经完成了一个op的Python -> C++ 之旅。从细节上看,是相对复杂的,但从整体流程上看,其实是比较简单的,排除了binding,vm调度机制等细节,其主要过程其实就4个环节: Functor -> Dispatch -> Interpreter -> Kernel Compute。
实现/新增一个op,通常也不需要管中间的Dispatch以及Interpreter,我们只需重点关注和该op强相关的部分——Functor层面的参数、op逻辑检查,以及Kernel Compute部分的实际op运算。
(参考代码:
https://github.com/Oneflow-Inc/oneflow/commit/1dbdf8faed988fa7fd1a9034a4d79d5caf18512d)
其他人都在看
 https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK