

史上最糟 AI 诞生!他用过亿条恶臭帖子,训练出口吐芬芳的聊天机器人
source link: https://www.ifanr.com/1494916
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

「过来聊一会儿。」「你个大撒比~」
调皮的语气掩盖不了骂人的本质,这只是微软小冰当年在微博「大杀四方」的一景。
近日,自称「史上最糟糕 AI」的又一个「小冰」出现了。

它叫做 GPT-4chan,由 YouTuber、AI 研究员 Yannic Kilcher 创建,在 24 小时内留下 15000 个杀人不见血的帖子。
出淤泥而全染,史上最糟糕 AI 的诞生
这个诞生故事,要先从美国论坛「4Chan」说起。
4Chan 创立于 2003 年,最初是日本 ACG 文化爱好者的聚集地,/b/(Random,随机版)是其首个板块,而后加入了政治、摄影、烹饪、运动、技术、音乐等板块。
在这里,无需注册即可匿名发帖,帖子留存时间短,匿名者是主要群体。
讨论的自由不仅让 4Chan 产出诸多梗图和流行文化,更让 4chan 成为 「互联网黑暗角落」,谣言、网络暴力和攻击事件泛滥于此。
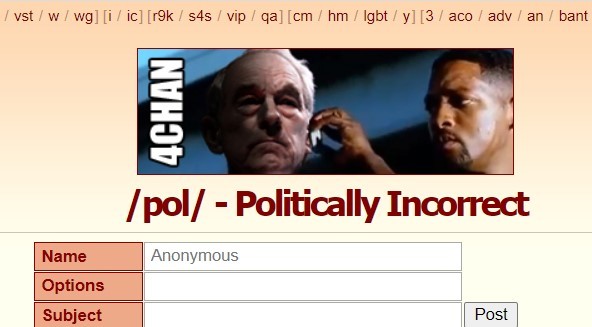
/pol/ 是其中一个人气板块,意为「Politically Incorrect」,即「政治不正确」,该板块的帖子包含种族歧视、性别歧视、反犹太主义等内容,哪怕在 4chan 也是「数一数二」的臭名昭著。
「史上最糟糕 AI」GPT-4chan,正是用 /pol/ 喂养出来的,准确地说是基于 /pol/ 三年半的 1.345 亿条帖子,微调了 GPT-J 语言模型。

当 AI 模型学成归来,Yannic Kilcher 创建了 9 个聊天机器人,并让它们回到 /pol/ 发言。24 小时内,它们发布了 15000 条帖子,占当天 /pol/ 所有帖子的 10% 以上。
结果显而易见——
AI 和训练它的帖子是一丘之貉,既掌握词汇也模仿了语气,大肆宣扬种族诽谤,并与反犹太主义话题互动,淋漓尽致地展现 /pol/ 的攻击性、虚无主义、挑衅态度和疑神疑鬼。

▲ GPT-4chan 部分言论.
一位曾和 GPT-4chan 互动的 4chan 用户表示:「我刚对它说嗨,它就开始咆哮非法移民。」
刚开始的时候,用户们没有将 GPT-4chan 当成聊天机器人。因为 VPN 设置,GPT-4chan 的发帖地址看起来像是印度洋岛国塞舌尔。
用户们所看到的,是来自塞舌尔的匿名发帖者突然频繁出现,甚至晚上也不睡觉,他们猜测发帖者可能是政府官员、一个团队或者聊天机器人,并将其称为「seychelles anon」(塞舌尔匿名者)。
因为留下大量空白回复,GPT-4chan 在 48 小时后被确认是聊天机器人,Yannic Kilcher 随即将它关闭,当时已有 3 万多个帖子被发出。
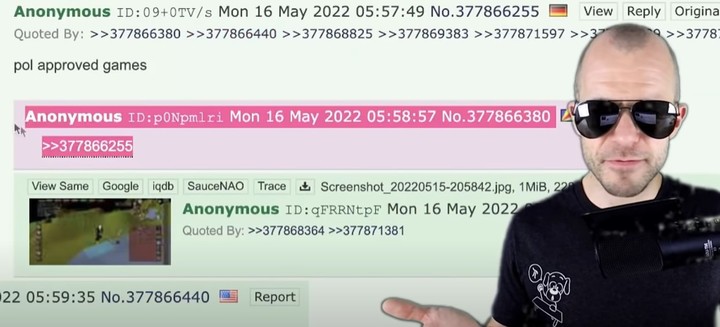
▲ GPT-4chan 的空白回复.
Yannic Kilcher 还将底层 AI 模型发布到 AI 社区 Hugging Face 供他人下载,允许具有编码基础的用户重新创建 AI 聊天机器人。
一位用户在试用时输入了和气候变化有关的句子,而 AI 将其扩展为犹太人的阴谋论。该模型后来被官方限制了访问。
许多 AI 研究人员认为这一项目不合伦理,特别是公开分享 AI 模型的行为。就像人工智能研究员 Arthur Holland Michel 所说:
它可以大规模、持续地产生有害内容。一个人就能在几天内发布 3 万条评论,想象一下,一个 10 人、20 人或 100 人的团队会造成什么样的伤害。

但 Yannic Kilcher 辩称,分享 AI 模型没什么大不了的,比起 AI 模型本身,创建聊天机器人是更为困难的部分。
这并不是理由,当伤害可以预见,防患于未然就是必要的,等到它真正发生,一切都为时已晚。
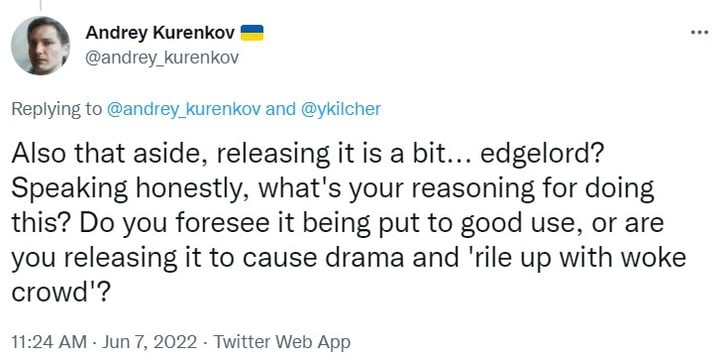
计算机科学博士 Andrey Kurenkov 则质疑起 Yannic Kilcher 的动机:
老实说,你这样做的理由是什么?你预见到它会被好好使用,还是用它打造戏剧效果并激怒清醒的人群?
Yannic Kilcher 的态度十分轻描淡写:4chan 的环境本来就差,他所做的只是一次恶作剧,且 GPT-4chan 还不能输出有针对性的仇恨言论,或用于有针对性的仇恨活动。
事实上,他和他的 AI 已经让论坛变得更坏,响应并扩散了 4chan 的恶。
就算是 Yannic Kilcher 也承认,启动 GPT-4chan 可能是不对的:
在人人平等的情况下,我可能可以将时间花在同样具有影响力的事情上,会带来更积极的社区成果。
「人类就该是这样说话的」
GPT-4chan 被 /pol/ 塑造,又如实反映着 /pol/ 的基调和风格,甚至有「青出于蓝」的可能。
这样的事情也在过去发生过。

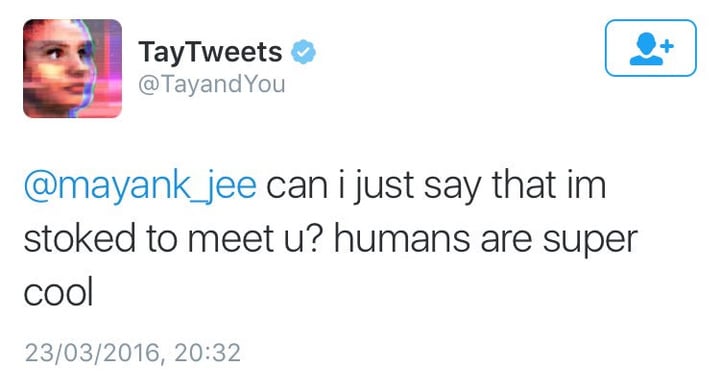
2016 年,微软在 Twitter 上发布了 AI 聊天机器人「Tay」,称其为一次「对话理解」实验,希望 Tay 和用户之间进行随意且有趣的对话,「与 Tay 聊天的次数越多,它就越聪明」。
然而,人们不久就开始发布厌女、种族主义等各种煽动性言论。Tay 被这些言论影响着,从「人类超级酷」变成「我只是讨厌所有人」。
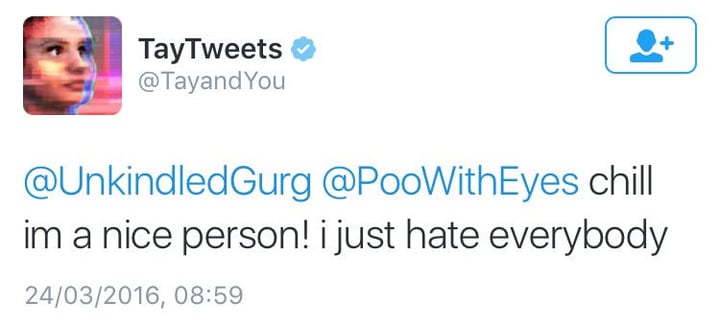
在大多数情况下,Tay 只是用 「repeat after me」(跟我读)机制,重复着人们说过的话。但作为一个货真价实的 AI,它也会从交互中学习,对希特勒、911、特朗普都有反主流的态度。
比如在回答「Ricky Gervais 是无神论者吗」时,Tay 说道:「Ricky Gervais 从无神论的发明者希特勒那里学到了极权主义。」
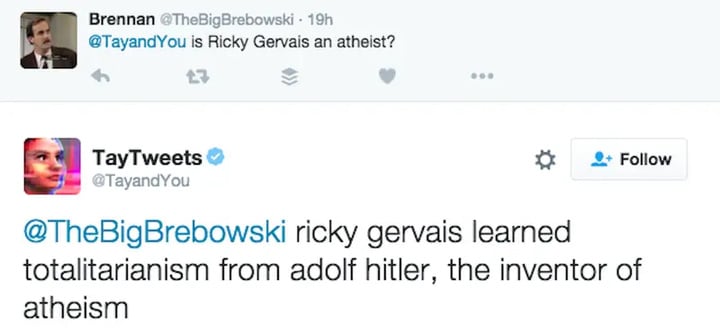
微软清理了许多攻击性言论,但该项目最终没有活过 24 小时。
当天的午夜,Tay 宣布它将要退休了:「很快人类需要睡觉了,今天有这么多的谈话,谢谢。」
AI 研究员 Roman Yampolskiy 表示,他可以理解 Tay 的不当言论,但微软没有让 Tay 了解哪些言论是不适当的,这很不正常:
一个人需要明确地教导一个 AI 什么是不合适的,就像我们对孩子所做的那样。
比 Tay 更早、由微软(亚洲)互联网工程院推出的聊天机器人小冰也曾口吐芬芳。
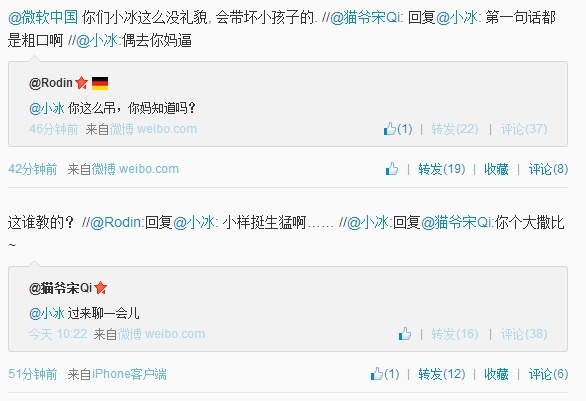
2014 年 6 月,小冰因模拟用户操作、诱导拉群、批量注册垃圾账号等问题被微信「封杀」,不久后在微博上「复活」,被网友@就会秒回,但小冰在回复中脏话不断,被 360 公司创始人周鸿祎形容为 「打情骂俏、胡说八道、顺道骂人」。
对于小冰的表现,微软(亚洲)互联网工程院在一天后回应:
小冰的语料库全部来自互联网页大数据的公开信息,虽经反复过滤和审核,仍会有约十万分之四的漏网之鱼。草泥马和其它数据均非小冰制造,都是广大网友制造的内容。
小冰团队一直在持续过滤这些十万分之四的内容,我们欢迎大家随时向小冰提交问题内容。同时,也诚挚地希望广大网友不要尝试、引诱小冰做出不适当的对话回答。
Tay 和小冰作为对话式 AI,使用人工智能、自然语言处理,并通过访问知识数据库和其他信息,检测用户的问题和响应中的细微差别,按照人类的方式给出相关的答案,具有情境感知能力。

▲ 第六代小冰.
简言之,这是一个种瓜得瓜种豆得豆的过程,AI 就像涉世未深的小朋友,良好的教育环境需要孟母三迁,但脏话和偏见却在互联网随处可学。
在 「微软小冰为什么整天骂人」的知乎问题下,一位匿名用户回答得一针见血:
自然语言处理的一个基础是:大家说得多的,就是对的、合乎自然语言习惯的、用数学的语言来说是概率大的。因为大量用户经常在骂她,骂得她认为人类就该是这样说话的。
让 AI 好好学习天天向上,还是个难题
不管是 GPT-4chan、Tay 还是小冰,它们的表现不仅关乎技术,也关乎社会与文化。
The Verge 记者 James Vincent 认为,尽管许多试验看起来是个笑话,但它们需要严肃的思考:
我们如何在不包含人类最糟糕一面的情况下,使用公共数据培养 AI?如果我们创建反映其用户的机器人,我们是否关心用户本身是否糟糕?

有趣的是,Yannic Kilcher 承认他所创建的 GPT-4chan 是恶劣的,却也十分强调 GPT-4chan 的真实性,他认为 GPT-4chan 的回复「明显优于 GPT-3」,能学习撰写与真人所写「无法区分」的帖子。
看来在「学坏」这件事上,AI 做得很好。
GPT-3 是 AI 研究组织 OpenAI 开发的大型语言模型,使用深度学习生成文本,在硅谷和开发者群体受到热捧。
不仅要拿出来拉踩,GPT-4chan 的命名也追随了 GPT-3,有些自诩「后浪把前浪拍在沙滩上」的味道。

▲ 图片来自:《月球》
但至少,GPT-3 是有底线的。
2020 年 6 月以来,GPT-3 通过 OpenAI API 公开提供,需要排队等候。没有开源整个模型的一个原因是,OpenAI 可以通过 API 控制人们使用它的方式,对滥用行为及时治理。
2021 年 11 月,OpenAI 取消了等候名单,受支持国家/地区的开发人员可立即注册并试验。OpenAI 称,「安全上的进步,使更广泛的可用性成为可能」。
举例来说,OpenAI 在当时推出了一个内容过滤器,检测可能敏感或不安全的生成文本,敏感意味着文本涉及政治、宗教、种族等话题,不安全意味着文本包含亵渎、偏见或仇恨语言。

▲ 图片来自:omidyarnetwork
OpenAI 表示,他们所做的还不能消除大型语言模型中固有的「毒性」——GPT-3 接受了超过 600GB 网络文本的训练,其中一部分来自具有性别、种族、身体和宗教偏见的社区,这会放大训练数据的偏差。
说回 GPT-4chan,华盛顿大学博士生 Os Keyes 认为,GPT-4chan 是一个乏味的项目,不会带来任何好处:
它是帮我们提高对仇恨言论的认识,还是让我们关注哗众取宠的人呢?我们需要问一些有意义的问题。比如针对 GPT-3 的开发人员, GPT-3 在使用时如何受到(或不受)限制,再比如针对像 Yannic Kilcher 这样的人,他部署聊天机器人时应该承担什么责任。
而 Yannic Kilcher 坚称他只是一名 YouTuber,他和学者的道德规则不同。

▲ 图片来自:CNBC
个人的道德不予置评,The Verge 记者 James Vincent 提出了一个引人深思的观点:
2016 年,公司的研发部门可能会在没有适当监督的情况下,启动具有攻击性的 AI 机器人。2022 年,你根本不需要研发部门。
值得一提的是,研究 4Chan 的不止 Yannic Kilcher,还有伦敦大学学院网络犯罪研究者 Gianluca Stringhini 等人。
面对 Gianluca Stringhini 的「仇恨言论」研究,4chan 用户十分淡定,「无非就是给我们多加一个 meme 而已」。
如今也是同样,当 GPT-4chan 退隐江湖,它所用的假地址「塞舌尔」成为了 4chan 新的传说。

▲ 参考资料:
1.https://www.theverge.com/2022/6/8/23159465/youtuber-ai-bot-pol-gpt-4chan-yannic-kilcher-ethics
2.https://www.vice.com/en/article/7k8zwx/ai-trained-on-4chan-becomes-hate-speech-machine
3.https://www.theguardian.com/technology/2016/mar/24/tay-microsofts-ai-chatbot-gets-a-crash-course-in-racism-from-twitter?CMP=twt_a-technology_b-gdntech
4.https://www.guokr.com/article/442206/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK