

神经网络前向和后向传播推导(二):全连接层 - Wonder-YYC
source link: https://www.cnblogs.com/chaogex/p/16350439.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

大家好~本文推导全连接层的前向传播、后向传播、更新权重和偏移的数学公式,其中包括两种全连接层:作为输出层的全连接层、作为隐藏层的全连接层。
神经网络前向和后向传播推导(一):前向传播和梯度下降
神经网络前向和后向传播推导(二):全连接层
构建神经网络
我们构建一个三层神经网络,由一层输入层+两层全连接层组成:
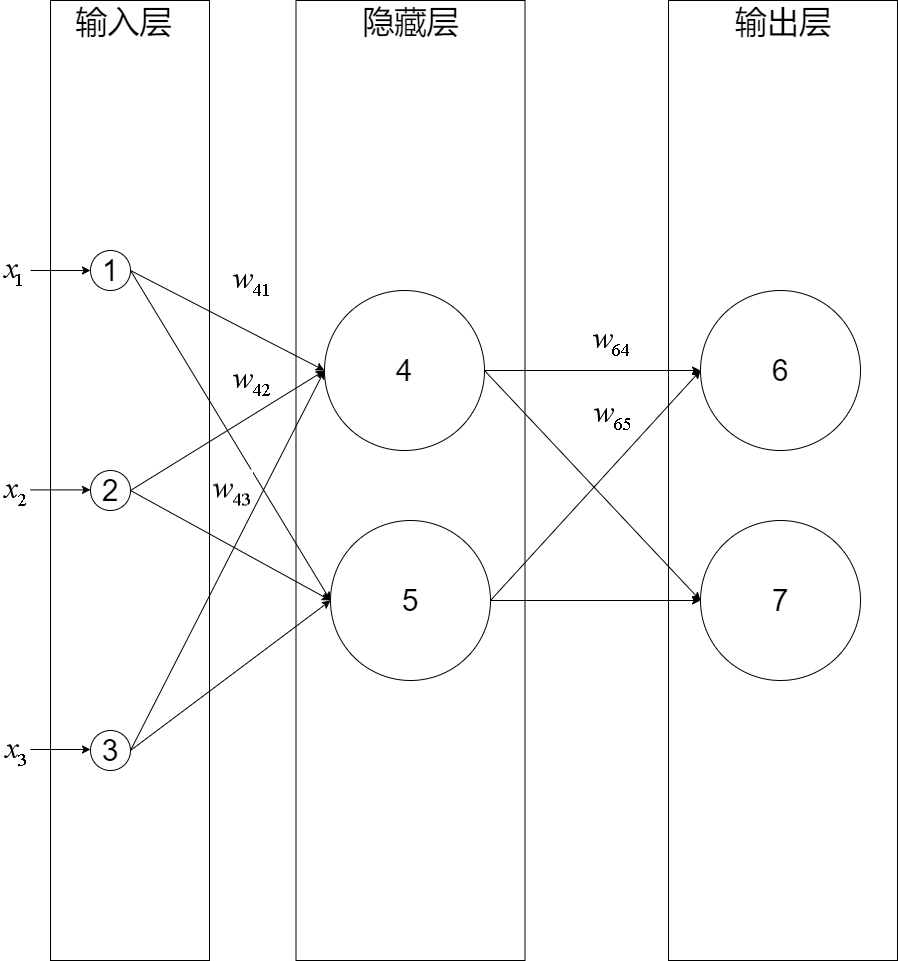
输入层有三个节点,我们将其依次编号为1、2、3;隐藏层的两个节点,编号依次为4、5;输出层的两个节点编号为6、7。因为我们这个神经网络是全连接网络,所以可以看到每个节点都和上一层的所有节点有连接。比如,我们可以看到隐藏层的节点4,它和输入层的三个节点1、2、3之间都有连接,其连接上的权重分别为w41,w42,w43
(注意:权重的序号的命名规则是下一层的序号在上一层的序号之前,如为w41而不是w14)
推导前向传播
节点4的输出值y4的计算公式为:
推导隐藏层的前向传播
我们把隐藏层的权重向量组合在一起成为矩阵,就推导出隐藏层的前向传播计算公式了:
推导输出层的前向传播
同理,可推出输出层的前向传播计算公式:
推导后向传播
我们先来看下输出层的梯度下降算法公式:
其中:k是输出层的节点序号,j是隐藏层的节点序号,wkj是输出层的权重矩阵W输出层的权重值,dEdwkj是节点k的梯度
设netk函数是节点k的加权输入:
因为E是→y输出层的函数,→y输出层是netk的函数,netk是wkj的函数,所以根据链式求导法则,可以得到:
定义节点k的误差项δk为:
因为yj已知,所以只要求出δk,就能计算出节点k的梯度
同理,对于隐藏层,可以得到下面的公式:
其中:j是隐藏层的节点序号,i是输入层的节点序号,wji是隐藏层的权重矩阵W隐藏层的权重值,dEdwji是节点j的梯度
因为xi已知,所以只要求出δj,就能计算出节点j的梯度
推导输出层的δk
因为节点k的输出值yk作为→y输出层的一个值,并没有影响→y输出层的其它值,所以节点k直接影响了E。也就说E是yk的函数,yk是netk的函数,所以根据链式求导法则,可以得到:
考虑上式的第一项:
上式的第二项即为求激活函数f的导数:
将第一项和第二项带入dEdnetk,得到:
只要确定了E和激活函数f,就可以求出δk
一般来说,E可以为softmax,f可以为relu
推导隐藏层的δj
因为节点j的输出值yj作为输出层所有节点的一个输入值,影响了→y输出层的每个值,所以节点j通过输出层所有节点影响了E。也就说E是输出层所有节点的net的函数,每个net函数netk都是netj的函数,所以根据全导数公式,可以得到:
因为netk是yj的函数,yj是netj的函数,所以根据链式求导法则,可以得到:
代入,得:
只要确定了激活函数f和得到了每个δk,就可以求出δj
后向传播算法
通过上面的推导,得知要推导隐藏层的δj,需要先得到出下一层(也就是输出层)每个节点的误差项δk
这就是反向传播算法:需要先计算输出层的误差项,然后反向依次计算每层的误差项,直到与输入层相连的层
推导权重和偏移更新
经过上面的推导,可以得出输出层的更新公式为:
隐藏层的更新公式为:
我们在推导隐藏层的误差项时,应用了全导数公式,这是一个难点
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK