

正确处理全球五大互联网注册机构的 IP 数据
source link: https://soulteary.com/2022/06/07/correct-handling-of-ip-data-from-the-world-s-top-five-internet-registries.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

正确处理全球五大互联网注册机构的 IP 数据
如果我们不需要精准判断服务请求来源和用户 IP 归属地,使用全球五大 RIR 机构每日更新的 IP 分配数据,相比较使用商业 IP 数据库而言,会是一个低成本的方案(免费)。
本文将聊聊如何正确对 APNIC、ARIN、RIPE NCC、LACNIC 和 AFRINIC 这五个全球顶级互联网注册机构(RIR)的 IP 注册数据进行处理。
网上关于这几个顶级 RIR 的数据处理的文章和内容并不少,但其实其中不乏谬误。
相信有一些读者对于 RIR 机构的了解并不多,所以我简单介绍一下目前仅有的五个全球互联网注册机构,它们负责统筹和管理我们日常使用的 IP ,先来看一下这几个机构各自的管辖区域。
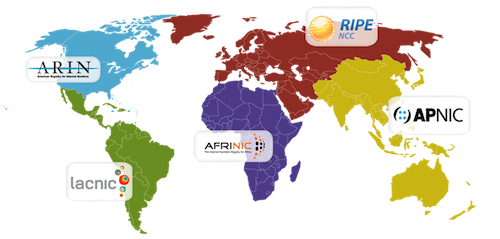
简单来说,在 90 年代之后,考虑到当前世界上的 IP 地址数量已经非常多,日常繁杂的 IP 地址分配等维护工作对于单一机构或者某几个学术院校来说,是一件很麻烦的事情。
各地区(亚太、南北美、欧洲、中东、非洲)的互联网发展速度和程度并不相同,语言、文化,甚至是时区都会对当时的维护者来说是一个麻烦的事情,为了更好的服务全球的用户,陆续出现了五个顶级机构:
简单了解这些机构之后,我们来回到正题上,聊聊如何处理它们公开的 IP 数据,网络上常见的谬误,以及该如何正确的处理它们分享的数据。
从顶级 IP 注册机构获取公开的 IP 数据
在聊如何下载数据之前,我们需要先了解这些数据有哪些“特点”,尽可能避开细节上的坑。
公开数据的一些坑
上面提到的五个机构会定期更新 IP 注册数据,我们可以从下面几个地址获取数据(NRO 版本数据):
https://ftp.arin.net/pub/stats/arin/delegated-arin-extended-latest
https://ftp.ripe.net/ripe/stats/delegated-ripencc-extended-latest
https://ftp.apnic.net/stats/apnic/delegated-apnic-extended-latest
https://ftp.lacnic.net/pub/stats/lacnic/delegated-lacnic-extended-latest
https://ftp.afrinic.net/pub/stats/afrinic/delegated-afrinic-extended-latest
这里要注意的是,虽然五个机构是伙伴关系,有的亚太的数据文件我们可以在欧洲或者非洲等 RIR 的服务器上找到。
https://ftp.ripe.net/pub/stats/apnic/delegated-apnic-extended-latest
https://ftp.apnic.net/stats/apnic/delegated-apnic-extended-latest
但是,这里埋着第一个坑:这些机构并不保证自己服务器上其他的 RIR 的数据是最新的版本。
就比如美国区域的 ARIN 只会更新自己的数据,其他的数据版本停留在 2013 年的版本。所以,想要得到哪个区域的数据,最好还是从哪个区域的注册机构站点获取数据,避免获取到老的数据。
第二个坑是,我们常常在网上看到的下载文件名称是 delegated-apnic-latest、delegated-ripencc-latest,但是当我们想获取美国注册数据的时候,得到的结果会是 404:
curl https://ftp.arin.net/pub/stats/arin/delegated-arin-latest
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>404 Not Found</title>
</head><body>
<h1>Not Found</h1>
<p>The requested URL /pub/stats/arin/delegated-arin-latest was not found on this server.</p>
</body></html>
这是因为美国的注册机构在 2013 年彻底废弃了老版本的数据格式,使用了新版本的 NRO 格式来进行数据统计。新版本的 NRO 格式相比较老格式,多了一列来表示 IP 分配给了那个组织(REG-ID),所以虽然地址变化了,但还是向前兼容的。
为了数据源格式能够保持一致,所以这里推荐使用本小节一开始推荐的几个数据地址,而非网络上各种转来转去的陈旧文章中使用的 delegated-${region}-latest 格式的文件。
此外,美国的 ARIN 的数据还有一个小坑,它是唯一一个 MD5 校验值倒序存放的数据源,所以后续在处理下载文件的完整性校验时,也需要额外进行处理。
当然,有问题的并不只有 ARIN 的数据,亚太注册机构 APNIC 的数据里一枝独秀的添加了“注释内容”。这几个机构的数据也并没有完全按照各自“管辖地”来划分,有一些古早的数据,可能还是散落在 ARIN 这些比较老的机构里,比如在 ARIN 里,你能够找到本应该存放在 APNIC 的我国 HK 地区的数据记录。
在使用这些数据的时候,还有一个小技巧,使用合适的访问协议。这些注册机构已经公开的提供了二十年的数据,所以考虑到向前兼容,数据支持通过 ftp、http、https 三种协议进行访问。
ftp://ftp.apnic.net/pub/stats/apnic/delegated-apnic-latest
http://ftp.apnic.net/pub/stats/apnic/delegated-apnic-latest
https://ftp.apnic.net/pub/stats/apnic/delegated-apnic-latest
一般情况下,我们使用 https 会获得更快的数据下载速度,如果你是在容器中使用,但不想安装 ca-certificates 软件包,那么也可以考虑使用 http 协议来访问数据。
聊完数据的问题,我们来聊聊如何编写下载脚本。
编写数据下载程序
下载数据的方式有很多种,最简单的方式莫过于使用系统自带的 curl 或者 wget 啦,但是这两个命令不一定会同时存在于操作系统,所以我写了一个简单的兼容脚本,来按需调用程序,依次下载不同 RIR 机构的 IP 数据:
#!/bin/sh
# author soulteary
command_exists() {
command -v "$@" >/dev/null 2>&1
}
use_curl() {
command_exists curl || return 1
}
use_wget() {
command_exists wget || return 1
}
declare -a files
files[0]=https://ftp.arin.net/pub/stats/arin/delegated-arin-extended-latest
files[1]=https://ftp.arin.net/pub/stats/arin/delegated-arin-extended-latest.md5
files[2]=https://ftp.ripe.net/ripe/stats/delegated-ripencc-extended-latest
files[3]=https://ftp.ripe.net/ripe/stats/delegated-ripencc-extended-latest.md5
files[4]=https://ftp.apnic.net/stats/apnic/delegated-apnic-extended-latest
files[5]=https://ftp.apnic.net/stats/apnic/delegated-apnic-extended-latest.md5
files[6]=https://ftp.lacnic.net/pub/stats/lacnic/delegated-lacnic-extended-latest
files[7]=https://ftp.lacnic.net/pub/stats/lacnic/delegated-lacnic-extended-latest.md5
files[8]=https://ftp.afrinic.net/pub/stats/afrinic/delegated-afrinic-extended-latest
files[9]=https://ftp.afrinic.net/pub/stats/afrinic/delegated-afrinic-extended-latest.md5
download() {
if use_curl; then
for file in ${files[*]}
do
curl -O "${file}"
done
else
if use_wget; then
for file in ${files[*]}
do
wget -c "${file}"
done
else
echo "You need install `wget` or `curl` first."
return 1
fi
fi
}
download
将上面的内容保存为 download.sh,然后执行 bash download.sh 就能够开始数据下载了。当程序执行完毕之后,在当前目录就能够看到来自各种 RIR 的数据和对应的文件校验值啦。
total 79056
drwxr-xr-x 12 soulteary staff 384 6 6 21:29 .
drwxr-xr-x 15 soulteary staff 480 6 6 21:29 ..
-rw-r--r-- 1 soulteary staff 711881 6 6 20:49 delegated-afrinic-extended-latest
-rw-r--r-- 1 soulteary staff 74 6 6 20:49 delegated-afrinic-extended-latest.md5
-rw-r--r-- 1 soulteary staff 7570060 6 6 20:49 delegated-apnic-extended-latest
-rw-r--r-- 1 soulteary staff 73 6 6 20:49 delegated-apnic-extended-latest.md5
-rw-r--r-- 1 soulteary staff 10999023 6 6 20:17 delegated-arin-extended-latest
-rw-r--r-- 1 soulteary staff 67 6 6 20:17 delegated-arin-extended-latest.md5
-rw-r--r-- 1 soulteary staff 3969444 6 6 20:49 delegated-lacnic-extended-latest
-rw-r--r-- 1 soulteary staff 74 6 6 20:49 delegated-lacnic-extended-latest.md5
-rw-r--r-- 1 soulteary staff 16367291 6 6 20:22 delegated-ripencc-extended-latest
-rw-r--r-- 1 soulteary staff 74 6 6 20:22 delegated-ripencc-extended-latest.md5
完整的数据下载脚本,我已经上传到了 GitHub,如果你有需要,可以自取:https://github.com/soulteary/Home-Network-Note/blob/master/scripts/ip-data-downloader.sh只需要将脚本程序保存到本地,然后执行 bash ip-data-downloader.sh,等待数据完成下载即可。
编写数据校验程序
出于数据不时会更新,以及我们下载时的网络可能不会那么稳定两个原因,推荐对下载的数据进行校验。
考虑到 macOS 和 Linux 上针对数据进行 MD5 校验的方法并不相同,以及上文中提到的 ARIN 数据源校验文件格式和其他数据源完全不同,我编写了一个小脚本,来针对数据进行校验。
#!/bin/sh
# author soulteary
command_exists() {
command -v "$@" >/dev/null 2>&1
}
use_md5() {
command_exists md5 || return 1
}
use_md5sum() {
command_exists md5sum || return 1
}
files=$(ls *latest)
download() {
if use_md5; then
for file in ${files[*]}
do
echo $file
digst=$(md5 -r $file | awk '{print $1}')
checksum=$(cat "$file".md5 | awk '{print $4}')
if [ "$digst" != "$checksum" ]; then
checksum=$(cat "$file".md5 | awk '{print $1}')
if [ "$digst" != "$checksum" ]; then
echo "$file data validation failed, please try downloading again."
fi
fi
done
else
if use_md5sum; then
for file in ${files[*]}
do
echo $file
digst=$(md5sum $file | awk '{print $1}')
checksum=$(cat "$file".md5 | awk '{print $4}')
if [ "$digst" != "$checksum" ]; then
checksum=$(cat "$file".md5 | awk '{print $1}')
if [ "$digst" != "$checksum" ]; then
echo "$file data validation failed, please try downloading again."
fi
fi
done
else
echo "You need install `md5` or `md5sum` first."
return 1
fi
fi
}
download
将上面的内容保存为 verify.sh,执行脚本,如果没有看到 data validation failed, please try downloading again. 的提示,那么就能够确认下载的数据是完整的,可以用于之后的处理啦。
上面的程序,我也已经上传到了 GitHub,如果你需要的话,可以从这里自取:https://github.com/soulteary/Home-Network-Note/blob/master/scripts/ip-data-verify.sh
正确处理公开的 IP 数据
当我们已经完成了数据的下载和校验之后,便可以开始着手进行数据的处理了。
进行数据预处理
为了方便后续折腾,先创建一个数据目录,然后将刚刚下载好的数据移动到这个目录中。
mkdir data
mv delegated-* data
如果我们想根据地区编号来对数据进行分堆儿,可以考虑将数据文件先拼合到一起,并先进行去重操作。然后过滤掉前文中提到的注释内容。
cat data/delegated-*-latest | sort | uniq > data/all.txt
cat data/all.txt | awk '$1 ~ /^[^;#]/' > data/pure.txt
整理数据 IP 归属地列表
实际使用的时候,一般是以下两个场景:
- 判断用户是否在或者不在某个或者某几个地区(比如是否是国内用户)
- 判断要访问的目标网站/接口是否是海外网站
为了程序效率更高,这里推荐先梳理数据包含的地区清单,以方便后续根据地区清单来将数据进行分堆儿:
cat data/pure.txt | awk -F '|' '{print $2}' | sort | uniq
当我们执行完命令之后,可以看到类似下面的输出:
*
AD
AE
AF
AG
AI
...
...
ZA
ZM
ZW
ZZ
afrinic
apnic
arin
lacnic
ripencc
可以看到输出的内容包含了“空白内容”、“通配符(*)”、“几个 RIR 机构名称”。没错,这里是又一个坑,IP 数据除了包含各种地区的数据之外,还包含了一些“悬而未决”的数据,以及“各个机构的自留地”,需要在处理的时候去除掉。
庆幸的是,我们可以通过强大的 AWK 表达式来过滤掉字符串长度不等于 2 的地区名称:
cat data/pure.txt | awk -F '|' '{print $2}' | sort | uniq | awk '{ if (length($0) == 2) print }' > data/region.txt
执行完命令,IP 归属地列表就搞定了。
根据归属地整理 IP 数据
假设我们要做一个仅限国内用户访问网站的功能,需要筛选出国内的 IP 地址,以网上搜索到的命令为例,大概是这样操作:
cat data/pure.txt | awk -F '|' '/CN/&&/ipv4/ {print $4 "/" 32-log($5)/log(2)}'
cat data/pure.txt | awk -F '|' '/CN/&&/ipv6/ {print $4 "/" 32-log($5)/log(2)}'
第一条命令的出处可能是这位博主在 2018 年写的一篇博客, 这条命令是没有问题的。
但是,第二条命令,一旦我们执行,我们将会得到类似下面的数据处理结果:
240f:4000::/27.415
240f:8000::/27.415
240f:c000::/27.415
2a03:f900::/27.142
2a07:f480::/27.142
2a09:3680::/27.142
2a0a:2840::/27.142
2a0d:280::/27.142
2a0e:7580::/27.142
2a10:1cc0::/27.142
好嘛,处理 CIDR 都搞出小数点了,这显然不对啊。如果有人原封不动的使用这个命令,业务肯定出问题啊。
而且,这样的写法不够灵活,如果我们需要同时允许某几个地区的话,难道要重复写几遍么?甚至极端情况下,如果我们要生成所有区域的数据,这个程序的行数恐怕会非常壮观。
解决上面这两个问题也不难,我们只要让程序能够动态读取列表,并修正 IPv6 相关数据的处理细节即可:
#!/bin/sh
# author soulteary
mkdir -p result
for region in $(cat data/region.txt)
do
echo "${region}"
echo "cat data/pure.txt | awk -F '|' '/${region}/&&/ipv4/ {print \$4 \"/\" 32-log(\$5)/log(2)}' | cat > result/${region}-ipv4.txt" | bash -
echo "cat data/pure.txt | awk -F '|' '/${region}/&&/ipv6/ {print \$4 \"/\" \$5}' | cat > result/${region}-ipv6.txt" | bash -
done
将上面的程序保存为 split.sh,然后使用 bash split.sh 执行程序。
稍等片刻,我们就能够在当前目录中看到一个新的目录 result,里面包含了若干以地区和 IP 类型命名的文件。
# ls result/
AD-ipv4.txt AZ-ipv6.txt BT-ipv4.txt CU-ipv6.txt EU-ipv4.txt GM-ipv6.txt IM-ipv4.txt KN-ipv6.txt MA-ipv4.txt MT-ipv6.txt NU-ipv4.txt QA-ipv6.txt SO-ipv4.txt TM-ipv6.txt VG-ipv4.txt
AD-ipv6.txt BA-ipv4.txt BT-ipv6.txt CV-ipv4.txt EU-ipv6.txt GN-ipv4.txt IM-ipv6.txt KP-ipv4.txt MA-ipv6.txt MU-ipv4.txt NU-ipv6.txt RE-ipv4.txt SO-ipv6.txt TN-ipv4.txt VG-ipv6.txt
AE-ipv4.txt ...
如果我们使用命令查看文件:
# head result/CN-ipv4.txt
1.0.1.0/24
1.0.2.0/23
1.0.32.0/19
...
# head result/CN-ipv6.txt
2001:250:2000::/35
2001:250:4000::/34
2001:250:8000::/33
...
就能够会看到已经处理完毕的各种数据啦。
其他:免费数据的遗憾
在文章的开头,我曾提到,“对于不需要精准判断服务请求来源、归属地的场景下,使用全球五大 RIR 是一个低成本(免费)的方案”。
相信你只要按照上面分享的方法,不难得到每日更新的 IP 归属数据。这样的数据对于个人开发者来说,或许是足够使用的。但是如果是生产场景,强烈建议考虑下基于路由表和 Ping 值检测等探测手段生成的商用 IP 库。
因为 IP 数据每时每刻都在更新和变动,甚至在当前云服务时代还会出现跨地区“借用”的情况,造成判断非常不准确的情况发生。在本文写完的时候,我曾咨询国内头部 IP 数据供应商(就是知乎、微博、阿里等厂商都在用的那家)的创始人高春辉:
“高总,如果使用 RIR 的数据做基础的归属地判断,和你们的数据差异有多少呢?”
“严谨点的说,至少有 5%~10% 的差别,换算成数字,大概是 2~4 个亿个 IP 上会有出入,国家量级的出入。这是啥概念呢?我们按照 4 亿计算的话,恐怕把全球 IP 拥有量 TOP10 的后五名加一起才够这个数字。你知道这五个国家是哪儿么?是韩国、巴西、法国、加拿大、意大利…”
面对这个夸张的数据推测,我原本是半信半疑,直到我找到了两个表格,分别包含本文分享的 RIR 数据,和上面提到的、现在国内各大平台使用的 IP 数据:

表格数据来源:
写到这里,全球五大顶级注册机构的数据处理上的坑就分享完了。
下一篇相关的内容里,我会聊聊如何在 Golang 、Nginx 、WASM 中高效的使用这类 IP 数据,完成一些我们常见的互联网系统风控/产品策略功能。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK