

吴维伟:京东大数据的强一致、高可用跨域存储实践,及冷热数据分层存储实践
source link: https://www.51cto.com/article/710954.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

今天的介绍会从下面三点展开:
- 京东数据平台架构简介
01京东数据平台架构简介
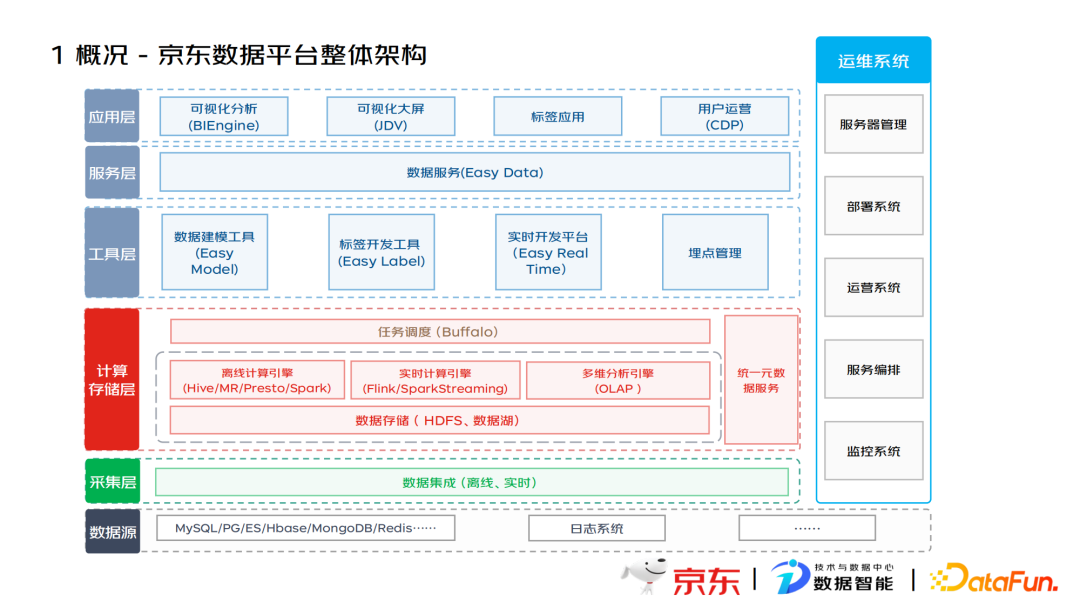
京东数据平台的整体架构主要由六部分组成,其中数据存储作为计算存储层的底层组件支撑着上游的计算引擎调度,以及更高层的工具层、服务层和应用层。在整个数据平台架构中,底层数据存储起到了基建的作用,是整个大数据平台的基础。
该数据存储系统的体量是数EB(1EB=1024PB),有数万个节点,三地多中心,每天的吞吐量是百PB级别。面对如此大的数据量,京东大数据平台采用了可视化管理,通过监控系统可快速方便地定位到集群问题,保证了集群的稳定性和服务的高可用。
02 跨域存储
1. 跨域存储——问题
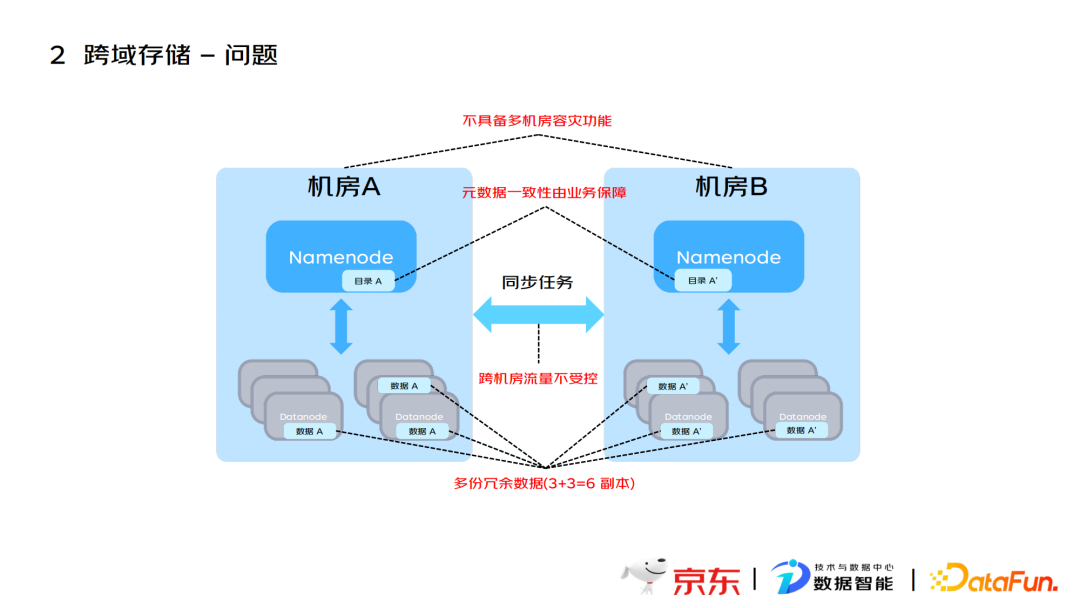
在跨域存储架构应用之前,跨机房数据的同步主要通过业务方在不同机房之间进行Distcp实现,这种方式便会存在一些隐患问题:
- 第一个问题:元数据一致性由业务方保证,数据迁移需要业务介入,成本高时间长。
- 第二个问题:跨机房的流量不受控,影响同步任务,需要借助外部调度系统和存储。
- 第三个问题:产生多份冗余数据,数据共享和同步成本高,比如在不同机房不同数据节点间载入了多份相同数据,导致冗余。
- 第四个问题:不具备多机房集群的容灾系统,未充分利用多机房优势。
2. 跨域存储——架构
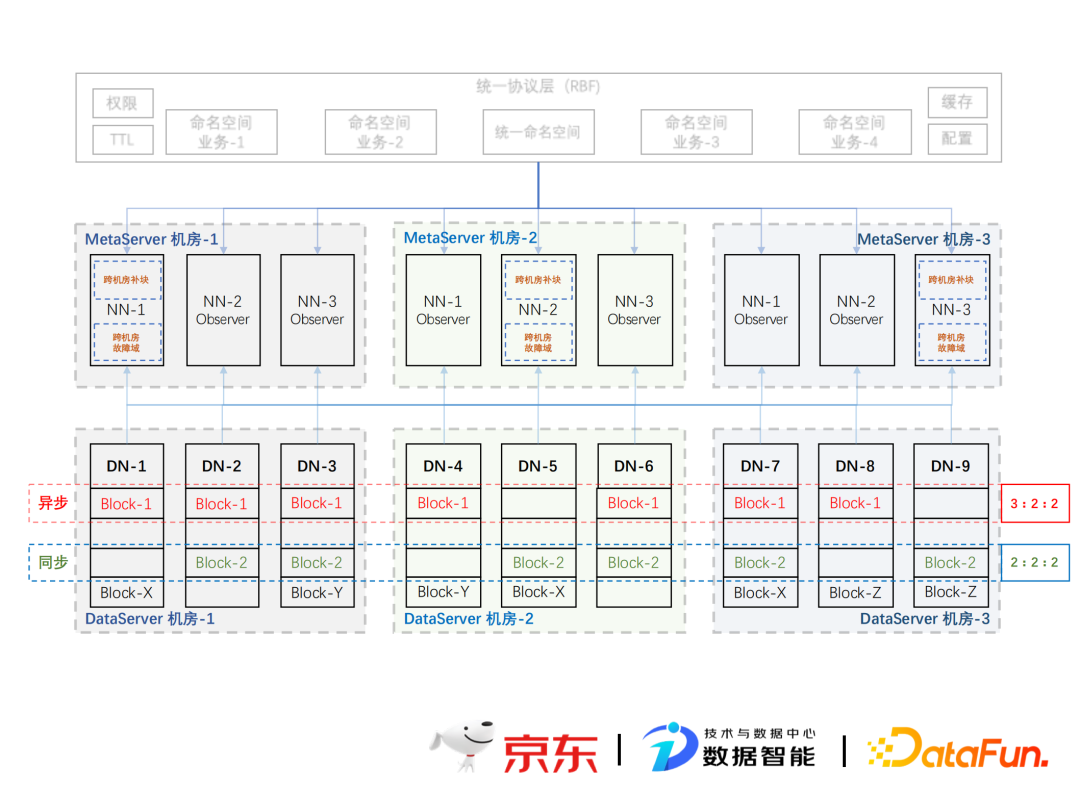
基于以上,京东大数据平台在底层存储模块设计了一个跨域数据同步功能来解决历史数据存储同步带来的问题。选择在底层解决该问题不仅可以把控跨域数据的一致性,还提供了业务无感知的跨域数据同步与分享功能,以减少业务方重复工作,使存储系统具备跨域迁移和跨域容灾的能力。
该京东跨域存储架构的主要思路是通过“全量存储+全网拓扑”,实现跨机房故障域,最终实现大数据关键数据异地容灾及跨机房存储能力。
这个项目的主要挑战有:
- 单集群规模庞大,达到数万个。
- 跨域补块与流动,存在性能瓶颈。
- 跨域心跳与块汇报,遇到限制。
该方案的主要优势有:
- 强一致性:全局文件一致性,数据自动同步避免数据参差和冗余。
- 复用原理:自主跨机房补块,跨域数据补块由后台自动进行。
- 易迁移:数据异动成本低,将数据与业务分开,降低成本,提高效率。
- 高可用:支持跨机房切换,提高机房容灾率,增加数据安全性。
3. 跨域存储——跨域数据流
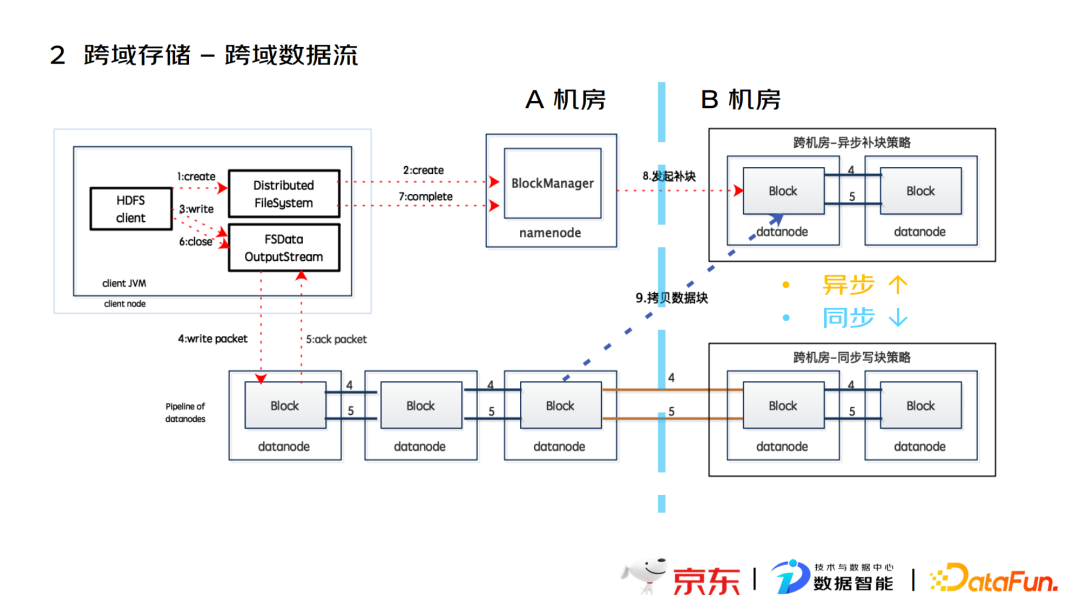
在实现跨域存储过程中,采用了两种数据流方式:
- 异步数据流
将数据先写到本地机房,再通过namenode(NN)自动进行跨域同步。该数据传输方式写入性能与现有未跨域场景一致,同步时延优于 distcp 方案。
- 同步数据流
建立pipeline数据管道,串联机房全部datanode(DN),一次将数据同步。该种传输方式针对数据一致性和可靠性要求高的业务。
4. 跨域存储——拓扑与机房感知
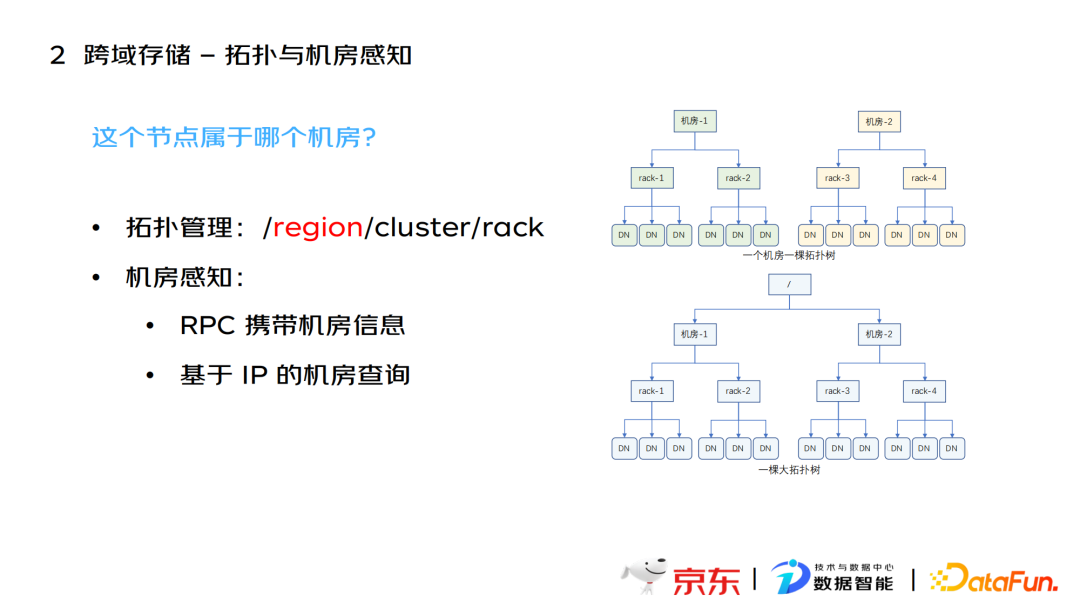
拓扑与机房感知是解决“节点定位”这一跨域存储核心问题的关键模块。基于该模块可控制数据块分布和控制客户端流量。该模块主要从两个方面解决问题:
- 拓扑管理
通过改造节点的拓扑方式,在拓扑管理中增加一个机房维度,同时选块逻辑要基于全网拓扑模块进行适配,以兼容多机房。
- 机房感知
针对跨域版本的客户端,可通过在RPC头部携带机房信息,以便识别和检索;针对不支持跨域版本的客户端,可通过京东网络服务团队提供的ip映射到机房的服务, 实现客户端对应机房的检索和查询。
5. 跨域存储——跨域标识

跨域标识模块是解决“数据跨机房存放”问题的关键设计,我们采用一个支持副本和EC的属性标签来描述数据的跨域属性。例如A:3,B:2,C:2,A,status,[period],[start,end],即表示在A机房有3个副本;B机房有2个副本;C机房有2个副本;A机房是跨域传输的主机房;[status]为标识存量数据内部流转的状态,包括“init、processing、done、invalid”四个状态;[period]用于跨域机房配置的时间戳,描述跨域数据的生命周期策略;[start,end]是另外一种数据共享生命周期配置方式,数据共享起止时间可通过绝对时间指定。
EC包含数据块和校验块两种类型, 相对于副本模式其跨域同步的支持更加复杂,需要支持在同机房内的数据重构和重构条件不具备时的跨域数据拷贝,以减少 EC 数据在跨域场景下的跨域同步流量。
加快整体跨域数据处理的速度,采用了三种方法:
- 将元数据固化在XATTR上
- 在内存上构建了Inode Proto
- 在每个数据块上,创建块属性标识
6. 跨域存储——跨域补块及流控
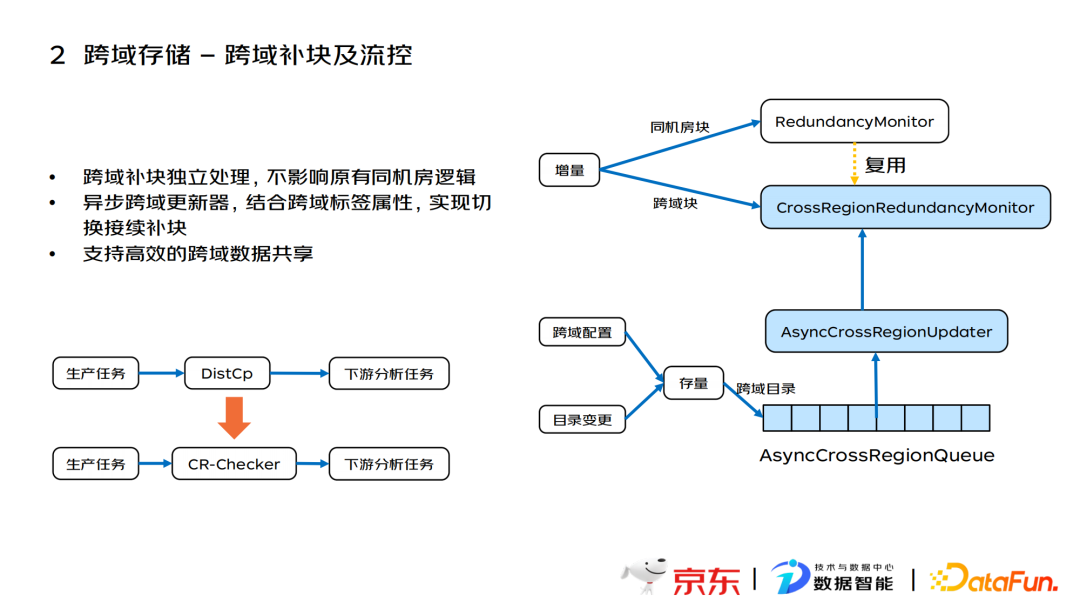
针对跨域补块和流控,采用了三种方法保证了性能:
- 在处理跨域补块时遵从的原理是跨域处理与原有流程隔离,保证新增的跨域处理流程不影响原先同机房的补块处理,在遇到机房网络中断等极端情况可以保障单机房元数据服务可用。
- 新增异步跨域更新器,结合跨域标签属性,实现HA切换接续补块,解决存量数据问题。
- 采用CR-Checker程序替代原有的DistCopy任务,可以将原先的跨集群同步任务平滑升级成跨域同步任务,最大限度减少跨域架构升级对原有存量任务的冲击。
跨域补块的逻辑如右图所示。对于增量的数据,分为两个模块,同机房块的增量数据通过原有的RedundancyMonitor进行补块,对于跨域块会放置到CrossRegionRedundancyMonitor模块进行补块。新增的更新器主要处理跨域配置和目录变更等跨域标签变更场景,经过跨域要求判断后加入到CrossRegionRedundancyMonitor模块进行补块处理。
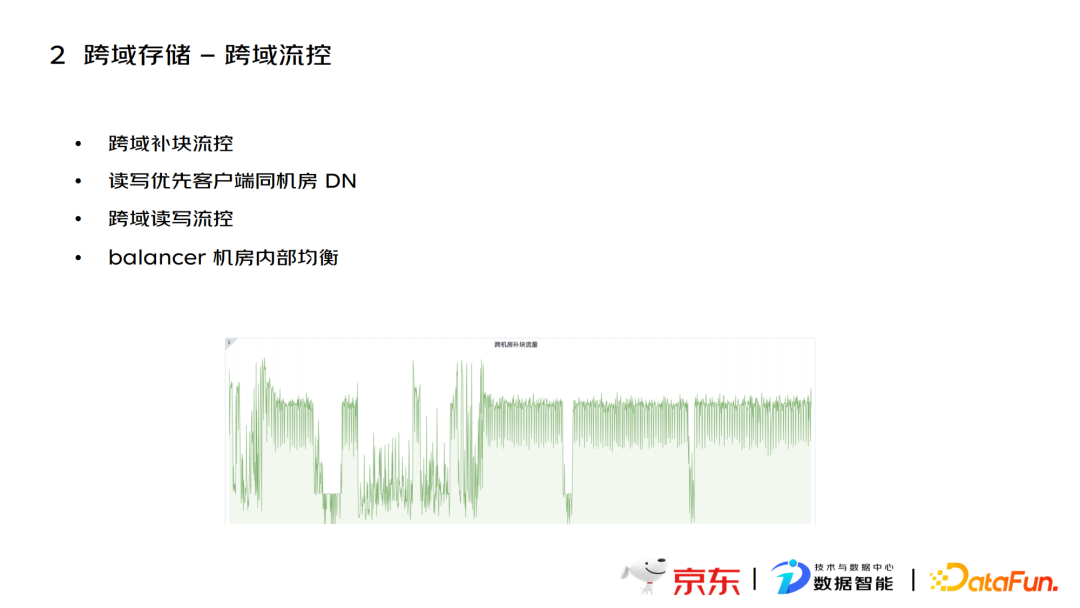
跨域流控分为四个部分:
- 跨域补块流控,通过配置带宽严格控制跨域带宽。
- 读写优先客户端同机房DN,基于前面介绍的机房感知功能,去匹配客户端和DN所属机房,确保只读取同机房的DN数据,避免产生跨域流量。
- 跨域读写流控,针对没有携带跨域标识的数据有跨域客户端访问时,对新版本用户端和老版本用户端有两种处理方法。对新版本客户端,会在NN做流量的统计和背压处理,保证读写不会影响核心专线的流量带宽;对于老版本客户端,会在DN处对流量进行统计和上报,如果超过限额后,会进行背压处理。
- Balancer机房内部均衡,在同机房节点上进行数据均衡。
03分层存储
1. 分层存储——问题

数据分层存储是为了解决原有框架所存在的问题:
- 冷热数据未区分对待。例如实时核心数据与旧数据未区分,导致无法做核心数据的加速处理。
- 不同硬件类型未区分对待。存储系统长期演进,集群内存在多种不同类型的存储机型,之前版本对不同存储机型未加区分处理,无法充分利用硬件特性。
- 数据治理需要协同用户处理,存在较大工作量,推进困难。
2. 分层存储
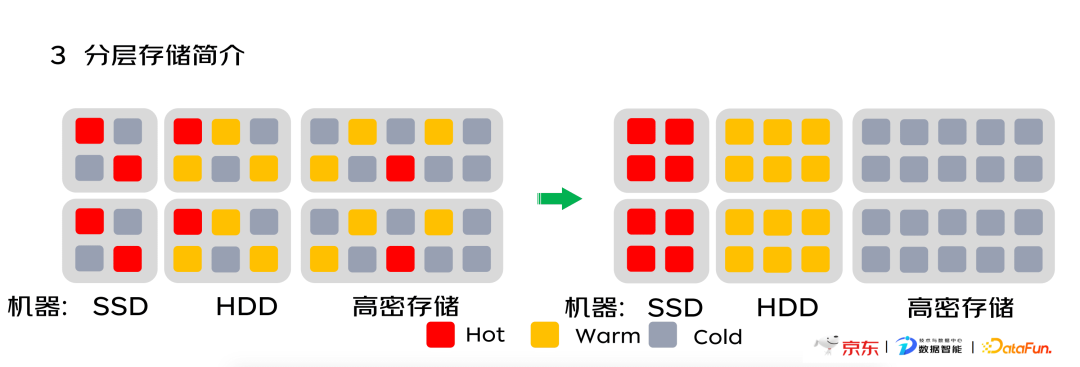
针对以上问题,我们需要在分层存储上完成以下功能要求:实现数据自动整理,将冷热数据通过打标签进行分级处理——分为Hot、Warm、Cold。将不同硬件机型也进行分级处理——分为SSD、HDD、高密存储。将实时热数据与性能较好的DN相匹配,存储在SSD的硬件上,而冷数据则存储在高密存储硬件上,实现资源合理搭配。
3. 分层存储——使用场景

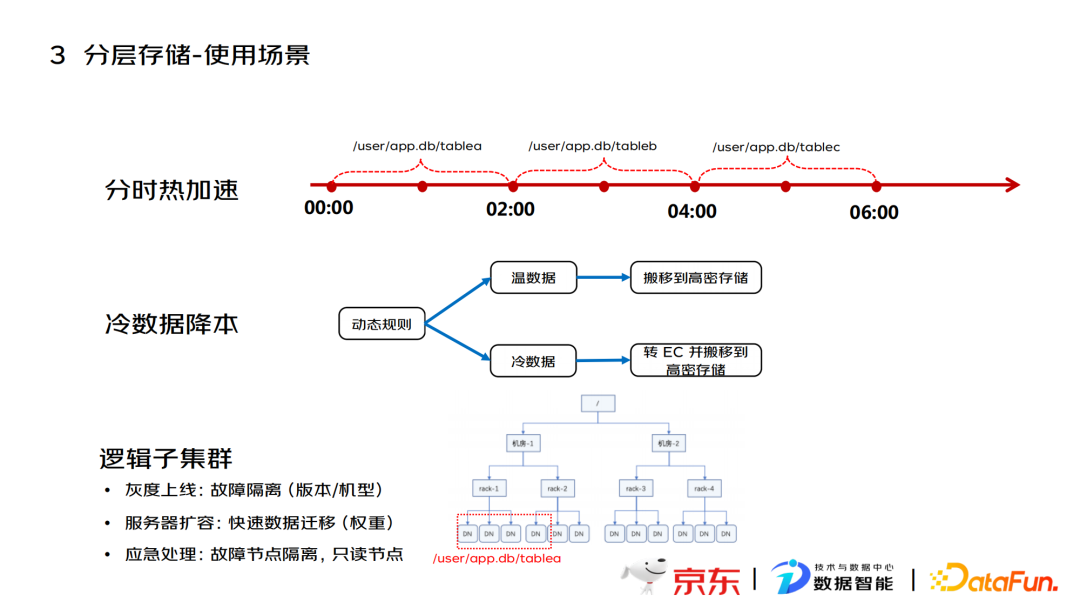
针对上述数据分层存储的实现方案,主要有以下三个应用场景:
- 存储加速
对热数据和核心数据提供加速手段,分时分层。例如在夜晚核心时间段,将其分为三个时间段,在对应时段将该时段的热数据搬移到高性能的存储机器上,这种处理方法可以在核心时段赋能更多的业务数据。
- 冷存归档
僵冷数据存储到高密存储机器上,优化单位存储成本。业务方通过配置集群维度的动态规则,完成冷热数据的自动分配,将冷数据存储到高密数据上,对于过度僵冷的数据会直接转化为EC(Erasure Coding),进一步降低存储成本。
- 逻辑子集群
支持按业务/目录维度划分逻辑子集群,实现数据隔离。针对新上线的机型,可采用该逻辑去摸索其性能;针对服务器扩容,可对新服务器增加写权重,提高存入数量。对于应急情况,可快速分离出故障机器,不影响整体的存量数据可靠性。
4. 分层存储——架构
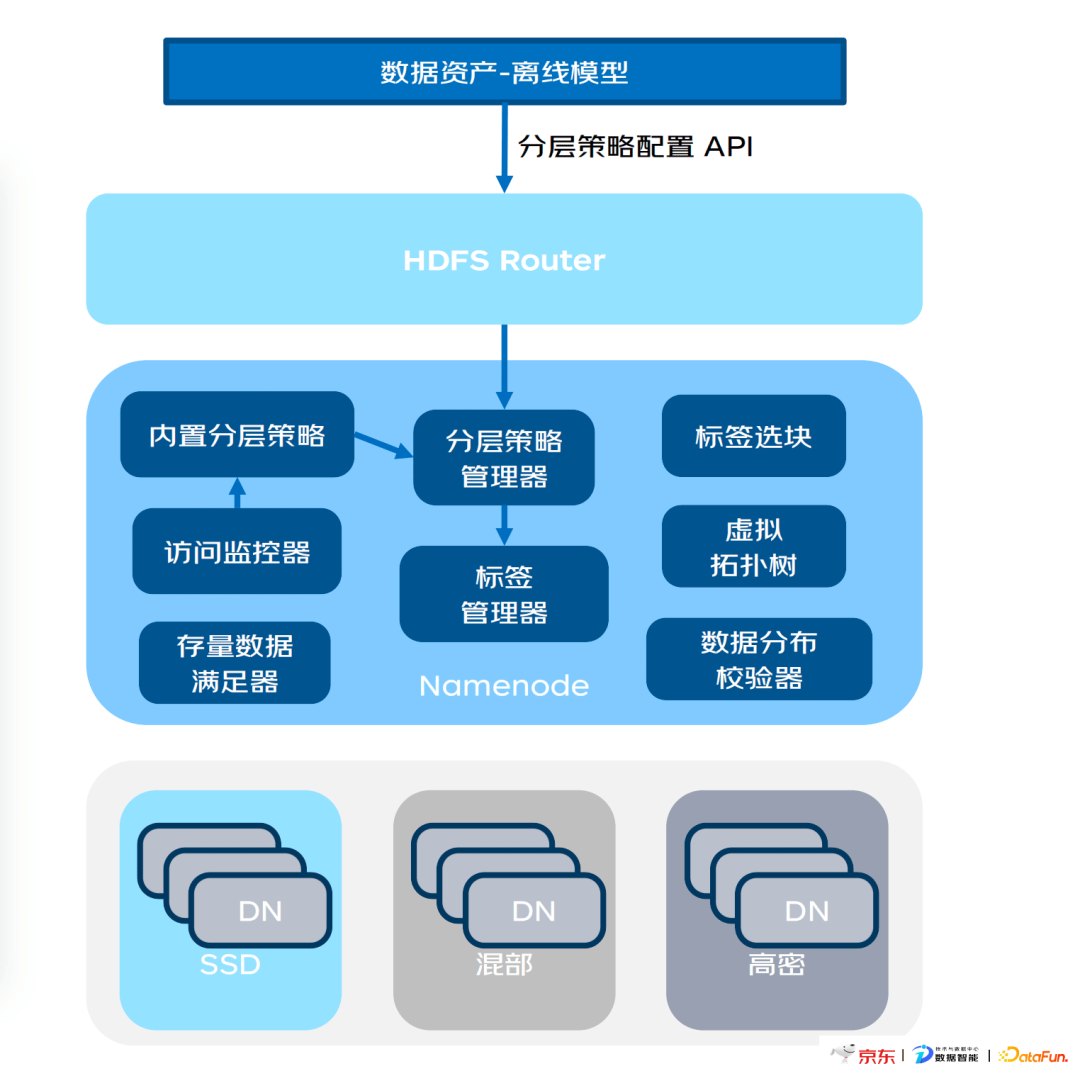
上面介绍了分层存储的逻辑和应用场景,下面将介绍分层存储的架构,整个框架主要是在NN内部实现的:
- 分层策略配置:提供外部API下发及内部配置。
- 分层配置API:提供分层策略下发接口,外部可通过离线数据分析及业务侧下发分层逻辑。
- 内置分层策略:可配置和动态刷新的分层策略,默认通过访问监控器统计数据进行LRU分层策略配置。
- 标签管理器:实现目录标签和节点标签管理,指导选块模块及分布校验器等模块进行数据迁移。
- 数据分布校验器:实现对新增数据的分布校验,指导数据按照标签进行分布。
- 存量数据满足器:对存量数据进行扫描验证,指导存量数据块迁移;实现数据生命周期管理功能。
5. 分层存储——核心设计
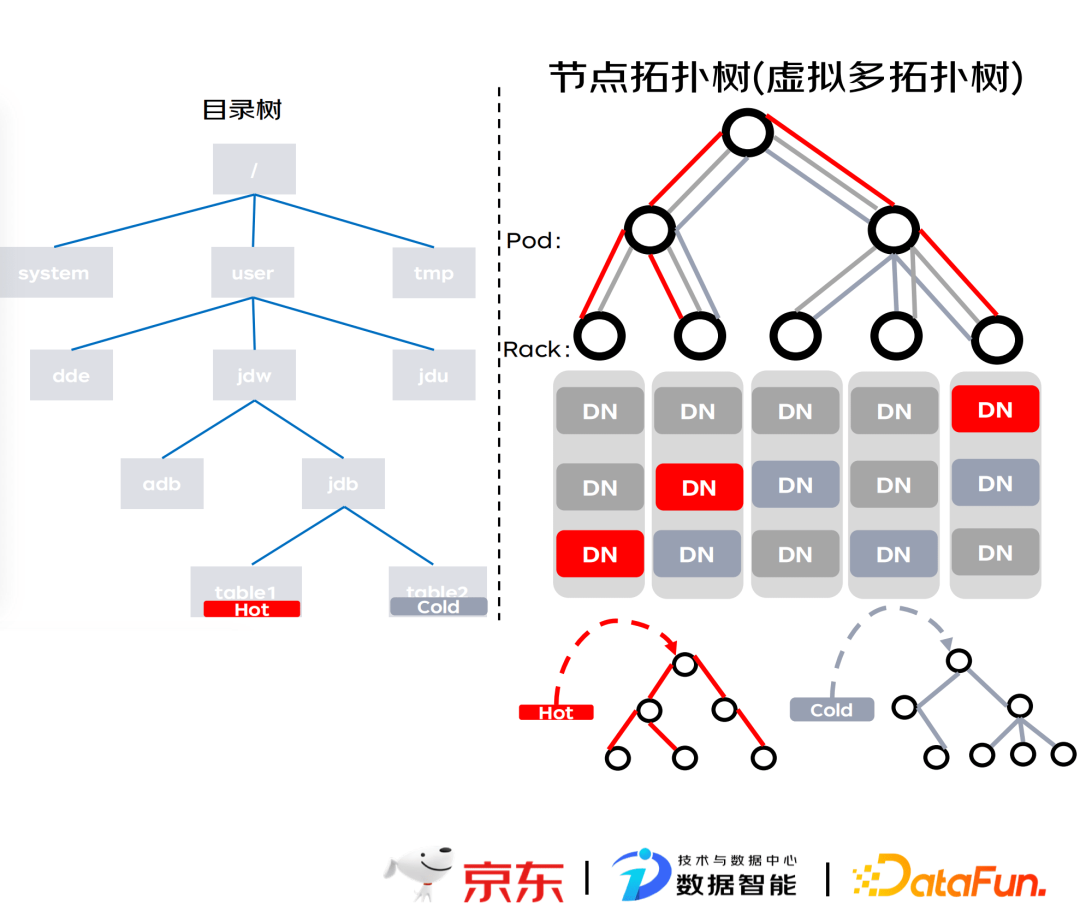
分层存储的核心设计,可以分为两个模块,一个是元数据上根据目录树进行标签管理,对数据进行冷热数据分配;另一块是节点拓扑树,采用虚拟多拓扑树在逻辑上将不同标签的节点进行区分,不同标签类型会有自己独立的拓扑树,实现更高效的选节点性能。虚拟拓扑树有两种更新方式,分别为根据节点权重进行异步更新和上下线数据进行同步更新。
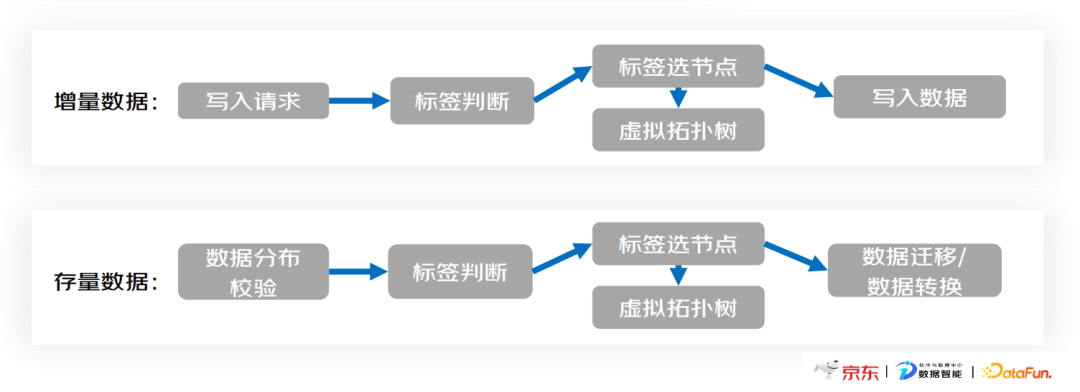
增量数据和存量数据在处理流程上有以下差异:
- 增量数据:对于写入请求,先判断标签,然后根据匹配对应节点,写入数据。
- 存量数据:后台数据分布校验会扫描数据的标签,基于虚拟拓扑树匹配对应的节点,然后完成数据迁移或转换。
04 问答
Q1:数据迁移到高密集群是通过什么方法,基于什么策略?
A1:我们是基于分层功能来实现数据迁移,整体的处理逻辑是基于动态规则的设定,将数据分为冷、温、热三种类型。针对温数据采用类 Balancer 的实现方式,将数据搬移到高密存储上;针对冷数据我们是在 HDFS 内部实现一套简单的调度系统,将扫描发现的冷数据发送给DN,由 DN实现数据的搬移和原地转EC。
Q2:京东有做HDFS计费的考虑吗,有哪些维度?
A2:计费功能也是我们下一步要重点投入的方向,整体的思路是通过计费功能指导业务方更合理高效的使用存储集群。目前我们将写操作和读操作进行分级,因为写操作对NN的压力比较大,因此写操作的计费权重会超过读操作计费权重,比例大概是 10 倍左右。在NN侧会将计费信息汇总到HDFS Router,做一个统一全集群的计费汇总统计。HDFS Router会定期将统计信息下发给NN,NN基于统计信息对用户访问进行分级处理,超过预设额度的业务方访问会被降级处理。
Q3:NN的压力会不会很大,对NN有何优化处理?
A3:在NameNode 内部新增模块时,会实时统计各模块对 NameNode 内部核心锁的占用时间,当新增模块的占锁时间超过设定阈值,程序会动态缩减模块的占锁时间,保证不影响NameNode对外的吞吐量。
今天的分享就到这里,谢谢大家。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK