

记一次生产事故的排查与优化——Java服务假死 - kbkb
source link: https://www.cnblogs.com/kbkb/p/16291393.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

记一次生产事故的排查与优化——Java服务假死
一、现象
在服务器上通过curl命令调用一个Java服务的查询接口,半天没有任何响应。关于该服务的基本功能如下:
1、该服务是一个后台刷新指示器的服务,即该服务会将用户需要的指示器数据提前计算好,放入redis中,当用户请求指示器数据时便从redis中获取;
2、指示器涉及到的模型数据更新时会发送消息到kafka,该服务监听kafka消息,收到消息后触发指示器刷新任务;
3、对于一些特殊的指示器,其涉及的项目和模型较多,且数据量比较大,无法通过kafka消息来触发刷新,否则一直处于刷新过程中,便每隔10分钟定时进行指示器的刷新,以尽量保证的数据的及时性;
4、该服务不对外提供接口,只预留一些指示器刷新的监控接口,供内部开发人员使用;
5、相同代码还部署了另外一个服务对外开放,用户请求指示器数据时就向其请求,如果redis缓存中有便直接返回,没有的话那个服务便实时计算。
二、排查
1、打印堆栈
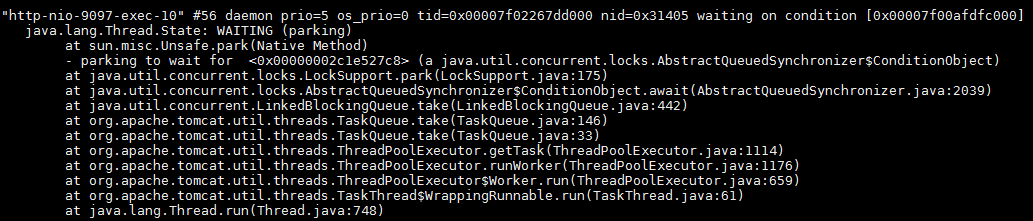
看到上述的现象,第一反应就是服务挂了,于是便通过jps命令查看该服务的进程号,发现服务还在。那么会不会是tomcat的线程被占满,没有线程去响应请求,但是按理说是不会的,因为该服务并没有对外提供接口。抱着好奇心还是通过jstack pid命令打印出堆栈来查看,如下图所示。发现当前只有10个tomcat的线程,并且都处于空闲状态,那么就不可能因为线程被占满而导致curl接口没有响应。
2、查看socket连接
就在一筹莫展之时,同事告诉我zabbix监控那边会每隔一分钟调用该服务的查询接口来获取当前的刷新任务数,从而展示在zabbix上进行实时监控。这时赶紧调用netstat -anp|grep 9097命令查看一下当前是否有请求,发现zabbix那边的请求全部卡死了。

这些卡死的请求全部都在ESTABLISHED状态,基本上把tomcat的socket连接全部占满了,这下终于明白为啥调用查询接口,服务没有响应了,但是为什么这些查询接口会卡死呢?
3、查看JVM基本信息
想要弄明白这个问题,还是要查看一下JVM内部的信息,是否内存溢出或者CPU占满,这里采用arthas插件,下载arthas后就可以通过java -jar arthas-boot.jar直接启动。
该服务是第一个,选择1按enter键进入
通过dashboard命令查看服务运行的基本信息
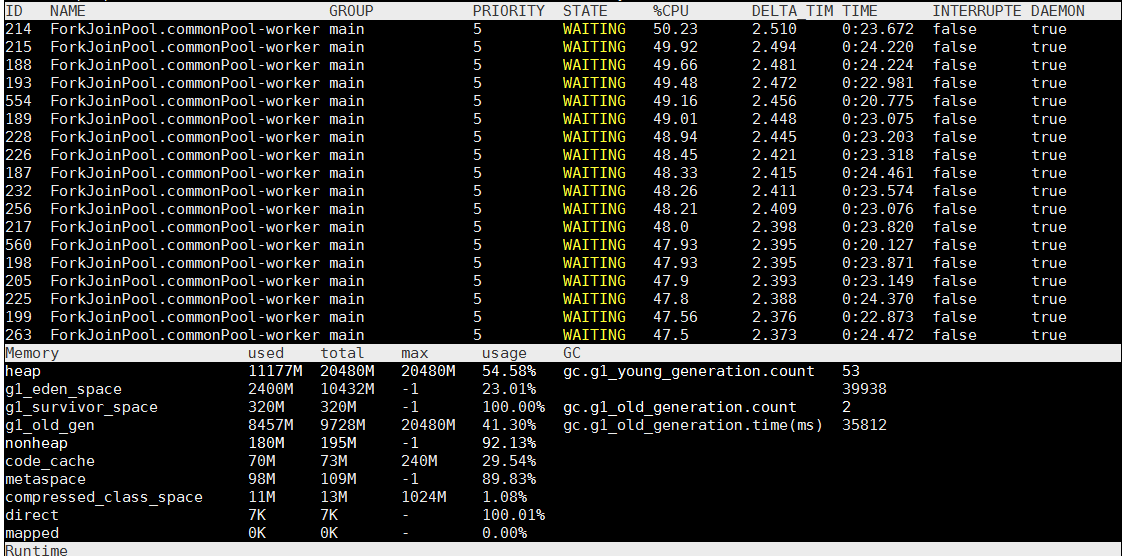
从上图可以看出,CPU占用率不是很高,但是内存占用率比较高,特别是老年代,该服务总共分配了20G的内存,新生代10G,老年代10G 。服务启动不久后就进行了Full GC,很快老年代就被占满,这说明有很多大对象在内存中,并且没有被Minor GC回收掉,进入了老年代。
4、查看GC日志
为了验证我的猜想,通过jstat -gcutil 221446 1s命令每隔1s将GC信息实时打印出来,如下图所示。
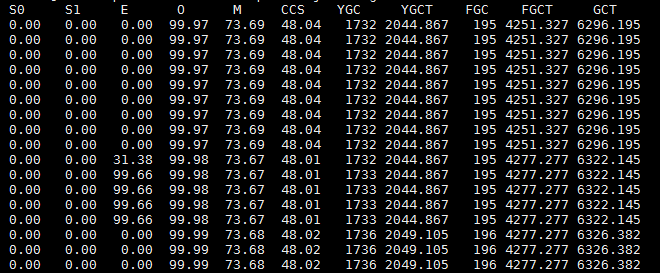
E表示Eden区的内存占用率,O表示老年代的内存占用率,YGC表示年轻代GC的次数,YGCT表示年轻代GC的时间总和,FGC表示Full GC的次数,FGCT表示Ful GC的时间总和。从上图可以看出,在195次Full GC后,Eden区仅仅过了4秒内存就基本上满了,这时又发生了Full GC,即第196次Full GC。
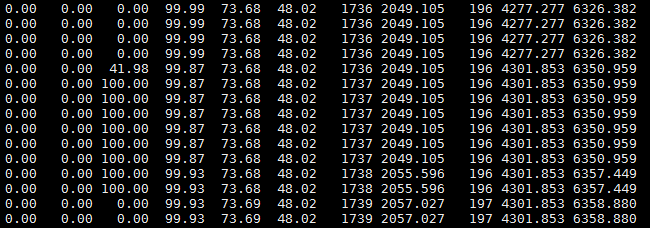
从上图可以看出,用两次的FGCT相减,即4301减去4277,可以知道196次Full GC花了大约24秒,这期间服务基本上处于停滞的状态,而且从Full GC后的老年代内存占用率可以看出,并没有回收老年代多少内存,占用率依旧很高。这意味着几秒后又将进行Full GC操作,反复循环。由此看出,该服务基本上一直处于卡死的状态,内存将要溢出。那么,到底是什么对象长期占据着内存呢?
5、分析dump文件
这时想起,该服务为了提高相似指示器的计算效率,使用了google的缓存guava。每次计算完指示器后会将该指示器涉及到的模型数据存储在缓存中,下次计算相同模型的指示器时可以直接从内存中获取,而不需要访问数据库,因为数据量比较大,所以可以显著提升查询指示器的效率。guava缓存的失效时间是30分钟,也就是说30分钟内的Full GC是无法回收多少内存的。为了证明我的猜想,就在服务启动参数上增加了-XX:+HeapDumpOnOutOfMemoryError。这样在服务内存溢出时会自动生成dump文件,将dump文件导出,通过VisualVM就可以分析出究竟是什么占据着内存。
由于我的电脑内存有限,无法打开20G的dump文件,就将服务内存调整为3G,guava缓存分配2G,运行一段时间就生成了dump文件,通过VisualVm打开,如下图所示。

从上图可以看出,byte数组占据了46%的内存空间,点击byte[]实例可以看到具体是哪些数据占据了内存,如下图所示。
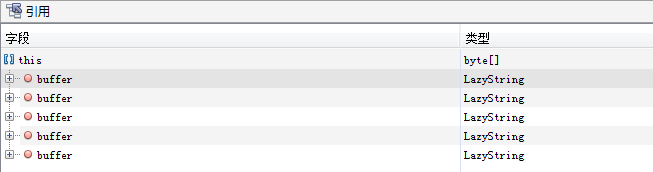
可以看到byte数组有大量的LazyString类型,即com.mysql.cj.util.LazyString,点击详情查看。
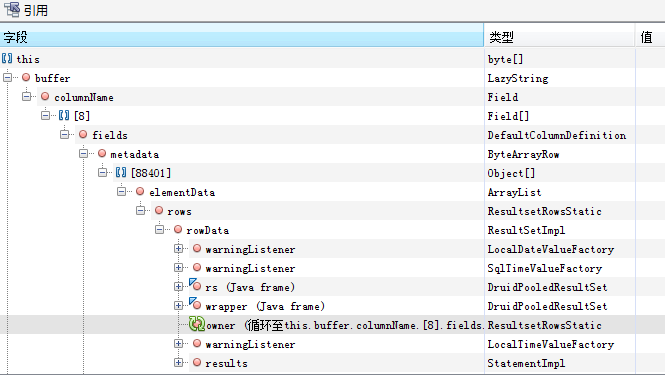
发现好多ResultSet没有被释放,这就是查询指示器模型数据的返回结果。由于这些模型数据都被缓存对象引用着,而且缓存的有效期是30分钟,所以新生代GC无法回收,直到进入老年代,如果没有超过30分钟缓存有效期Full GC也不会回收,所以内存被占满。由于这些指示器计算都是并发的,30个线程同步查询数据会导致内存中有大量的数据缓存对象,从而导致内存溢出。
三、优化
针对以上分析出的原因,有以下两点优化建议:
1、不再使用guava缓存,每次都实时查询指示器的数据。因为该服务是后台刷新服务,将计算的好指示器结果存入redis缓存,不需要直接给用户提供服务。因此,该服务不需要计算很快,只需要正确即可,取消guava缓存后新生代GC会很快回收掉不再使用的大对象,使得这些对象不会进入老年代引发Full GC,即使进入老年代也能通过Full GC回收掉,不至于内存溢出。
2、降低线程的并发数。虽然不使用缓存会提高内存的使用率,但是如果并发数过高,并且指示器数据量过大,那么在某一瞬间内存也会被占满,且不会被Minor GC回收掉,从而进入老年代,直到触发Full GC。
只有做到以上两点,并且适当调大服务内存,这样才会尽量让大量的垃圾数据在年轻代就GC掉,而不是进入到老年代引发Full GC。
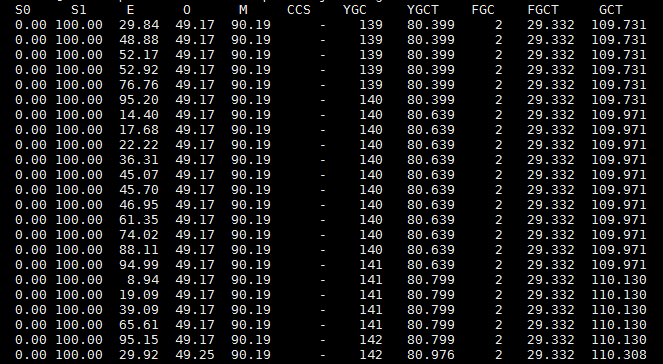
上图是优化后的GC日志,可以看出,新生代GC后回收了很多垃圾,并且很少一分部分对象会进入到老年代,这样会减少Full GC的次数,从而解决系统卡死的问题。
四、总结
通过本次事故的排查,对于服务假死这样的现象,一般的排查过程为:
1、查看服务进程是否存在;
2、根据进程号查看CPU占用率和内存占用率,这里可以使用arthas这样第三方的插件,也可以使用jdk自带的工具,如jstack,jstat,jmap等;
3、查看GC日志;
4、如果有内存溢出情况,可以查看dump文件找出溢出点。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK