

论文 Efficient Dense Frontier Detection for 2D Graph
source link: https://charon-cheung.github.io/2022/05/16/%E8%87%AA%E4%B8%BB%E6%8E%A2%E7%B4%A2/cartographer_frontier_detection/%E8%AE%BA%E6%96%87%20Efficient%20Dense%20Frontier%20Detection%20for%202D%20Graph/#%E5%AE%9E%E9%AA%8C%E7%BB%93%E6%9E%9C
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文 Efficient Dense Frontier Detection for 2D Graph
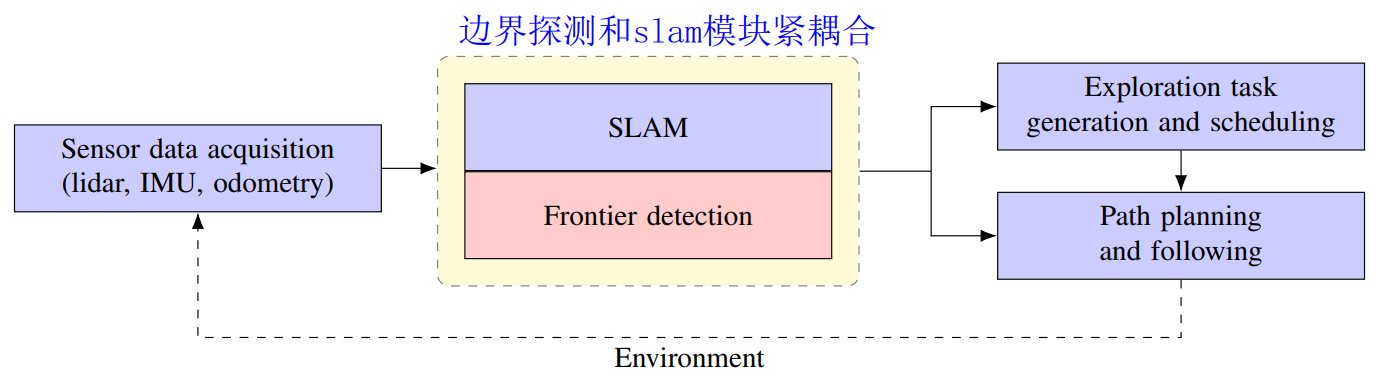
从Yamauchi在1997年的论文开始,后来有了复杂的探索策略用于多个机器人的探索。
简单的frontier检测是在每次地图更新后,对整个地图进行边缘检测(edge detection)。但是这种方法对大规模地图不实用,而且构成的计算量也太大。
2014年,Keida 和 Kaminka提出两种方法:Wavefront Frontier Detector(WFD) 和 the Fast Frontier Detector (FFD). 都有一些缺点。FFD提出了活跃区域(active area)的概念,在地图上围绕机器人位置的一个边界框,限定了更新地图的最后scan。frontier的update step 由于限定在活跃区域而得到了加快。本论文提出的算法有类似的概念:活跃子图(active submaps)
loop closure对frontier检测的影响:为了返回正确的结果,frontier检测必须能处理loop closure引起的地图变化。这些地图变化不是只限于活跃区域,而是遍布整个地图。高效的frontier检测算法应该避免每次遍历时都要处理整个地图,而把算法限定在活跃区域又导致对loop closure不鲁棒。
Keidar and Kaminka 提出了针对Gmapping算法而实现的WFD-INC算法,本论文的算法则针对cartographer。Quin and Alempijevic提出两种frontier检测算法,一个就是限定在活跃区域的,另一个认为每个地图栅格的熵(entropy)只会随时间而减小。对于考虑了loop closure的完整地图来说,这种假设不正确,在loop closure时观察的区域会移动 and leave unexplored space in their wake. 但是对于每个子图来说,熵降低的假设基本正确,本论文正是利用了这一点。
Umari 提出了RRT算法进行稀疏的frontier检测,方式是在地图的空闲区域创建树,当算法扩展随机树穿越了frontier时,就会检测到单独的frontier点。但是算法在每次遍历时不要求重组全局地图,而且算法对loop closure不鲁棒,因为创建RRT树不是根据pose graph优化的结果,所以不能和cartographer搭配。RRT的frontier检测算法在窄通道和大地图的情况下出现多种问题。
子图栅格的熵可认为是单调递减: 一旦进入observed状态,活跃子图(active submap)的栅格不会成为unobserved
frontier detection
Ssik,jSk,jsi 是子图 si 中栅格(k,l)的占据概率
Occupancy classification: 栅格的占据概率不是在frontier detection中直接使用的。
局部边界点(Local frontier point): 子图中未观测栅格的中心,这个栅格近邻一个空闲栅格。子图的局部边界(local frontier)是一系列的局部边界点。
stabbing query: 对于一个给定的全局点,在给定的子图里寻找相应的栅格。具体说,对于子图 si 和全局点 pgpg,寻找子图的栅格索引(k, l),这个栅格在子图si对应的local坐标系的坐标是最接近 (Tsig)−1 pg(Tgsi)−1pg 的栅格。
stabbing query test的意思是检查栅格(k ,l)是未观测的栅格,如果是,测试通过了。全局边界点(global frontier point): 未观测的全局地图栅格,它近邻一个空闲的全局地图栅格。valid全局边界点必须通过所有子图的stabbing query test。全局边界是给定时间的一系列valid全局边界点。
perimeter: 全局或局部边界包含的边界点的个数。
处理子图的更新
算法1的6-10行,在子图层面使用普通的边界检测方法,而不是其他复杂的方法。原因有两个,(一) 由于子图大小受限制(参数 num_scans)和活跃子图只有2个,局部边界检测的时间复杂度不收全局地图或数据集规模的影响。 (二) 算法的 classification (line 6) and edge detection (lines 7– 9) 可以向量化,这样在CPU上可以有好的表现。论文的实现基于Eigen,使用 Eigen’s matrix block algebra and Hadamard products to vectorize thresholding, classification and Boolean logic for edge detection.
算法13行的stabbing query test,如果未通过,相应的子图会记录为 hint (Algorithm 2, line 5),这样在未来的再次测试(算法3)可以运行快一些。
已经完成的子图的栅格不再变化,因此对已完成的子图,没必要再检测局部边界
处理子图更新的算法部分,假设从上次子图更新后没有发生后端优化,这样所有已完成子图的现有全局边界valid
活跃子图的占据概率的熵一直下降,所以只有之前未观测的栅格变为已观测,没有反过来的情况。所以,子图的更新可能会遮盖住之前intersecting submaps的全局边界。在算法1的11-13行进行测试是否遮盖,方式是对全局边界点和活跃子图进行stabbing query test
已完成子图的bounding box保存在树数据结构里,可以快速query和给定bounding box相交的子图。论文使用Boost实现R树保存已完成子图的global axis-aligned bounding boxes。并不是所有子图的更新都要处理,不是最后子图的更新事件可以跳过。探索系统不要求针对每个scan都实时更新边界,只有每个子图完成时才使用探索算法。
处理后端优化:子图的位姿改变,算法3验证子图的全局bounding box和整个全局边界。每个子图的局部边界已经计算出了,所以只要重新把局部边界点转换到全局坐标系,而且需要测试新的全局边界点。
鲁棒性和完整性
- 鲁棒性: 假设算法返回的全局边界点valid,两种情况:全局边界点是已观测的全局地图栅格;全局边界点邻近栅格不是空闲全局栅格。
第1种不可能,因为这样的全局边界点会通不过stabbing query。第2种是可能的但可能性很小。如果有多个子图的邻近栅格是占用的,合并的过程会导致邻近的全局地图栅格标记为占用而不是空闲,而全局边界点只邻近占用的全局地图栅格。之所以说可能性很小,是因为未观测栅格未被已观测栅格覆盖(这又会导致stabbing test失败)的可能性小的可以忽略。为了避免这种情况,stabbing query测式可以增加检查子图的邻近栅格的功能,而不是只检查单个栅格。这样不会增加时间复杂度。
算法复杂度
- 处理子图的更新
算法1的第5行,在R树梨查找和更新的子图si相交的子图,时间复杂度是O(log|S| + |S∩siS∩si|)。 S是所有子图,S∩siS∩si是与子图si相交的子图。这也包括了向R树插入已经完成子图的bounding box的时间复杂度。
算法6-10行,栅格的分类和原始查找局部边界点的算法复杂度是 O(A(si))O(A(si)), A(si)A(si)是子图si的区域,也就是栅格个数。
算法2的第3行,对已更新子图的每个局部边界点,与相交子图进行stabbing query测试的算法复杂度为 O(S∩si)O(S∩si),那么总的就是 O(P(LFsi) S∩si)O(P(LFsi)S∩si)
算法1的第11-15行,验证相交子图的全局边界,与他们的周长是线性关系,算法复杂度 O(P(⋃sj∈S∩si GFsj))O(P(⋃sj∈S∩siGFsj))
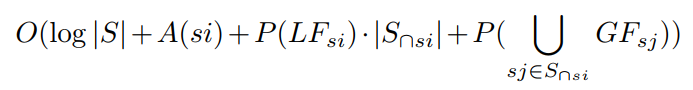
- 处理后端优化的事件
算法3的第一步是重建R树(1-3行),算法复杂度O(|S| log|S|)。这个复杂度包括对每个子图查找相交的子图(第6行)。然后,每个局部边界点被转换到全局坐标系,再对相交的子图执行stabbign query测试。(算法2的1-3行) 坏的情况会对每个局部边界点对其他所有子图进行测试。 所以时间复杂度是O(|S| P(LF))。 如果未通过测试的点数是 P(FF) = P(LF) - P(GF), 时间复杂度为 O(|S| P(GF) + P(FF) )*
处理后端优化的时间复杂度取决于子图数量和局部、全局的边界长,因此为
O(|S| · (log|S| + P(GF) ) + P(FF))
算法在单线程里异步执行, 如果不是最后一个子图更新,会 adaptively 跳过以保证处理速度。
测试平台是Intel i7 6800K @ 3600 MHz。没有进行 frontier grouping,返回的边界范围是 unstructured set of points.
我们实现的优化:在局部边界检测中,对一小部分临时关闭的子图执行stabbing query测试(算法1,第8行,比如针对4个之前的子图)。 This has the result of permanently “baking in” a negative test result against these submaps, since these
points are permanently erased from the local frontiers
算法 3 中,从局部边界中抛弃点的好处是加速全局边界的计算,因为这样会减少重新转换和重新测试的局部边界点。而且,连续子图之间的定位漂移很小,后端优化不会在连续的子图之前产生很大的相对错位。使用未优化的位姿实际上对处理连续的子图更好,因为可以防止检测到错误边界,错误边界是在后端优化时的连续子图之间的微小错位导致的。
算法的具体两个优化:
拥有非常不确定的“空闲”概率( Ssik,l∈[0.5−ϵ,0.5]Sk,lsi∈[0.5−ϵ,0.5] )被当做“未观测”栅格. 这是为了防止因错误的雷达远距离数据而检测到错误边界,这会导致一束错误的“空闲”栅格插入子图。
对局部边界的简易平滑,通过调整局部边界点的定义:未观测栅格的邻近栅格中,至少有2个空闲栅格和至少2个未观测栅格。 算法其他部分未变,这样可以获得平滑(smoothed)局部边界点,进而获得平滑的全局边界点。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK