

【译】深度解析 Roam 数据结构 —— 为什么 Roam 远不只是一个笔记应用
source link: https://blog.jimmylv.info/2021-03-08-Roam-Data-Structure-Query-zh-translation/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【译】深度解析 Roam 数据结构 —— 为什么 Roam 远不只是一个笔记应用
随着 Roam Research 的大热,双向链接和基于 Block 的笔记软件层出不穷,而他们(葫芦笔记、logseq、Athens)无一例外都采用了 Clojure 技术栈的 Datomic/datascript Datalog 数据库,这不免让我感到好奇想要深入探索一番。本文就将硬核解析 Roam 背后原理,发掘 Roam 基于 Block 的深层技术优势,帮助你迎接 Roam API 时代的到来!
原文地址:Deep Dive Into Roam’s Data Structure - Why Roam is Much More Than a Note Taking App —— Zsolt Viczián
你想不想知道以下问题的答案?
- 你的 Graph 笔记库中最长的段落是那一段?
- 上周你编辑或者创建了哪些页面?
- 你的笔记库中总共有多少段文字?
- 在某个给定的命名空间下你总共有哪些页面?(例如:
meetings/)
(译注:问题 1 可通过 Roam Portal Chrome 插件 查看,问题 2 可查看 #Roam42 DB Stats,但本文将帮助你深入理解插件背后的原理。)
Roam Research 是一个全功能型数据库,相信你已经用上了 ` {{query:}} ` 的查询方法,但其实远不止如此,你还可以问它更多的问题。这篇文章会让你对 Roam 的底层数据结构基础有一个很好的理解。
上周我一直在深入研究 Roam 的数据结构,玩得非常开心,也学到了很多。这篇总结写给我自己,也分享给你,我尝试通过写作来加深我对 Roam 的理解程度。如果你发现这太过于技术向了,很抱歉,我会尽力用一种容易理解的方式来传达信息,从最基本的概念慢慢过渡到更为复杂的概念。
在我的探索过程中,我还构建了一组用于查询的 SmartBlocks,和相应的几个查询示例,你可以在这里找到它。虽然你不一定想要了解具体细节,但也会发现这些例子非常有趣。
随着我的深入,我对 Roam Research 的赞叹就更进一步,我也愈发相信 Roam 一定能够占领市场。在不久的将来,Roam 将以全文的形式保存你我所读到的一切:笔记、书籍和文章摘要等等,都将能够方便地追溯其原始出处,只需在一个系统中点击即可访问。“Roam” 未来可期!
我的文章也参考了很多极具价值的文章和参考资料。我特别想分享以下的几篇文章,如果你读了我的概述发现还想了解更多,那我强烈建议你继续探索:
而这篇文章,将会提到以上文章都没有涵盖的两个点:
- 对 Roam Research 数据结构的详细讨论,包括非常基础和复杂的介绍
- 一套基于 #42SmartBlocks 可以在 Roam 中执行高阶查询。如果你对基础部分不感兴趣,想要直接看 SmartBlock 部分的话,点击跳转。
让我们开始吧!期望你像我一样享受这次旅程!
Roam 基于 Datomic 数据库构建。简而言之,一个 Datom 是一个独立的 fact,它是一个带值的属性,包括四个元素:
- Entity ID 实体 ID
- Attribute 属性
- Value 值
- Transaction ID 交易 ID
你可以把 Roam 想象成一组扁平化的 Datoms 集合,看起来就像这样:
[<e-id> <attribute> <value> <tx-id> ]
...
[4 :block/children 5 536870917]
[4 :block/children 9 536870939]
[4 :block/uid "01-19-2021" 536870916]
[4 :node/title "January 19th, 2021" 536870916]
[5 :block/order 0 536870917]
[5 :block/page 4 536870918]
[5 :block/parents 4 536870918]
[5 :block/refs 6 536870920]
[5 :block/string "check Projects" 536870919]
[5 :block/uid "r61dfi2ZH" 536870917]
共享相同事务 id 的 Datoms 就是在同一个事务中添加的。其中,这种基于事务的方法使 Roam 能够将内容同步到不同的设备,并管理非常复杂的撤销操作。
具有相同 entity-id 的 Datoms 就是同一个 Block 的 facts。
如果你想基于块引用来查询一个 Block 的 entity-id,你就可以写:
[:find ?e-id
:where
[?e-id :block/uid "r61dfi2ZH"]]
从上面的数据可以看出,这个查询将返回值 5。
Attributes 属性
Roam 使用 :block/ 属性来存储关于段落(paragraphs)和页面(pages)的 facts。页面和段落之间有一些细微的差别,我在一分钟内就会解释。但是,你必须理解的基本概念是,页面只是一种特殊类型的块(block)。大多数情况下,Roam 将页面(page)和段落(paragraph)一视同仁。两者都是 Blocks。
区块 Block 的两个 ID
- Hidden ID 隐藏 ID:
这个 entity-id 才是真正的 block-id,即使它在 Roam 用户界面是看不到的。这是用于将数据库中的信息绑定在一起的 ID。Entity ID 标识了有关 Block 的 facts,描述了父子层级关系和对 Block 的引用。
- Public ID 公共 ID:
公共 ID 是段落(paragraph)的块引用,例如 GGv3cyL6Y,或者是页面(pages) 的 Page Title(页面标题)。请注意,页面(pages)还有一个 UID,长度也为九个字符串 —— 非常类似于块引用。例如,你可以使用它们来构造指向 Graph 中特定页面的 URLs。
(译者注:比如现在这篇文章在 Roam Research URL 中的 /page/mdz6JIWDD https://roamresearch.com/#/app/Note-Tasking/page/mdz6JIWDD)
所有区块的公共属性
每个块都有以下属性:
:block/uid公共 ID,即 9 个字符长的块引用:create/email创建块的作者 Email 地址:create/time以毫秒为单位的时间,纪元计时(1970 年 1 月 1 日 UTC/GMT 午夜):edit/email编辑该块的作者 Email 地址:edit/time最新一次块的编辑时间
[10 :block/uid "p6qzzKa-u" 536870940]
[10 :create/email "[email protected]" 536870940]
[10 :create/time 1611058803997 536870940]
[10 :edit/email "[email protected]" 536870940]
[10 :edit/time 1611058996600 536870949]
森林中的树木(Trees in the forest)
Roam 数据库就像一片森林。每一页都是一棵树。树的根是页面(page),树的枝干是更高层次的段落(paragraphs);树的叶子(block)就是嵌套在页面(page)最深层次的段落(paragraphs)。
Page
* Branch
* Branch
* Leaf
* Leaf
* Leaf
* Branch
* Branch
* Leaf
* Branch
* Leaf
...对于每个段落(paragraph),Roam 总是创建两个指针。 子级 Block 使用:block/parents 引用其父级的 entity-id,父级则使用: :block/children 引用其子级的 entity-id。
[4 :block/children 5 536870917]
[5 :block/parents 4 536870918]
父级会在 :block/children 属性中保留其子级的列表。这个列表只会包含其直系后代的 entity-id,而不包括隔代的孙辈。一个 Page 只会将 Page 顶层的段落(paragraphs)作为子段落列出来,而不会列出嵌套的段落(paragraphs)。类似地,段落将只列出嵌套在它下面的块(block),而不是嵌套在嵌套块下面的块。嵌套中最低层级的 Block 块(叶子)则没有 :block/children 属性。
子级同样会在 :block/parents 属性中保留其父级的列表。与 :block/children 相反的是,父级列表包括所有祖先的 entity-id,即祖父母、曾祖父母等。嵌套的段落(paragraphs)将包含对父段落(paragraphs)和页面(page)的引用。页面的顶层段落(paragraphs)在 :block/parents 属性中具有页面(page)的 entity-id,而嵌套在另一段落下的段落(paragraphs)将具有更高层级段落的 entity-id 和当前页面(page)的 entity-id。
页面 Page 独有属性
所有的页面都有标题属性,而没有任何段落会有标题。
如果要查找数据库中的所有页面,则需要查询 :node/title,因为此属性只包含页面的值。通过执行以下查询,你将得到一个包含两列的表格:?p 参数下每个页面的 entity-id 和 ?title 参数下每个页面的标题。
[:find ?p ?title
:where [?p :node/title ?title]]
如果你还希望查到每个页面的九个字符的 UID,例如,要构造指向该页面的链接,则需要通过 :block/uid 属性来查找 ?p entity-id。下面是 query 查询语句的样子。注意 ?p 是如何出现在 where 子句的两种模式中的。这告诉查询引擎查找同一实体的 title 和 uid。
[:find ?p ?title ?uid
:where [?p :node/title ?title]
[?p :block/uid ?uid]]
段落 Paragraph 的独有属性
每个段落都有以下属性:
:block/page页面上的每个段落,不管它们的嵌套级别如何,都会引用他们的页面entity-id:block/order这是页面中块的顺序,或者是段落下嵌套的级别。你需要对这个值进行排序,以便按照适当的顺序检索出现在文档中的段落:block/string块的内容:block/parents段落的祖先们。对于顶层段落,它就是当前的页面。对于嵌套的段落,该属性会列出通向(包括)页面的所有祖先。
其他可选属性
Roam 只会在你改变特定块的默认值时才会设置这些属性(只存在于数据库中的段落),例如,你将块的文本对齐方式从左对齐改为居中。
:children/view-type指定如何显示块的子元素。可识别的值是“列表”模式、“文档”模式、“编号”模式:block/heading你可以将块的标题级别设置为 H1、 H2 或 H3。允许的值是 1,2,3:block/props这是 Roam 存储图像或 iframe 的大小、slider(滑块)的位置、 Pomodoro 番茄计时器设置等信息的地方:block/text-align段落对齐的方式。值为“左”、“中间”、“右”、“对齐”
Roam 数据结构
如果你想知道如何查找数据库中存在哪些属性,我有一个好消息!使用一个简单的查询,你就可以列出数据库中的所有属性:
[:find ?Namespace ?Attribute
:where [_ ?Attribute]
[(namespace ?Attribute) ?Namespace]]
以下就是所有属性的列表。说实话,上面的查询不会对值进行排序,也不会创建最后一列。我在可下载的 roam.json 文件中包含了稍微高级一点的查询版本,它将可用于排序。我在 clojure.core 文档中找到了namespace 函数。
| Namespace | Attribute | :Namespace/Attribute |
|---|---|---|
| attrs | lookup | :attrs/lookup |
| block | children | :block/children |
| block | heading | :block/heading |
| block | open | :block/open |
| block | order | :block/order |
| block | page | :block/page |
| block | parents | :block/parents |
| block | props | :block/props |
| block | refs | :block/refs |
| block | string | :block/string |
| block | text-align | :block/text-align |
| block | uid | :block/uid |
| children | view-type | :children/view-type |
| create | :create/email | |
| create | time | :create/time |
| edit | :edit/email | |
| edit | seen-by | :edit/seen-by |
| edit | time | :edit/time |
| entity | attrs | :entity/attrs |
| log | id | :log/id |
| node | title | :node/title |
| page | sidebar | :page/sidebar |
| user | color | :user/color |
| user | display-name | :user/display-name |
| user | :user/email | |
| user | photo-url | :user/photo-url |
| user | settings | :user/settings |
| user | uid | :user/uid |
| vc | blocks | :vc/blocks |
| version | id | :version/id |
| version | nonce | :version/nonce |
| version | upgraded-nonce | :version/upgraded-nonce |
| window | filters | :window/filters |
| window | id | :window/id |
Queries 查询
如果你对如何编写 Roam 查询语句感兴趣,那么你应该仔细阅读 Learn Datalog Today 的九个章节。它的内容非常有趣,且包含对应的练习。
接下来,我将几乎逐字逐句地引用教程中的几段话,当然会改变例子以适用于 Roam。其余的内容,请访问上面的教程。
我还推荐以下 Stuart Halloway 的 YouTube 视频,它在 11 分钟内总结了 Datomic Datalog 查询语言的关键特性。
查询是一个以 :find 关键字开头的矢量,后面跟着一个或多个模式变量(以 ? 符号开头,e.g. ?title)。find 子句之后是 :where 子句,它将查询限制在与给定的数据模式(data patterns)相匹配的 datoms 上。而使用 _ 符号作为通配符,则表示你希望忽略的数据模式部分。
例如,如果你想根据一个段落的块引用来查找文本,你需要这样写:
[:find ?string
:where [?b :block/uid "r61dfi2ZH"]
[?b :block/string ?string]]
根据本文章开头表格里面的例子,这个查询将返回 “Check Projects”
这里需要注意的是,模式变量?b在两个数据模式中都会使用。当一个模式变量在多个地方使用时,查询引擎要求它在每个地方都绑定为相同的值。因此,这个查询只会找到具有 uid r61dfi2ZH的块的字符串。
一个实体的 datoms 可能出现在不同命名空间的属性中。例如,如果我想找到包含r61dfi2ZH段落的页面的标题,我会编写以下查询。请注意,我首先读取页面的 entity-id 的 ?block/page 属性,并将其存储在 ?p 当中。 然后,我用它来定位页面的 ?note/title 和 ?block/uid。
[:find ?title ?uid
:where [?b :block/uid "r61dfi2ZH"]
[?b :block/page ?p]
[?p :node/title ?title]
[?p :block/uid ?uid]]
考虑到上面的例子,这将返回 “January 19th, 2021” 和 “01-19-2021”。
:in 子句为查询提供了输入参数,这与编程语言中的函数或方法参数的作用非常相似。以下是上一个查询的样子,注意其中有一个用于 block_reference 的输入参数。
[:find ?title ?uid
:in $ ?block_ref
:where [?b :block/uid ?block_ref]
[?b :block/page ?p]
[?p :node/title ?title]
[?p :block/uid ?uid]]
这个查询需要两个参数。$就是当前数据库本身(隐含值,如果没有指定:in子句),block_ref则可能是段落的块引用。
你可以使用 window.roamAlphaAPI.q(query,block_ref); 执行上述操作。如果没有为 $ 提供值,则查询引擎将隐式假定的是默认数据库。因为你将只查询你自己的 Roam 数据库,所以没有必要声明数据库。也许一旦 Roam 提供了跨数据库的链接,这将会变得非常有趣!
现在我将跳过本教程,以涵盖在 Roam 中稍有不同的几个主题。如果你对你错过了什么感兴趣,请阅读我跳过的详细教程。有一个关于元组、集合和关系(Tuples, Collections, and Relations)非常有用的讨论,它们提供了执行逻辑 OR 和 AND 操作的方法。
Predicates 断言
断言子句可以过滤结果集,只包括断言返回 true 的结果。在 Datalog 中,你可以使用任何 Clojure 函数或 Java 方法作为谓词函数。根据我的经验,在 Roam JavaScript 的实现中,Java 函数是不可用的,只有少数 Clojure 函数可以使用。
除了clojure.core命名空间之外,Clojure 函数必须是完全命名空间限定的。遗憾的是,在核心命名空间之外,我只找到了几个在 Roam 中能用的函数。这些函数包括clojure.string/includes?、clojure.string/starts-with?和clojure.string/ends-with?。另外一些来自核心命名空间的有用函数包括,返回属性命名空间的 namespace 和返回字符串长度的 count。一些无处不在的断言,也可以在没有命名空间限定的情况下使用,比如<, >, <=, >=, =, not=, !=等等。
这里有两个使用断言的例子。第一个函数指的是根据 block_reference 计算段落中的字符数。
[:find ?string ?size
:in $ ?block_ref
:where [?b :block/uid ?block_ref]
[?b :block/string ?string]
[(count ?string) ?size]]
第二个列出了在给定日期之后修改的所有 Blocks。
[:find ?block_ref ?string
:in $ ?start_of_day
:where [?b :edit/time ?time]
[(> ?time ?start_of_day)]
[?b :block/uid ?block_ref]
[?b :block/string ?string]]
Transformation 转换函数
遗憾的是,我无法让转换功能在 JavaScript 中工作。只有当您在桌面上安装了 Datalog 数据库,并加载 Roam.EDN 进行进一步的操作时,这些功能才有可能工作。
唯一可用的变通方法是在查询后对结果进行后处理。下面的例子将过滤页面标题,以大小写不敏感的方式查找文本片段 (“temp”),然后按字母顺序对结果进行排序。此查询将返回包括 “Template”、”template”、”Temporary”、”attempt “等词的页面。
let query = `[:find ?title ?uid
:where [?page :node/title ?title]
[?page :block/uid ?uid]]`;
let results = window.roamAlphaAPI.q(query)
.filter((item,index) => item[0].toLowerCase().indexOf('temp') > 0)
.sorta,b) => a[0].localeCompare(b[0];;
Aggregates 聚合
Aggregates,则可以像预期的那样工作。有许多可用的 Aggregates,包括sum、max、min、avg、count。你可以在这里阅读更多关于 Aggregates 的信息。
例如,如果你不知道某个属性的用途,或者不知道允许使用哪些值,只需查询数据库就可以找到现有的值。下一个例子列出了:children/view-type的值。需要注意的是,如果你只在 Graph 中使用 bullet 列表模式,查询将只返回一个值:”bullet”。我使用了独特的 Aggregates 函数,如果没有这个函数,我将得到一个可能有数千个值的列表,每个指定了视图类型的块都有一行。
[:find (distinct ?type)
:where
[_ :children/view-type ?type]]
Rules 规则
你可以将查询的可重用部分抽象为规则,给它们起有意义的名称,然后忘记其实现细节,就像你可以使用自己喜欢的编程语言编写函数一样。
Roam 中一个典型的规则例子是祖先规则。这些规则利用:block/children来遍历嵌套块的树。一个简单的祖先规则是这样的。这条规则基于 ?parent entity-id 来寻找 ?child。
[[(ancestor ?child ?parent)
[?parent :block/children ?child]]]
第一个矢量称为规则的 head,其中第一个符号就是规则的名称。规则的其余部分称为 body。
你可以用(...)或[...]将其括起来,但常规的做法是用(...)来帮助你的眼睛区分 head 和 body 的规则,也可以区分规则调用(rule invocations)和正常的数据模式(data patterns),我们将在下面看到示例。
你可以将规则看作一种函数,但请记住,这是逻辑编程,因此我们可以使用相同的规则,根据子 entity-id 找到父实体,根据父 entity-id 找到子实体。
换句话说,你可以在 (ancestor ?child ?parent) 中使用?parent和?child作为输入和输出。如果你既不提供值,你将得到数据库中所有可能的组合。如果你为其中一个或两个都提供值,它将如你所期望的那样限制查询返回的结果。
[:find ?uid ?string
:in $ ?parent
:where [?parent :block/children ?c]
[?c :block/uid ?uid]
[?c :block/string ?string]]
现在就变成了:
[:find ?uid ?string
:in $ ?parent %
:where (ancestor ?c ?parent)
[?c :block/uid ?uid]
[?c :block/string ?string]]
:in子句中的%符号代表规则。
乍一看,这似乎并不是一个巨大的成就。但是,规则是可以嵌套的。通过扩展上面的规则,你可以使它不仅返回子树,而且返回?parent下的整个子树。规则可以包含其他规则,也可以自己递归调用。
[[(ancestor ?child ?parent)
[?parent :block/children ?child]]
[(ancestor ?child ?grand_parent)
[?parent :block/children ?child]
(ancestor ?parent ?grand_parent)]]]
例如,我们现在可以使用这条规则来计算一个给定块的所有子孙数量。
window.roamAlphaAPI.q(`
[:find ?ancestor (count ?block)
:in $ ?ancestor_uid %
:where [?ancestor :block/uid ?ancestor_uid]
[?ancestor :block/string]
[?block :block/string]
(ancestor ?block ?ancestor)]`
,"hAfIHN6Gi",rule);
当然,在这个例子中,我们最好使用:block/parent属性,这样可以使查询更加简单。
[:find ?ancestor (count ?block)
:where [?ancestor :block/uid "hAfIHN6Gi"]
[?ancestor :block/string]
[?block :block/parents ?ancestor]]
Pull 拉
这篇文章已经太长,而且技术性太强。出于这个原因,我完全省略了关于(pull ) requests 的讨论 —— 尽管在 roam.json 中的例子中,我将会提到一部分。(pull ?e [*])是一种强大的从数据库中获取数据的方法。如果你想了解更多,这里有两个值得阅读的参考文献。
Datomic Pull in the Datomic On-Prem Documentation
Introduction to the Roam Alpha API on Put Your Left Foot.
Roam 查询 SmartBlock
我们可以在 SmartBlocks 内和浏览器中的开发者工具控制台中运行查询。然而,结果很难查看,因为它们是以嵌套的 JSONs 等晦涩的数据结构返回的。
2021 年 1 月 28 日更新:
同时我了解到,你也可以在 Roam 中使用块中的 :q 命令原生运行简单的查询。试试下面的命令:
:q [:find(count ?t):where[_ :node/title ?t]]
它不会像我的 SmartBlock 一样显示拉动或有页面链接,但仍然非常酷……
2021 年 2 月 22 日进一步更新:
我使用 :q 创建了一个长长的统计查询样本清单。你可以在这里找到它们。
我想让查询体验更加方便,并将其集成到 Roam 中。因此,我创建了一组 SmartBlocks,它们可以帮助将查询嵌入到你的 Roam 页面中,就像你在文档中包含的任何其他组件一样。
这里是可以导入到 Roam Graph 中的 DatomicQuery.JSON 文件链接。包括两个页面,SmartBlocks 和大量查询示例。继续阅读,可以了解如何使用它们。
你可以选择简单查询和高级查询。简单查询不接受输入参数,也不能包含规则。当然,你可以直接在查询中包含输入参数,你可以在下面的例子中看到。而高级查询则可以给你更充分的灵活性。
页面链接与日期链接
我做的 SmartBlock 可以把 query 查询结果格式化变成表格。它使用::hiccup在单个 Block 中返回结果,这样就可以避免在 Graph 中创建不必要的 Block。还有个额外的好处是,我加上了一些简单的显示逻辑,将页面标题(page titles)转换为可点击的页面链接(URL),可以将时间转成相对应的 Daily Notes 页面的链接。
要使用页面链接功能,你需要以一种特殊的方式生成查询:
- 通过在字段名后面添加
:name来指定标题字段,例如:?title:name。 - 将 uid 放在紧跟
?title:name字段的后面,并在字段名的末尾加上:uid,指定相应的 uid。例如:?title:uid - 在字段末尾添加:date,指定一个你想转换为 Daily Notes 页面链接的字段,例如:
?time:date
[:find ?title:name ?title:uid ?time:date
:where [?page :node/title ?title:name]
[?page :block/uid ?title:uid]
[?page :edit/time ?time:date]
[(clojure.string/starts-with? ?title:name "roam/")]]
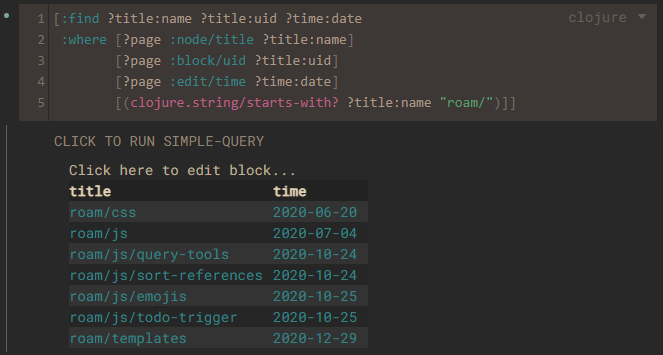
Pull 表达式
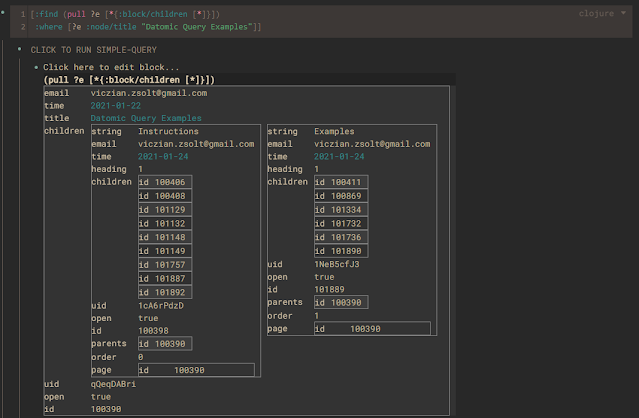
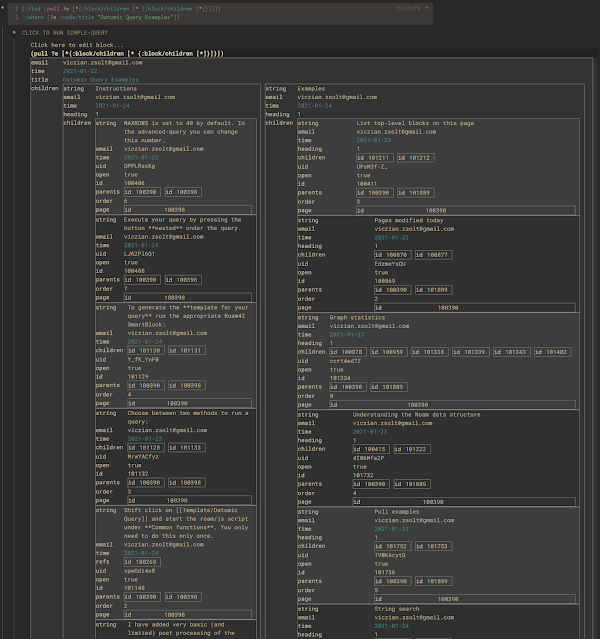
SmartBlock 还会将嵌套的结果显示为一个表格,在表格里显示得更整齐。当你执行包含(pull )语句的查询时,它的结果其实是一棵树,而不是一张表。所以我按照下面的逻辑来呈现查询结果。
- 我会把结果集的顶层显示为表格的行,值为列。
- 结果集中的嵌套层会交替以列或行的方式呈现。
- 为了避免结果集过大,MAXROWS 默认设置为 40。在高级查询中,你可以更改这个数字。
- 在嵌套层,我使用 MAXROWS/4 来限制显示的行数。即使这样设置,生成的表格也可以达到数百行。(40x10x10x…)
这是一个 (pull ) 结果所显示的表格。只拉取 1 个层级的深度:
拉取 2 个层级的深度:
Query 查询模板
要为你的查询生成模板,请运行相应的 Roam42 SmartBlock。
- Datomic simple-template 简单模板
- Datomic advanced-template 高级模板
一旦准备好你的查询,只需按下嵌套在查询下的按钮即可执行。
经过一周的时间,我还没有成为这方面的专家。如果我写的东西很傻,比如我的查询或 SmartBlock 有错误的话,请告诉我。你可以在下面的评论中联系我,或者在 Twitter 上@zsviczian。
另外,我很想了解你是如何使用从这篇文章中学到的知识,以及如何使用 SmartBlock 的。请分享你的想法和成果。谢谢你!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK