

地区分布图及其应用
source link: https://cosx.org/2022/05/choropleth-map/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

美国各郡的年平均癌症死亡率分布
下面以 latticeExtra 包 (Sarkar and Andrews 2019) 内置的 USCancerRates 数据集为例介绍分面,同时展示多个观测指标的空间分布。USCancerRates 数据集来自美国国家癌症研究所(National Cancer Institute,简称 NCI)。根据 1999-2003 年的 5 年数据,分男女统计癌症年平均死亡率(单位十万分之一),这其中的癌症数是所有癌症种类之和。癌症死亡率根据 2000 年美国标准人口年龄分组调整,分母人口数量由 NCI 根据普查的人口数调整,即将各年各个年龄段的普查人口数按照 2000 年的美国标准人口年龄分组换算。因 latticeExtra 包没有提供数据集的加工过程,笔者结合 NCI 网站信息,对此数据指标的调整过程略加说明,这里面其实隐含很多的道理。
人口数每年都会变的,为使各年数据指标可比,人口划分就保持一致,表 1 展示 1940-2000 年各个年龄段(共 19 个年龄组)的标准人口数,各个年龄段的普查人口数换算成年龄调整的标准人口数,换算公式为:
某年龄段标准人口数=某年龄段普查人口数/总普查人口数∗1000000.某年龄段标准人口数=某年龄段普查人口数/总普查人口数∗1000000.
以 2000 年的 10-14 岁年龄段标准人口数为例,即:
73032=20056779/274633642∗1000000.73032=20056779/274633642∗1000000.
| Age | 2000 | 2000 (Census) | 1990 | 1980 | 1970 | 1960 | 1950 | 1940 |
|---|---|---|---|---|---|---|---|---|
| 00 | 13,818 | 3,794,901 | 12,936 | 15,598 | 17,151 | 22,930 | 20,882 | 15,343 |
| 01-04 | 55,317 | 15,191,619 | 60,863 | 56,565 | 67,265 | 90,390 | 86,376 | 64,718 |
| 05-09 | 72,533 | 19,919,840 | 72,772 | 73,716 | 98,204 | 104,235 | 87,591 | 81,147 |
| 10-14 | 73,032 | 20,056,779 | 68,812 | 80,523 | 102,304 | 93,538 | 73,785 | 89,208 |
| 15-19 | 72,169 | 19,819,518 | 71,384 | 93,439 | 93,845 | 73,717 | 70,450 | 93,670 |
| 20-24 | 66,478 | 18,257,225 | 76,476 | 94,103 | 80,561 | 60,231 | 76,191 | 88,007 |
| 25-29 | 64,529 | 17,722,067 | 85,694 | 86,168 | 66,320 | 60,612 | 81,237 | 84,277 |
| 30-34 | 71,044 | 19,511,370 | 87,905 | 77,516 | 56,249 | 66,635 | 76,425 | 77,789 |
| 35-39 | 80,762 | 22,179,956 | 80,267 | 61,644 | 54,656 | 69,601 | 74,629 | 72,495 |
| 40-44 | 81,851 | 22,479,229 | 70,829 | 51,510 | 58,958 | 64,689 | 67,712 | 66,742 |
| 45-49 | 72,118 | 19,805,793 | 55,778 | 48,951 | 59,622 | 60,670 | 60,190 | 62,697 |
| 50-54 | 62,716 | 17,224,359 | 45,638 | 51,689 | 54,643 | 53,568 | 54,893 | 55,114 |
| 55-59 | 48,454 | 13,307,234 | 42,345 | 51,271 | 49,077 | 47,009 | 48,011 | 44,383 |
| 60-64 | 38,793 | 10,654,272 | 42,685 | 44,528 | 42,403 | 39,830 | 40,210 | 35,911 |
| 65-69 | 34,264 | 9,409,940 | 40,657 | 38,767 | 34,406 | 34,897 | 33,199 | 28,911 |
| 70-74 | 31,773 | 8,725,574 | 32,145 | 30,008 | 26,789 | 26,427 | 22,641 | 19,515 |
| 75-79 | 26,999 | 7,414,559 | 24,612 | 21,160 | 18,871 | 17,028 | 14,283 | 11,422 |
| 80-84 | 17,842 | 4,900,234 | 15,817 | 12,956 | 11,241 | 8,811 | 7,467 | 5,881 |
| 85+ | 15,508 | 4,259,173 | 12,385 | 9,888 | 7,435 | 5,182 | 3,828 | 2,770 |
| Total | 1,000,000 | 274,633,642 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 |
年龄调整的比率(Age-adjusted Rates)的定义详见 NCI 网站,它是一个根据年龄调整的加权平均数,权重根据年龄段人口在标准人口中的比例来定,一个包含年龄 xx 到年龄 yy 的分组,其年龄调整的比率计算公式如下:
aaratex−y=y∑i=x[(countipopi)×(stdmili∑yj=xstdmilj)×100000]aaratex−y=∑i=xy[(countipopi)×(stdmili∑j=xystdmilj)×100000]
一个具体的例子可见网站,篇幅所限,此处仅以 2000 年举例,一个年龄段 0-0 死亡人数 29(可看作婴儿死亡人数),总人数 139879,则年龄调整的死亡率:
aarate0−0=29139879∗3794901274633642∗100000=0.2864aarate0−0=29139879∗3794901274633642∗100000=0.2864
读者可能有疑惑,一系列复杂的调整是为什么?指标稳定性和可比性。稳定不是代表不变,稳定是不轻易受干扰。从各社区、各郡、各州乃至国家,从下往上聚合数据的时候,分年龄、种族、性别等下钻 / 上卷的时候,有的郡总人口可能相对很少,死亡人数也很少。可比性是指组与组间可比,且随时间变化依然可比,刻画因癌症死亡的相对风险。
# 加载死亡率数据
data(USCancerRates, package = "latticeExtra")
# 查看 Alabama 的 Pickens County 的数据
subset(x = USCancerRates, subset = state == "Alabama" & county == "Pickens County")
# rate.male LCL95.male UCL95.male rate.female LCL95.female
# alabama,pickens 363.7 311.1 423.2 151 123.6
# UCL95.female state county
# alabama,pickens 183.6 Alabama Pickens County以 Alabama 的 Pickens County 为例,1999-2003 年平均年龄调整的男性癌症死亡率为 363.7(单位:十万分之一),在 95% 置信水平下,置信限为 [311.1,423.2][311.1,423.2]。根据最新的五年数据显示 2014-2018 年男性癌症死亡率为 479.8,95% 置信水平下的置信区间为 [425.7,539.3][425.7,539.3]。简单验证一下,就会发现有意思的现象,置信区间不是关于观测的癌症死亡率对称,且离置信区间中心尚有距离, 311.1+423.22=367.1≠363.7311.1+423.22=367.1≠363.7。一般来说,100000 人中有 363.7 人因癌症死亡,死亡人数较多(比如大于 100)的情况下,二项分布可用正态分布逼近,置信区间上下限应该分别为:
qnorm(p = 1 - 0.05 / 2)
# [1] 1.96
# 置信下限
363.7 - 1.96 * sqrt(363.7 / 100000 * (1 - 363.7 / 100000) / 100000) * 100000
# [1] 326.4
# 置信上限
363.7 + 1.96 * sqrt(363.7 / 100000 * (1 - 363.7 / 100000) / 100000) * 100000
# [1] 401而美国国家癌症研究所给的置信带更宽,更保守一些,显然这里面的算法没这么简单。以阿拉巴马州为例,将所有的郡死亡率及其置信区间绘制出来,如图 1 所示,整体来说,偏离置信区间中心都很小。
图 1: 1999-2003 年美国阿拉巴马州各个郡的年平均癌症死亡率
不难看出,女性癌症死亡率整体上低于男性,且各个地区的死亡率有明显差异。NCI 网站仅对置信区间的统计意义给予解释,这跟统计学课本上没有太多差别,没有提供具体的计算过程。可以推断的是必然使用了泊松、伽马一类的偏态分布来刻画死亡人数的分布,疑问尚未解开,欢迎大家讨论。
癌症死亡率相关数据仅可用于统计报告和分析,不可用于其他目的,请遵守相关法律规定。
分析和展示地理信息数据是一项常规任务,约 30 年前,Richard A. Becker 等为 S 语言引入地理可视化,特别是本文介绍的地区分布图,以及简单的区域面积和区域中心的计算能力 (Becker and Wilks 1993, 1995),而后到了 2003 年,Ray Brownrigg、Thomas P Minka 和 Alex Deckmyn 等将其引入 R 语言社区并持续维护至今 (Richard A. Becker, Ray Brownrigg. Enhancements by Thomas P Minka, and Deckmyn. 2021)。除了最基础的 maps 包,还有坐标投影 mapproj 包 (R by Ray Brownrigg, Minka, and Plan 9 codebase by Roger Bivand. 2022),以及提供更多地图数据的 mapdata 包 (Richard A. Becker and Ray Brownrigg. 2018)。那个时候,因缺乏一些基础工具,在地图数据获取、空间数据操作和可视化方面都不太容易,仅用这些能做到下图 2 已属不易。
# 加载数据
data(USCancerRates, package = "latticeExtra")
library(maps)
# 郡地图数据
us_county <- map("county", plot = FALSE, fill = TRUE, projection = "polyconic")
# 奈何 maps 内置的地图数据不全,仅保留部分观察数据
USCancerRates2 <- subset(
x = USCancerRates,
subset = rownames(USCancerRates) %in% us_county$names
)
# 调色板
colors <- viridisLite::plasma(13)
# 图例文本
leg.txt <- mapply(paste, 50*0:12, 50*1:13, collapse = " ", sep = "~")
# 癌症死亡率划分区间
USCancerRates2$colorBuckets_male <- as.numeric(cut(USCancerRates2$rate.male, 50*0:13))
# 根据城镇名称给地图上每个区域的癌症死亡率匹配颜色
colorsmatched_male <- USCancerRates2$colorBuckets_male[match(
us_county$names, rownames(USCancerRates2)
)]
# 对女性癌症死亡率类似操作
USCancerRates2$colorBuckets_female <- as.numeric(cut(USCancerRates2$rate.female, 50*0:13))
colorsmatched_female <- USCancerRates2$colorBuckets_female[match(
us_county$names, rownames(USCancerRates2)
)]
# 绘图
par(mar = c(0, 0, 3, 0), mfrow = c(2, 1))
# 添加地图背景
map("county",
col = "grey80", fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic"
)
# 绘制区县地图
map("county",
col = colors[colorsmatched_male], fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic", add = TRUE
)
# 添加州边界线
map("state",
col = "white", fill = FALSE, add = TRUE,
lty = 1, lwd = 0.2, projection = "polyconic"
)
map.scale()
# 添加图标题
title("1999-2003 年美国各个郡的年平均癌症死亡率(单位:十万分之一)", line = 2)
mtext(text = "男性", side = 3, adj = 0.5)
par(mar = c(1, 0, 2, 0))
map("county",
col = "grey80", fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic"
)
map("county",
col = colors[colorsmatched_female], fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic", add = TRUE
)
# 添加州边界线
map("state",
col = "white", fill = FALSE, add = TRUE,
lty = 1, lwd = 0.2, projection = "polyconic"
)
map.scale()
mtext(text = "女性", side = 3, adj = 0.5)
mtext(text = "数据源:美国国家癌症研究所", side = 1, adj = 0)
# 添加图例
legend("bottomright",
legend = c(leg.txt, "NA"), title = "死亡率", box.col = NA, border = NA,
horiz = FALSE, fill = c(colors, "grey80"), cex = 0.85, xjust = 0.5
)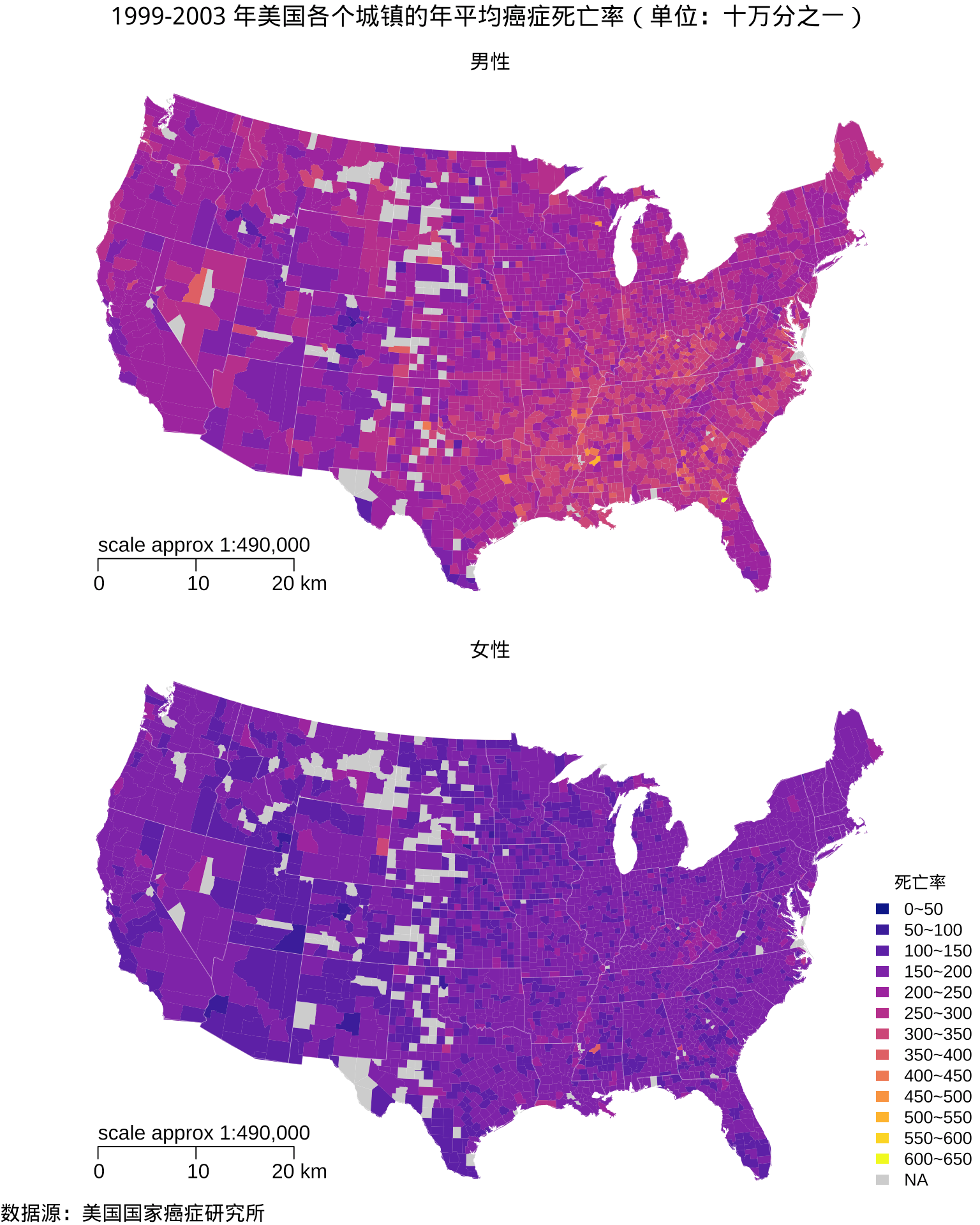
图 2: 1999-2003 年美国各个郡的年平均癌症死亡率分布
maps 包 (Becker and Wilks 1993) 内置的美国郡级地图数据欠缺阿拉斯加、夏威夷和波多黎各。数据集 USCancerRates 没有夏威夷、波多黎各各个郡的数据,阿拉斯加的部分郡有数据,如图 2 所示,不少郡没有收集到癌症死亡率数据,以灰色表示。值得一提的是,关于死亡率分级,不同的分法会带给人不同的印象甚至是错觉,此处是可以有操作空间的,特定的死亡率分割方式可以让男女死亡率的空间分布看起来差异不大或很大 (Kolak et al. 2020),详细介绍见 Marynia Kolak 和 Susan Paykin 在 2021 R/Medicine 大会上的视频和网页材料。
在数据操作方面,麻烦的是建立数据指标和各个地理区域的映射,上面反复用到函数 match(),Base R 有很多这样短小精悍的函数。下面简单介绍一下以助理解,函数 match() 返回一个向量,向量的长度与参数 x 一致,向量的元素是整型的,表示参数 x 中的元素出现在参数 table 中的位置,下面是三个小示例:
match(x = c("A", "B"), table = c("A"))
# [1] 1 NA
match(x = c("A", "B"), table = c("C", "A"))
# [1] 2 NA
match(x = c("A", "B"), table = c("C", "A", "D"))
# [1] 2 NA另外,maps 包内置的地图数据制作起来比较复杂,也很长时间没有更新了,笔者不推荐读者再从零开始构建 map 数据对象。sp 包 (E. J. Pebesma and Bivand 2005) 发布后,maps 包支持将 Spatial 数据对象转为 map 数据对象,这相当于引入了 sp 包及其生态在空间数据获取和数据操作方面的能力 (R. S. Bivand, Pebesma, and Gomez-Rubio 2013)。目前,美国国家人口统计局已提供了历年的州、郡、普查级多个比例尺的行政区划地图数据,配合 sf 包 (E. J. Pebesma 2018),可以很好地解决地理可视化的背景底图问题。一些以前看起来很难的问题,随着时间变迁,技术革新,已经解决了。
latticeExtra
maps 包是基于 Base R 绘图系统的,以线和多边形为基础,辅以颜色填充,还没有任何分层绘图的概念,Deepayan Sarkar 将其引入新的 Trellis(栅格)图形系统,这就有了 latticeExtra 包 (Sarkar and Andrews 2019),它是以 lattice 包 (Sarkar 2008) 为基础的,特别适合多元数据可视化,不管数据是「宽格式」还是「长格式」都能轻松应对,既保留了 Base R 那种精细操作图形元素的能力,也引入图层面板的概念。如图 3,在代码形式上将所有的操作都集于一身,没有严格的分层绘图,保留更大的灵活性的代价是提升了复杂性。绘图主要步骤如下:
- 准备数据:准备想要展示的数据指标
x,指标所在的数据集data,指标所描述的地理区域map,同时传递给函数mapplot(x, data, map, ...)完成图形主体部分。 - 添加配色:了解死亡率的分布情况,设置合适的分段,选择合适的调色板。
- 添加边界:函数
mapplot(x, data, map, panel, ...)中的参数panel需要一个函数作为参数值,修改默认的面板函数panel = panel.mapplot,添加各郡的边界线,再调函数latticeExtra::layer叠加各州的边界线,设置颜色深浅和边界线的粗线形成层次。 - 添加标题:添加横轴、纵轴、图例、分面标题,图形副标题,适当调整位置。
- 最后调整布局、刻度等细节。除了步骤 1 必须先做,后续步骤没有严格的顺序,图形中各部分是相对独立的,若遇覆盖情况则需注意顺序。
# 美国州边界数据
us_state <- map("state", plot = FALSE, fill = TRUE, projection = "polyconic")
library(lattice)
# 绘图
latticeExtra::mapplot(rownames(USCancerRates) ~ rate.female + rate.male,
# 观测数据
data = USCancerRates,
# 修改默认的面板函数
panel = function(x, y, map, ...) {
# 对未收集到癌症死亡率数据的郡,添加郡边界线
panel.lines(
x = us_county$x, y = us_county$y,
lty = 1, lwd = 0.2, col = "black"
)
latticeExtra::panel.mapplot(x, y, map, ...)
},
# 郡地图数据为背景
map = us_county,
# 填充地图用的调色板
colramp = viridisLite::plasma,
# 覆盖郡边界线
border = NA,
# 多图布局 2 行 1 列
layout = c(1, 2),
# 死亡率分桶数
# cuts = 14, # 指定 breaks 后就不需要 cuts
# 死亡率数据分割点
breaks = 50 * 0:13,
# 仅展示地图数据中包含的郡死亡率数据
subset = rownames(USCancerRates) %in% us_county$names,
# 取消坐标轴刻度
scales = list(draw = F),
# 修改分面展示文本
strip = strip.custom(factor.levels = c("女性", "男性")),
# 去掉横轴标签
xlab = "",
# 添加图例标题
legend = list(top = list(
fun = grid::textGrob("死亡率", y = 0.1, x = 1.03)
)),
# 常规图形参数列表 trellis.par.get('par.sub.text')
par.settings = list(
# 副标题放在左下角
par.sub.text = list(
font = 2,
just = "left",
x = grid::unit(5, "mm"),
y = grid::unit(5, "mm")
),
# 分面边界和背景色
strip.border = list(col = "white"),
strip.background = list(col = "white"),
# 轴线设置白色以隐藏
axis.line = list(col = "white")
),
# 副标题
sub = "数据源:美国国家癌症研究所",
# 主标题
main = "1999-2003 年美国各个郡的年平均癌症死亡率"
) +
# 添加州边界
latticeExtra::layer(panel.lines(
x = us_state$x, y = us_state$y,
lty = 1, lwd = 0.2, col = "white"
))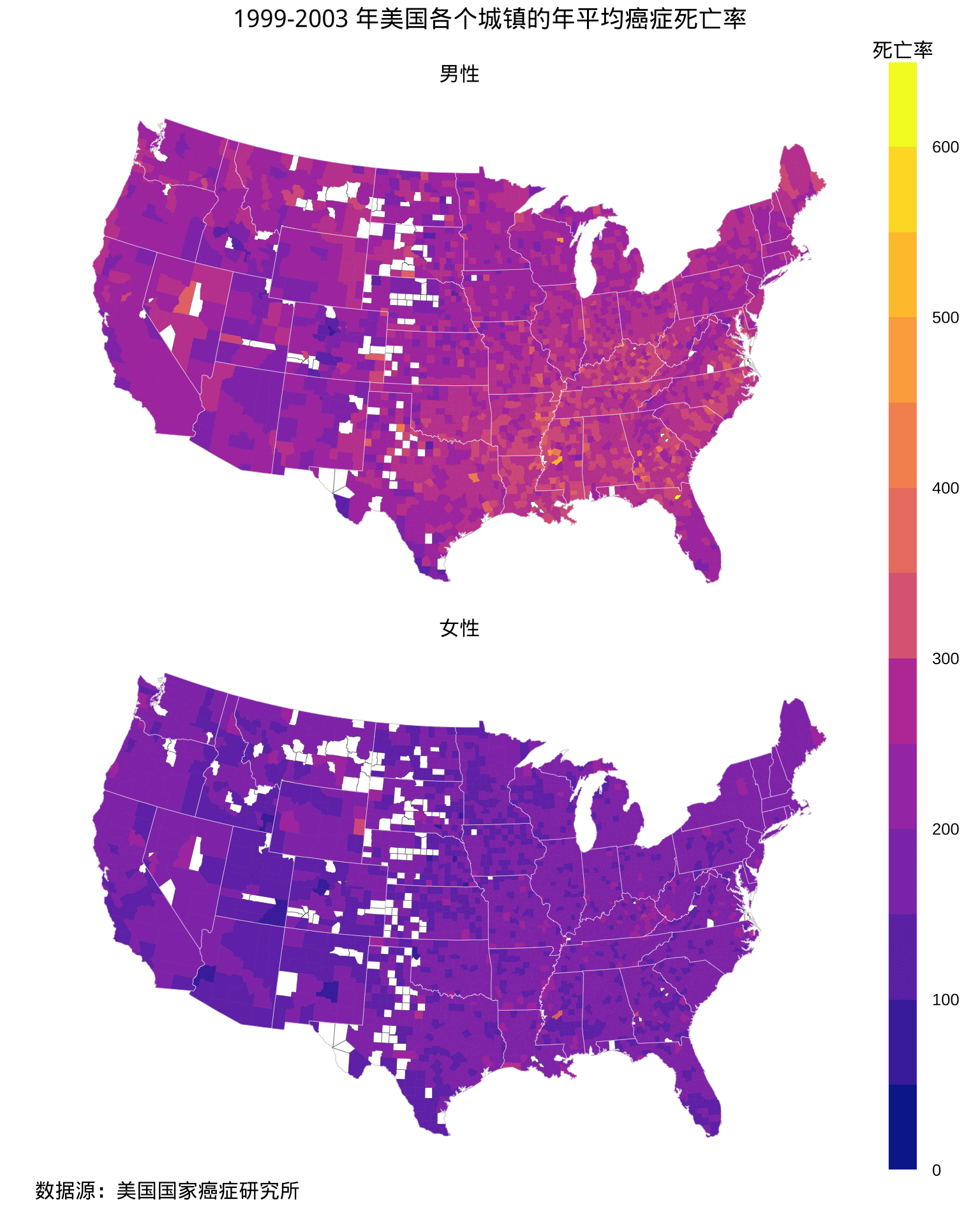
图 3: 1999-2003 年美国各个郡的年平均癌症死亡率分布
用 lattice 包绘图往往可以一个函数搞定,参数非常多,都放在一起,这和 Base R 的绘图函数类似,也同时提供全局图形参数控制,但似乎更加复杂。下面谈几个细节:
只需传给参数
colramp一个生成颜色值向量的函数即可更改调色板,比如 R 内置的hcl.colors()或terrain.colors()等,为保持全文配色风格一致,图中配色采用 viridisLite 包提供的 plasma 调色板。参考 Markus Gesmann 在 2015 年写的一篇文章 (Gesmann 2015),设置 Lattice 图形参数
par.settings对图中的标题做了细致的调节,比如副标题的文本par.sub.text所有可调整的细节有:trellis.par.get("par.sub.text") # $alpha # [1] 1 # # $cex # [1] 1 # # $col # [1] "#000000" # # $font # [1] 2 # # $lineheight # [1] 1想必读者已看出其规律,以 R 语言的列表结构来传递各个层级的图形参数值。
参考 SO 论坛帖子设置参数
strip自定义了分面子图的标题文本,再在par.settings里对背景strip.background和边界strip.border微调,而类似的设置在 ggplot2 包的主题函数theme()里也有,在 R 控制台执行formalArgs(ggplot2::theme)可获得主题函数的参数列表。读者下一个疑惑可能是如何知道所有的图形控制参数,以及控制的精细程度,Deepayan Sarkar 在书里以图 4 归纳了,纵轴是图形参数,横轴是参数值名称列表 (Sarkar 2008),按图索骥一定有所帮助。
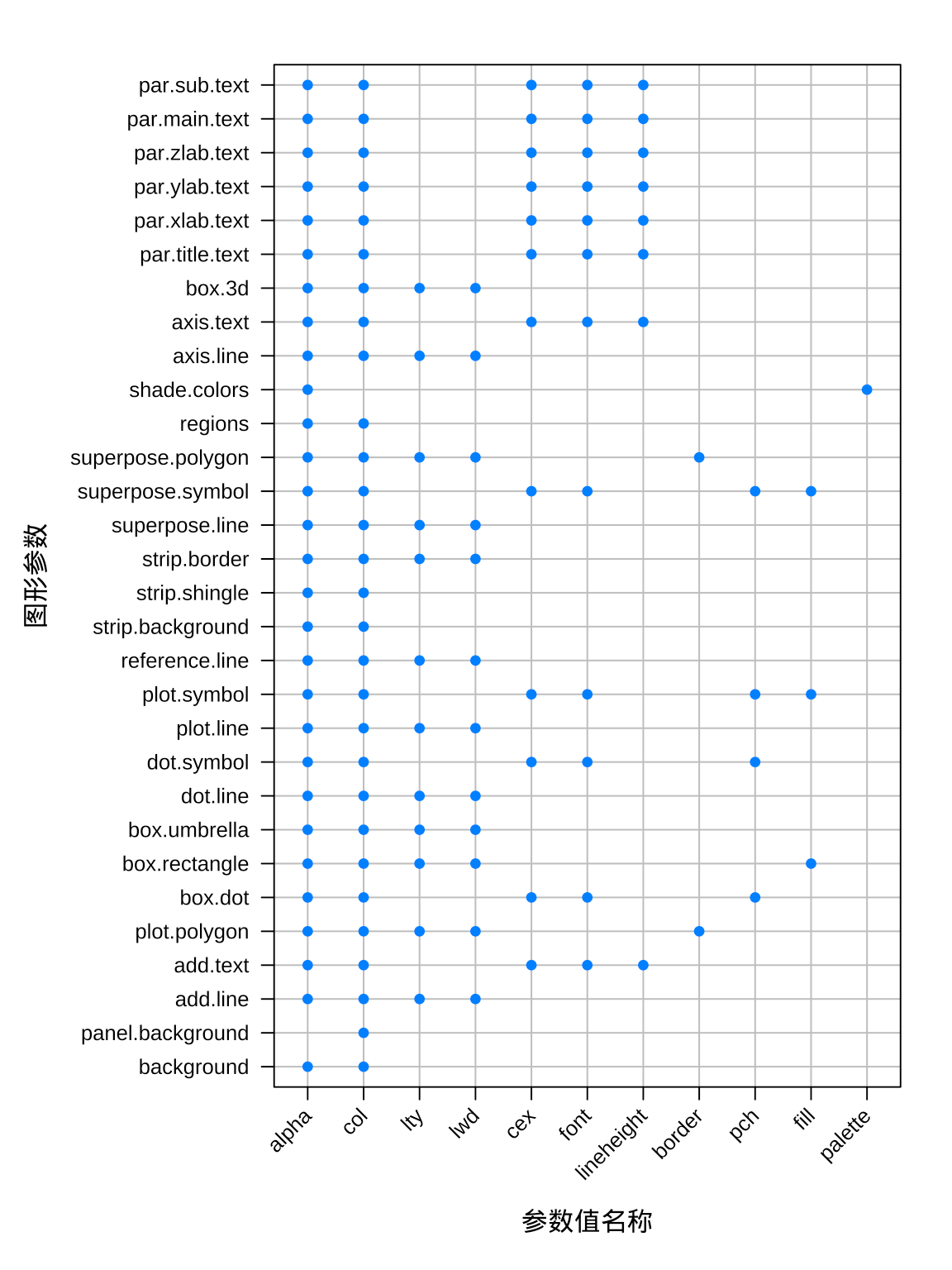
图 4: lattice 包常用图形参数一览
参数控制的效果预览如图 5 所示,不难看出,lattice 包 (Sarkar 2008) 可以提供精细化的图形调整,是一个非常成熟的绘图工具。
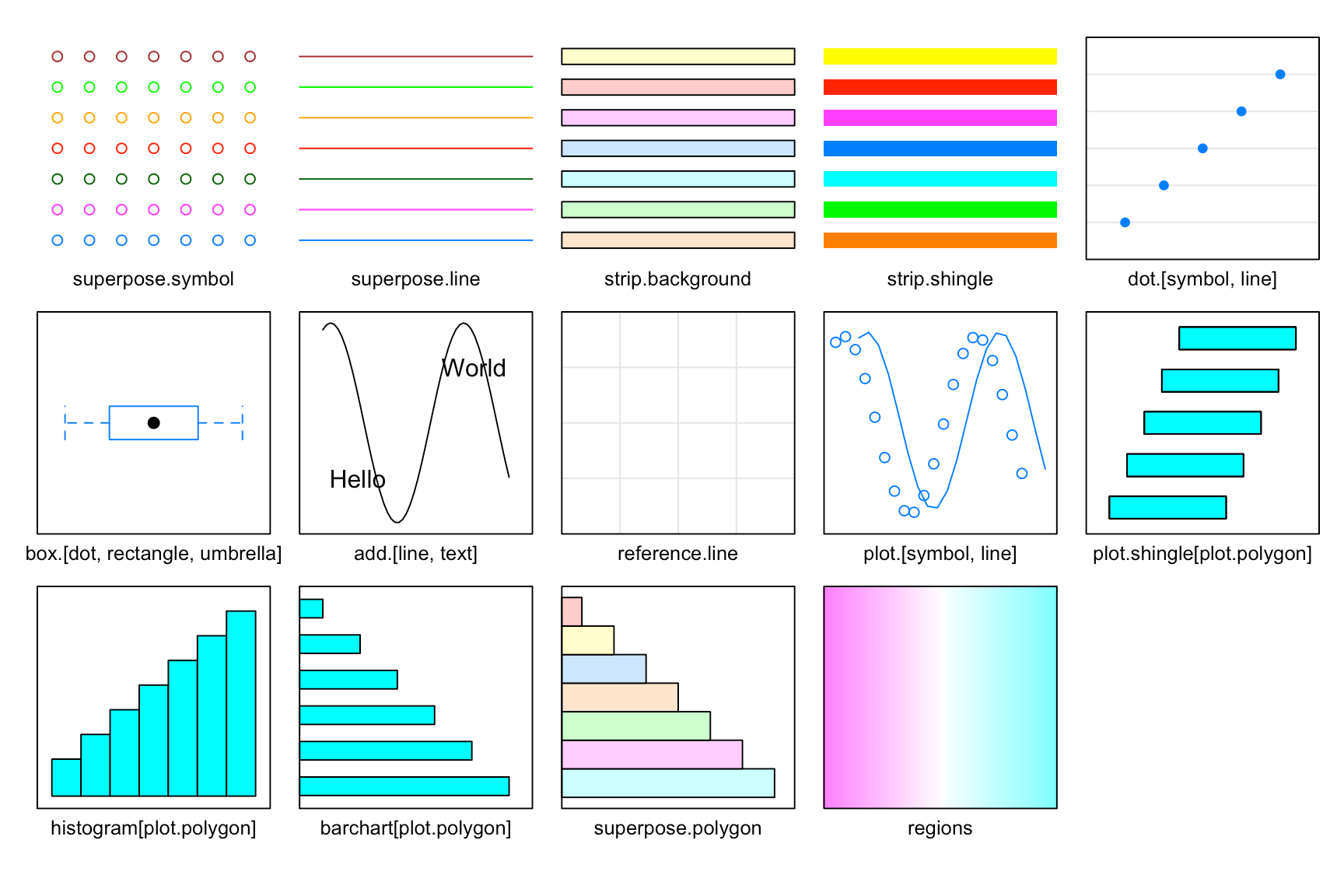
图 5: 图形控制参数
如前所述,lattice 和 ggplot2 同出一脉,既然 ggplot2 有图层的概念,lattice 自然也有,除了 提供丰富的内置图层(约 100 个,读者可在控制台运行
apropos('panel')查看当前环境下可用的图层),也支持用户自定义图层,图 6 展示叠加图层panel.superpose的效果,传递自定义的符号给pch参数,实际上修改了默认图形参数"superpose.symbol"。p1 <- xyplot(Sepal.Length ~ Sepal.Width, data = iris, groups = Species) p2 <- xyplot(Sepal.Length ~ Sepal.Width, data = iris, groups = Species, pch = c("L", "M", "N"), panel = panel.superpose ) print(p1, split = c(1, 1, 2, 1), more = TRUE) print(p2, split = c(2, 1, 2, 1), more = FALSE)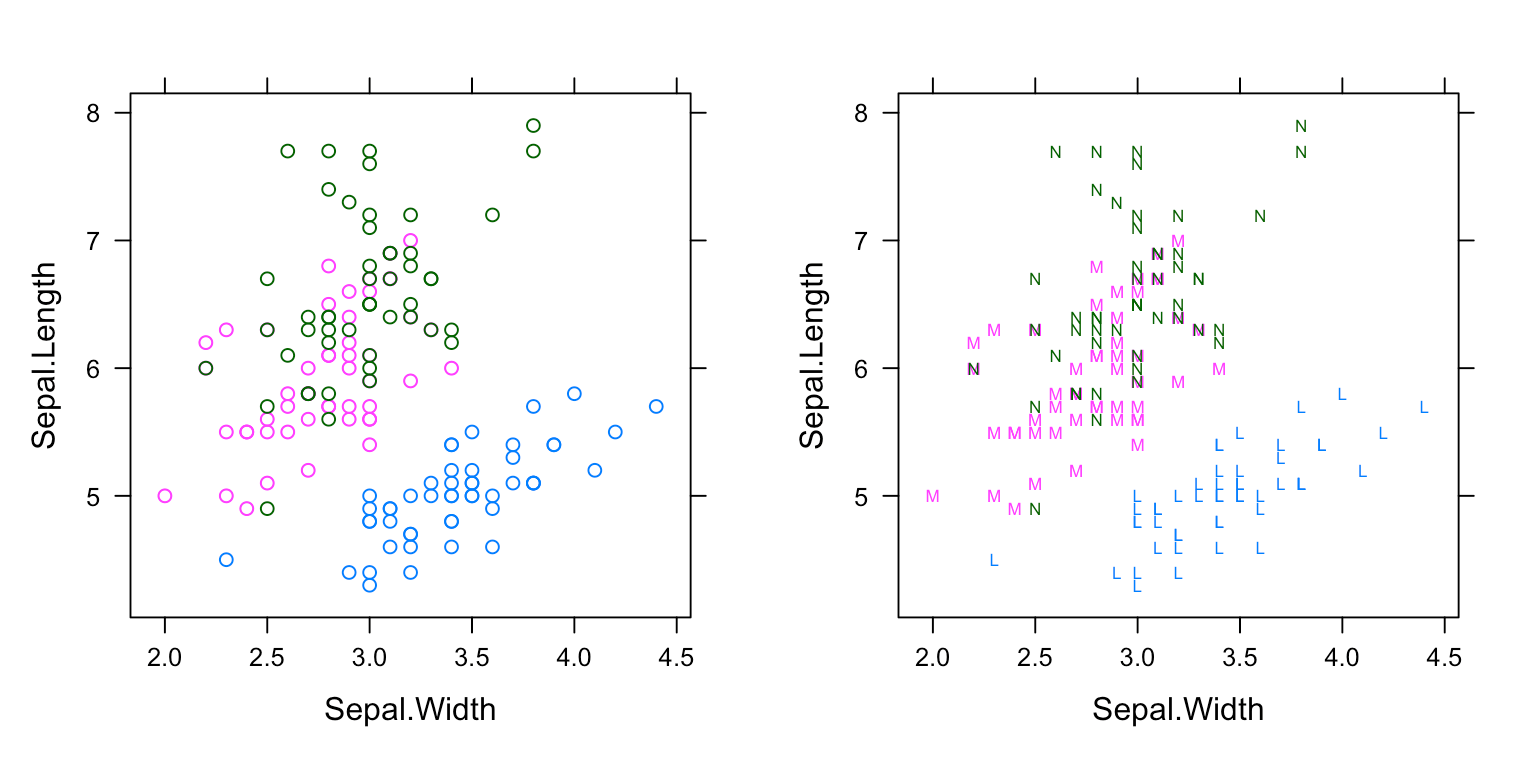
图 6: panel 叠加图层:左图默认散点图层,右图符号图层
此外,latticeExtra 扩展了图层功能,特别是
layer()函数,可在主体绘图函数之后直接叠加新图层。如上图 3,在latticeExtra::mapplot()完成主体绘图工作后,添加美国各州边界线,有助于识别郡位置。大家应该都有这样一种感觉,将一张只有中国国家边界的地图放在面前,你不一定能清晰地指出每一个省份的位置,但只要画上各个省的边界,你肯定能指出更多的省份位置,类似地,从省到市、乃至区县,边界给了我们很好的参照。
ggplot2
考虑到 maps 包内置的地图数据的缺陷,ggplot2 包的流行度,下面采用 ggplot2 包绘制分面地区分布图,相比于 latticeExtra 包,ggplot2 包更适合「长格式」的数据,因此,需要先重塑 USCancerRates 数据集,将郡死亡率数据和郡地理边界数据配对,根据死亡率的分布设置合适分段,最后恢复地图数据的原始顺序。数据操作过程中有两点强调:
数据重塑:USCancerRates 数据集除了 state 和 county 列,剩余列是由三个原子指标按性别维度衍生出来的,分别是癌症死亡率及其置信区间的上、下限值。在「宽格式」转「长格式」过程中,要注意转化前后各个列名的对应关系。
数据关联:先将地图数据放左边,观测数据放右边,以 LEFT JOIN (左关联) 的方式关联起来,接着将连续性的死亡率数据分段,最后调用绘图函数绘制地区分布图。
# 宽格式转长格式
us_cancer_rates <- reshape(
data = USCancerRates,
# 需要转行的列
varying = c(
"LCL95.male", "rate.male", "UCL95.male",
"LCL95.female", "rate.female", "UCL95.female"
),
times = c("男性", "女性"), # 构成新列 sex 的列值
v.names = c("LCL95", "rate", "UCL95"), # 列转行 列值构成的新列,指定名称
timevar = "sex", # 列转行 列名构成的新列,指定名称
idvar = c("state", "county"), # 可识别郡的 ID
# 原数据有 3041 行,性别字段只有两个取值,转长格式后有 2*3041 行
new.row.names = 1:(2 * 3041),
direction = "long"
)# 数据重塑前
head(USCancerRates) # 宽格式
# rate.male LCL95.male UCL95.male rate.female LCL95.female
# alabama,pickens 363.7 311.1 423.2 151.0 123.6
# alabama,bullock 345.7 274.2 431.4 140.5 102.8
# alabama,russell 340.7 304.5 380.9 182.3 161.3
# alabama,barbour 335.9 288.9 389.1 185.3 157.2
# alabama,dallas 330.1 293.4 370.6 172.0 151.4
# alabama,greene 328.1 255.9 416.6 124.1 88.5
# UCL95.female state county
# alabama,pickens 183.6 Alabama Pickens County
# alabama,bullock 189.7 Alabama Bullock County
# alabama,russell 205.5 Alabama Russell County
# alabama,barbour 217.5 Alabama Barbour County
# alabama,dallas 195.0 Alabama Dallas County
# alabama,greene 171.7 Alabama Greene County# 数据重塑后
head(us_cancer_rates, 12) # 长格式
# state county sex LCL95 rate UCL95
# 1 Alabama Pickens County 男性 311.1 363.7 423.2
# 2 Alabama Bullock County 男性 274.2 345.7 431.4
# 3 Alabama Russell County 男性 304.5 340.7 380.9
# 4 Alabama Barbour County 男性 288.9 335.9 389.1
# 5 Alabama Dallas County 男性 293.4 330.1 370.6
# 6 Alabama Greene County 男性 255.9 328.1 416.6
# 7 Alabama Perry County 男性 261.4 327.9 408.0
# 8 Alabama Walker County 男性 299.1 327.4 358.2
# 9 Alabama Macon County 男性 276.4 323.6 377.5
# 10 Alabama Lamar County 男性 265.3 321.4 386.3
# 11 Alabama Lawrence County 男性 276.1 318.5 366.9
# 12 Alabama Marengo County 男性 267.4 315.6 370.7# 从 usmapdata 包获取地图数据
county_df <- usmapdata::us_map("counties")
# 给每个郡的癌症死亡率数据配上地图数据
dat <- merge(
x = county_df, y = us_cancer_rates,
by.x = c("full", "county"),
by.y = c("state", "county"),
all.y = T
)
# 准备州边界线数据
state_df <- usmapdata::us_map("states")
# 癌症死亡率分级
dat$rate_d <- cut(dat$rate, breaks = 50 * 0:13)
# 恢复地图数据顺序
dat <- dat[order(dat$order), ]数据准备工作完成后,绘图过程主要有八个步骤:
- 底图:绘制美国郡地图,填充灰色背景,以此为底图。
- 映射:添加每个郡的癌症死亡率数据,填充颜色根据死亡率而定。同时以浅白色绘制郡的边界线,将线调细一些,与后面州的边界线形成层次。
- 边界:添加美国各个州的边界线,帮助熟悉美国地图的读者从州到郡快速定位。
- 配色:类似前文设置,采用
plasma调色板,未采集到死亡率数据的郡填充灰色,和地图背景融为一体。 - 布局:以函数
facet_wrap()实现分面,分面标题放在图形上方,布局为两行一列。 - 标题:添加整个图形的主标题、副标题和图例标题。
- 主题:设置整个图形主题样式
theme_void()以符合地图特色,将图形主标题位置居中。 - 细节:打磨图形配色、长宽尺寸、字体大小等方面,直至满意。
library(ggplot2)
ggplot() +
geom_polygon(
data = county_df, aes(x, y, group = group),
fill = "grey80"
) +
geom_polygon(
data = dat, aes(x, y, group = group, fill = rate_d),
colour = alpha("white", 1 / 4), size = 0.1
) +
geom_polygon(
data = state_df, aes(x, y, group = group),
colour = "gray80", fill = NA, size = 0.15
) +
scale_fill_viridis_d(option = "plasma", na.value = "grey80") +
facet_wrap(~sex, ncol = 1, strip.position = "top") +
labs(
fill = "死亡率", title = "1999-2003 年美国各个郡的年平均癌症死亡率",
caption = "数据源:美国国家癌症研究所"
) +
theme_void(base_size = 13) +
theme(plot.title = element_text(hjust = 0.5))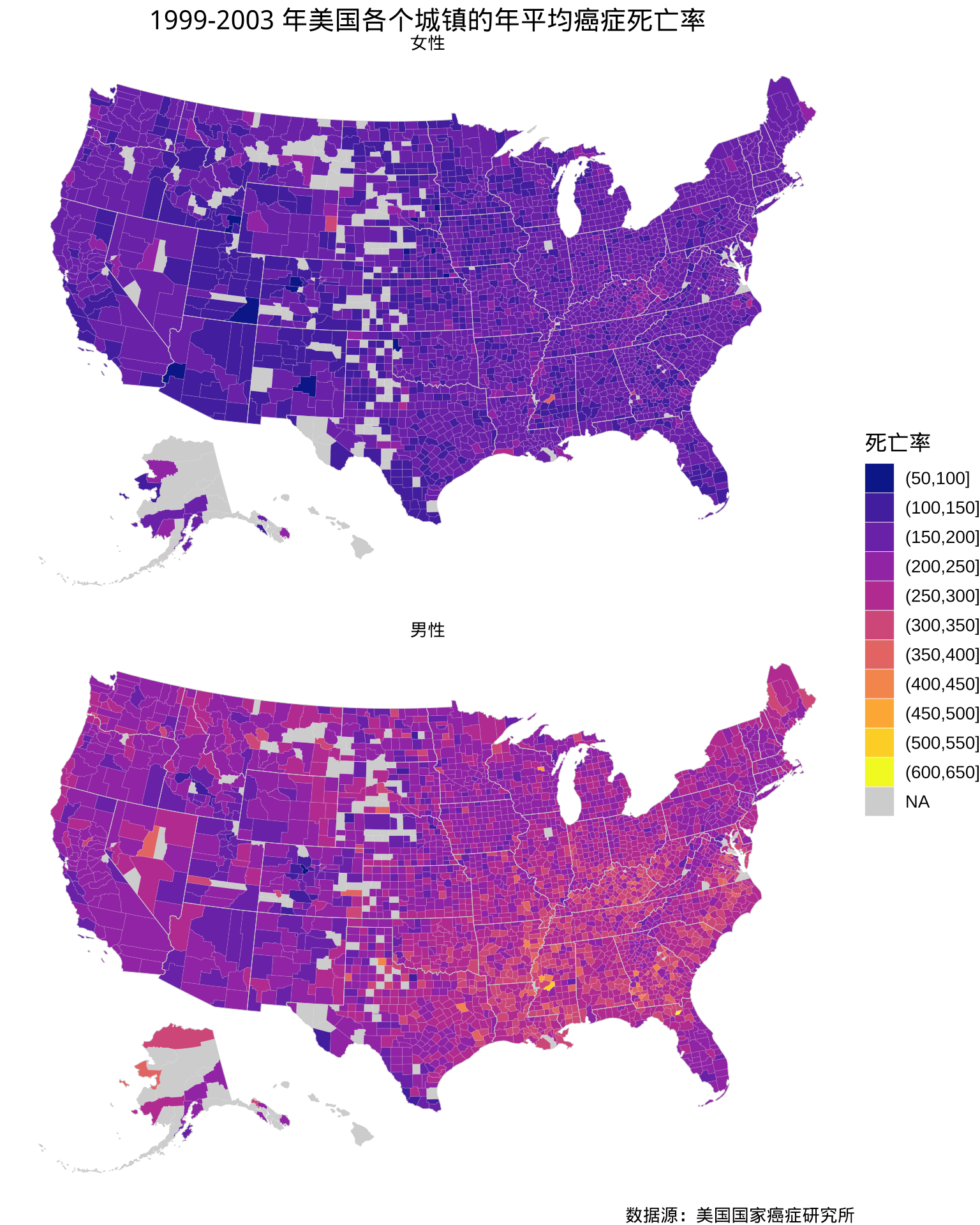
图 7: 1999-2003 年美国各个郡的年平均癌症死亡率分布
尽管已经调整了上图 7 的长宽比例,可一旦和非 ggplot2 绘制的图形对比,就可以看出明显变形了。
同 sf 包 (E. J. Pebesma 2018) 的绘图函数 plot() 一样,tmap (Tennekes 2018) 也是基于 Base R 图形系统,但使用语法更加贴合 ggplot2 包 (Wickham 2022),对空间数据可视化有更多专业支持,比如基于比例的符号 / 气泡图 (Tanimura, Kuroiwa, and Mizota 2006) 1 和基于二维核密度估计的热力图 (Tennekes 2018)。
tmap 支持 sp 包提供的 Spatial 类数据对象,也支持 sf 包提供的 Simple Features 类数据对象,后者是新一代更好的工具,因此接下来的示例都将基于 sf 包。首先从美国人口调查局下载州和郡级别的多边形边界数据,再类似 usmapdata 包对阿拉斯加、夏威夷和波多黎各做适当的调整,借助 tidycensus 包 (Walker and Herman 2022) 让这个过程变得容易,调整地图数据的代码与源文档放在一起,读者可自取。
# 准备地图数据
library(sf)
us_state_map <- readRDS(file = "data/us_state_map.rds")
us_county_map <- readRDS(file = "data/us_county_map.rds")
# 重命名 fips_codes 的 state 列为 state_abbr
fips_codes <- within(tidycensus::fips_codes, {state_abbr = state})
fips_codes <- subset(x = fips_codes, select = setdiff(colnames(fips_codes), "state"))
# 癌症死亡率数据关联州、郡代码 FIPS
us_cancer_rates <- merge(
x = us_cancer_rates,
y = fips_codes,
by.x = c("state", "county"),
by.y = c("state_name", "county"),
all.x = TRUE
)
# 合并地图数据和观测数据
us_county_cancer2 <- merge(
x = us_county_map, y = us_cancer_rates,
by.x = c("STATEFP", "COUNTYFP"),
by.y = c("state_code", "county_code"), all.x = TRUE
)准备好数据后,绘图过程比较类似之前使用 ggplot2 绘图,所不同的是,添加了指北针、比例尺等地区分布图特有的内容。
# 绘图
tmap::tm_shape(us_county_cancer2) +
tmap::tm_polygons(border.col = "gray") +
tmap::tm_shape(us_county_cancer2) +
tmap::tm_polygons(
col = "rate",
palette = "plasma", border.alpha = 0.2,
legend.reverse = TRUE, title = "死亡率",
colorNA = "gray",
textNA = "NA", border.col = "gray",
breaks = 50 * 0:13
) +
tmap::tm_facets(by = "sex", drop.NA.facets = T, ncol = 1) +
tmap::tm_shape(us_state_map) +
tmap::tm_polygons(col = NA, border.col = "gray", alpha = 0) +
tmap::tm_compass(position = c("right", "bottom")) +
tmap::tm_scale_bar(position = c("right", "bottom")) +
tmap::tm_credits(text = "数据源:美国国家癌症研究所", position = "left") +
tmap::tm_layout(
legend.outside = TRUE,
legend.outside.position = "right",
legend.outside.size = 0.15,
legend.format = list(text.separator = "~"),
outer.margins = 0,
asp = 0
)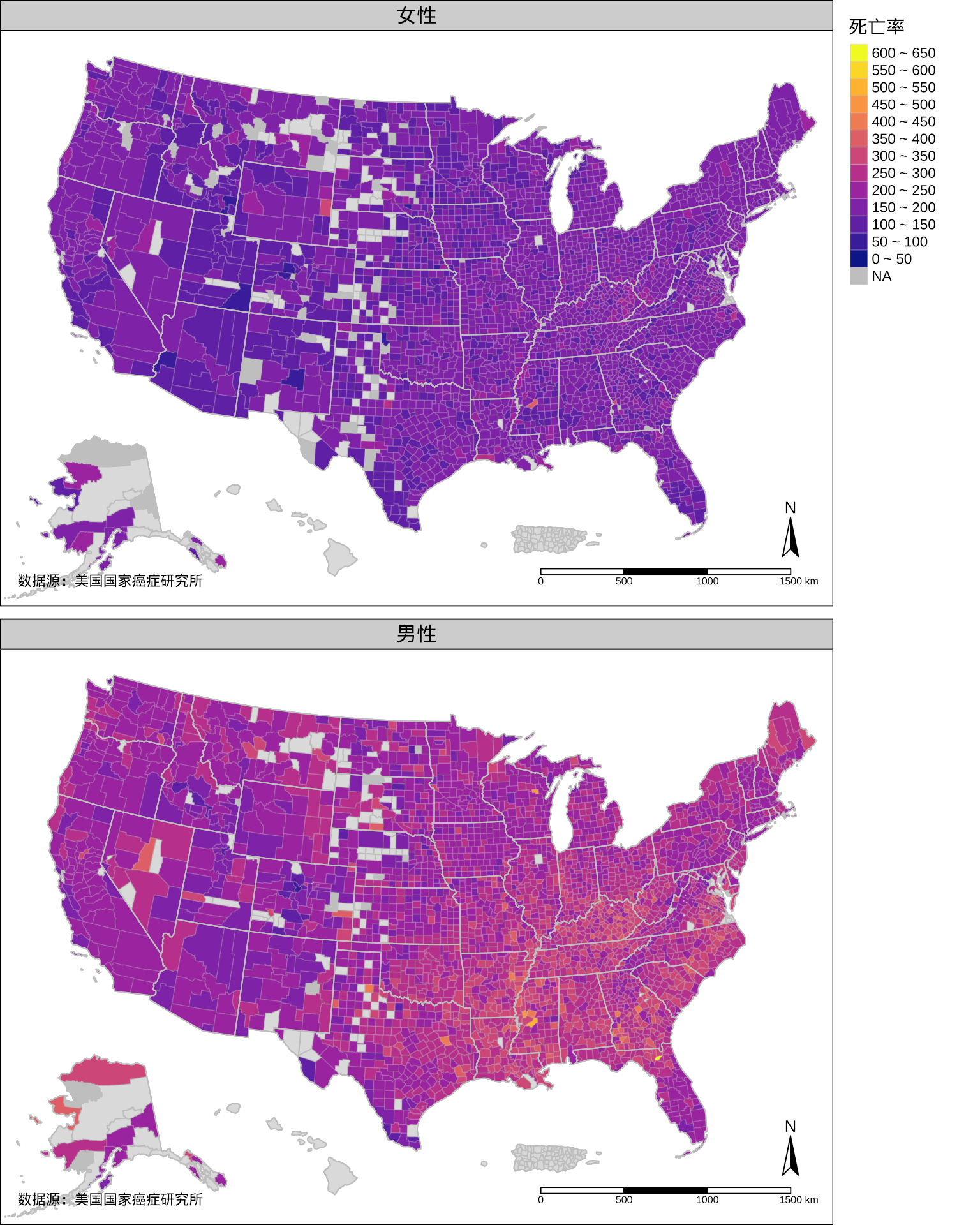
图 8: 1999-2003 年美国各个郡的年平均癌症死亡率分布
在上一节已经准备好了美国各个郡的边界数据,接下来合并各个郡的癌症死亡率数据 USCancerRates,调用 sf 包 (E. J. Pebesma 2018) 的绘图函数 plot()。除了调用函数 plot()的几行代码,绘制图 9 的代码和前面调用 maps 包绘图大体是类似的,但灵活性高得多,因 sf 包的强大,支持大量的空间数据存储格式,不受限于 maps 包内置的不完整地图数据,也不因给郡区域上色添加额外的数据匹配操作。
# 癌症死亡率数据关联州、郡代码
USCancerRates2 <- merge(
x = USCancerRates,
y = fips_codes,
by.x = c("state", "county"),
by.y = c("state_name", "county"),
all.x = TRUE
)
# 空间数据合并观测数据
us_county_cancer <- merge(
x = us_county_map, y = USCancerRates2,
by.x = c("STATEFP", "COUNTYFP"),
by.y = c("state_code", "county_code"),
all.x = TRUE
)
par(mar = c(0, 0, 4, 0), mfrow = c(2, 1))
# 添加郡地图
plot(st_geometry(us_county_map),
reset = FALSE, border = NA, col = "grey80", main = ""
)
# 添加癌症死亡率数据
plot(us_county_cancer["rate.male"],
pal = viridisLite::plasma, reset = FALSE, key.pos = NULL,
breaks = 50 * 0:13,
border = NA, lwd = 0.25, add = TRUE
)
# 美国各个州边界
plot(st_geometry(us_state_map), border = "gray80", lwd = 0.25, add = TRUE)
# 添加主标题
title(main = "1999-2003 年美国各个郡的年平均癌症死亡率", line = 2)
# 添加分面标题
mtext(text = "男性", side = 3, adj = 0.5)
# 调整边空
par(mar = c(1, 0, 2, 0))
plot(st_geometry(us_county_map),
reset = FALSE, border = NA, col = "grey80", main = ""
)
plot(us_county_cancer["rate.female"],
pal = viridisLite::plasma, reset = FALSE, key.pos = NULL,
breaks = 50 * 0:13,
border = NA, lwd = 0.25, add = TRUE
)
plot(st_geometry(us_state_map), border = "gray80", lwd = 0.25, add = TRUE)
mtext(text = "女性", side = 3, adj = 0.5)
mtext(text = "数据源:美国国家癌症研究所", side = 1, adj = 0)
# 调色板
colors <- viridisLite::plasma(13)
# 图例文本
leg.txt <- mapply(paste, 50 * 0:12, 50 * 1:13, collapse = " ", sep = "~")
# 添加图例
legend("bottomright",
legend = c(leg.txt, "NA"), title = "死亡率", box.col = NA, border = NA,
horiz = FALSE, fill = c(colors, "grey80"), cex = 0.85, xjust = 0.5
)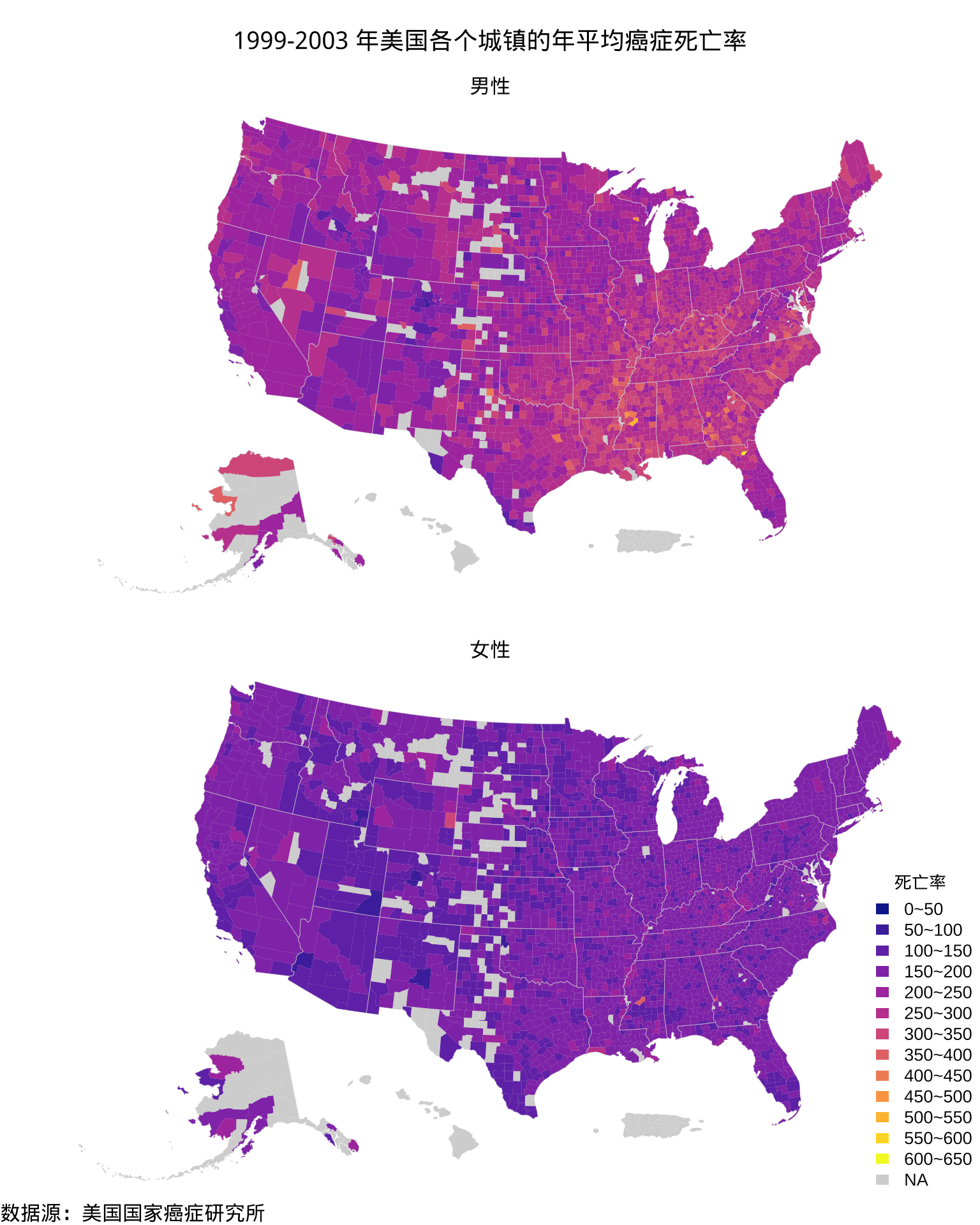
图 9: 1999-2003 年美国各个郡的年平均癌症死亡率分布
ggplot2 + sf
ggplot2 截止当前最新版本,ggplot2 在空间数据可视化都是非常不专业的,最糟糕的一个点是它会将地图弄变形了。 尽管 ggspatial (Dunnington 2021) 在 ggplot2 的基础上补充了一些地图特有的元素,如比例尺、指北针,但并没有解决地图变形的核心问题。正如 Roger Bivand 所言,还有其它可能难以预料的问题:
For visualisation, please avoid using ggplot2 unless you use this package often (daily). For thematic mapping, tmap and mapsf are to be preferred, because they are written for making maps. Do not simplify/generalise coastlines unless you really need to do so. You can use tmap and mapview to view thematic maps interactively - as you zoom in, you see artefacts created by line generalization.
因此,尽管 ggplot2 包已经流行开来,并且在很多方面取得成绩,但严格来说,不推荐使用 ggplot2 包来绘制任何和地图相关的图形,除非很清楚研究区域的情况,即在合适的地理区域采用合适的投影、合适的工具绘制准确的地理图形。ggplot2 在 2018 年发布 3.0.0 版本,开始借助 sf 包支持 Simple Features 数据对象的绘图,这就一定程度上缓解了地图变形的问题。
us_county_cancer2$rate_d <- cut(us_county_cancer2$rate, breaks = 50 * 0:13)
ggplot() +
geom_sf(
data = us_county_map,
fill = I("grey80"), colour = NA
) +
geom_sf(
data = us_county_cancer2[!is.na(us_county_cancer2$sex), ],
aes(fill = rate_d), colour = alpha("white", 1 / 4), size = 0.1
) +
geom_sf(
data = us_state_map,
colour = alpha("gray80", 1 / 4), fill = NA, size = 0.15
) +
scale_fill_viridis_d(option = "plasma", na.value = "grey80") +
coord_sf(crs = st_crs("ESRI:102003")) +
facet_wrap(~sex, ncol = 1) +
labs(
fill = "死亡率", title = "1999-2003 年美国各个郡的年平均癌症死亡率",
caption = "数据源:美国国家癌症研究所"
) +
theme_void(base_size = 13) +
theme(plot.title = element_text(hjust = 0.5))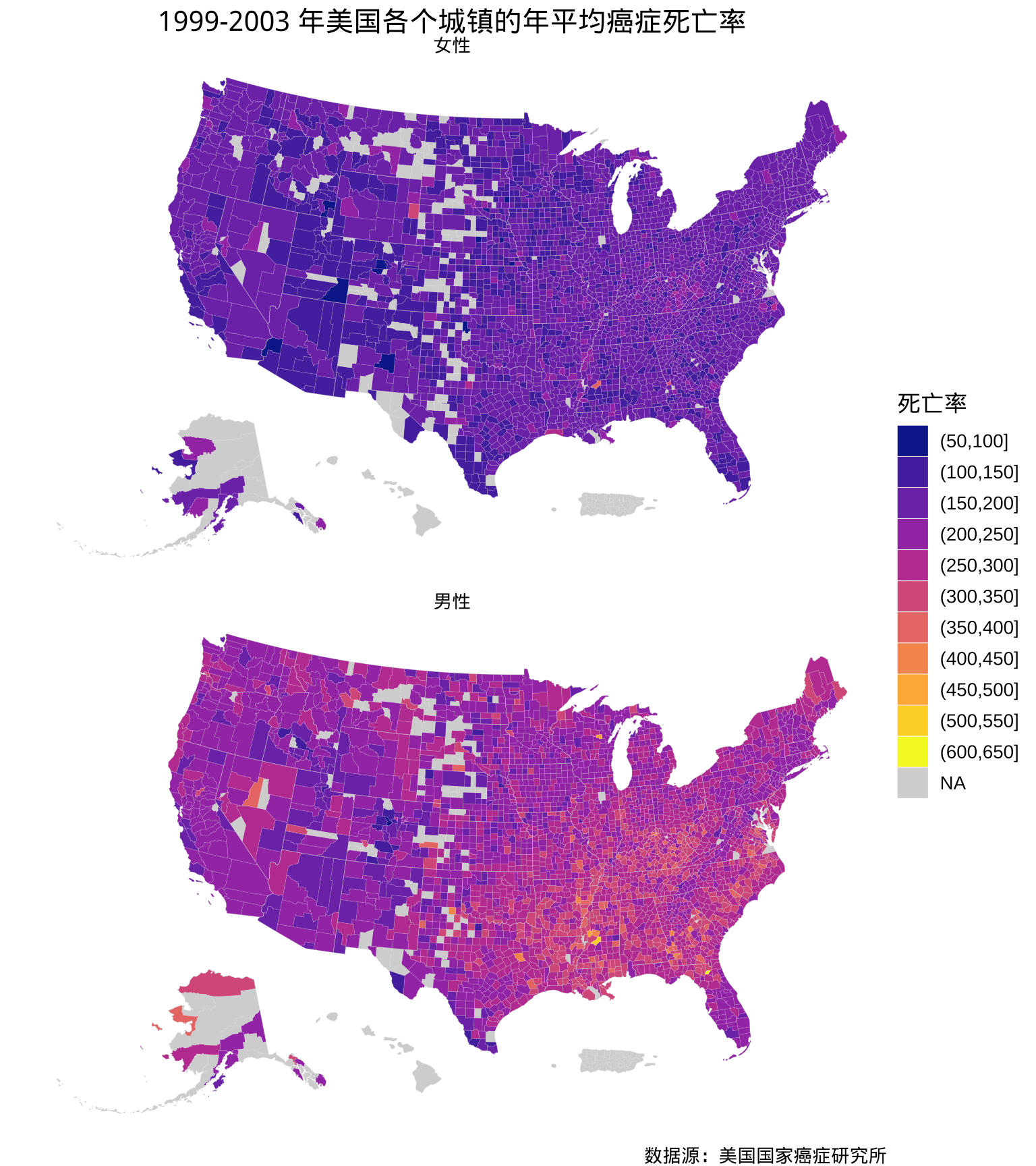
图 10: 1999-2003 年美国各个郡的年平均癌症死亡率分布
mapsf
如 Roger Bivand 所推荐,下面介绍 mapsf 包 (Giraud 2022),它在 sf 包的基础上添加更多地理可视化的功能,比如指北针、比例尺、三维特效等,同时也支持比例符号图、地区分布图及其混合地图。mapsf 绘图思路和 sf 是一致的,只是封装了一些更加便捷的绘图函数,如图 11 所示,大体分三步:其一准备主题样式,配色、布局等;其二表达地理数据,选择合适的图形,建立数据到地图的映射;其三补充一些说明,如注释、比例尺、标题等。
library(mapsf)
par(mfrow = c(2, 1))
# 设置主题
mf_theme("default", inner = TRUE, tab = TRUE, pos = "center")
# 绘制地图
mf_map(
x = us_county_cancer,
var = "rate.male",
type = "choro",
breaks = 50 * 0:13,
pal = "Plasma",
border = "gray",
lwd = 0.5,
leg_val_rnd = 0,
leg_pos = "left",
leg_no_data = "NA",
leg_title = "死亡率\n(每10万人)"
)
# 指北箭头
mf_arrow(pos = "topleft")
# 比例尺
mf_scale(pos = "bottomleft")
# 标题
mf_title(txt = "男性", bg = "#f7f7f7", fg = "black", cex = 1)
# 出处
mf_credits(txt = "数据源:美国国家癌症研究所", pos = "bottomright", cex = 1)
mf_map(
x = us_county_cancer,
var = "rate.female",
type = "choro",
breaks = 50 * 0:13,
pal = "Plasma",
border = "gray",
lwd = 0.5,
leg_val_rnd = 0,
leg_pos = "left",
leg_no_data = "NA",
leg_title = "死亡率\n(每10万人)"
)
mf_arrow(pos = "topleft")
mf_scale(pos = "bottomleft")
mf_title(txt = "女性", bg = "#f7f7f7", fg = "black", cex = 1)
mf_credits(txt = "数据源:美国国家癌症研究所", pos = "bottomright", cex = 1)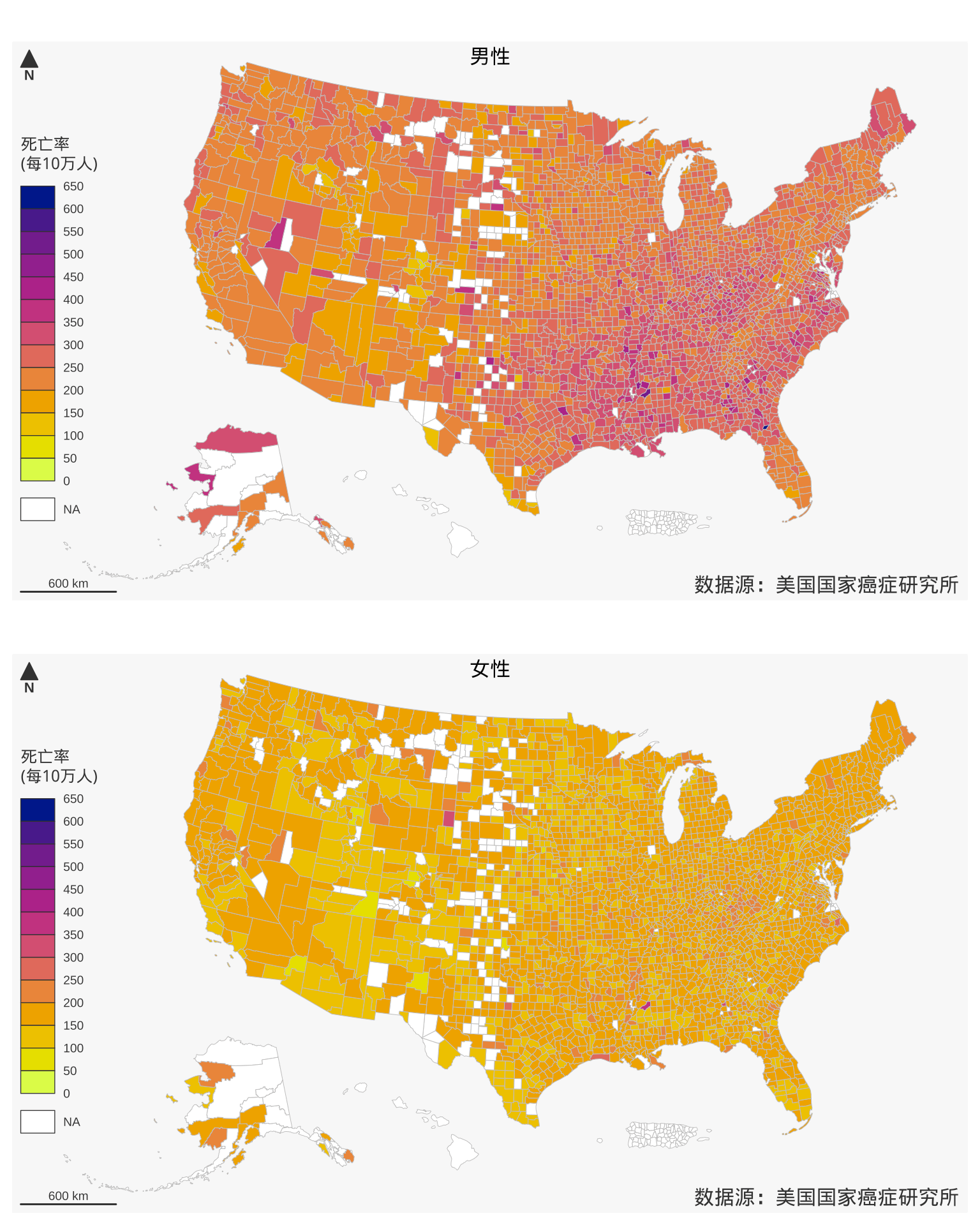
图 11: 1999-2003 年美国各个郡的年平均癌症死亡率分布
mapsf 包函数 mf_map() 的参数 pal 可取自 R 内置的调色板 hcl.pals(),共计 115 个。设置调色板的内部函数 mapsf:::get_the_pal() 将原调色板 hcl.colors() 反向了,导致图 11 的整个配色和之前的图形有所不同,但这并不妨碍图形的准确性和美观性。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK