

缓存和数据库一致性探讨,理解CAP理论
source link: https://petrie.github.io/2022/05/%E7%BC%93%E5%AD%98%E5%92%8C%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%80%E8%87%B4%E6%80%A7%E6%8E%A2%E8%AE%A8%E7%90%86%E8%A7%A3cap%E7%90%86%E8%AE%BA/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

缓存和数据库一致性探讨,理解CAP理论
文章
缓存和数据库一致性探讨,理解CAP理论
2022 五月 22日
从用户信息查询开始
用户信息的存储是大家较为熟悉的场景,为了实现用户信息存储的基本功能。 我们需要将数据存入数据库。
查询的时候select。更新的时候update。
什么时候查询缓存?什么时候更新缓存 ?
当并发起来后,数据库的并发性能有限。这个时候就需要引入缓存慢,在查询时优先查缓存,以缓解数据库压力。 引入缓存,需要考虑一下两个问题:
- 1、什么时候查询缓存
- 2、什么时候更新缓存
1、什么时候查询缓存?
首先看第一个问题:什么时候查询缓存,既然我们要提升查询请求的性能,当然是在查询数据库之前先查询缓存,如果缓存有数据则直接返回,见下图1.1。这样的话才能将大部分的请求拦在数据库之外,提升接口性能。

2、什么时候更新缓存?
第二个问题:什么时候更新缓存,这里有几个时机可以选择
- 1、在更新逻辑中,直接将最新的数据存入缓存
- 2、在查询逻辑中,查到数据库的数据后存入缓存
如果查询和更新请求量都很小,且是顺序请求的。选择任何时机都没有问题,但是在真实的业务场景中,顺序请求这是不可能的。 真实业务场景中,查询和更新请求必然是并发的,那么上面两种处理方式会分别会产生什么问题呢? 我们一个个看。
2.1在更新逻辑中,直接将最新的数据存入缓存
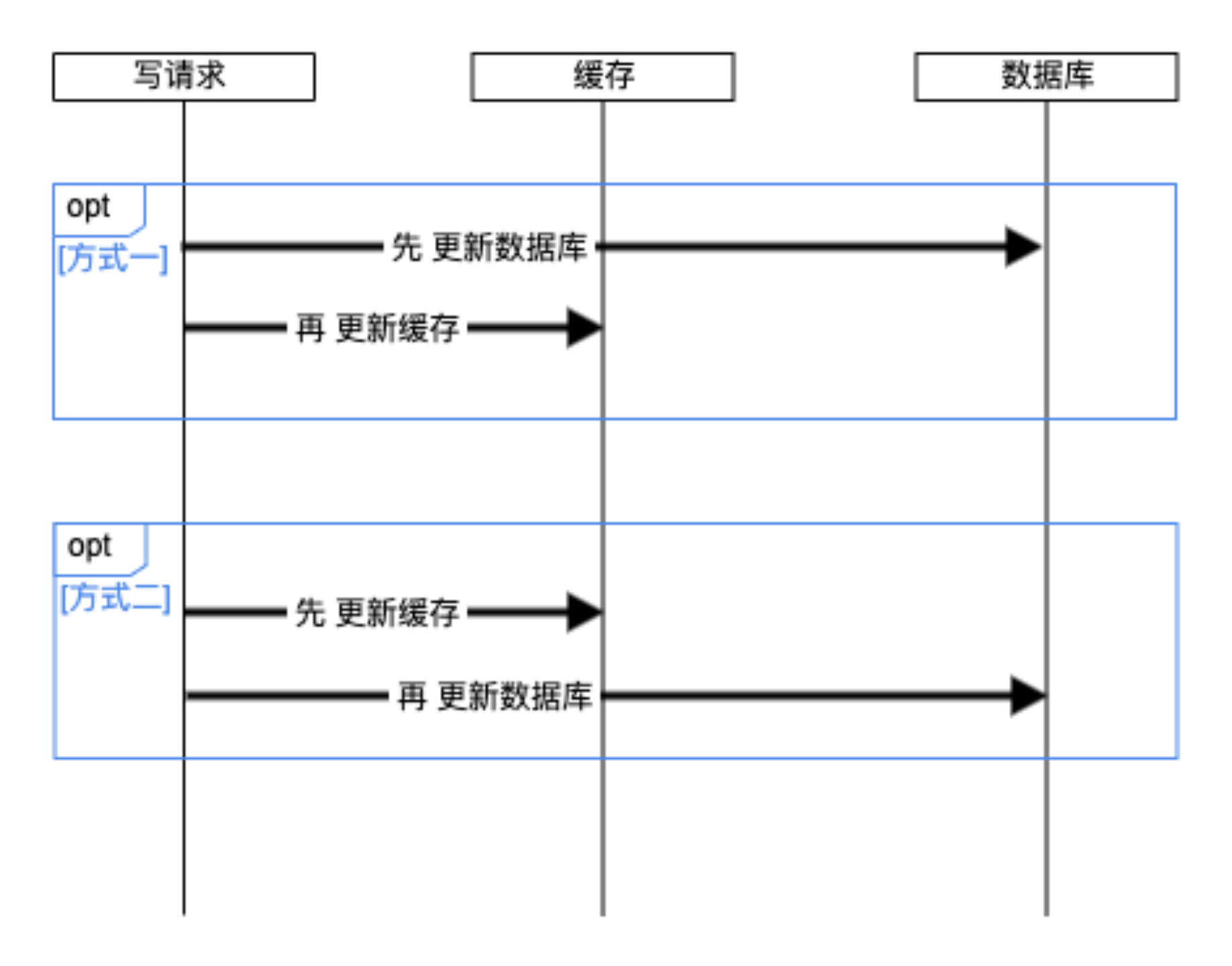
先来看“在更新逻辑中,直接将最新的数据存入缓存”。按照更新数据库、缓存的顺序我们有两种处理方式:
- 2.1.1、先更新缓存再更新数据库
- 2.1.2、先更新数据库再更新缓存
该如何选择呢?两种方案都有如下逻辑:如果第一步失败,很简单直接返回报错。
如果第二部失败呢,就需要回滚第一步操作。 是否能成功回滚呢?
先看选项1:“先更新缓存再更新数据库”。 如果在第二步更新数据库失败, 需要回滚第一步,但第一步是缓存无法回滚。 所以无法保证一致性。
在看选项2:“先更新数据库再更新缓存”。如果在第二步更新缓存失败,数据库是可以回滚的。 但是缓存的更新失败可能有多种原因。如果是因为网络超时,此时我们无法确定缓存更新是否成功,也就无法判断是否需要回滚数据库。 此选项也无法保证一致性。
所以无论是”先更新缓存再更新数据库“,还是 ”先更新数据库再更新缓存“。 都无法保证数据库和缓存的一致性。
2.2 在查询逻辑中,查到数据库的数据后存入缓存
在1.2.1的论述中,是无法保证数据库和缓存的一致性的。 我们继续往后看,如果选择“在查询逻辑中,查到数据库的数据后存入缓存”。
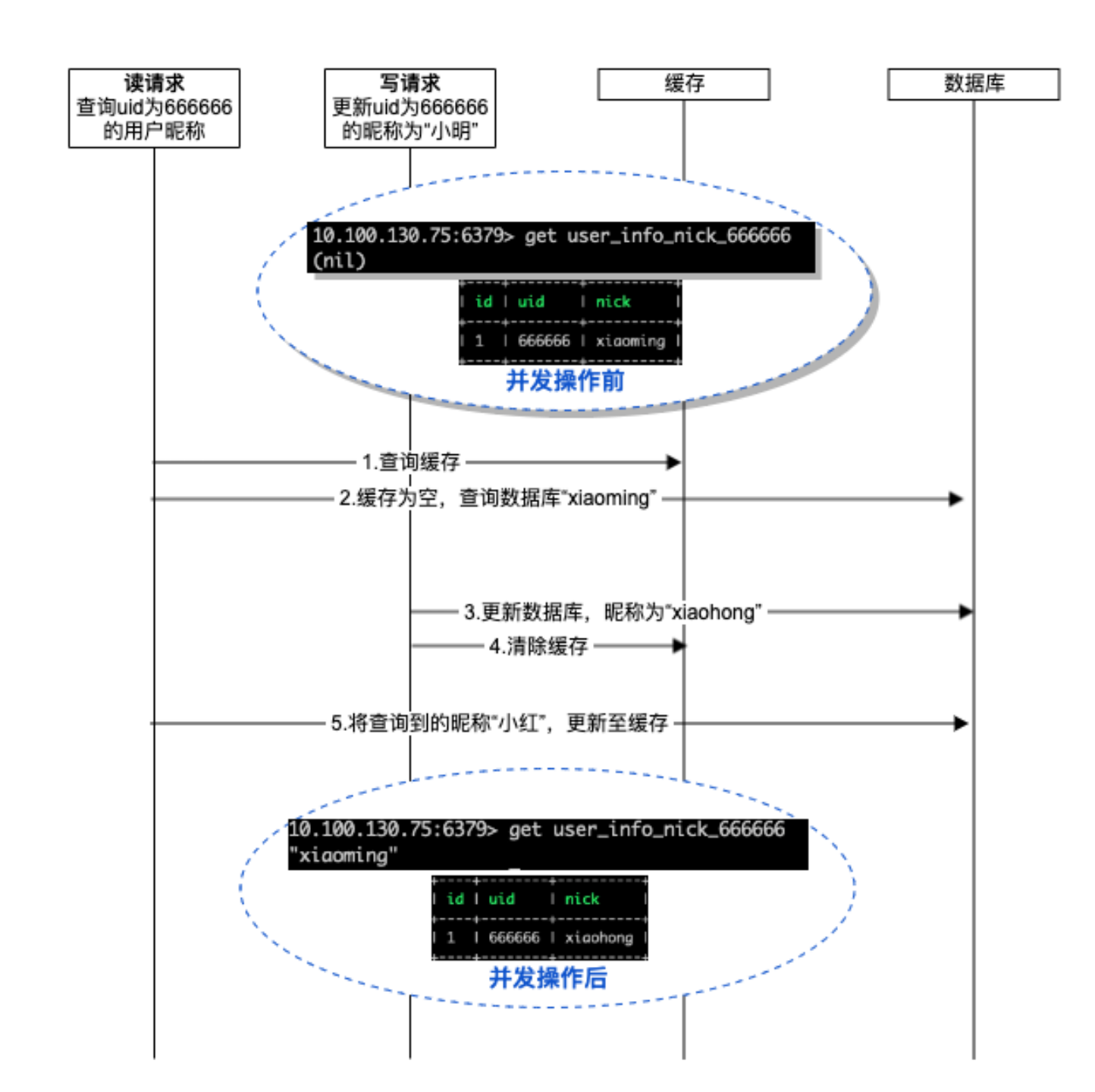
此方案在查询时,优先查询缓存,如果缓存有数据则直接返回缓存中的数据,如果缓存没有数据,则直接查询数据库。查询成功后再放入缓存。图示如下:
单从查询操作来看,这个过程中我们只会更新缓存数据,如果更新成功,则缓存数据自然与数据库中一致。如果不成功,则缓存数据不生效,不会有一致性问题。
下面我们结合更新操作一起看,我们在更新操作中要做哪些处理呢?很容易想到要在更新操作的时候讲缓存删除。
乍看好像没问题了,更新操作时清理缓存,查询操作时写入缓存。这里暂时不讨论缓存清理失败的问题,因为有更严重的问题。
考虑下面的场景,如下图:
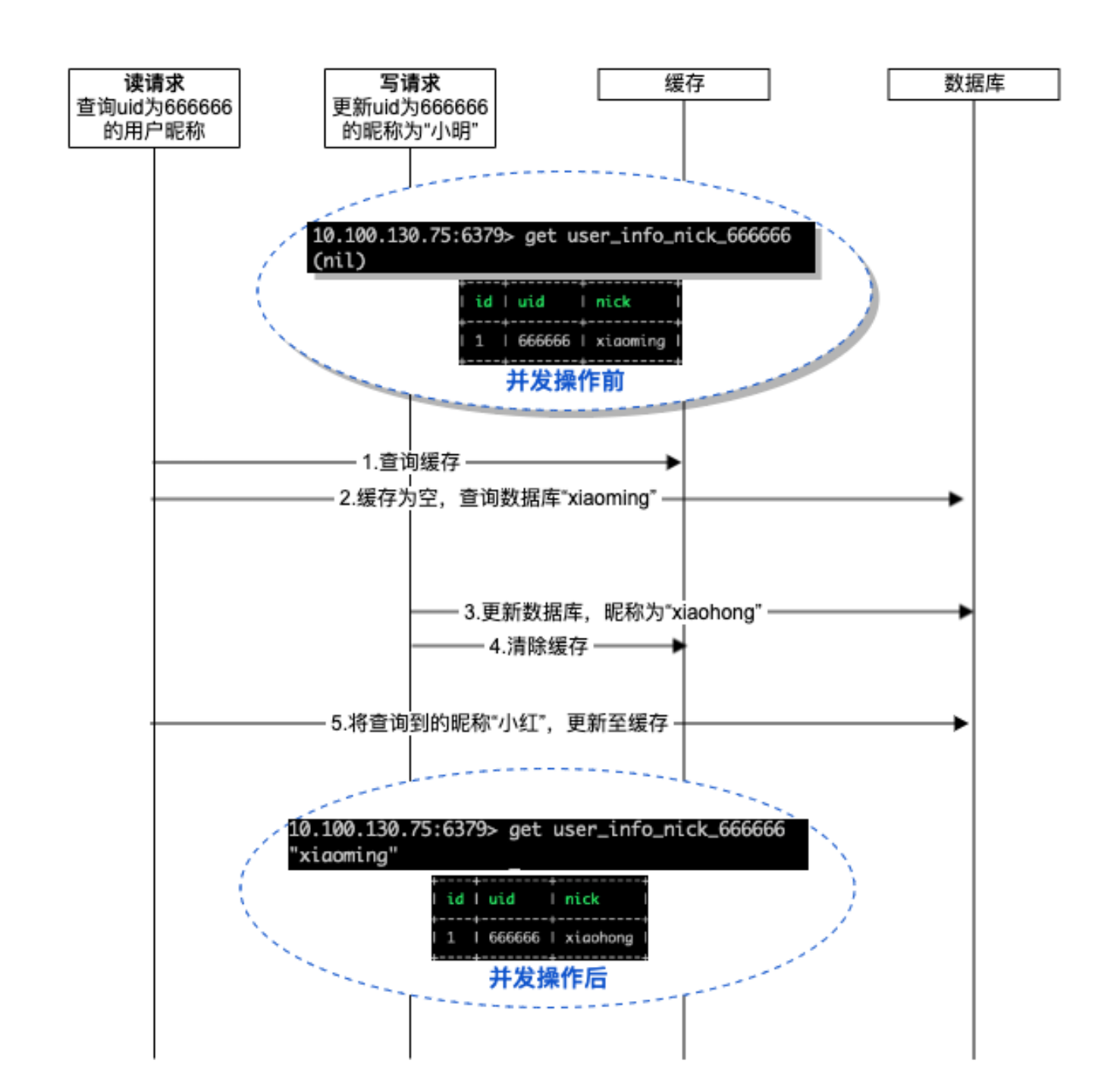
查询操作成功查询数据库但还未写入缓存,此时更新操作来了,并且它更快,更新了数据库并清理了缓存。在这之后查询操作继续,将刚刚查询成功的数据存入了缓存。此时,数据库和缓存数据完全不一致了。下次查询操作来的时候,发现缓存有数据,就把缓存的老数据库直接返回了。
有同学会说此类问题发生概率很小。但是还是有可能发生的。比如:批量查询,或者存入缓存前要做预处理。
缓存一致性小结
- 1.2.1 在更新逻辑中,直接将最新的数据存入缓存
- 1、先更新缓存再更新数据库
- 2、先更新数据库再更新缓存
- 1.2.2 在查询逻辑中,查到数据库的数据后存入缓存
按照不同的数据库、缓存更新时机和策略,我们尝试了很多方法,一致性的问题都解决不了。是不是根本就无法解决呢?
引出CAP
这里就引出下一个话题:CAP
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
- Consistency 一致性
- Availability 可用性
- Partition tolerance 分区容错
先看 Partition tolerance,中文叫做"分区容错"。 分区容错的意思是,区间通信可能失败。我们借助缓存一致性的例子去理解。 上述有例子三个角色,“业务服务”、”缓存“,“数据库”。他们分属于不同的服务器。因为中间跨网络,业务服务、缓存、数据库之间的通信都有可能失败。总的来说,在任何分布式系统中,任何两个节点都可能无法通讯。 因此可以认为CAP的P总是成立的。 CAP定理告诉我们,剩下的C和A无法同时做到。
我们一个个看,如何保证C。还是回到我们最初的讨论,尝试了很多方案,没有一个能保证一致性。 那么真的就没有办法吗? 其实在上面我们有做过简单的讨论,“如果查询和更新请求量都很小,且是顺序请求的。” 一致性是可以保证的。 那么我们如何保证请求是顺序的呢?拿最后一个方案todo举例,我们可以引入分布式锁,在更新操作前锁定,完成后释放,那么在读请求的时候,如果拿不到锁,则一直循环等待,直到拿到锁后再继续。这样就可以严格保证顺序了,也就保证了一致性保证了C。这个方案有个显而易见的问题,因为查询的时候有可能阻塞等待,需要等待锁的时候接口会很慢。这也就是我们保证C的代价:牺牲了A
尝试解决P的问题
拿最近做的需求举例,男女配对系统,包含匹配和调度两部分。匹配部分需求是:男女同时发起匹配,则将其达成关系。 调度部分的需求是:如果系统中只有一方发起匹配,那么需要查询一定数量的在线用户,发出匹配邀请。两部分需求典型的耦合场景是:在调度部分发出调度后,男女用户在匹配系统达成了关系,需要将匹配邀请取消。
设计上我们有两个选择,第一个选择是: 将匹配和调度逻辑完全隔离为两个服务。 匹配和调度逻辑通过接口或kafka通讯。这样的设计匹配和调度可以理解为分布式系统的两个分区,CAP理论指导我们,这两部分的数据是不可能同时满足AC的。 因为两个系统需要跨网络相互通讯,必然无法满足P。 那么在AC中我们只能选择其一,要么满足A,要么满足C。 至于如何满足,留给各位自行自考。
这里我们讨论下,如何让系统满足P。 如果我们将匹配和调度分布逻辑放在一起,通过数据库事务保证两边的数据完全一致。还是上面典型场景:在调度部分发出调度后,男女用户在匹配系统达成了关系,需要将匹配邀请取消。 我们将匹配和调度数据的处理,放在同一个数据本地事务中,那么也就没有多个分区了,自然也就没有了P的问题。但在这个场景下系统已经不是分布式系统了,CAP已经不再适用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK