

Analyzing The activation functions of common neural networks
source link: https://onepagecode.substack.com/p/analyzing-the-activation-functions?r=19p4do&s=r
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Analyzing The activation functions of common neural networks
It is important to choose function activation for hidden and output layers that are differentiable when constructing Artificial Neural Networks (ANN). As a result, to calculate the backpropagated error signal necessary to determine ANN parameter updates, it is necessary to know the gradient of the activation function gradient. Identity functions, logistic sigmoid functions, and hyperbolic tangent functions are three of the most common activation functions used in ANNs. In Figure 1, examples of these functions and their derivatives (in one dimension) are shown.
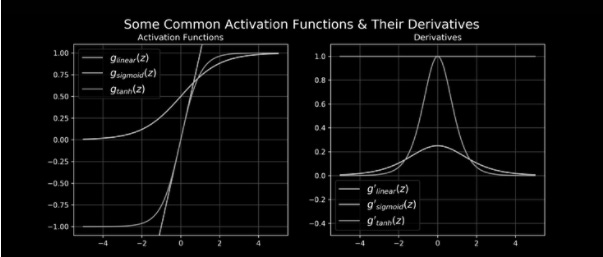
This post will show the derivatives and gradients of the four common activation functions.
The Identity Activation Function
Activation functions that are commonly used in regression problems, such as the output layer activation function, are identity/linear functions:
Preactivation is just mapped to this activation function, so it can output values between (−∞,∞). What is the purpose of making use of an identity activation function? Multilayered networks with linear activations can be conceptualized in the same way as one-layered linear networks. The identity activation function turns out to be quite useful.
In particular, a multilayer network using nonlinear activation functions on hidden units and identity activation functions on the output layer implements a powerful form of nonlinear regression. A linear combination of signals is used to predict continuous target values as a result of nonlinear transformations of the input.

Logistic Sigmoidal Activation Function
In binary classification problems, the logistic sigmoid is often used (Figure 1, blue curves) as the output activation function. The logistic sigmoid looks like this:
The output ranges between 0 and 1. An artificial neuron’s firing probability can be interpreted as the logistic sigmoid’s motivation in part from biological neurons. There is also a maximum likelihood solution for logistic regression that can be derived from the logistic sigmoid in statistics). Adding and subtracting one from the numerator is used to calculate the logistic sigmoid function.
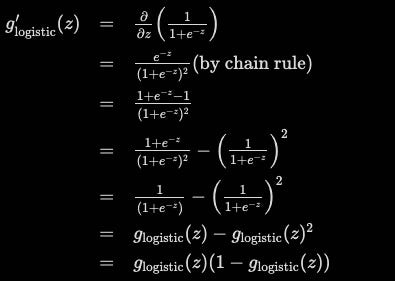
If one keeps in memory the feed-forward activations for each layer, this form proves to be a convenient way to calculate gradients in neural networks. By using simple multiplication and subtraction, gradients for that layer can be calculated instead of reevaluating the sigmoid function, which requires additional exponentiation.
Function for activating hyperbolic tangents
It turns out that the logistic sigmoid can cause a neural network to get “stuck” during training, despite it having a very biological interpretation. In part, this can be explained by the fact that if a strongly-negative input is applied to the logistic sigmoid, the output will be very close to zero. Due to the fact that neural networks use feed-forward activations to calculate parameter gradients, they may not update model parameters as often as we would like them to, which leaves them “stuck” in their current state.
Hyperbolic tangents, or tanhs, are an alternative to logistic sigmoids.
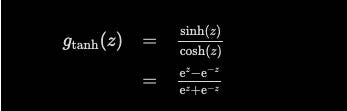
In the same way as the logistic sigmoid, the tanh function also produces sigmoidal (“s”-shaped) values, but instead, they range between (0,1). So the tanh will produce negative outputs when the input is strongly negative. The outputs are also mapped to near-zero values only for zero-valued inputs. These attributes ensure that the network won’t get “stuck” during training. For the tanh function, the gradient is also calculated using the quotient rule:
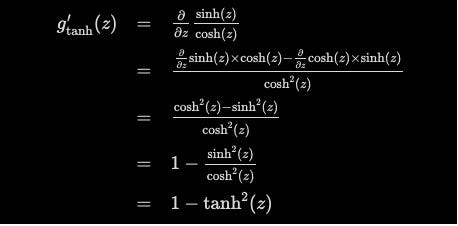
As with the derivative for the logistic sigmoid, the derivative for gtanh(z) corresponds to an evaluation of feed-forward activation at z, namely (1−gtanh(z)2). The same caching technique applies to layers that implement tanh activation functions.
Concluding
Our objective here was to review some common activation functions in the literature and their derivatives. In addition to providing some useful implementation tricks like cached feed-forward activation values, these activation functions are motivated by biology. In addition to the activation functions covered here, there are several other options, such as rectification, soft rectification, polynomial kernels, etc. In fact, machine learning research is focused on identifying and evaluating new activation functions. It is however worth noting that the three basic activations presented here can be used by a majority of machine learning problems.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK