

Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert - 风雨中的小七
source link: https://www.cnblogs.com/gogoSandy/p/16265469.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert
Albert是A Lite Bert的缩写,确实Albert通过词向量矩阵分解,以及transformer block的参数共享,大大降低了Bert的参数量级。在我读Albert论文之前,因为Albert和蒸馏,剪枝一起被归在模型压缩方案,导致我一直以为Albert也是为了优化Bert的推理速度,但其实Albert更多用在模型参数(内存)压缩,以及训练速度优化,在推理速度上并没有提升。如果说蒸馏任务是把Bert变矮瘦,那Albert就是把Bert变得矮胖。最近写的文本分类库里加入了Albert预训练模型,有在chinanews上已经微调好可以开箱即用的模型,感兴趣戳这里SimpleClassification
Albert主要有以下三点创新
- 参数共享:降低Transfromer Block的整体参数量级
- 词向量分解:有效降低词向量层参数量级
- Sentence-Order-Prediction任务:比NSP更加有效的学习句间关系
下面我们分别介绍这三个部分
词向量分解
其实与其说是分解,个人觉得词向量重映射的叫法更合适一些。在之前BERT等预训练模型中,词向量的维度E和之后隐藏层的维度H是相同的,因为在Self-Attention的过程中Embedding维度是一直保持不变的,所以要增加隐藏层维度,词向量维度也需要变大。但是从包含的信息量来看,词向量本身只包含上下文无关的信息,并不需要像隐藏层一样存储大量的上下文语义,所以相同维度的限制在词向量部分存在一定的参数冗余。所以作者对词向量做了一层映射,词向量本身的参数变成Vocab * E,映射层是E* H,这样本身的复杂度O(Vocab * H),就降低成了O(Vocab * E + E*H ),相当于把隐藏层大小和词向量部分的参数做了解耦。
这个Trick其实之前在之前的NER系列中出现过多次,比如用在词表增强时,不同词表Embeeding维度的对齐,以及针对维度太高/太低的词表输入,进行适当的降维/升维等等~
以下作者分别对比了在参数共享/不共享的情况下,词向量维度E对模型效果的影响,从768压缩到64,非共享参数下有1个点的下降,共享参数时影响较小。这个在下面参数共享处会再提到,和模型整体能处理的信息量级有一定关系,整体上在共享参数的设定下词向量压缩影响有限~
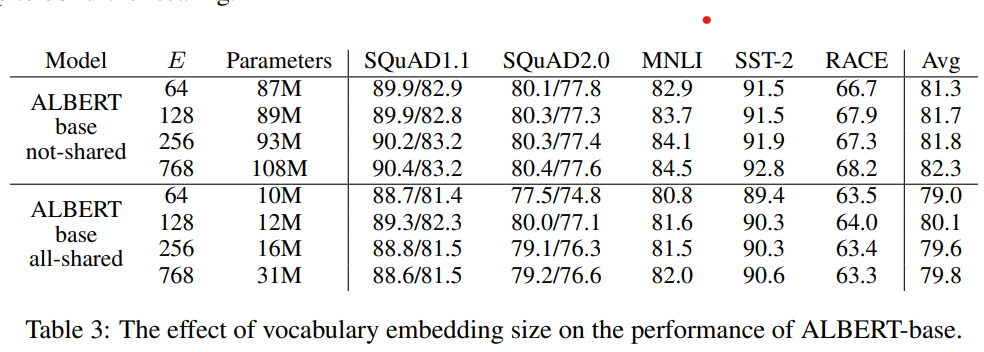
参数共享是ALbert提高参数利用率的核心。作者对比了各个block只共享Attention,只共享FFN,和共享所有参数,结果如下~
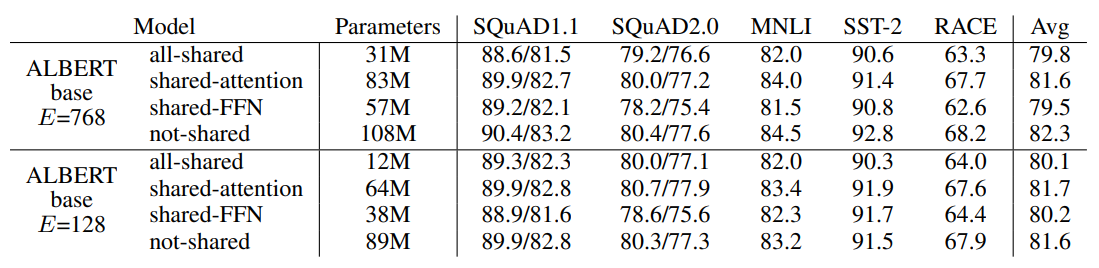
共享参数多少都会影响模型表现,其中效果损失主要来自共享FFN参数。以及在压缩词向量之后,共享参数带来的影响会降低。这里感觉和之前在做词表增强时观察到的现象有些相似,也就是模型的天花板受到输入层整体信息量的影响,因为压缩了词向量维度,限制了输入侧的信息量,模型需要处理的信息降低,从而参数共享带来的损失影响也被降低了
最终作者的选择更多是for最大程度压缩参数量级,share attenion缩减的参数有限,索性就共享了全部的参数。
在第三章讲到Roberta的时候,提到过Roberta在优化Bert的训练策略时,提出NSP任务没啥用在预训练中只使用了MLM目标。当时就提到NSP没有用一定程度上是它构造负样本的方式过于easy,NSP中连续上下文为正样本,从任意其他文档中采样的句子为负样本,所以模型可以简单通过topic信息来判断,而这部分信息基本已经被MLM任务学到。Albert改良了NSP中的负样本生成方式,AB为正样本,BA为负样本,模型需要判别论述的逻辑顺序和前后句子的合理语序。
作者也进行了对比,在预训练任务上,加入NSP训练的模型在SOP目标上和只使用MLM没啥区别,这里进一步证明了NSP并没有学到预期中的句子关联和逻辑顺序,而加入SOP训练的模型在NSP上表现要超过只使用MLM。在下游依赖上下文推理的几个任务上,加入SOP的模型整体表现略好。不过差异没有想象中的明显,感觉在如何构建负样本上应该还有优化的空间。个人感觉只是AB,BA的构造方式可能有些过于局部了

Albert在以上三点改良之外,在训练中也进行了一些优化,例如使用了SpanBert的MASK策略,用了LAMB optimizer来加速训练等等,Albert总共放出了以下几种参数的模型,和BERT之间的效果对比如下~
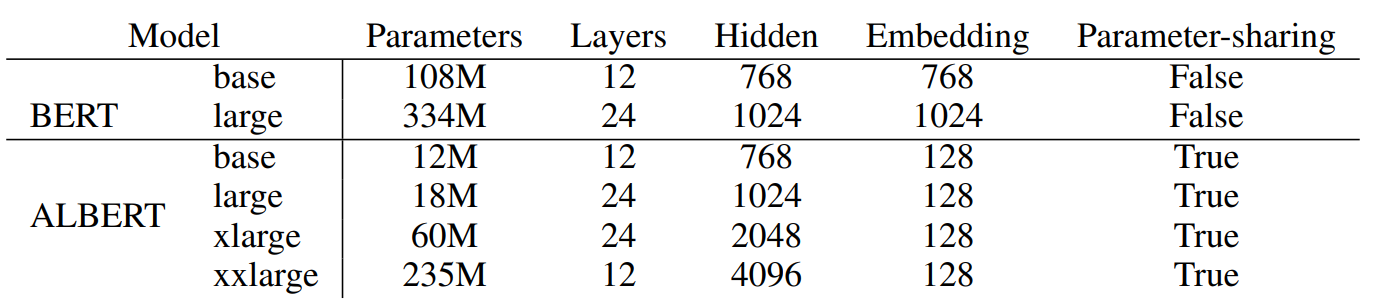
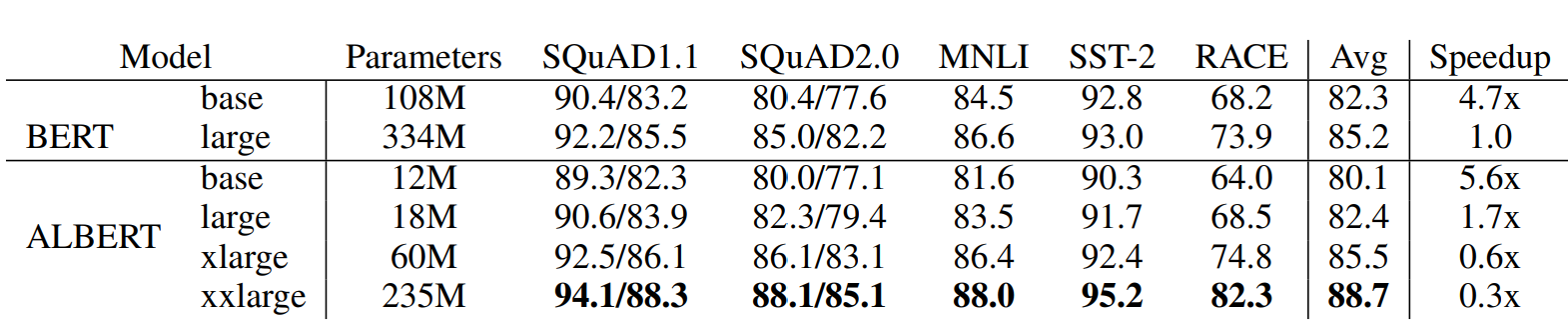
需要注意最后一列是训练速度的对比哈,哈哈之前看paper没带脑子,想都没想就给当成了推理速度,琢磨半天也没明白这为啥就快了???
- 直接base和base比,large和large比:参数可以压缩到1/10,适合大家自己跑来玩玩,整体模型大小甚至比一些词表大的词向量模型还要小,训练速度上也有提升但是模型效果都有2个点以上的损失,以及因为层数没变,所以推理速度不会更快,以及因为词向量分解的原因多了一层,所以还会略慢些
- 相似表现对比:ALbert xlarge和Bertlarge对比,都是24层,xlarge的隐藏层是bert的两倍,这里也是为啥说albert是矮胖,因为参数共享所以加层数效果有限,只能增加隐藏层维度。虽然albert xlarge参数压缩到1/5,但是训练更慢,推理也更慢
- 超越Bert:Albert xxlarge虽然只有12层,但是4倍的隐藏层还是让它的表现全面超越了Bert large,参数压缩到2/3,但是训练速度更更慢,以及超大隐藏层会导致计算中中间变量的存储过大,一般机子跑不动。。。
所以整体感觉albert的实际应用价值比较有限的,但是提出的两个点还有进一步深挖的价值,其一NSP任务负样本是否有进一步改造的空间,其二如何更有效地利用Bert的参数?
Reference
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK