
8

Python爬虫编程思想(145):使用Scrapy Shell抓取Web资源
source link: https://blog.csdn.net/nokiaguy/article/details/124694521
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Python爬虫编程思想(145):使用Scrapy Shell抓取Web资源
Scrapy提供了一个Shell,相当于Python的REPL环境,我们可以用这个Scrapy Shell测试Scrapy代码。
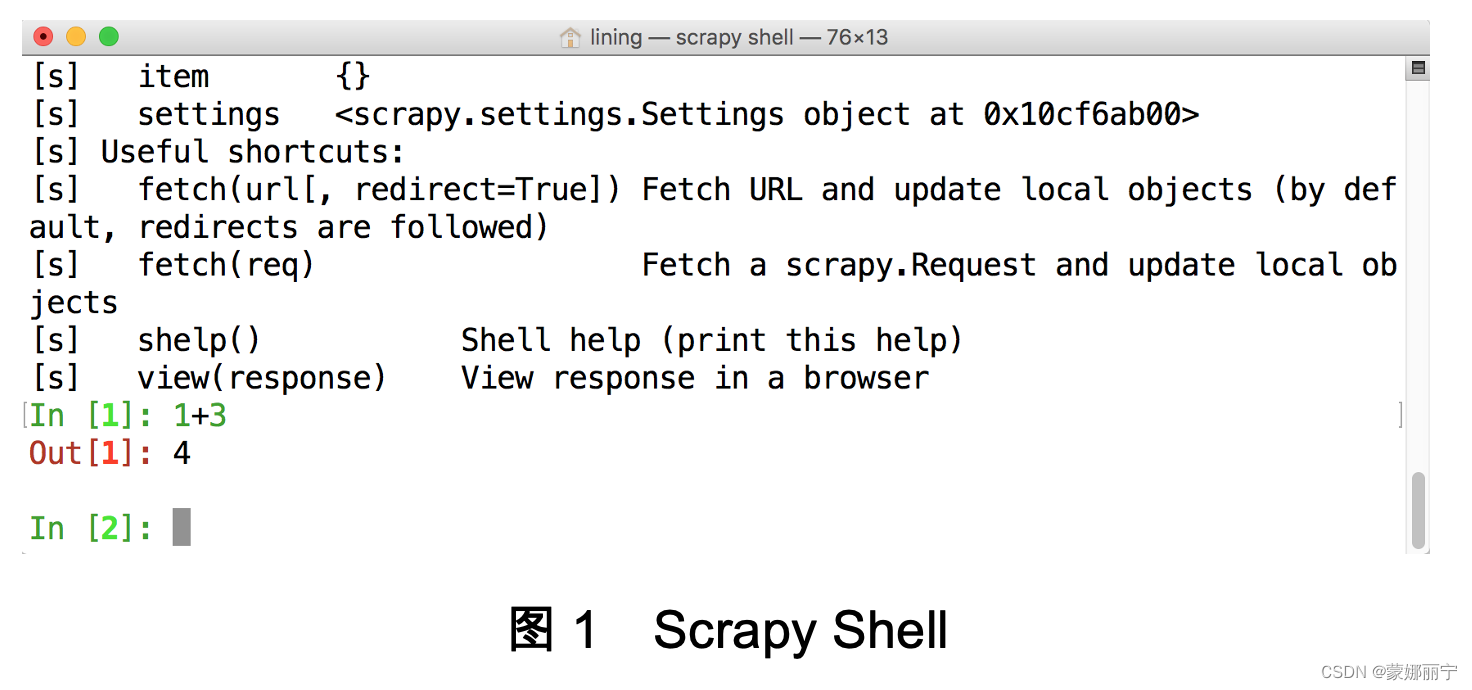
现在打开终端,然后执行scrapy shell命令,就会进入Scrapy Shell。其实Scrapy Shell和Python的REPL环境差不多,也可以执行任何的Python代码,只是又多了对Scrapy的支持,例如,在Scrapy Shell中输入1+3,然后按回车,会输出4,如图1所示。
Scrapy主要是使用XPath过滤HTML页面的内容。那么什么是XPath呢?也就是类似于路径的过滤HTML代码的一种技术,关于XPath的内容后面再详细讨论。本节基本不需要了解XPath就可以使用,因为Chrome可以根据HTML代码的某个节点自动生成XPath。
现在先体验下什么叫XPath。启动Chrome浏览器
文章知识点与官方知识档案匹配,可进一步学习相关知识
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK