

去哪儿网MySQL日志分析实践,80%数据丢失都给你救回来!
source link: https://dbaplus.cn/news-11-4456-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

去哪儿网MySQL日志分析实践,80%数据丢失都给你救回来!
一、背景
日志记录了一个系统的行为,对于了解系统、诊断问题、辅助审计等都有极其重要的作用。通常最近一段时间的日志访问频率是最高的,我们通过聚合日志,分析日志、汇总数据,帮助开发、运维、DBA了解业务的状态和行为。这次实践是针对MySQL的抓包日志进行分析,当前系统不足以支持新的需求,需要重构一套日志分析系统。
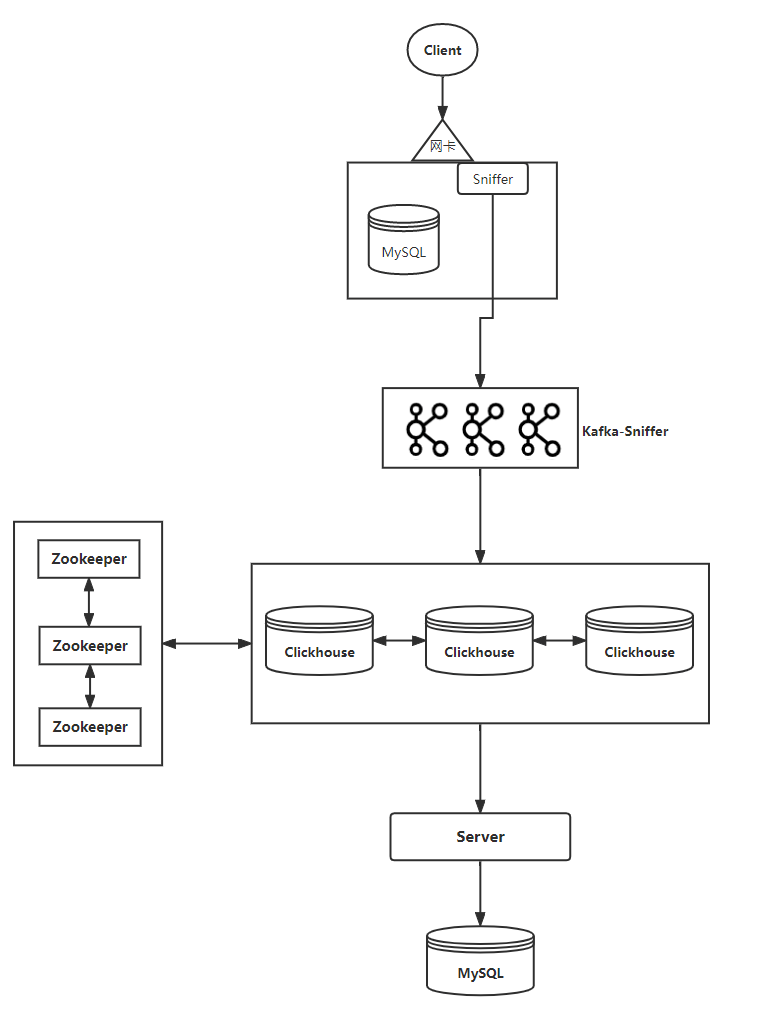
现有抓包系统是将 MySQL 请求的所有 SQL 语句抓取并分析之后写入到 Clickhouse 中,数据可以用来分析数据库的操作。可以查找当前实例、库、表有多少 AppCode 在访问、数据库资源是否可以回收、辅助审计等功能。
Sniffer 抓包之后将数据写入到 Kafka 中,Clickhouse 直接消费 Kafka 的队列中数据,并将数据 merge 到 Clickhouse 中。由 Server 程序按照天级别定时读取 Clickhouse 中的数据,分析、汇总数据,并解析请求 IP 对应的服务信息等,最后将结果写入到 MySQL 中。
当前数据为日志数据,允许少部分丢失或重复,Kafka 队列中的数据约有 133w/s(单个队列最多 33W),MySQL 中存储的结果数据规模大约在 4.6T 左右。
二、名词解释
-
AppCode
服务的名称,是一个服务的基本属性。
-
Clickhouse
一个用于联机分析(OLAP)的列式数据库。
-
Kafka
一个高性能的分布式队列服务。
-
Zookeeper
一个分布式的开源协调服务。
-
扩展性
在业务量上涨时,服务通过较低的代价就可以满足对业务量上涨的需求。
-
聚合比
将 N 条数据按照同一纬度聚合为 M 条数据,M 一定小于等于 N。聚合比 = 聚合之后的数据条数/聚合之前的数据条数。
三、现状分析
1、消费能力不足导致数据丢失
Clickhouse 消费 Kafka 队列中的数据能力不足,延迟较高。并且 Kafka 中的数据只保留 3 个小时,根据测试四个节点 Clickhouse 消费的 Kafka 队列中的数据,约有 80% 的数据丢失,导致数据不完整。
2、服务信息计算不准确
Server 是天级别计算请求的服务信息。由于服务已经上云部署,单个服务的 IP 变动非常频繁,导致 Server 获取到服务信息有延迟(最高延迟 24 小时),甚至很多计算的结果是错误的。这导致部分场景下分析出来的数据完全不可信。
3、汇总数据较少
当前只汇总了四个维度的请求数据,并且只有天级别的数据,粒度较大,无法下钻查询具体信息,展示的维度和明细信息较少。
4、服务监控&可用性
Server 节点目前只有一个,缺乏可用性并没有详细的监控信息。
四、需求
针对当前服务的不足,设计一套服务需要满足当前日志计算性能和业务需求,并且具备较好的扩展性。
五、目标
1、高性能、高扩展性、高可用
服务需要具备以下特性:
1)高性能
在有限资源的情况下,尽可能提高数据消费、聚合能力,降低数据丢失的概率,降低数据入库的延迟。
2)高可用
单个或多个节点出现问题时,不影响服务整体的可用性。
3)高扩展
在未来业务日志体量进一步增长时,仅通过增加部署节点或者修改配置,就可以满足增长的需求,无需额外的工作。
2、降低计算请求业务信息的延迟
从请求 IP 到获取服务信息的延迟降低在 1min 以内,确保 99.9% 的准确性。
3、更多维度汇总数据和下钻查询
支持更多维度的汇总信息查询,以及支持部分场景下的下钻查询。
4、监控
提供多种监控数据,方便展示服务情况,根据监控即可以方便定位到问题。
六、分析
当前 Clickhouse 消费能力不足可以通过扩展节点和调优参数进一步解决,但是服务信息计算是 Clickhouse 做不到的,并且 OLAP 类型的数据库对数据更新并不是太友好,尤其是大规模的更新。如果要解决【降低计算请求业务信息的延迟】这个问题可以有两个解决方案:
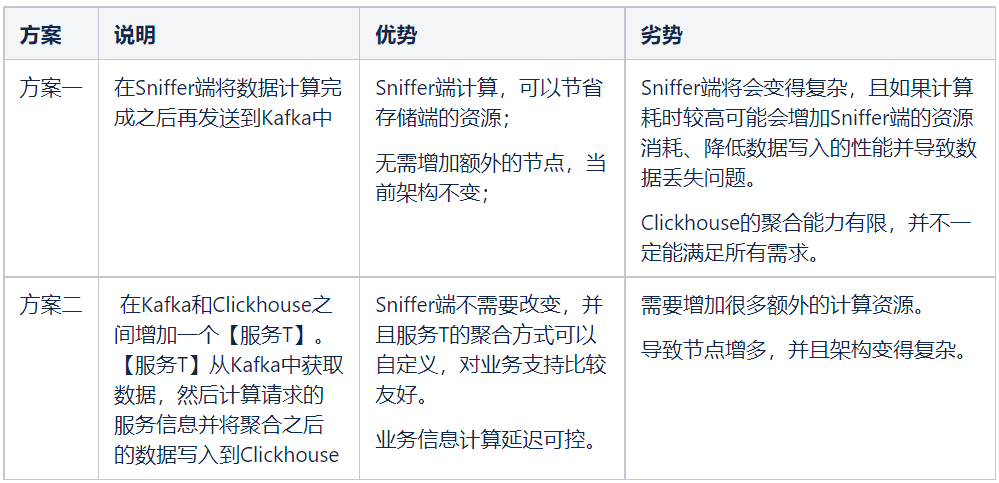
如果采用方案一,会增加 Sniffer 端的不可控性,这与我们之前设计的尽可能减少 Sniffer 端资源消耗的初衷相违背,所以我们选择方案二。
七、设计
1、整体流程
整体流程设计如下所示:
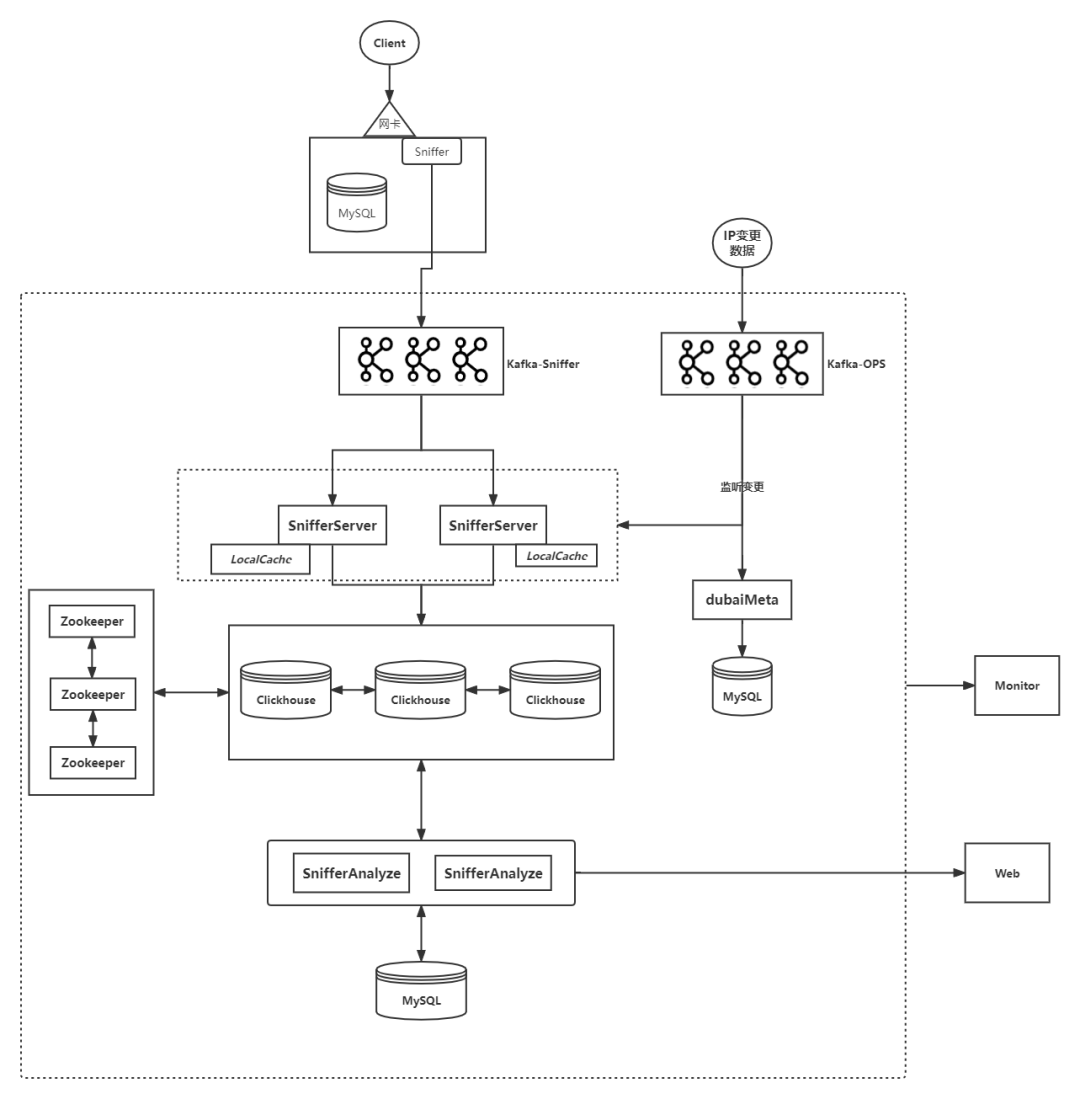
2、模块划分

所有模块的目标:高性能、高可用、高扩展。
3、dubaiMeta
1)说明
由于基础服务不能提供高性能的 IP-AppCode 映射信息的接口,需要自行实现这一功能。对接基础服务的 IP-AppCode 映射信息提供的接口,实时从 Kafka-OPS 队列中获取 IP-AppCode 映射变更的信息流,Merge 到当前数据,并提供 IP-AppCode 信息的接口;
2)设计
由于 dubaiMeta 是提供基础信息的接口,访问量比较大,需要提供高性能、高可用、高扩展性,故 dubaiMeta 需要尽可能设计成为无状态的服务。
将所有的 IP-AppCode 映射数据存储在 MySQL,映射为最新版本。所有的 IP-AppCode 变更历史也都会存储在 MySQL。通过版本信息持续将 IP-AppCode 变更信息 Merge 到最新版本。目前 IP-AppCode 数据整体体量不大,可以在服务内部缓存,不使用其他缓存。这样既可以减少网络和缓存的请求,降低请求耗时,也会避免因对缓存的依赖而导致的性能和可用性问题。这样 dubaiMeta 就可能成为一个接近无状态的服务。
单个请求如果不能命中缓存则会请求基础服务的 IP-AppCode 接口,并将变更数据 Merge 到缓存。但是单个 dubaiMeta 节点数据变更之后如何与其他 dubaiMeta 节点通讯最后达到所有节点数据一致?
有两种方案:
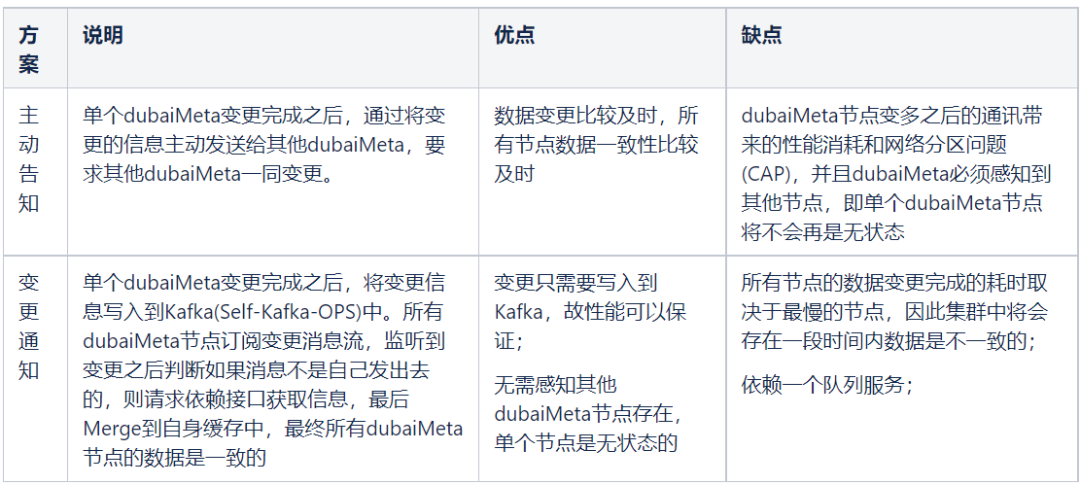
尽可能保证单个节点的高性能的,并检测单个节点的数据一致性延迟,将有问题的服务及时下掉,通过这个方法可以尽可能减低数据不一致带来的问题。故选择【变更通知】的方式;
3)启动流程

服务启动时首先从 Kafka-OPS 持续订阅信息流,所有变更信息 Merge 到内部缓存,然后再从 Self-Kafka-OPS 中持续订阅变更信息流,所有变更信息 Merge 到内部缓存,最后从 MySQL 中获取全量的数据信息,将所有数据 Merge 到缓存,组合成全量的数据。等到所有数据 Merge 完成,并且两个 Kafka 队列无堆积时,再提供服务。
4)性能分析
目前基础信息的数据量不大,可以在服务内部缓存,不使用其他缓存。既可以减少网络和访问缓存的耗时,大幅度降低请求的耗时,又可以避免因对缓存的依赖而导致的性能和可用性问题。
单节点 IP-AppCode 映射变更会发起变更通知,异步通知其他节点,无需感知其他节点存在,故性能可以得到保证。
5)可用性分析
dubaiMeta 目前所有数据存储在本地缓存,在 MySQL 中存储一份副本和变更信息流。
由于 dubaiMeta 是接近无状态的,部署多个节点,通过负载均衡服务下发到不同的节点就可以保证整体服务的可用性。
MySQL 通过平台已有的 HA,保证可用性;
6)扩展性分析
由于 dubaiMeta 是接近无状态的,故可以横向扩展,不对其他节点产生影响,只需要在负载均衡器上添加节点即可。
4、SnifferServer
1)说明
从 Kafka-Sniffer 队列获取日志数据,在日志中补充各种业务信息,并聚合数据。最后将聚合之后的结果批量写入到 Clickhouse 中。
由于队列中的数据量比较大,无法全量存储所有数据,需要按照一定的维度聚合数据。通过降低聚合比(聚合之后的数据条数/聚合之前的数据条数)可以降低总体数据量,在保证性能的前提下尽可能缩短入库的时间。
由于 Clickhouse 是 OLAP 分析类型的列式数据库,更推荐批量写入的方式提高数据库的写入性能(每次不少于 1000 条)。
2)设计
针对单个队列,可以使用多个 SnifferServer 使用同一个 consumerGroup 消费数据,保证消费者的性能、可用性,同时 SnifferServer 也具备了一定的扩展性。
SnifferServer 是内存消耗和 cpu 消耗类型的服务。为了减少 gc 和内存消耗,通过复用对象,确保单个服务内部对象的数量不会有较大波动,可以大幅度降低 gc 以及内存的使用量,提高性能。
按照功能,将 SnifferServer 拆分成三个模块:consumer 模块、aggregator 模块、writer 模块。
consumer 模块消费队列中的数据,将数据传递给 aggregator 模块;aggregator 模块填充业务信息并聚合数据,将聚合之后的数据传递给 writer 模块;writer 模块将数据批量写入到 Clickhouse 中。
① consumer 模块
-
功能
从 Kafka-Sniffer 队列中获取数据,将数据组合之后批量传输给 aggregator 模块。
-
分析
针对单个 Kafka 队列,提升消费的速度途径有:

经测试,在当前场景配置下,单个 SnifferServer 消费队列速度可以达到 20W/s+。通过对 consumer 的调优已经能够完全达到 33w/s (两个 SnifferServer)的消费速度,已完全满足业务的需求。
② aggregator 模块
-
功能
从 consumer 接受数据,并获取 IP-AppCode 映射信息和业务信息,将信息补充到日志数据中。等到一定数量的数据或者超时之后,将这一批次的数据按照指定的维度聚合。最后将聚合之后的结果传输给 writer 模块
-
分析
-
如果每条数据都需要通过接口获取 IP-AppCode 映射和业务信息,那样会大大降低聚合的效率,故本地需要缓存 IP-AppCode 和业务信息。aggregator 模块同样也需要订阅 Kafka-OPS 和 Self-Kafka-OPS 变更,Merge IP-AppCode 变更信息到本地缓存。
-
通过增加 aggregator 线程数量提升并发数,可以有效的提升聚合的效率。但线程数越多会在不同程度上提高聚合比(和业务行为相关),通过增加单个批次的数量可以降低聚合比,两个指标需要根据需要测试调优;
经测试:针对同一个队列中的数据,单个 SnifferServer 的聚合比约为 10%-20% 左右,两个 SnifferServer 的平均聚合比约为 15%-30% 左右,三个 SnifferServer 的平均聚合比约为 30% 以上,故在同等配置的情况下增加 SnifferServer 则会增加聚合比,存储端将增加数据量。
③ writer 模块
-
功能
从 aggregator 模块接受数据,缓存在内存中。当缓存数据超过 N 条或者缓存时间超过 M 秒之后再将缓存数据批量写入到 Clickhouse 中;
-
分析
每个批次应该尽可能缓存足够的的数据量再写入数据,提升写入的效率,降低写入的次数,预设单个批次为 1w(最少,可配置)条数据;
3)分析
每个模块均可以设置缓存大小和并行的线程数,通过设置缓存大小和并行的线程数可以提高效率。但是需要注意的是,缓存大小和并行线程越多,占用的资源也就越多。并且如果程序意外终止,那么丢失的数据也会变多,需要酌情考虑各个参数的配置。
对于各个模块的启动和关闭顺序需要额外关注。
① 模块启动顺序

先启动 writer 模块,初始化 writer 模块的缓存和线程,再启动 aggregator 模块,初始化 aggregator 的缓存和线程,最后启动 consumer 模块,初始化 consumer 模块的线程和缓存。
② 模块关闭顺序
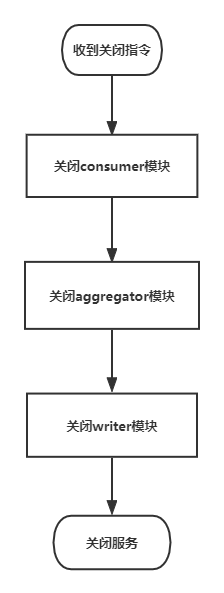
为了减少数据丢失,在正常情况下关闭服务时需要按照以下顺序关闭模块
-
关闭所有的Kafka的连接;
-
将 consumer 模块中所有缓存数据发送到 aggregator 模块之后,再关闭所有 consumer 模块的线程;
-
将 aggregator 中的缓存数据立即聚合(所有日志数据补完业务信息,并聚合完成)。聚合完成的数据全部发送给 writer 模块之后,再关闭所有 aggregator 模块的线程;
-
将 writer 模块中的数据分批次,全部写入到 Clickhouse 中,最后关闭所有 writer 模块的线程。
4)扩展性分析
由于 SnifferServer 是偏计算类型的服务,并且从 Kafka 到 SnifferServer 到 Clickhouse,需要大量的数据传输,需要较好的 cpu 和网卡才可以充分发挥 SnifferServer 的性能;
① SnifferServer 内部扩展性
SnifferServer 的每个模块都可以通过设置线程数和缓存大小提高性能;
② SnifferServer 级别的扩展性
对于单个队列,受限于 Kafka 的 partition 数量,最多有于 partition 数量相等的 SnifferServer 运行,超过 partition 数量时节点不再参与队列消费;
③ Kafka 的 Partition
单个 Kafka 集群的 partition 理论上没有限制,受限于服务器资源、Zookeeper 和运维的方便性等,需要设置上限;
④ 整个服务
可以规划针对不同的 IDC,向不同的 Kafka 写入日志数据,这样日志数据将被分区;
5)可用性分析
SnifferServer 之间通过 consumerGroup 消费 Kafka 队列中的数据。对于单个队列通过冗余 SnifferServer,即使单个 SnifferServer 挂掉,不会影响整体服务。
5、SnifferAnalyze
1)说明
按照天级别定时从 Clickhouse 中获取聚合数据,分析、汇总,存储分析之后的结果并提供接口和页面展示结果。
2)设计
分析汇总之后的结果大概分为两类数据,第一类是初步聚合的粗粒度数据,数据量比较大。数据一旦产生不会修改,只有大范围的删除,一般是溯源、分析、下钻查询使用,使用的频率不是很高;第二类是汇总的报告数据。部分数据会存在大范围的修改,较多的并发查询。整体数据量相对于第一类数据量较少,一般是展示结果、接口查询较多;
Clickhouse 在大规模存储上的单表查询和写入效率较高,压缩效率较高但不擅长做并发查询和频繁的修改数据,官网建议每秒最多查询 100 次。相比较而言,MySQL 适合存储小体量数据,以及数据的增删改查,并擅长高并发查询。
综合考虑节省存储成本以及各个存储的特性,第一类数据适合存储到 Clickhouse 中,第二类数据适合存储到 MySQL 中。针对原始日志数据设置合适的过期时间,超过指定时间的数据都予以删除,而汇总数据相较于原始数据量已经大幅度减少,可以保留较长的过期时间。
依托 Clickhouse 的分析能力,对于第一类数据直接将 Clickhouse 中的数据分析出来直接写入到 Clickhouse 中,避免中间转储。第二类数据需要从 Clickhouse 中获取出来,分析、计算、汇总之后再写入到 MySQL 中。
每个任务执行前都需要获取锁,只有成功获取到锁的任务才可以执行该任务。SnifferAnalyze 多个节点在执行任务前会通过抢占的方式获取任务锁,仅当成功获取了锁的节点会执行任务,保证了单个节点挂掉不影响分析任务的执行。但是如果任务执行过成中被终端,目前需要人为介入处理。
3)扩展性分析
目前分析类型的任务节点扩展能力有限。
4)可用性分析
由于分析类型的任务扩展能力有限,故只能在节点之间保证高可用。并且一旦任务执行中断需要人为介入处理。
6、Clickhouse
1)说明
Clickhouse 架构图
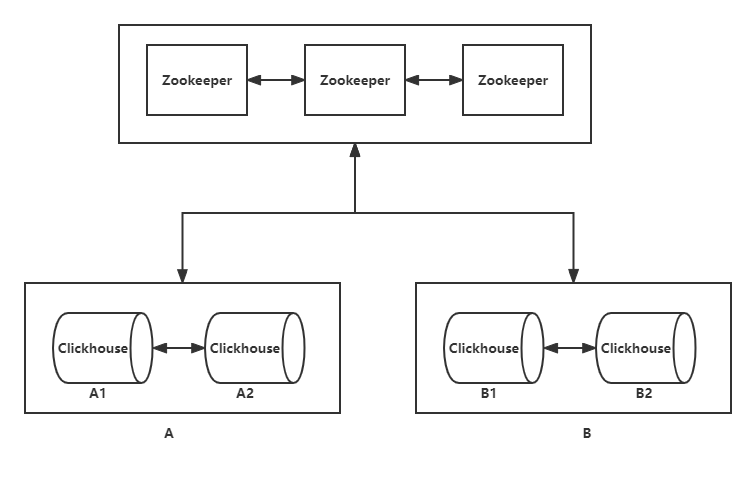
例如图示 Clickhouse 有两个分片(A 和 B),每个分片有两个副本([A1,A2],[B1,B2]),集群与三节点的 Zookeeper 通讯。
① 同步
Clickhouse 集群 Replication 引擎的副本是通过 Zookeeper 实现的,Zookeeper 存储数据块的元数据信息。分片 A 有 A1 和 A2 两个节点,A1 和 A2 共同监听 Zookeeper 执行目录下节点的数据。当 A1 节点写入数据块之后,A1 在 Zookeeper 上变更元数据信息。A2 收到 Zookeeper 的元数据变更之后,向 A1 发起拉取指定数据块的通知,A1 将指定的数据块发送给 A2,完成数据传输。同理 A2 也可以写入数据,通知 Zookeeper 变更数据,并向 A1 传输数据。数据同步是异步的,传输数据块时会去重。更多副本相关的信息请见官网说明。
② 分片
分片依靠 Distribute 引擎实现。Distribute 引擎不存储任何数据,Clickhouse 有 Distribute 引擎支持将数据按照指定的规则(random,hash,range,自定义)将数据分发到各个分片。
数据写入 Distribute 引擎时,数据在本地写入完成后立即返回。Clickhouse 会周期性的按照规则将数据分发的其他节点上。
③ 查询
通过 Distribute 引擎查询时,无论分片规则是什么样的,Distribute 都会将 SQL 分发到所有的分片上查询,并在当前节点汇总数据,最后返回给客户端。如果查询 Replication 引擎的表,那么只查询本地数据。
2)可用性分析
Clickhouse 的 Replication 引擎和 Zookeeper 实现数据副本,保证了每个分片内可以允许一个副本宕机。Distribute 引擎可以保证在 Clickhouse 所有节点上都可以写入和读取。
但是通过数据同步是异步的。如果节点写入成功并在数据尚未完成传输之前宕机,无法恢复,则尚未同步的数据块将会丢失。
3)扩展性分析
由于 Distribute 查询的时候会将 SQL 分发到所有的分片上,无论分片的数据状态如何,故新增的节点可以直接加入到 Clickhouse 集群中,而无需担心旧数据迁移的问题。但是需要考虑数据倾斜问题,通过提高新加入节点权重可以将新写入的数据更多的发送到新加入分片上。
向 Distribute 引擎写入数据时,Distribute 引擎首先会写入本地,再依次转发给其他节点,可能会导致本地网络流量增加、服务 merge 数据块时产生额外的 cpu 以及 IO 使用的问题。可以通过只写入本地表,而不写入 Distribute 表解决这个问题。但是需要通过一定的策略(比如轮询)写入不同的 Clickhouse 节点,解决数据倾斜的问题。
7、监控
1)说明
当前监控只是用于查看各个节点的状态情况,展示性能问题,并未提供高级别的功能。监控告警接入公司现有的监控系统。
八、效果
1、SnifferServer
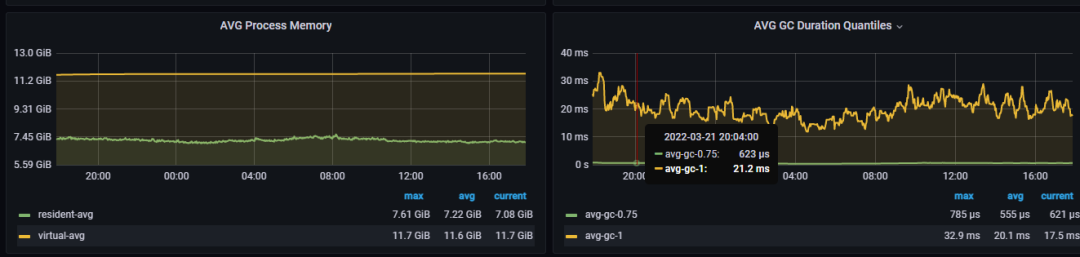
所有 SnifferServer 节点平均内存占用约为 12G 左右,最大 gc 平均约为 21ms,75 分位的 gc 平均约为 0.6ms。
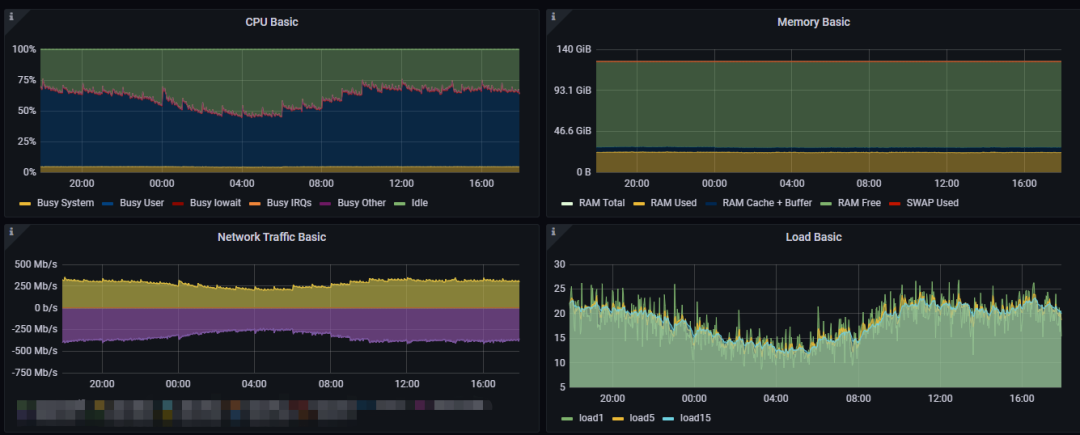
两节点 SnifferServer 合计 CPU(32核)利用率峰值约 70%,网卡峰值 上行约 330Mb/s 下行 400Mb/s。
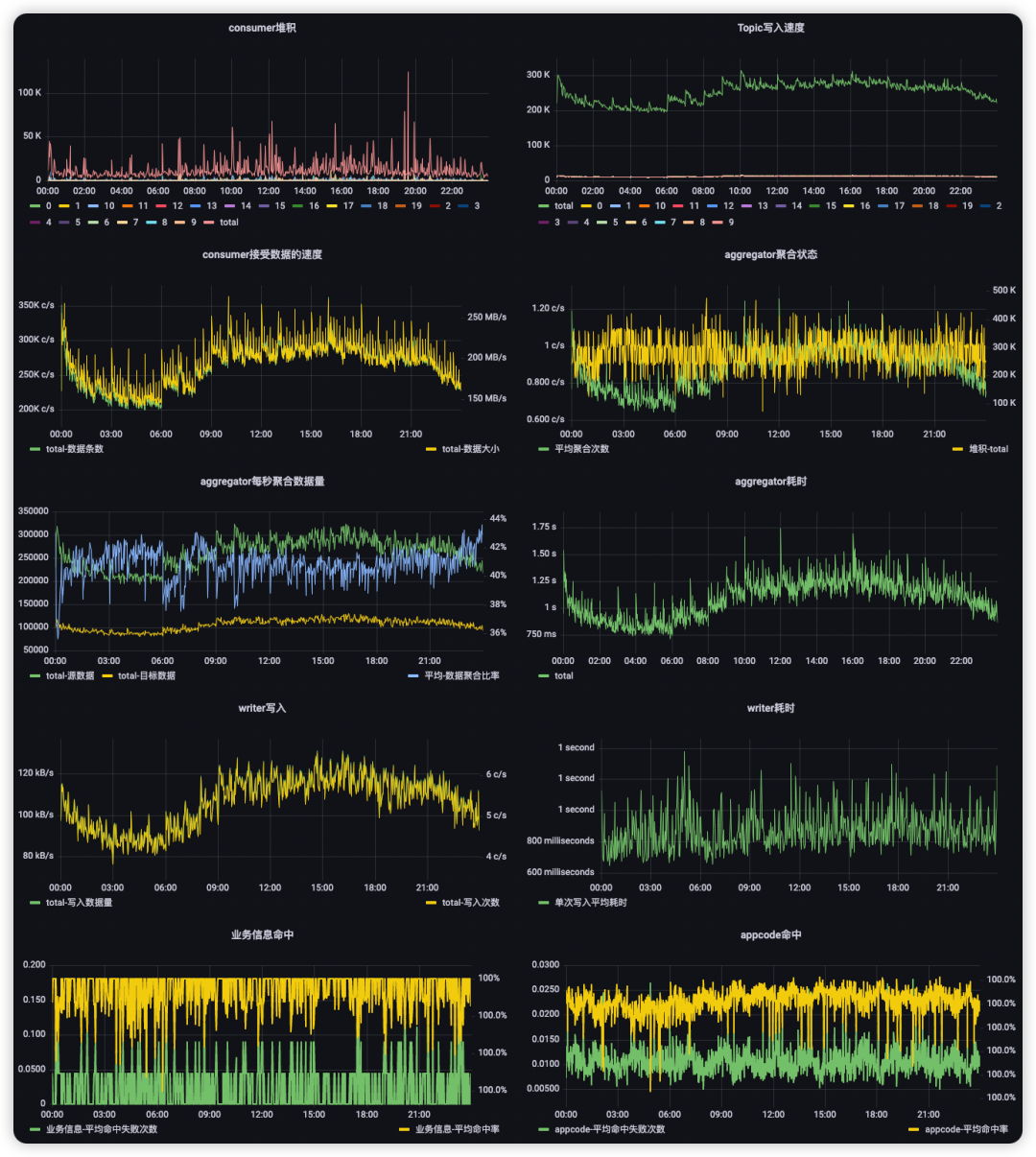
单个队列数据生成速度峰值约为 30w/s,平均堆积约 20k,消费者速度要快于生产者。
aggregator 平均每秒聚合 1.2 次,数据聚合比约为 40%,writer 每秒约写入 6 次,业务信息和 appCode 命中率几乎 100%。
2、页面展示
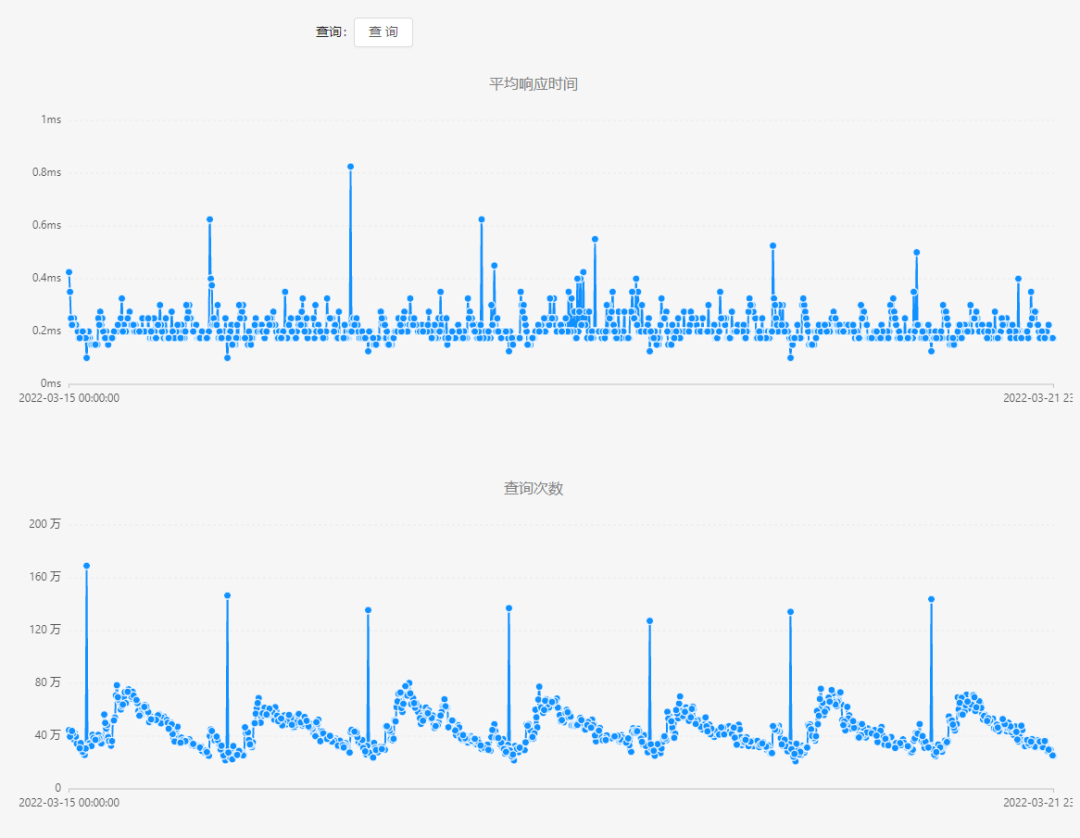
展示某个业务的平均响应时间和查询次数
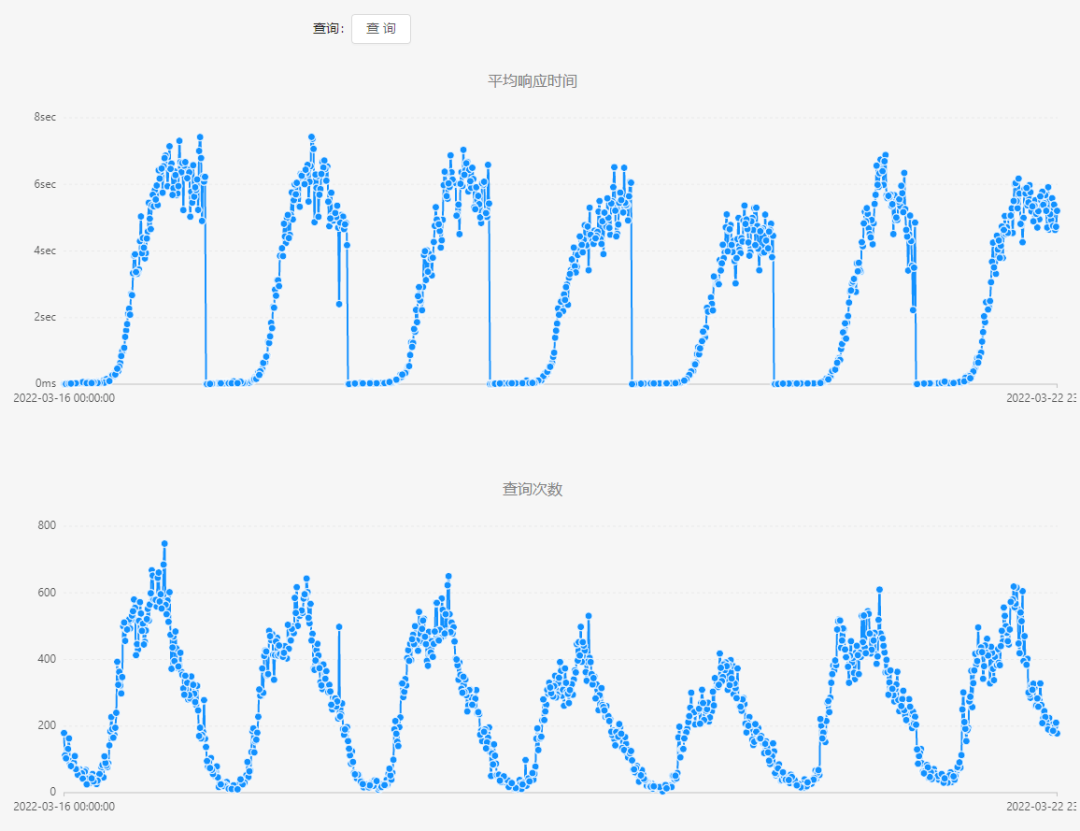
展示某个慢查询的平均响应时间和查询次数
九、总结
SnifferServer 将队列中的日志数据补全业务信息、聚合数据、将结果写入到 Clickhouse 中,SnifferAnalyze 定期分析数据,将结果写入到 Clickhouse 和 MySQL。整个系统具备高性能、高可用性、高扩展性的优点,内存和 CPU 使用率比较稳定。日志分析系统呈现出来的结果可以帮助开发更好的了解业务的行为,发现潜在的问题,评估业务在数据库方面的风险。结合慢查询风险指数系统可以更精确的评估慢查询的风险。
>>>>
参考资料
-
https://clickhouse.com/docs/zh/
-
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/replication/
-
https://mp.weixin.qq.com/s/kFbW5K7txdijLOVkYLs40A
作者丨钱芳园 来源丨公众号:Qunar技术沙龙(ID:QunarTL) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK