

如何写出高性能代码(三)优化内存回收(GC)
source link: https://blog.csdn.net/xindoo/article/details/124536896
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

同一份逻辑,不同人的实现的代码性能会出现数量级的差异; 同一份代码,你可能微调几个字符或者某行代码的顺序,就会有数倍的性能提升;同一份代码,也可能在不同处理器上运行也会有几倍的性能差异;十倍程序员 不是只存在于传说中,可能在我们的周围也比比皆是。十倍体现在程序员的方法面面,而代码性能却是其中最直观的一面。
本文是《如何写出高性能代码》系列的第三篇,本文将告诉你如何写出GC更优的代码,以达到提升代码性能的目的
优化内存回收
垃圾回收GC(Garbage Collection)是现在高级编程语言内存回收的主要手段,也是高级语言所必备的特性,比如大家所熟知的Java、python、go都是自带GC的,甚至是连C++ 也开始有了GC的影子。GC可以自动清理掉那些不用的垃圾对象,释放内存空间,这个特性对新手程序猿极其友好,反观没有GC机制的语言,比如C++,程序猿需要自己去管理和释放内存,很容易出现内存泄露的bug,这也是C++的上手难度远高于很多语言的原因之一。
GC的出现降低了编程语言上手的难度,但是过度依赖于GC也会影响你程序的性能。这里就不得不提到一个臭名昭著的词——STW(stop the world) ,它的含义就是应用进程暂停所有的工作,把时间都让出来让给GC线程去清理垃圾。别小看这个STW,如果时间过长,会明显影响到用户体验。像我之前从事的广告业务,有研究表明广告系统响应时间越长,广告点击量越低,也就意味着挣到的钱越少。
GC还有个关键的性能指标——吞吐率(Throughput),它的定义是运行用户代码的时间占总CPU运行时间的比例。举个例子,假设吞吐率是60%,意味着有60%的CPU时间是运行用户代码的,而剩下的40%的CPU时间是被GC占用。从其定义来看,当然是吞吐率越高越好,那么如何提升应用的GC吞吐率呢? 这里我总结了三条。
减少对象数量
这个很好理解了,产生的垃圾对象越少,需要的GC次数也就越少。那如何能减少对象的数量?这就不得不回顾下我们在上一讲巧用数据特性 中提到的两个特性——可复用性和非必要性,忘记的同学可以再点开上面的链接回顾下。这里再大概讲下这两个特性是如何减少对象生成的。
可复用性在这里指的是,大多数的对象都是可以被复用的,这些可以被复用的对象就没必要每次都新建出来,浪费内存空间了。 处了巧用数据特性 中的例子,我这里再个Java中已经被用到的例子,这个还得从一段奇怪的代码说起。
Integer i1 = Integer.valueOf(111);
Integer i2 = Integer.valueOf(111);
System.out.println(i1 == i2);
Integer i3 = Integer.valueOf(222);
Integer i4 = Integer.valueOf(222);
System.out.println(i3 == i4);
上面这段代码的输出结果会是啥呢?你以为是true+true,实际上是true+false。 What?? Java中222不等于222,难道是有Bug? 其实这是新手在比较数值大小时常犯的一个错误,包装类型间的相等判断应该用equals而不是’’,'’只会判断这两个对象是否是同一个对象,而不是对象中包的具体值是否相等。
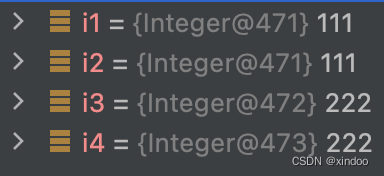
像1、2、3、4……等一批数字,在任何场景下都是非常常用的,如果每次使用都新建个对象很是浪费,Java的开发者也考虑到了这点,所以在Jdk中提取缓存了一批整数的对象(-128到127),这些数字每次都可以直接拿过来用,而不是新建一个对象出来。而在-128到127范围外的数字,每次都会是新对象,下面是Integer.valueOf()的源码及注释:
/**
* Returns an {@code Integer} instance representing the specified
* {@code int} value. If a new {@code Integer} instance is not
* required, this method should generally be used in preference to
* the constructor {@link #Integer(int)}, as this method is likely
* to yield significantly better space and time performance by
* caching frequently requested values.
*
* This method will always cache values in the range -128 to 127,
* inclusive, and may cache other values outside of this range.
*
* @param i an {@code int} value.
* @return an {@code Integer} instance representing {@code i}.
* @since 1.5
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
我在Idea中通过Debug看到了i1-i4几个对象,其实111的两个对象确实是同一个,而222的两个对象确实不同,这就解释了上面代码中的诡异现象。
非必要性的意思是有些对象可能没必要生成。这里我举个例子,可能类似下面这种代码,在业务系统中会很常见。
private List<UserInfo> getUserInfos(List<String> ids) {
List<UserInfo> res = new ArrayList<>(ids.size());
if (ids == null || res.size() == 0) {
return new Collections.emptyList();
}
List<UserInfo> validUsers = ids.stream()
.filter(id -> isValid(id))
.map(id -> getUserInfos(id))
.filter(Objects::nonNull)
.collect(Collectors.toList());
res.addAll(validUsers);
return res;
}
上面代码非常简单,就是通过一批用户Id去获取出来完整的用户信息,获取前要对入参做校验,之后还会对id做合法性校验。 上面代码的问题是 res对象初始化太早了,如果一个UserInfo没查到,res对象就白初始化了。另外,最后直接返回validUsers是不是就行了,没必要再装到res中,这里res就具备了非必要性。
像上述这种情况,可能在很多业务系统里随处可见(但不一定这么直观),提前初始化一些之后没用的对象,除了浪费内存和CPU之外,也会给GC增加负担。
缩小对象体积
缩小体积对象也很好理解,如果对象在单位时间内生成的对象数量固定,但体积减小后,同样大小的内存就能装载更多的对象,更晚才触发GC,GC的频次就会降低,频次低了自然对性能的影响就会变小。
关于减少对象体积,这里我给大家推荐一个jar包——eclipse-collections,其中提供了好多原始类型的集合,比如IntMap、LongMap…… 使用原始类型(int,long,double……)而不是封装类型(Integer,Long,Double……),在一些数值偏多的业务中很有优势,如下图是我对比了HashSet和eclipse-collections中IntSet在不同数据量下的内存占用对比,IntSet的内存占用只有HashSet的四分之一。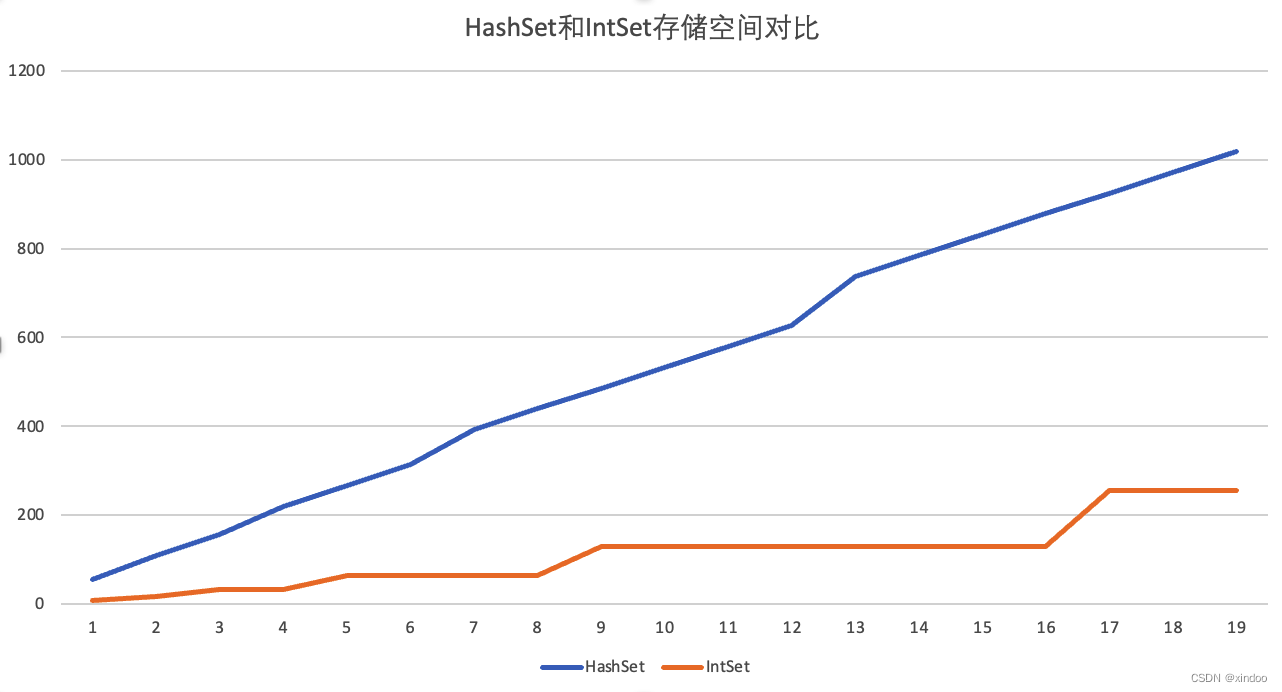
另外,咱在写业务代码的时候,写一些DO、BO、DTO的时候没必要的字段就别加进去了。查数据库的时候,不用的字段也就别查出来了。我之前看到过很多业务代码,查数据库的时候把整行都查出来了,比如我要查一个用户的年龄,结果把他的姓名、地址、生日、电话号码…… 全查出来,这些信息放在Java里面需要一个个的对象去存储的,没有用到部分字段首先就是白取了,其实存它还浪费内存空间。
缩短对象存活时间
为什么减少对象的存活时间就能提升GC的性能?总的垃圾对象并没有减少啊! 是的 没错,单纯缩短对象的存活时间并不会减少垃圾对象的数量,而是会减少GC的次数。要理解这个就得先知道GC的触发机制,像Java中当堆空间使用率超过某个阈值后就会触发GC,如果能缩短对象的时间,那每次GC就能释放出来更多的空间,下次GC也就会来的更迟一些,总体上GC次数就会减少。
这里我举个我自己经历的真实案例,我们之前系统有个接口,仅仅是调整了两行代码的顺序,这个接口的性能就提升了40%,这个整个服务的CPU使用率降低了10%+,而这两行顺序的改动,缩短了大部分对象的生命周期,所以导致了性能提升。
private List<Object> filterTest() {
List<Object> list = getSomeList();
List<Object> res = list
.stream()
.filter(x -> filter1(x)) // filter1需要调用外部接口做过滤判断,性能低且过滤比例很少
.filter(x -> filter2(x))
.filter(x -> filter3(x)) // filter3 本地数值校验,不依赖外部,效率高且过滤比例高
.collect(Collectors.toList());
}
上面代码中,filter1性能很低但过滤比低,filter3恰恰相反,往往没被filter1过滤的会被filter3过滤,做了很多无用功。这里只需要将filter1和filter3互换下位置,除了减少无用功之外,List中的大部分对象生命周期也会缩短。
其实有个比较好的编程习惯,也可以减少对象的存活时间。其实在本系列的第篇中我也大概提到过,那就是缩小变量的作用域。能用局部变量就用局部变量,能放if或者for里面就放里面,因为编程语言作用域实现就是用的栈,作用域越小就越快出栈,其中使用到的对象就越快被判断为死对象。
除了上述三种优化GC的方式话,其实还有种骚操作,但是我本人不推荐使用,那就是——堆外内存
在Java中,只有堆内内存才会受GC收集器管理,所以你要不被GC影响性能,最直接的方式就是使用堆外内存,Java中也提供了堆外内存使用的API。但是,堆外内存也是把双刃剑,你要用就得做好完善的管理措施,否则内存泄露导致OOM就GG了,所以不推荐直接使用。但是,凡事总有但是,有一些优秀开源代码,比如缓存框架ehcache就可以让你安全的享受到堆外内存的好处,具体使用方式可以查阅官网,这里不再赘述。
好了,今天的分享就到这里了,看完你可能会发现今天的内容和上一讲 (二)巧用数据特性有一些重复的内容,没错,我理解性能优化底层都是同一套方法论,很多新方法只是以不同的视角在不同领域所衍生出来的。最后感谢下大家的支持,希望你看完文章有所收获。另外有兴趣的话也可以关注下本系列的前两篇文章。
如何写出高性能代码系列文章
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK