

DPDK Optimization on Arm
source link: https://community.arm.com/arm-community-blogs/b/tools-software-ides-blog/posts/dpdk-optimization-on-arm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

What is Data Plane Development Kit (DPDK)?
Network process occurs at two planes: control plane and data plane.
- Control plane refers to all functions and processes that determine which path to use to send the packet/frame. It is responsible for populating the routing table, drawing network topology, forwarding table, and enabling data plane functions. All these mean the router makes its decision. In a single line, control plane is responsible for how to forward packets.
- Data plane refers to all functions and processes that forward packets and frames from one interface to another based on control plane logic. The routing table, forwarding table and routing logic constitute data plane functions. Data plane packets go through the router, and frames’ incoming and outgoing are based on control plane logic. In a single line, data plane is responsible for moving packets from source to destination, which is called as forwarding plane.
Data Plane Development Kit (DPDK) is a preferred network solution for data plane. It consists of libraries to accelerate packet process workloads running on a wide variety of CPU architectures.
- Designed to run on Arm, PowerPC and x86 processors, DPDK runs mostly in Linux userland and supports Windows. It is available for a subset of DPDK features with a FreeBSD port. DPDK is under the Open-Source BSD License.
- DPDK facilitates quicker deployment of high-performance network applications and enables more efficient computing than the standard interrupt-based kernel network stack.
DPDK: How it works?
Generic features
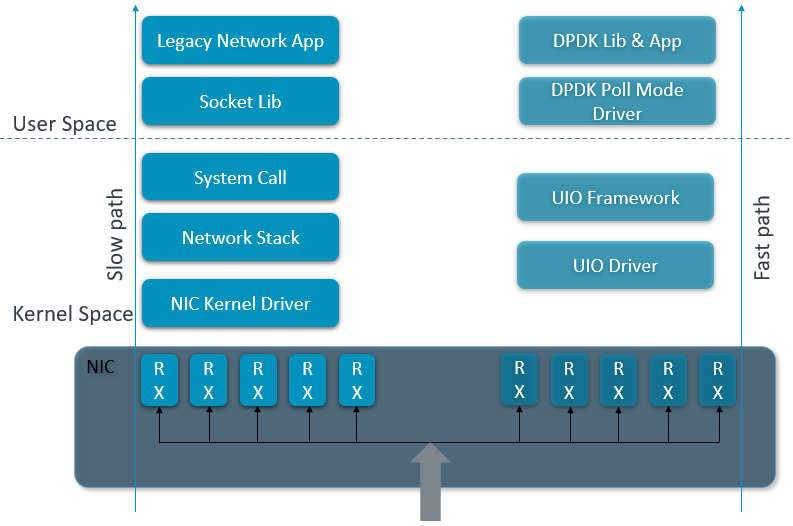
Figure 1: Packet process by Linux kernel (left) and DPDK (right).
Though DPDK uses several techniques to optimize packet throughput, how it works (and the key to its performance) is based on bypassing kernel and Poll Mode Driver (PMD).
- Kernel bypass: Create a path from the NIC to the application within user space, in other words, bypass the kernel. This eliminates context switching when moving the frame between user space and kernel space. Additionally, further gains are obtained by negating the NIC driver, kernel network stack, and performance penalties they introduce.
- Poll Mode Driver (PMD): When CPU receives a frame, instead of raising an interrupt by the NIC, CPU would run a PMD constantly to poll the NIC for new packets.
Besides these, DPDK employs other methods such as CPU affinity, CPU isolation, huge page memory, cache line alignment and bulk operations to achieve the possible best performance.
DPDK scope
Besides the fundamental high-performance network I/O, DPDK provides many network functions, for example, Longest Prefix Match (LPM), which serve as libraries for upper-level application to use. Here are the basic modules within DPDK.
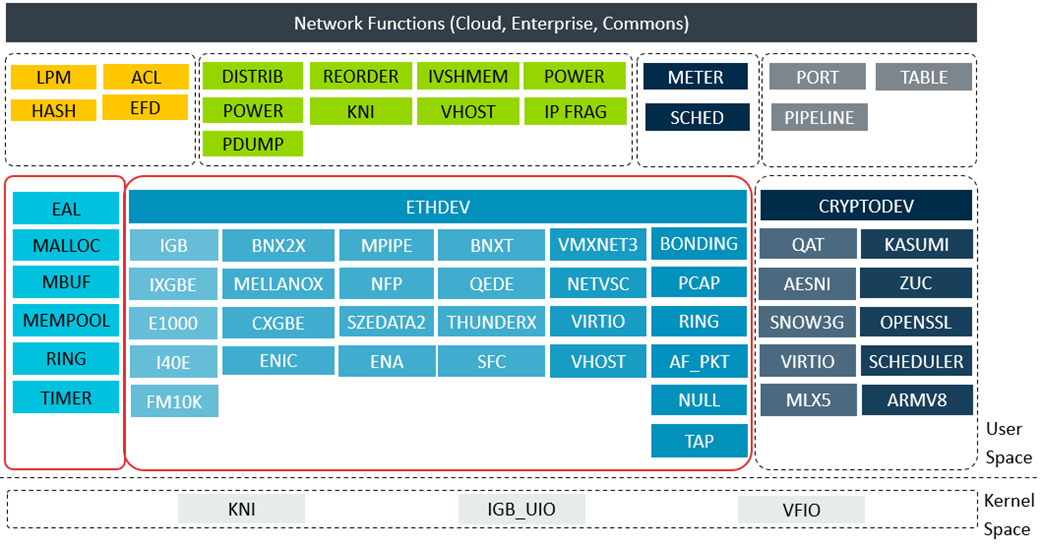
Figure 2: DPDK framework and modules
DPDK libraries are divided into the kernel module and the user-space module.
For the kernel part,
- KNI provides a path to the kernel stack. With it, DPDK can use traditional Linux network tools such as ethtool and ifconfig.
- UIO and VFIO map NIC’s registers to user space during initialization.
Among user-space modules, PMDs and core libraries are the key parts that affect the performance most.
- PMDs provide NIC drivers from userland to obtain a high network throughput. Most industry-leading ethernet companies have already provided their PMDs at DPDK. In addition, PMDs for a variety of vNICs such as Microsoft, VMware, and KVM-based virtualized interfaces are implemented.
- Core libs provide the OS abstraction layer and software APIs to use the huge page memory, buffer pool, timers, lock-free rings, and other underlying components.
Instead of relying on memory management APIs (such as malloc and free) provided by the system, DPDK develops its own memory management APIs. These APIs fully utilize the huge page memory, avoid memory fragmentation and remote access on NUMA system. DPDK provides buffers to the NIC when receiving packets and reclaims consumed buffers when transmitting packet. The buffer allocation and reclamation are high-efficient because of lockless algorithm design and fixed buffer size. NIC queues comprise of fixed number of descriptors, and each descriptor consumes a packet buffer to contain a packet received or transmitted.
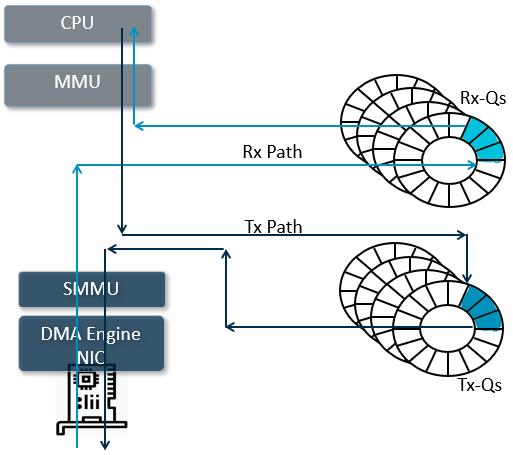
Figure 3: Memory management
Optimization work on Arm
DPDK is very efficient in driving high-performance packet I/O over high-speed NICs. Its performance improvement comes from appropriate platform configuration and software optimization. Configure the platform according to its own architecture and features. The configuration includes platform hardware layout, Linux system configuration, and NIC setting. For software optimization, work focuses on memory optimization, SIMD applying, and new features.
Configuration optimization
Firmware setting:
NUMA balancing
Suggest enabling NUMA for a multi socket system. NUMA balancing moves tasks closer to the memory that tasks are accessing. It also moves application data to the closer memory that referenced by tasks. All of these improve performance because of lower latency of memory access.
Virtualization Host Extensions (VHE)
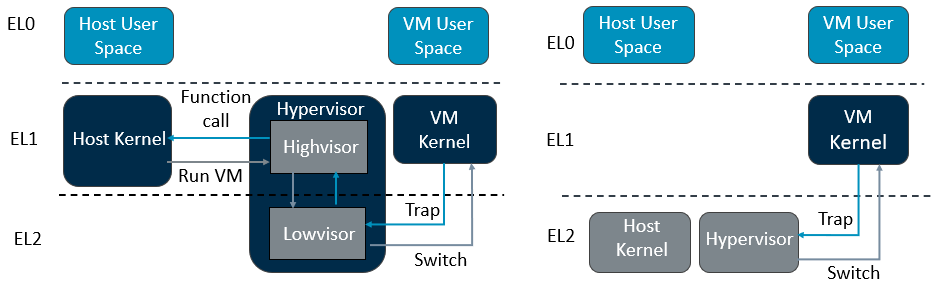
Figure 4: KVM/ARM without VHE (left) and KVM/ARM with VHE (right).
Figure 4 shows a simplified version of the software stack and Exception levels. The left diagram shows a standalone hypervisor map of Arm Exception levels. Traditionally, the kernel runs at EL1, and the hypervisor including lowvisor and highvisor runs at EL1 and EL2. Lowvisor makes full use of Arm’s extended virtualization features to configure the environment. Highvisor integrates and utilizes existing KVM codes such as the scheduler module. When running an application in VM, OS and VM involve context switching and register changes. In other words, KVM enables virtualization features at EL2 when switching from the host kernel to the VM kernel. On the other hand, KVM at EL1 disables virtualization features, allows OS to access hardware at EL1, and isolates VM at EL1.
The right diagram shows Armv8.0 split-mode KVM. Virtualization Host Extensions (VHE) supports the kernel to run directly at EL2 which leads to better performance for KVM, by reducing context switching and register changes.
The following diagram shows enabling VHE is important for virtio on Arm. We can observe almost 77% performance improvement in some test.
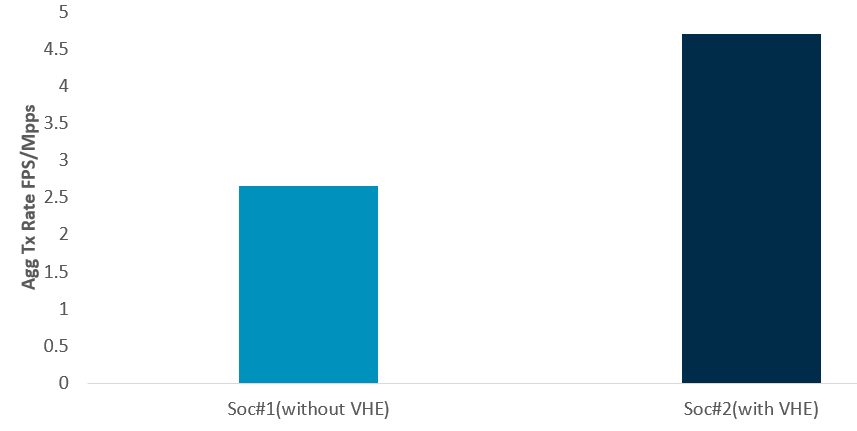
Figure 5: PVP performance
Linux kernel setting
- Huge pages: Regular page size is 4KB, and DPDK supports huge pages like 2MB and 1GB to cover large memory areas without TLB misses. Fewer TLB misses lead to better performance when working with large memory areas, this is customary for DPDK use cases.
- Core isolation: To reduce the possibility of context switching, give a hint to the kernel for refraining from scheduling other user-space tasks to cores used by DPDK application threads.
For example, if DPDK runs on logical cores 10 - 12, and the huge page size is 1G, we need to add the following command line to the kernel configuration.
hugepagesz=1G hugepages=8 isolcpus = 10-12
NIC parameters tuning
How to configure NIC parameters for the best performance?
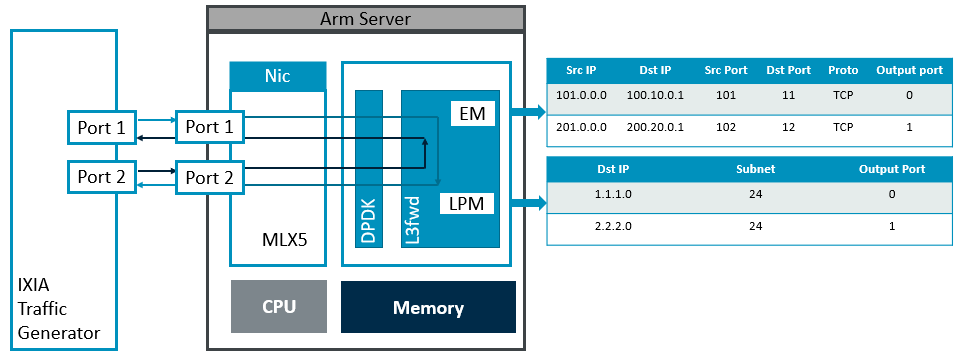
Figure 6: L3fwd sample
Figure 6 shows an Arm server is plugged with high-perf NICs which are connected to a packet generator (IXIA). Use l3fwd function as an example, after NICs receive the packet, CPU will check the IP header for validation, and complete routing table lookup according to the destination IP address. When finding the destination port, send out the packet with IP header modification like TTL update. Two routing table lookup mechanisms are implemented here: the Exact Match (EM) and the Longest Prefix Match (LPM), which are specifically based on DPDK Hash and DPDK LPM libraries.
Use the following command line to enable this instance:
sudo ./build/examples/dpdk-l3fwd -n 6 -l 10-12 -w 0000:89:00.0 -w 0000:89:00.1 --socket-mem=1024,0 -- -p 0x3 -P --config=‘(0,0,5),(1,0,7)’
It is a default set to allocate equal-sized resources for Tx and Rx which are known as queue length described by RTE_TEST_TX_DESC_DEFAULT and RTE_TEST_RX_DESC_DEFAULT.
#define RTE_TEST_TX_DESC_DEFAULT 1024 #define RTE_TEST_RX_DESC_DEFAULT 1024
The shorter length for Tx and Rx means that the NIC holds less packets, which may lead to packet loss in high traffic scenarios. In turn, the longer queue length holds more packets with more memory space, which may lead to resource cost.
DPDK utilizes burst process to decompose transmitting and receiving into multiple stages, and deal with several packets at a time, usually 8, 16, or 32 described by MAX_PKT_BURST.
#define MAX_PKT_BURST 32
The burst mode processes adjacent data access and similar data calculation together. This mode minimizes memory access for multiple data read/write and make the maximize cache benefits. Therefore, it saves time for processing packets and achieves better performance.
What is the optimum setting for Tx and Rx queue length? And what is the optimal size for burst process? Tune these according to specified NICs and platforms. The following graph shows the throughput changes with different Tx/Rx length and burst size for MLX5 NIC on N1SDP platform.
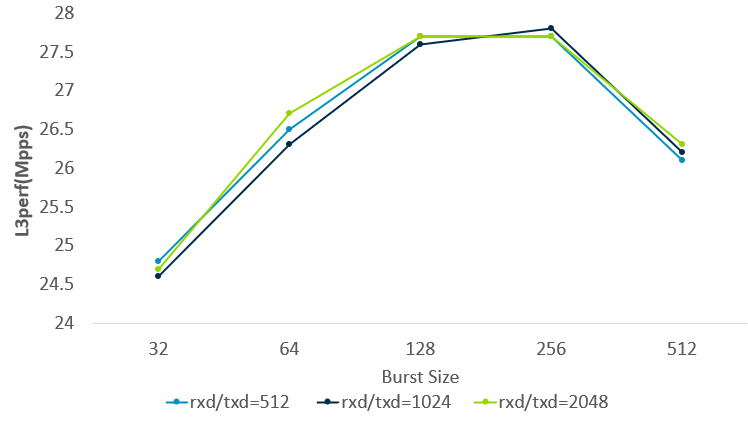
Figure 7: Throughput of different parameters
Memory optimization
Cache optimization
Performance Monitoring Unit (PMU) is a hardware unit that collects hardware events, including cache events. And perf is a tool to control PMU which offers a rich set of commands to analyze performance bottlenecks by measuring events from various sources based on Linux perf event subsystem.
The tool ‘perf’ is to calculate the cache-miss event in l3fwd sample with i40e driver on N1SDP platform. I40e driver does not release the mbuf back to the mempool or local cache immediately after transmitting the packet. Instead, it leaves the mbuf in Tx ring and performs a bulk free when reaching the tx_free_thresh. Figure 8 shows the hot spot is in the tx_free function because of frequent packet buffer memory loading.
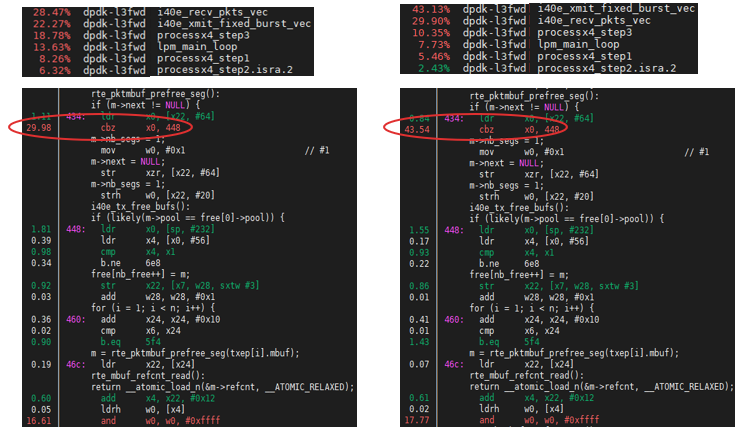
Figure 8: Task-clock (left) and cache-miss (right) in l3fwd sample.
How to optimize cache miss? Summarize four perspectives,
- Add prefetch instructions.
- Avoid the routine of cache miss.
- Process packets in burst instead of one by one.
- Avoid repeated loading.
Version 1: Add prefetch instructions
First consider adding prefetch instructions to free the mbuf. In this way, cache miss is reduced from 43.54% to 25.26% (in figure 9), and the throughput on N1SDP platform has a 4.2% improvement.
i40e_tx_free_bufs(struct i40e_tx_queue *txq)
{ struct rte_mbuf *m;
……
txep = &txq->sw_ring[txq->tx_next_dd – (n – 1)];
+ for (i = 0; i < n; i++)
+ rte_prefetch0((txep + i)->mbuf);
m = rte_pktmbuf_prefree_seg(txep[0].mbuf);
……
}Version 2: Avoid the cache miss routine and apply burst process
The tx_free function frees mbuf one by one, and free operation would cause cache flushing each time. Therefore, consider about avoiding the cache miss routine and applying the burst process. If mbufs ready to be freed all come from the same memory pool, try to collect 32 mbufs and put them back to the memory pool together. In this way, flushing frequency is reduced, and mempool_put API is called less. With the change, cache miss disappears (in figure 10), and the throughput improves 18.4% on N1SDP platform.
i40e_tx_free_bufs(struct i40e_tx_queue *txq)
{ struct rte_mbuf *m;
……
txep = &txq->sw_ring[txq->tx_next_dd – (n – 1)];
+ if (txq->offloads & DEV_TX_OFFLOAD_MBUF_FAST_FREE) {
+ for (i = 0; i < n; i++) {
+ free[i] = txep[i].mbuf;
+ txep[i].mbuf = NULL;
+ }
+ rte_mempool_put_bulk(free[0]->pool, (void **)free, n);
+ goto done;
+ }
m = rte_pktmbuf_prefree_seg(txep[0].mbuf);
……
+done:
/* buffers were freed, update counters */
txq->nb_tx_free = (uint16_t)(txq->nb_tx_free + txq->tx_rs_thresh);
txq->tx_next_dd = (uint16_t)(txq->tx_next_dd + txq->tx_rs_thresh);
……
}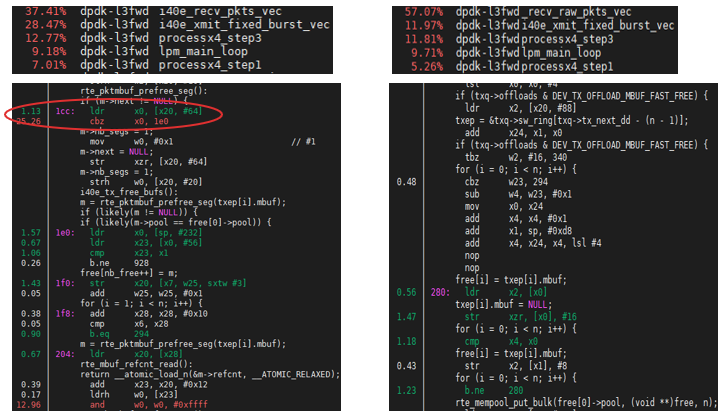
Figure 9: Cache miss with version 1 Figure 10: Cache miss with version 2
Loop unrolling
Loop unrolling attempts to optimize a program's execution speed by eliminating instructions which control the loop, it is an approach known as space-time tradeoff. Rewrite loops in sequence of similar independent statements. See the following bullets, summarize three advantages,
- Minimize branch penalty.
- Execute instructions in parallel if statements are independent in each cycle because Arm has a weakly ordered memory model.
- Implement instructions dynamically.
Use i40e_tx_free_bufs function as an example, loop unrolling free operation gains 5.3% improvement for virtio PVP test case.
Reduced memory footprint
Current per core cache implementation stores pointers to mbufs on 64b architectures, and each pointer consumes 64b. Replace this way with index-based implementation which uses based address plus offset index to address the buffer. This reduces the amount of memory and cache required for per core.
Batch process is a big step to achieve performance optimization. Effective use of cache and memory bandwidth is the most critical area for batch process. SIMD instructions can make more effective use of bandwidth.
SIMD means single instruction and multiple data access. Operate simultaneously on multiple data elements in a vector register. The Arm NEON instruction is based on 128-bit registers, and SVE allows using the wide registers. The software implementation for utilizing Neon/SVE registers is a challenge. Take care when defining the data structure because SIMD accesses the wide registers. The rte_mbuf is SIMD-friendly to avoid performance degradation.
One example is to swap source MAC and destination MAC on Arm platform. By using NEON intrinsic, 20% performance is gained because of saving CPU cycles and swapping four packets at a time.
+ const uint8x16_t idx_map = {6, 7, 8, 9, 10, 11, 0, 1, 2, 3, 4, 5,12, 13, 14, 15};
……
// Use NEON intrinsic vld to batch load ethernet header.
+ v0 = vld1q_u8((uint8_t const *)eth_hdr[0]);
+ v1 = vld1q_u8((uint8_t const *)eth_hdr[1]);
+ v2 = vld1q_u8((uint8_t const *)eth_hdr[2]);
+ v3 = vld1q_u8((uint8_t const *)eth_hdr[3]);
// Use NEON intrinsic vqtbl to swap byte 0-5 with byte 6-11, byte 12-15 keep unchanged.
+ v0 = vqtbl1q_u8(v0, idx_map);
+ v1 = vqtbl1q_u8(v1, idx_map);
+ v2 = vqtbl1q_u8(v2, idx_map);
+ v3 = vqtbl1q_u8(v3, idx_map);
// Use NEON intrinsic vst to batch store ethernet header.
+ vst1q_u8((uint8_t *)eth_hdr[0], v0);
+ vst1q_u8((uint8_t *)eth_hdr[1], v1);
+ vst1q_u8((uint8_t *)eth_hdr[2], v2);
+ vst1q_u8((uint8_t *)eth_hdr[3], v3);Barrier optimization
The memory model describes the access behavior to shared memory by multi-processor systems. The Arm and PowerPC architectures support a weakly ordered model and x86 supports a strongly ordered memory model. Consider the following table that shows the ordering guarantees provided by theses architectures for various sequences of memory operation.
| Memory Ordering Sequences | Arm | X86 | PowerPC |
| Load - Load | Reordering - Allowed | Reordering - Not Allowed | Reordering - Allowed |
| Load - Store | Reordering - Allowed | Reordering - Not Allowed | Reordering - Allowed |
| Store - Store | Reordering - Allowed | Reordering - Not Allowed | Reordering - Allowed |
| Store - Load | Reordering - Allowed | Reordering - Allowed | Reordering - Allowed |
The table shows that the Arm architecture supports four reordered possibilities of memory operation. If an algorithm requires to execute memory operation in a program order, utilize memory barriers to enforce it.
In Arm architecture, there are four types of barrier instructions [1].
Instruction Synchronization Barrier (ISB) is the heaviest, it flushes the instruction pipeline in hardware terms. Typically use ISB in memory management, cache control, context switching, and moving code in memory.
Data Memory Barrier (DMB) is the lightest, it prevents reordering data access instructions, which include load and store, except the fetch instruction. Data access prior to the DMB is visible to other requesters before data access which is after the DMB. It acts within the specified shareability domain.
Data Synchronization Barrier (DSB) is heavier than DMB. DSB enforces the same ordering as DMB, but it blocks executing any further instructions, not just load and store, until completing synchronization.
Arm64 adds new load and store instructions with implicit barrier semantics such as load-acquire and store-release. The instructions are less restrictive than either DMB or DSB instruction.
Unnecessary use of barrier instructions can reduce software performance. Consider carefully whether a barrier is necessary in a specific situation, and which barrier is the correct one to use. DPDK’s default memory model is Arm’s weakly ordered memory model.
Remove unnecessary barriers
In the following example, use a x86 compiler barrier originally to ensure the order between twice descriptor access. The previous code changes simplify the code logic, and removal of some memory access results in no need of the barrier. Remove the unnecessary barrier, 2.0% - 4.3% performance gain is measured on Arm platform under the test.
_recv_raw_pkts_vec:
……
rte_mbuf_prefetch_part2(rx_pkts[pos + 2]);
rte_mbuf_prefetch_part2(rx_pkts[pos + 3]);
}
- /* avoid compiler reorder optimization */
- rte_compiler_barrier();
/* pkt 3,4 shift the pktlen field to be 16-bit aligned */
uint32x4_t len3 = vshlq_u32(vreinterpretq_u32_u64(descs[3]), len_shl);#define rte_compiler_barrier() do { \
asm volatile (“” : : : “memory”); \
} while (0)Use lighter barriers
Another example is to relax the heavy barrier in i40e Tx vectorized path. PCI_REG_WRITE maps PCIe address space to CPU memory space, then writes the tail register. For PCIe, because coherent memory is enabled, rte_cio_wmb (dmb) barrier is enough rather than the heavier rte_wmb (dsb) barrier. With this change, 4% - 7% performance uplifts on Arm platform.
i40e_xmit_fixed_burst_vec:
- I40E_PCI_REG_WRITE(txq->qtx_tail, tx_id);
+ rte_cio_wmb();
+ I40E_PCI_REG_WRITE_RELAXED(txq->qtx_tail, tx_id);
return nb_pkts
}#define I40E_PCI_REG_WRITE(reg, value) \
{ rte_io_wmb();
rte_write32((rte_cpu_to_le_32(value)), reg);
}
#define I40E_PCI_REG_WRITE_RELAXED(reg, value) \
rte_write32_relaxed((rte_cpu_to_le_32(value)), reg)
#define rte_wmb() asm volatile(“dsb st” : : : “memory”)
#define rte_cio_wmb() asm volatile(“dmb oshst” : : : “memory”)Save ordering
Analyze the following context, load-acquire only acts with a branch case. Remove unnecessary load-acquire barriers before if-branch.
search_one_bucket_lf:
if (key_idx != EMPTY_SLOT) {
k = (struct rte_hash_key *) ((char *)keys + key_idx * h->key_entry_size);
- pdata = __atomic_load_n(&k->pdata, __ATOMIC_ACQUIRE);
if (rte_hash_cmp_eq(key, k->key, h) == 0) {
if (data != NULL)
- *data = pdata;
+ *data = __atomic_load_n(&k->pdata, __ATOMIC_ACQUIRE);
return key_idx - 1;
}
}Adopt C11 memory model
Not all algorithms need the stronger ordering guarantees. Take the case of simple protecting the critical section [2].

Figure 11: Spinlock protection sample
The operation inside the critical section is not allowed to hoist ‘spinlock-lock’ and sink ‘spinlock-unlock’. But operation above the section is allowed to sink ‘spinlock-lock’ and operation after the section is allowed to hoist ‘spinlock-unlock’. In this case, use locks to protect the critical section. It does not require the lock and unlock function to provide full barriers. This gives more flexibility to CPU to execute instructions efficiently during run time. Note that this is just one example, and many other algorithms have similar behaviors. The Arm architecture provides load and store instructions, atomic instructions, and barriers that support sinking and hoisting of memory operation in one direction. To support architectural differences, DPDK adopts C11 memory model to help implement one-way barriers.
Next is an example to replace full barriers with C11 one-way barriers for synchronizing points in the shared memory. Use avail flag and used flag to synchronize the virtio packed vring. Replace the wmb barrier with store_release and the rmb barrier with load_acquire.
By testing vhost-user and virtio-user PVP case, 9% performance gain is measured in the RFC2544 test on Thunderx2 platform. And 11% perf gain is measured on Ampere platform by VM2VM case benchmarking.
+static inline uint16_t
+virtqueue_fetch_flags_packed(struct vring_packed_desc *dp, uint8_t weak_barriers)
+{
+ uint16_t flags;
+ if (weak_barriers) {
+ /* x86 prefers to using rte_smp_rmb over __atomic_load_n as it reports
+ * a better perf(~1.5%), which comes from the saved branch by the compiler.
+ * The if and else branch are identical with the smp and cio barriers both
+ * defined as compiler barriers on x86.
+ */
+#ifdef RTE_ARCH_X86_64
+ flags = dp->flags;
+ rte_smp_rmb();
+#else
+ flags = __atomic_load_n(&dp->flags, __ATOMIC_ACQUIRE);
+#endif
+ } else {
+ flags = dp->flags;
+ rte_cio_rmb();
+ }
+ return flags;
+}
+static inline void
+virtqueue_store_flags_packed(struct vring_packed_desc *dp,
+ uint16_t flags, uint8_t weak_barriers)
+{
+ if (weak_barriers) {
+ /* x86 prefers to using rte_smp_wmb over __atomic_store_n as it reports
+ * a better perf(~1.5%), which comes from the saved branch by the compiler.
+ * The if and else branch are identical with the smp and cio barriers both
+ * defined as compiler barriers on x86.
+ */
+#ifdef RTE_ARCH_X86_64
+ rte_smp_wmb();
+ dp->flags = flags;
+#else
+ __atomic_store_n(&dp->flags, flags, __ATOMIC_RELEASE);
+#endif
+ } else {
+ rte_cio_wmb();
+ dp->flags = flags;
+ }
+}New features
This section introduces new features implemented in DPDK, and some are based on the C11 memory model.
Ticket lock & mcs lock
If there are multiple threads contending, they all attempt to take the spinlock at the same time once it is released. This results in a huge amount of processor bus traffic, which is a huge performance killer. Ordering the lock-takers so that they know who is next in line for the resource, the amount of bus traffic can be vastly reduced.
Introduce ticket lock to resolve this. It gives each waiting thread a ticket and they can take the lock one by one. First come, first serviced. It avoids starvation for too long time and is more predictable.
Furthermore, MCS lock is implemented. It provides scalability by spinning on the CPU and thread local variable, and avoids expensive cache bouncing. It provides fairness by maintaining a list of acquirers and passing the lock to each CPU/thread in the order they acquired the lock.
RCU library
RCU library supports quiescent state-based memory reclamation method. This library helps identify the quiescent state of reader threads so that the writers can free the memory associated with the lockless data structures. It targets for the scenario where update is less frequent than read, like the routing table. RCU library has been integrated with LPM library.
Zero-copy ring
It is common to deploy DPDK applications in semi-pipeline model. In this model, a few cores (typically 1) are designated as I/O cores which transmit and receive packets from NICs and packet processing cores. I/O cores and packet processing cores would exchange packets over a ring. Typically, such applications receive mbufs in a temporary array, then copy mbufs to the ring. Depending on the requirements, copy packets in batches of 32, 64 or 128 and this results in memory copy of 256B, 512B, or 1024B.
The zero-copy APIs help avoid intermediate copy by exposing the ring space directly to the application.
Conclusion
This article goes over the internal principles of DPDK optimization on Arm. The topic is too complex and extensive to fit in one article, for better understanding, one can refer to the link https://www.dpdk.org/ for more details.
Then evaluate optimization work with examples and explanation. For example, enable vector process to increase data path throughput. Use C11 memory model wherever possible to leverage Arm's relaxed memory model. Tune memory barriers to be optimal for Arm platforms. All these helps provide better instructions per cycle (IPC) and improve the overall performance.
Last but not the least, implement ticket lock and mcs lock to improve the lock performance. Use lock-free algorithms to provide scalability across enormous number of cores in a SoC. How to integrate them with existing applications is further considered.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK