

B+树数据库加锁历史
source link: http://catkang.github.io//2022/01/27/btree-lock.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

B+树数据库加锁历史
作为数据库最重要的组成之一,并发控制一直是数据库领域研究的热点和工程实现中的重点和难点。之前已经在文章《浅析数据库并发控制》[4]中介绍了并发控制的概念和实现方式。简单的说,就是要实现:并行执行的事务可以满足某一隔离性级别[5]的正确性要求。要满足正确性要求就一定需要对事务的操作做冲突检测,对有冲突的事务进行延后或者丢弃。根据检测冲突的时机不同可以简单分成三类:
- 在操作甚至是事务开始之前就检测冲突的基于Lock的方式;
- 在操作真正写数据的时候检测的基于Timestamp的方式;
- 在事务Commit时才检测的基于Validation的方式。
这三种策略的立足点其实是对冲突的乐观程度,越乐观,也就是认为冲突发生越少,就越倾向于推迟冲突的检测。直观的也可以看出,越晚的冲突检测越有可能获得高的并发。但当冲突真正出现时,由于前面的操作可能都需要一笔勾销,因此在冲突较多的场景下,太乐观反而得不偿失。而冲突归根结底是由用户的使用场景决定的,在不能对用户场景做太多假设的通用数据库中,毫无疑问,基于Lock的方式显得更为合适。除此之外,由于MVCC的广泛应用消除了读写之间的冲突,使得Lock带来的并发影响大大降低,也使得基于Lock的并发控制仍然是主流。 对数据库的数据加锁这件事情,本身是跟数据的组织方式是密不可分的,数据组织方式可能给加锁带来限制,同时利用组织方式的特性,可能也能改造和优化加锁过程。在磁盘数据库中,数据组织方式的王者非B+树莫属,而且已经半个世纪有余。B树是1972年Bayer在《Organization and Maintenance of Large Ordered Indices》一文中提出的[1]。其通过多叉树的方式,实现从单个节点中索引大量子树。从而大大降低了整个树高,将二叉树中大量的随机访问转化为顺序访问,减少磁盘寻道,完美契合了磁盘顺序访问性能远好于随机访问的特性,以及其块设备接口。本文主要关注的就是如何在B+树上实现基于Lock的并发控制,限于篇幅本文暂时抛开MVCC的影响。
1. B+Tree
BTree在结构上有大量变种,本文聚焦于Bayer 1977年在《Concurrency of Operations on B-Trees》中提出的B+ Tree(或B* Tree)[2]:所有的数据信息都只存在于叶子节点,中间的非叶子节点只用来存储索引信息,这种选择进一步的增加了中间节点的索引效率,使得内存可以缓存尽可能多的索引信息,减少磁盘访问;除根节点以外,每个节点的键值对个数需要介于M/2和M之间,超过或者不足需要做分裂或者合并。 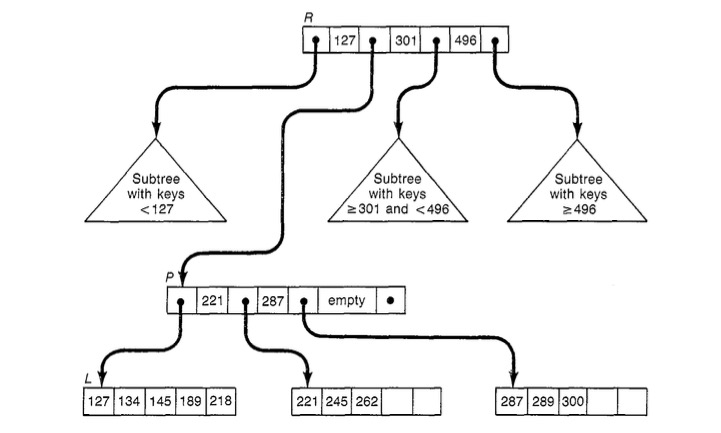
如上图所示是树中的一部分,每个节点中包含一组有序的key,介于两个连续的有序key,key+1中间的是指向一个子树的指针,而这个子树中包含了所有取值在[key, key+1)的记录。 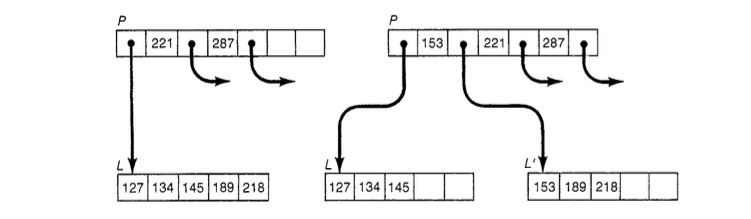 当节点中的记录插入超过M/2时,需要触发Split,如上图将节点L中153之后的记录拆分到新节点中,同时需要修改在其父节点中插入一条新的Key 153以及对应的指针。分裂的过程可能继续向更上层传到。与之对应的是从树中删除数据时,可能触发节点合并,同样需要修改其父节点,同样可能向更上层传导。
当节点中的记录插入超过M/2时,需要触发Split,如上图将节点L中153之后的记录拆分到新节点中,同时需要修改在其父节点中插入一条新的Key 153以及对应的指针。分裂的过程可能继续向更上层传到。与之对应的是从树中删除数据时,可能触发节点合并,同样需要修改其父节点,同样可能向更上层传导。
2. Lock
首先要明确,并发控制中的Lock跟我们在多线程编程中保护临界区的Lock不是一个东西,这个的区别会在后面讲到。事务在操作数据库时,会先对要访问的元素加对应的Lock,为了更高的并发, Lock通常有不同的Mode,如常见的读锁SL,写锁WL,不同Mode的锁相互直接的兼容性可以用兼容性表来表示: 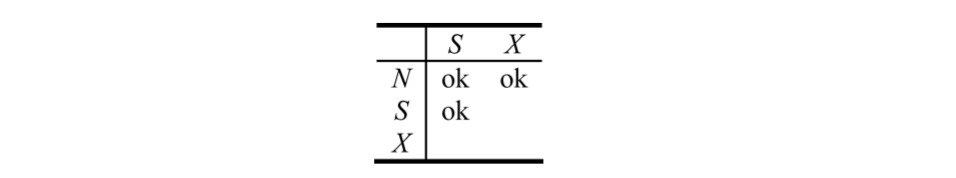
如多个事务可以同时持有SL,但已经有WL的元素不能再授予任何事务SL或WL。数据库通常会有一个调度模块来负责资源的加锁放锁,以及对应事务的等待或丢弃。所有的锁的持有和等待信息会记录在一张Lock Table中,调度模块结合当前的Lock Table中的状况和锁模式的兼容表来作出决策。如下图所示:事务T3已经持有了元素A的写锁WL,导致事务T1和T2无法获得读锁SL,从而在队列中等待,直到T3结束释放WL后,调度模块再依次唤醒等待的事务。 《浅析数据库并发控制》[4] 中提到了,为了实现Serializable,通常会按照两阶段锁(2PL)的规则来进行加锁,也就是将事务的执行过程分为Growing阶段以及Shrinking阶段,Growing阶段可以对任何元素加锁但不能放锁,一旦有一次放锁就进入了Shrinking阶段,这个阶段就不能再对任何元素加锁了。通常的实现中,Shrinking阶段会在事务Commit时。可以用反证法方便的证明遵守2PL的加锁规则的并发事务满足Seralizable。
本文将要讨论的就是如何在B+Tree数据库上,基于Lock的方式,来实现高并发、高效的数据库并发控制。我们会按照时间先后顺序逐步展开,并分析每前进一步时的思路和背后的动机。即使是那些历史的方案,笔者认为也是很有价值进行研究的,他们其中一部分可能已经不是最初的用途,却在新的方向上发扬光大;另一部分虽然暂时被淘汰,但在未来随着新的硬件软件发展,以及新的数据库需求的出现,可能又会焕发新的生机。本文主要关注B+Tree加锁策略的两个指标:
- 并发度(Concurrency):在满足正确性的前提下,能够支持多少种相同或不同的数据库操作的并发。
- 加锁开销(Locking Overhead):通过调度模块请求加锁,其本身的开销大小。
传统的加锁策略
这个时期的加锁策略认为树节点是最小的加锁单位。由于B+Tree的从根向下的搜索模式,事务需要持有从根节点到叶子节点路径上所有的锁。而两阶段锁(2PL)又要求所有这些锁都持有到事务Commit。更糟糕的是,任何插入和删除操作都有可能导致树节点的分裂或合并(Structure Modification Operations, SMO),因此,对根结点需要加写锁WL,也就是说任何时刻只允许一个包含Insert或Delete操作的事务进行。显而易见,这会严重的影响访问的并发度。
Tree Protocol
针对这个问题,Tree Protocol[3]应运而生,他正是利用B+Tree这种从根访问的特性,实现在放松2PL限制,允许部分提前放锁的前提下,仍然能够保证Serializable:
- 先对root加锁
- 之后对下一层节点加锁必须持有其父节点的锁
- 任何时候可以放锁
- 对任何元素在放锁后不能再次加锁
这种加锁方式也被称为Lock Coupling。直观的理解:虽然有提前放锁,但自root开始的访问顺序保证了对任何节点,事务的加锁顺序是一致的,因此仍然保证Seralizable。Tree Protocol实现上需要考虑一个棘手的问题:就是对B+Tree而言,一直要搜索到叶子结点才可以判断是否发生SMO。以一个Insert操作为例,悲观的方式,对遇到的每一个节点先加写锁,直到遇到一个确认Safe的节点(不会发生SMO);而乐观的方式认为SMO的相对并不是一个高频操作,因此只需要先对遇到的每个节点加读锁,直到发现叶子节点需要做分裂,才把整个搜索路径上所有的读锁升级写锁(Upgrade Lock)。当两个持有同一个节点读锁的事务同时想要升级写锁时,就会发生死锁,为了避免这种情况,引入了Update Lock Mode,只有Update Lock允许升级,并且Update Lock之间不兼容,这其实是一种权衡。
Blink Tree
仔细分析会发现,2PL和Tree Protocol中面临的最大问题其实在于:节点的SMO时需要持有其父节点的写锁。正因为如此才不得不在搜索过程提前对所有节点加写锁,或者当发现SMO后再进行升级,进退维谷。而之所以这样,是由于需要处理父节点中的对应key及指针,节点的分裂或合并,跟其父节点的修改是一个完整的过程,不允许任何其他事务看到这个过程的中间状态。针对这个问题,Blink Tree[7]巧妙的提出对所有节点增加右向指针,指向其Sibling节点,这是个非常漂亮的解决方案,因为他其实是提供了一种新的节点访问路径,让上述这种SMO的中间状态,变成一种合法的状态,从而避免了SMO过程持有父节点的写锁。 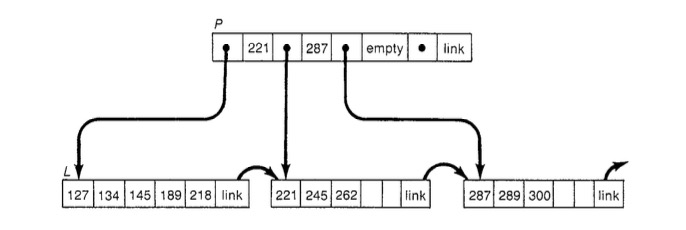
对Record加Lock而不是Page
上面讲到的传统的加锁策略,认为Btree的节点是加锁的最小单位,而所做的努力一直是在降低单个事务需要同时持有的锁的节点数,能不能更进一步提升Btree的并发能力呢?《Principles and realization strategies of multilevel transaction management》[8]对这个问题进行了深入的研究,如下图所示: 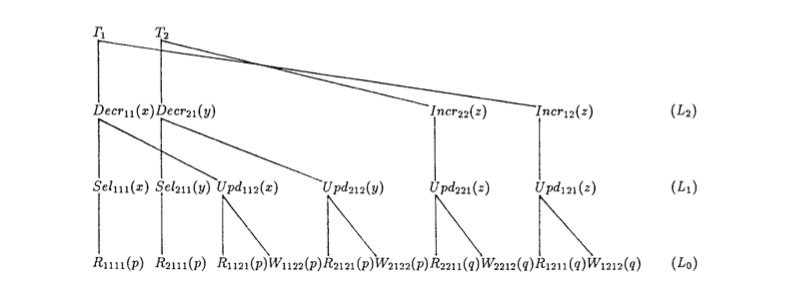 以两个转账业务T1,T2为例,用户A和用户B分别转账给用户C一笔钱,在数据库中的执行可以分为三层,最高层L2从用户角度看,A和B的账户上的金额减少,C的账户金额增加;中间层L1在记录角度,代表A和B账户金额的Record x、Record y做了查询以及更新操作,而代表C账户金额的Record z做了更新操作;最下层L0站在Page的角度,Record x以及y都在Page p上,而Record z在Page q上,因此Page p以及Page q都被两个事务读写。按照上面讲到的对Page加Lock的做法,T2必须等T1执行完成并释放p,q两个Page上的锁。这种接近串行的并发度当然不是我们想要的。因此《Principles and realization strategies of multilevel transaction management》提出分层事务的解决方案,如果能在L1层,也就是对Record而不是Page加锁,就可以避免T1和T2在Page p Lock上的等待,如上图所示,T1和T2对Record x和Record y的操作其实是并发执行的。而L0层对Page的并发访问控制可以看做是上层事务的一个子事务或嵌套事务,其锁持有不需要持续整个最外层事务的生命周期。沿着这个思路,ARIES/KVL出现了。
以两个转账业务T1,T2为例,用户A和用户B分别转账给用户C一笔钱,在数据库中的执行可以分为三层,最高层L2从用户角度看,A和B的账户上的金额减少,C的账户金额增加;中间层L1在记录角度,代表A和B账户金额的Record x、Record y做了查询以及更新操作,而代表C账户金额的Record z做了更新操作;最下层L0站在Page的角度,Record x以及y都在Page p上,而Record z在Page q上,因此Page p以及Page q都被两个事务读写。按照上面讲到的对Page加Lock的做法,T2必须等T1执行完成并释放p,q两个Page上的锁。这种接近串行的并发度当然不是我们想要的。因此《Principles and realization strategies of multilevel transaction management》提出分层事务的解决方案,如果能在L1层,也就是对Record而不是Page加锁,就可以避免T1和T2在Page p Lock上的等待,如上图所示,T1和T2对Record x和Record y的操作其实是并发执行的。而L0层对Page的并发访问控制可以看做是上层事务的一个子事务或嵌套事务,其锁持有不需要持续整个最外层事务的生命周期。沿着这个思路,ARIES/KVL出现了。
ARIES/KVL 峰回路转
《ARIESIKVL: A Key-Value Locking Method for Concurrency Control of Multiaction Transactions Operating on B-Tree Indexes》[10]提出了一套完整的、高并发的实现算法,引导了B+Tree加锁这个领域今后几十年的研究和工业实现。ARIES/KVL首先明确的区分了B+Tree的物理内容和逻辑内容,逻辑内容就是存储在B+Tree上的那些数据记录,而B+Tree自己本身的结构属于物理内容,物理内容其实事务是不关心的,那么节点分裂、合并这些操作其实只是改变了B+Tree的物理内容而不是逻辑内容。因此,ARIES/KVL就将这些从Lock的保护中抽离出来,也就是Lock在Record上加锁,对物理结构则通过Latch来保护其在多线程下的安全。这里最本质的区别是Latch不需要在整个事务生命周期持有,而是只在临界区代码的前后,这其实也可以看作上面分层事务的一种实现。更多Lock和Latch的区别见下表: 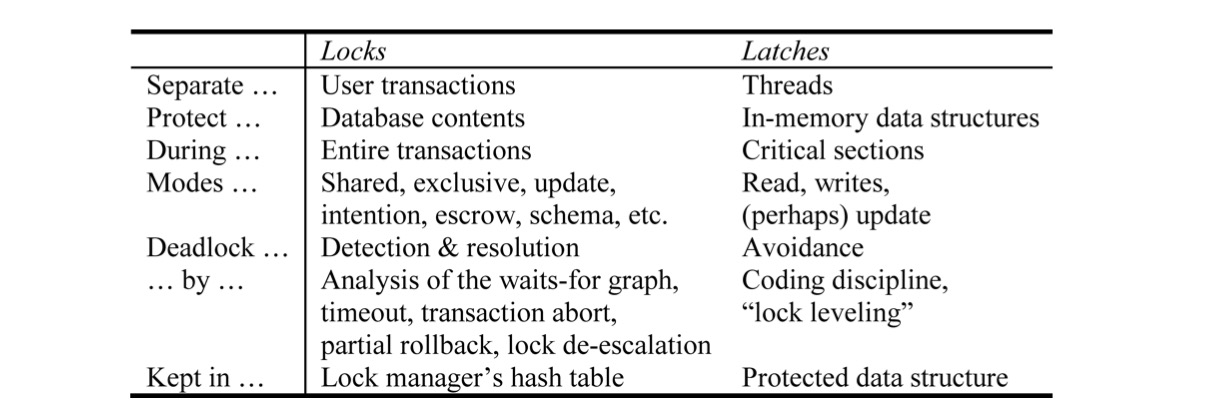
Latch保护物理结构
可以看出Latch才是我们在多线程编程中熟悉的,保护临界区访问的锁。通过Latch来保护B+Tree物理结构其实也属于多线程编程的范畴,上述传统的B+Tree加锁方式的优化,也可以直接无缝转化过来。只是将Lock换成的Latch,其作用对象也从事务之间变成线程之间。比如Lock Coupling变成了Latch Coupling;比如对中间结点先持有Read Latch或Update Latch,而不是Write Latch,等需要时再升级;又比如,可以采用Blink的方式可以避免SMO操作持有父节点Latch。以及这个方向后续的一些无锁结构如BW-Tree,其实都是在尝试进一步降低Latch对线程并发的影响。本文对这里不再进一步探讨,而是回到本文主要关心的事务之间并发控制上,也就是保护逻辑内容的Lock。
Lock保护逻辑结构
有了这种清晰的区分,事务的并发控制就变得清晰很多,不再需考虑树本身的结构变化。假设事务T1要查询、修改、删除或插入一个Record X,而Record X所在的Page为q,那么加Lock过程就变成这样:
Search(X)and Hold Latch(q);
SLock(X) or WLock(X);
// Fetch, Insert or Delete
Unlatch(q);
....
T Commit and Unlock(X)
在第一步对Btree的查找过程,会按照上面所说的Latch Coupling的方式申请及释放对应的Page Latch,最终持有目标Record所在叶子结点的Latch,如果Insert或者Delete需要导致树结构变化,也就是发生SMO,只需在Latch的保护下完成即可,不涉及Lock。之后在第三步向调度器申请Record Lock,如果能马上满足,那么这个Page Latch就可以释放了。但如果这个Lock需要等待,持有Latch等待显然是不明智的,会让并发回退到之前对Page加Lock的方案。为了解决这个问题,ARIES/KVL采用了Condition Lock加Revalidation的方式,就是说先对Record加Conditional Lock,这种Lock如果不能满足会立即返回而不是阻塞等待,如果失败则先释放Page Latch,再对Record 加Unconditional Lock来阻塞等待。等这个Lock可以满足并返回的时候,由于这段时间没有Latch保护,Page或整个树结构都发生了变化,当然不能继续之前的操作了。这个时候就要Revalidation,其实就是判断自己需要的叶子节点以及其所有的祖先节点有没有发生变化,需要从未变化的那层重新搜索,这里的办法就是在之前释放Latch之前先记录这些节点的版本号,Revalidation的时候直接找到版本号没有变化的位置。
Key Range Locking
前面这套结合Latch和Lock方案,已经可以很好的支持对单条Record的增删改查。但很多数据库访问并不是针对某一条记录的,而是基于条件的。比如查询满足某个条件的所有Record,这个时候就会出现《数据库事务隔离发展历史》[5]中提到的幻读的问题,也就是在事务的生命周期中,由于新的满足条件的Record被其他事务插入或删除,导致该事务前后两次条件查询的结果不同。这其实是要求,条件查询的事务和插入/删除满足这个条件Record的事务之间,有相互通信或冲突发现的机制,最直接的想法是对所有可能的,还不存在的Key也加锁,在大多数情况下,由于Key范围的无限,这都是不可接受的。传统的解决幻读的方案是谓词锁(Predicate Lock),也就是直接对查询条件加锁,每次插入删除需要判断是否与现有的判断条件冲突,但通用数据库中,条件千变万化,判断条件冲突这件事情开销极大。也正是因此,谓词锁并没有成为主流。在B+Tree上,由于其Key有序的特点,通常会采用Key Range Locking,也就是对Key加锁,来保护其旁边的区间Range,有很多中选择,如下图所示:

其中最常见的一种实现是Next Key Locking,也就是上图中最上面的一条线,通过对1174加锁,来保护1174这个节点以及其前面和1171之间的Gap。 我们来看下增加了Next Key Lock的加锁过程如下。假设当前Record X的下一条记录是Y,且都在Page q,X和Y都满足条件查询事务T1的查询条件,T1会重复上面的加锁过程并持有X和Y上的Lock。这时事务T2尝试在X和Y之间插入Record M,我们看看它的加锁过程:
Search(M,Y)and Hold Latch(q);
XLock(Y);
XLock(M);
Insert M into q
Unlatch(q);
....
T2 Commit and Unlock(M), Unlock(Y)
跟之前相比,这里多了对Next Key也就是Y加锁,正是由于这个锁,可以发现持有Y上SLock,并且还没有提交的查询事务T1,等待直到T1 完成Commit并放锁。为了追求更高的并发度,会有一些手段来改进Key Range Locking:
Instant Locking
可以看到,上述加锁过程中,Insert需要对要插入位置的Next Key加Lock,如果已经是最大则需要对正无穷加Lock,并持有整个事务生命周期。尤其在高频率顺序插入的场景,这个Next Key Lock就会成为明显的瓶颈。Instant Locking的方案很好的解决了这个问题。顾名思义,Instant Locking只在瞬间持有这把Next Key Locking,其加锁是为了判断有没有这个Range冲突的读操作,但获得锁后并不持有,而是直接放锁。乍一看,这样违背了2PL的限制,使得其他事务可能在这个过程获得这把锁。通过巧妙的利用Btree操作的特性,以及Latch及Lock的配合,可以相对完美的解决这个问题,如下是引入Instant Locking后的Insert加Next Key Lock的流程:
Search(M,Y)and Hold Latch(q);
XLock(Y);
Unlock(Y)
XLock(M);
Insert M into q
Unlatch(q);
....
T Commit and Unlock(M)
可以看出,Y上Lock的获取和释放,和插入新的Record两件事情是在Page q的Latch保护下进行的,因此这个中间过程是不会有其他事务进来的,等Latch释放的时候,新的Record其实已经插入,这个X到Y的区间已经被划分成了,X到M以及M到Y,新的事务只需要对自己关心的Range加锁即可。分析这个过程,可以提前放锁的根本原因是:Insert的New Record在其他事务对这个Range加锁的时候已经可见。Delete就没有这么幸运了,因为Delete之后这个Key就不可见了,因此Delete的持有的Next Key Locking似乎不能采用Instant Locking,这个时候Ghost Record就派上用场了。
Ghost Records
Ghost Record的思路,其实跟之前讲到拆分物理内容和逻辑内容是一脉相承的,Ghost Record给每个记录增加了一位Ghost Bit位,正常记录为0,当需要删除某个Record的时候,直接将其Ghost Bit修改为1即可,正常的查询会检查Ghost Bit,如果发现是1则跳过。但是Ghost Record是可以跟正常的Record一样作为Key Range Lock的加锁对象的。可以看出这相当于把删除操作变成了更新操作,因此删除事务不在需要持有Next Key Lock。除此之外,由于回滚的也变成了修改Ghost Bit,不存在新的空间申请需要,因此避免了事务回滚的失败。Ghost Record的策略也成为大多数B+Tree数据库的必选实现方式。 当然,这些Ghost Record最终还是需要删除的,其删除操作通常会放到后台异步进行,由于Ghost Record对用户请求是不可见的,因此这个删除过程只是对物理结构的改变,也不需要加Lock。但Record的删除会导致其左右的两个Lock Range合并,因此这个过程除了需要Page的Latch之外,还需要获得Lock系统中Lock的Latch,在Lock的Latch保护下对Lock Range合并。 除了这种延迟删除的Ghost Record之外,还有一种Ghost Record也称为Fence Key,是在Page的末尾添加一个独立的Key值记录这个Page所在子树的分隔Key,实现上可以在Page Split的时候从Parent节点拷贝而来。这种做法最大的好处就是避免加Next Key Lock的时候对后继结点的访问需求。
Keep Going
追求更好的B+Tree加锁方案的努力不曾停止,这里就介绍他们中的一些佼佼者,以及其设计思路。
ARIES/IM
实际的数据库中,单个表常常会有大量的二级索引,也就是大量的B+Tree,显然对每个B+Tree分别加锁开销是很大的。Mohan C在文章《ARIES/IM: an efficient and high concurrency index management method using write-ahead logging》[11]中提出了ARIES/IM,将加锁对象由B+Tree上的Key-Value变成了其最终指向的数据,这样无论有多少二级索引最终都只需要加一把锁。显而易见的,这种做法在降低锁开销的同时也降低了并发度。另外,从这个例子中可以清楚地看到:对Locking Resource的选择是在Concurrency 和 Locking Overhead之间的权衡。
Lomet D B.在《Key Range Locking Strategies for Improved Concurrency》[13]中分析了上面的ARIES/KVL和ARIES/IM,并提出从两个方向的改进。首先是Range Lock的加锁范围,KVL和IM中的Range都是对Next Key以及中间的Gap同时加锁,一定程度上限制了对Key和对Gap访问的并发,KRL提出将二者拆分,分别加锁。这种选择在提高并发度的同时,由于需要加更多的锁而增加了加锁开销。第二个改进提出了更精确的锁Mode,包括Intention Update,Intention Insert以及Intention Delete,其基本思路就是用更精确的锁mode区分操作类型从而更大程度的挖掘他们之间的并发可能。
Hierarchical Locking
Hierarchical Locking其实有非常久的历史了,初衷是为了让大事务拿大锁,小事务拿小锁,来在事务并发度及加锁开销做权衡,常见的加锁层级包括对表加锁,对索引加锁,以及对Record加锁。Hierarchical Locking对高层级的加锁对象通常采用Intention Lock来增加并发, 比如Intention X Lock自己是相互兼容的。随着硬件发展,数据库的表和索引也在变大,同时在上述的Range Lock语义下,一个事务的查询范围内,如果有较多的Record,那么就需要加很多的Range Lock,大量的Lock会带来大量的内存占用,消耗大量的CPU。因此Graefe G.在《Hierarchical locking in B-tree indexes》[14]中提出了可以在Table和Key之间增加更多的加锁粒度,其中探索了两种思路,一种是利用B+Tree的层级关系,在中间节点的Key上加Range Lock;另一种是对Key的前缀加锁,这其实是更接近传统谓词锁的一种方式。除此之外,《Hierarchical locking in B-tree indexes》还探索了每种方案下,随着负载变化动态的Lock层级变化策略。
Early Lock Release
传统的2PL为了保证Serializable,要求事务要持有锁一直到事务Commit,但如果拉长事务Commit的过程看,其包括进入Commit状态后内存状态的改变,以及等待Commit Log落盘的时间,其中等待落盘的时间通常又大大超过了修改内存状态的时间。针对这一点,在《Efficient locking techniques for databases on modern hardware》[15]中提出了可以在等待Commit Log落盘之前就释放锁的方案,以此来提高并发度。这个方案最大的挑战就是Commit Log落盘前的Crash会导致该事务回滚,因此后续事务虽然可以提前获得锁,但还是不能早于之前的事务Commit,这一点对写事务是容易保证的,因为之后的写事务也需要写Commit Log,而Commit Log所在的REDO文件是连续的。难点在于读事务,读事务并不会写Commit Log,那么就必须增加额外的机制来阻止其提前Commit,比如《Efficient locking techniques for databases on modern hardware》中采用的对Lock加Tag以及《Controlled lock violation》[16]中调度器对Lock Violation的检查。
我们看到,B+Tree加锁的发展历史其实都是围绕着我们前面提到的两个主要问题进行的,即提高并发度和降低锁开销,而采用的手段通常包括:
- 对Lock对象或粒度的选择,比如从Page Lock到Key Lock,以及Hierarchical Locking。
- 引入新的Lock Mode,比如KRL以及没有提到的Increment Lock。
- 缩短Lock持有时间,比如Early Lock Release或Controlled Lock Violation。
回顾整个的发展过程:
- 传统阶段将Btree Page当成最小的加锁单位。围绕如何减少事务需要持有的锁的Page数量而发展:提出了Tree Protocol的来实现提前释放祖先节点的Lock;又通过Blink Tree避免对父节点的加锁;
- Multilevel Transaction尝试改变加锁的最小单位,从对Page加锁变成对Record加锁;
- ARIES/KVL将逻辑内容和物理内容分离,由Lock和Latch分别保护,并提供了一套相对完善的对Record加锁的实现算法,Key Value Locking,也基本确定了后续的发展方向。
- ARIES/KVL,ARIES/IM以及后续的很多算法都采用Key Range Locking来解决幻读的问题,并采用Instant Locking及Ghost Locking来进一步提高并发度。
- 后续的研究多围绕权衡Lock粒度、新的Lock Mode及缩短Lock持有时间等方向继续前进。
如果用横坐标表示算法的并发度,纵坐标表示加锁开销,可以看到本文提到的算法之间的关系,如下图所示,注意这里只是定性的分析。通常认为,在可接受的锁开销范围内,更倾向于获得更高的并发度。因此图中红框的部分是笔者认为现代数据库应该做到的区域。 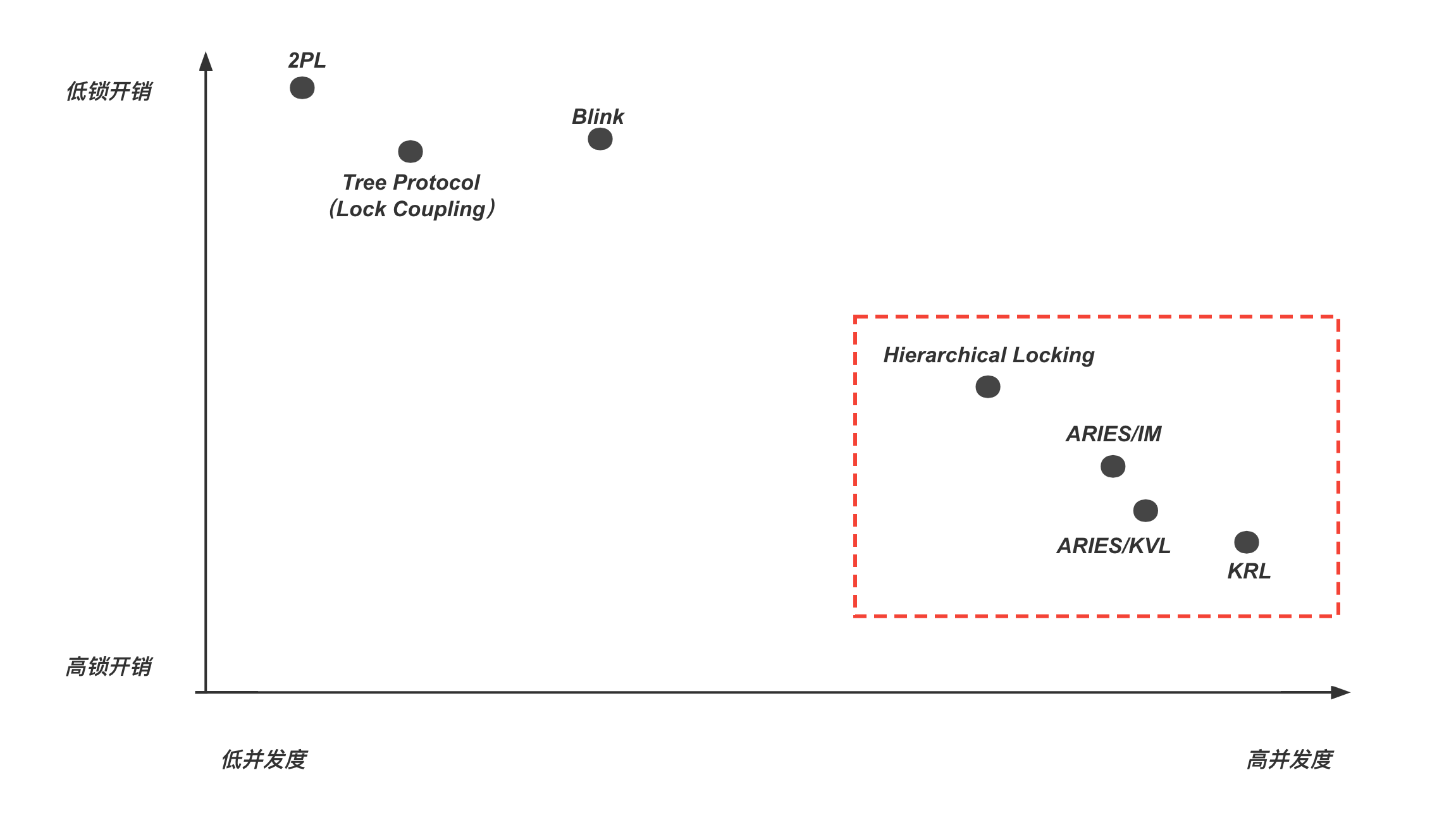
[2] Bayer R, Schkolnick M. Concurrency of operations on B-trees[J]. Acta informatica, 1977, 9(1): 1-21.
[4] http://catkang.github.io/2018/09/19/concurrency-control.html
[5] http://catkang.github.io/2018/08/31/isolation-level.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK