

训练时显存优化技术——OP合并与gradient checkpoint
source link: https://bindog.github.io/blog/2020/05/20/optimize-training-memory-by-op-fusion-gradient-checkpoint/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前几天看到知乎上的文章FLOPs与模型推理速度,文中提到一个比较耗时又占显存的pointwise操作x * sigmoid(x),这实际上是swish activation;暂且不提它背后的争议,本文主要想从这个结构入手来优化它的显存占用以及耗时,并讨论更广泛的训练时显存优化技术。
反向传播是如何工作的?
要分析清楚swish activation为什么会比较占显存,我们首先需要搞清楚反向传播是如何工作的,或者更进一步说,现有的自动求导框架是如何求出梯度的。
先明确一点,所谓自动求导框架实际上是“半自动”的:它并非直接求出一个复杂函数导数的解析形式,而是通过构建计算图和预先写好的基础函数的求导规则,结合链式求导法则实现的自动求导。
以swish acivation为例进行说明,其表达式为f(x) = x * sigmoid(x),通过简单的数学推导得到其梯度的解析式为f'(x) = sigmoid(x) + x * sigmoid(x) * (1 - sigmoid(x));先把这个结果放一边,看看自动求导框架是如何一步步求出这个结果的,画出计算图如下:
除了计算图以外,我们还需要定义几个基本函数的求导规则,在这个例子里涉及两个函数,一个是乘法,另一个是sigmoid函数(实际上sigmoid也是由几个基本函数构成的,这里我们将其视为一个整体)
f(x, y) = x * y
# gradient for x: y
# gradient for y: x
g(x) = sigmoid(x) # 1 / (1 + exp(-x))
# gradient for x: sigmoid(x) * (1 - sigmoid(x))
回到刚才的计算图上,反向传播先经过乘法运算,根据上面的求导规则,路径1上的梯度为sigmoid(x),路径3上的梯度为x;路径3再反向传播要经过路径2,除了sigmoid(x)本身的梯度外,还要乘上输入进来的梯度x,所以最终路径2上的梯度为x * sigmoid(x) * (1 - sigmoid(x)),路径2和路径1汇聚到一起,所以最终的梯度为sigmoid(x) + x * sigmoid(x) * (1 - sigmoid(x)),刚好等于我们用数学公式计算出来的结果。自动求导框架正是依靠这些基础的规则和链式求导法则在高效准确的运作。
显存被谁吃掉了
先说一个结论,在绝大多数神经网络的训练过程中,显存占用的大头是中间结果,也就是所谓的“特征图”。那我们为什么要保留中间结果呢?当然是为了方便求导啊!还是以swish acivation为例,把它放入神经网络来看,x就是前一层输出的中间结果(特征图)
-
在适用乘法的求导规则时,要求我们要事先保留下中间结果x和sigmoid(x),有人可能会说只保留一个x不就可以了吗?sigmoid(x)可以通过计算得出,注意框架定义的乘法及其求导规则是通用规则,乘法的左右两边完全可能是不相关的两个值,所以必须同时保留下来。
-
在对sigmoid函数适用求导规则时,需要存下中间结果x。
在不考虑框架自身优化的情况下,显存占用就包括了两个x和一个sigmoid(x),注意x可不是一个单独的数值,而是类似32x32x128这样大小的特征图,考虑到swish acivation在网络中数量庞大,每出现一次就意味着巨大的显存浪费。
手动合并OP
那么有没有办法优化呢?当然是可以的,既然我们能用数学公式提前算出swish acivation的梯度,那么直接将其视为一个整体不就好了?无非就是定义一个新的函数和新的求导规则
swish(x) = x * sigmoid(x)
# gradient for x: sigmoid(x) + x * sigmoid(x) * (1 - sigmoid(x))
这样一来,计算图变成了下面这个样子:

x的梯度可以直接根据新的规则求出,而在新的规则下,我们只需要保留x这一个中间结果即可,sigmoid(x)可以根据x求出。
所以说,自动求导框架虽然省事,但是其缺陷也很明显,由于大部分求导规则是面向通用的函数,很难针对特定的场景进行自动优化而导致显存浪费。对swish acivation这样的函数,只能依靠工程师的经验手动的进行优化。
需要指出的是,现有的一些框架如TVM和TensorRT也能自动的对某些算子进行融合,进而大大提高计算效率,降低显存消耗,但是这些都属于部署阶段了,而本文讨论的均为训练阶段。
类似的优化案例还有inplace-abn,针对的是类似BN-ReLU-Conv这样的常见结构组合,如下所示
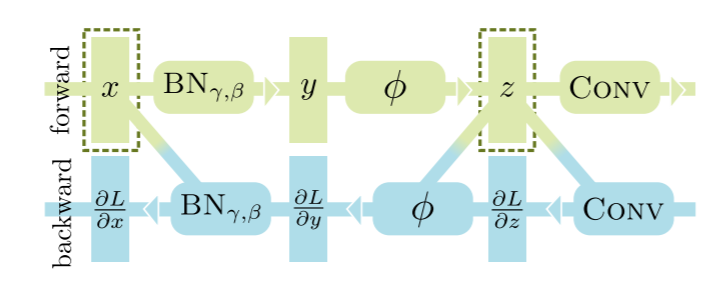
图中的虚线框是需要保留的中间结果,inplace-abn的优化思路是只保留中间结果z,通过反推得到x,然而众所周知ReLU是不可逆的运算,因此inplace-abn将其替换为了Leaky ReLU,计算图变成了如下形式:
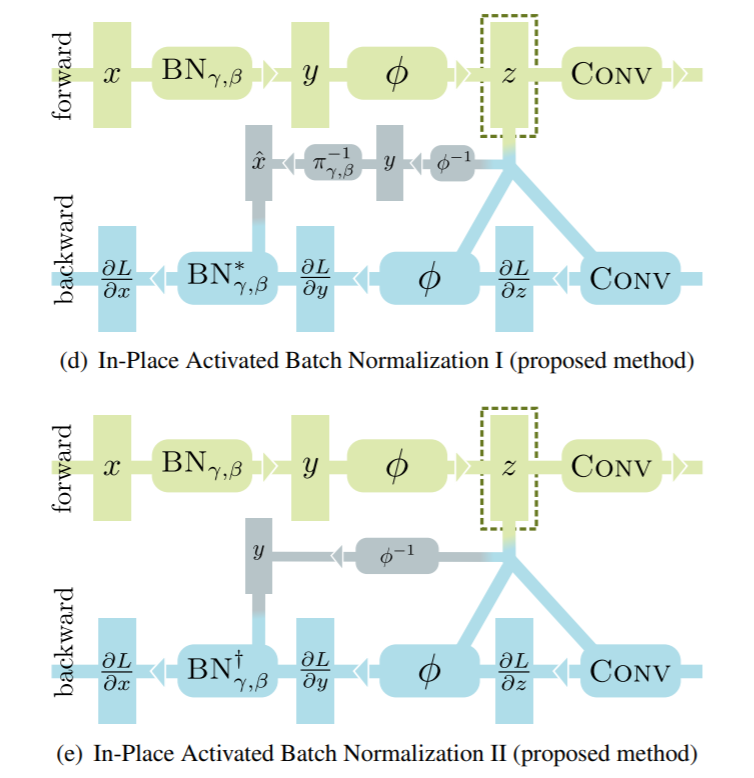
接下来的事情就是用数学的方式手动求出导数,然后定义成规则即可。
对I型,我们有
∂yj∂γ=ˆxj,∂yj∂β=1,∂yj∂ˆxj=γ∂L∂γ=∑mj=1∂L∂yj∂yj∂γ=∑mj=1∂L∂yjˆxj,∂L∂β=∑mj=1∂L∂yj∂yj∂β=∑mj=1∂L∂yj,∂L∂ˆxj=∂L∂yj∂yj∂ˆxj=∂L∂yjγ∂ˆxj∂σ2B=−12(σ2B+ϵ)xj−μB√σ2B+ϵ=−ˆxj2(σ2B+ϵ),∂ˆxj∂μB=−1√σ2B+ϵ∂L∂σ2B=∑mj=1∂L∂ˆxj∂ˆxj∂σ2B=−γ2(σ2B+ϵ)∑mj=1∂L∂yjˆxj=−γ2(σ2B+ϵ)∂L∂γ∂L∂μB=∑mj=1∂L∂ˆxj∂ˆxj∂μB=−γ√σ2B+ϵ∑mj=1∂L∂yj=−γ√σ2B+ϵ∂L∂β∂σ2B∂xi=2(xi−μB)m,∂μB∂xi=1m,∂ˆxi∂xi=1√σ2B+ϵ∂L∂xi=∂L∂ˆxi∂ˆxi∂xi+∂L∂σ2B∂σ2B∂xi+∂L∂μB∂μB∂xi=(∂L∂yi−1m∂L∂γˆxi−1m∂L∂β)γ√σ2B+ϵ
对II型,更进一步,直接用yi=ˆxi∗γ+β的反函数,ˆxi=yi−βγ进行替换即可
∂L∂γ=∑mj=1∂L∂yjˆxj=∑mj=1∂L∂yjyj−βγ=1γ∑mj=1∂L∂yjyj−βγ∑mj=1∂L∂yj=1γ[∑mj=1∂L∂yjyj−β∂L∂β]∂L∂xi=(∂L∂yi−1m∂L∂γˆxi−1m∂L∂β)γ√σ2B+ϵ=(∂L∂yi−1m∂L∂γyi−βγ−1m∂L∂β)γ√σ2B+ϵ=[∂L∂yi−1γm∂L∂γyi−1m(∂L∂β−βγ∂L∂γ)]γ√σ2B+ϵ
虽然推导过程有些复杂,但写出求导公式后,我们只需要将其封装进手写的模块中即可。原论文中的实现表明,采用Inplace-abn后,显存占用最高可下降50%左右,而且由于Leaky ReLU实际效果其实与ReLU非常接近,省下来的显存可以用于提高batch_size,模型训练实际上能从中得到更大收益。
还能更进一步吗?
回想前面的优化过程,我们发现其实这是一种典型的时间换空间的做法,虽然模型占用的显存下降了(舍弃了大量中间结果),但是我们定义的求导规则非常复杂,计算步骤明显多于优化前,其根本原因并非是不需要中间结果,而是有办法在求导过程中实时的计算出之前被舍弃掉的中间结果。考虑GPU上显存资源与计算资源的关系,只用较少的计算量和额外的一点计算时间换取宝贵的显存资源,这么做实际上是划算的。
如果沿着这个思路更进一步,所有的中间结果都不需要存储了,只需要存最初的输入即可,因为所有的中间结果都可以由输入重新计算得到,然而这个方案显然是不划算的,因为反向传播的过程是“由深入浅”,而计算中间结果的过程是“由浅入深”,二者的方向并不匹配,每当我们需要中间结果时就需要从头再来一遍,这样的计算和时间开销显然是不划算的。
如果折中一下呢?这就是OpenAI提出的gradient-checkpoint的思路,在神经网络中间设置若干个检查点(checkpoint),检查点以外的中间结果全部舍弃,反向传播求导数的时间,需要某个中间结果时,从最近的检查点开始计算,这样既节省了显存,又避免了从头计算的繁琐过程;
从代码层面来看,原版实现用的是tensorflow,由于是静态图的缘故,需要用到grapheditor等一系列骚操作,而且包含了很多“智能”寻找bottleneck选择为checkpoint的代码,很容易劝退新人。但是如果看一下pytorch的官方实现,你会惊讶的发现gradient-checkpoint的核心部分出奇的简单,这也算是动态图以及pytorch的一点小优势吧,当然pytorch版本的实现并不包括智能寻找checkpoint点的功能,需要人为设定。核心代码如下所示:
class CheckpointFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, run_function, preserve_rng_state, *args):
check_backward_validity(args)
ctx.run_function = run_function
ctx.preserve_rng_state = preserve_rng_state
if preserve_rng_state:
ctx.fwd_cpu_state = torch.get_rng_state()
# Don't eagerly initialize the cuda context by accident.
# (If the user intends that the context is initialized later, within their
# run_function, we SHOULD actually stash the cuda state here. Unfortunately,
# we have no way to anticipate this will happen before we run the function.)
ctx.had_cuda_in_fwd = False
if torch.cuda._initialized:
ctx.had_cuda_in_fwd = True
ctx.fwd_gpu_devices, ctx.fwd_gpu_states = get_device_states(*args)
ctx.save_for_backward(*args)
with torch.no_grad():
outputs = run_function(*args)
return outputs
@staticmethod
def backward(ctx, *args):
if not torch.autograd._is_checkpoint_valid():
raise RuntimeError("Checkpointing is not compatible with .grad(), please use .backward() if possible")
inputs = ctx.saved_tensors
# Stash the surrounding rng state, and mimic the state that was
# present at this time during forward. Restore the surrounding state
# when we're done.
rng_devices = []
if ctx.preserve_rng_state and ctx.had_cuda_in_fwd:
rng_devices = ctx.fwd_gpu_devices
with torch.random.fork_rng(devices=rng_devices, enabled=ctx.preserve_rng_state):
if ctx.preserve_rng_state:
torch.set_rng_state(ctx.fwd_cpu_state)
if ctx.had_cuda_in_fwd:
set_device_states(ctx.fwd_gpu_devices, ctx.fwd_gpu_states)
detached_inputs = detach_variable(inputs)
with torch.enable_grad():
outputs = ctx.run_function(*detached_inputs)
if isinstance(outputs, torch.Tensor):
outputs = (outputs,)
torch.autograd.backward(outputs, args)
grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else inp
for inp in detached_inputs)
return (None, None) + grads
注意到最近旷视开源的MegEngine,在PR的时候提到一个亚线性显存优化技术,其实就是gradient-checkpoint技术,详情可参考论文Training Deep Nets with Sublinear Memory Cost,当然MegEngine肯定在细节上对其进行了一些优化,本文就不展开讨论了。
CUDA版的swish activation
回到swish activation的优化上来,如果要追求效率的极致提升,下一步考虑的方案应该是手写C++ extension,将计算从python层面转移到C++与CUDA上。
如何基于 pytorch写C++扩展,官方文档上有非常详细的教程,写法和方式也都比较灵活,可以根据自己的习惯进行选择,这里我们选择利用setuptools的方式进行构建
pytorch在用户自定义扩展上也是做了非常多的支持,用户能非常方便的使用pytorch底层定义好的一些类和函数;在写CUDA函数时,pytorch还提供了一个CUDAApplyUtils.cuh头文件,专门用于优化pointwise操作的情况,以减小拷贝和临时存储的显存浪费(用于lambda函数,函数名非常直观,CUDA_tensor_applyN表示操作数的个数,N可以为1,2,3,4,用户还可以指定每个操作数的属性,如只读/读写,针对每对情形都有专门的优化实现)
对于swish activation来说,由于全是pointwise操作,利用这个优化技巧可以把显存占用进一步压缩。具体代码可参考swish_optimize
简单对比一下以上几种实现在实际场景中(单卡RTX 2070,resnet50, bs=32)的显存占用情况和运行时间(一次forward & 一次backward & 参数更新)
- 无优化纯Python:GPU memory=6383MB,time=223ms
- 合并算子(Python):GPU memory=5139MB,time=234ms
- 合并算子(CUDA):GPU memory=5143MB,time=188ms
从上述对比结果来看,结果基本符合前文的分析,纯Python的实现下,显存优化后的由于是时间换空间,所以显存占用降低了,而时间稍有增加;在CUDA版本的优化下,一方面得益于C++的高效,另一方面得益于由于pointwise计算的优化,在显存占用降低的同时,计算时间也大幅缩短
如果觉得本文对您有帮助,欢迎打赏我一杯奶茶钱~
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK