

实现一个现代编译器
source link: https://taodaling.github.io/blog/2022/04/09/%E5%AE%9E%E7%8E%B0%E4%B8%80%E4%B8%AA%E7%8E%B0%E4%BB%A3%E7%BC%96%E8%AF%91%E5%99%A8/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

- 语言:可能字符串的集合
- 字符串:有限符号序列,每个符号都来自相同的有限字符集
- 字符集:所有可能符号组成的集合
编译器结构
如果有N种语法和M种机器,那么我们需要实现NM个编译器,但是如果允许编译器前后端分离,那么只需要实现N个前端和M个后端即可。
编译器的分为前端和后端,前端输入是源代码,而输出是中间表示(IR),而后端的输入是中间表示,输出是可以执行的机器码。前端不需要考虑机器底层细节,而后端不需要考虑语法细节。
分词的作用是:
- 从源代码中去除不必要的空白字符和注释
- 将源代码的输入分解为Token
分词一般可以通过正则表达式来实现
正则表达式
正则表达式基本元素
a, 字面量,匹配自身@, 空字符串(正式写法是ϵ,这里只是出于简化的目的)A|B,A或BAB,先A后BA*,匹配任意多次A
其余扩展元素可以通过基本元素的组合实现
A?,等价于A|@A+,等价于AA*[ABC],等价于A|B|C[a-cA-B],等价于[abcAB]
给定一个正则表达式和一个输入字符串,可能存在不同的匹配方案。比如if8可以匹配一个标识符,也可以先后匹配if和8。下面是为了确定匹配关系的规则:
- 最长匹配:最长可以匹配任意正则表达式的输入前缀,将作为下一个token
- 规则优先级:对于特定的前缀,如果有多个正则表达式可以匹配,则第一个正则表达式将决定token类型。
正则表达式的实现
可以通过有限自动机(finite automaton)来实现正则表达式。
自动机是一副有向图,每个状态对应图中的一个结点,如果存在符号x使得从状态A向状态B迁移,则从A到B有一条标记x的有向边。
自动机会有两个特殊状态:开始状态(start state)和中止状态(final state)。每次匹配都从开始状态出发,如果最终到达中止状态则匹配输入字符。
如果自动机中每个状态的出边上标记的符号都不同,那么自动机为确定有限自动机(deterministic finite automaton),否则为非确定有限自动机(nondeterministic finite automaton)。
构建NFA的算法可以采用Thompson算法。
在得到了NFA后,由于NFA是不确定的,因此在匹配的时候需要枚举所有可能性,会降低性能。观察可以发现对于一段输入,NFA可能会处于多个状态,换言之,处于某个状态集合,而对于某个符号,NFA会从某个特定的状态集合转移到另外一个特定的状态集合。因此如果我们将NFA的状态集合作为DFA的状态,那么就可以构建一个DFA。拥有n个状态的NFA的状态集合是2n级别的,但是实践中可达的状态集合只有大约n个,因此这个方法是可行的。
语法分析的作用是判断某个字符串是否属于某一语言,它的输入是Token序列。
上下文无关语法
上下文无关语法拥有一系列下面形式的产生式:
symbol -> symbol ... symbol
左边是一个符号,右边可以是任意数目的符号。符号分为两类:
- 终止符(terminal):某个特定的Token
- 非终止符(nonterminal):出现在某个产生式的左边
其中开始符S是一个特殊的非终止符。同时为了方便解析,需要引入一个文件结束符号$,以及新的开始符S'->S$。
展开(derivation)
展开指从开始符展开为整个字符串。展开分为两类:
- 最左展开:每次选择最左边的非终止符展开
- 最右展开:每次选择最右边的非终止符展开
解析树(Parse Tree)
在展开的时候,每次替换非终止符时,都将原来的非终止符和展开的右式中的符号连接,形成的树为解析树。
如果一个语法可能将相同的字符串解析为两颗不同的解析树,那么这个语法是歧义的。一般有歧义的语法可以通过引入额外的非终止符来去除歧义,但是依旧存在一些语法无法消除歧义,这种语法一般不适合作为编程语言。
比如只有加法和乘法的语法定义如下:
S -> E$
E -> num
E -> E + E
E -> E * E
前者对于1+2*3生成的解析树有两种可能:
E-------
| | |
1 + E----
| | |
2 * 3
E------
| | |
| * 3
|
E------
| | |
1 + 2
通过引入新的非终止符可以得到
S -> E$
M -> num
M -> M * M
E -> M
E -> E + E
它的解析树是唯一的,即
E-------
| | |
1 + M----
| | |
2 * 3
一些术语定义
- FIRST集合:给定符号串
y,定义FIRST(y)表示所有可能从y导出的字符串的第一个符号组成的集合。 - nullable(X):给定符号
X,nullable(X)为真当且仅当X能展开为空字符串 - FOLLOW(X):给定符号
X,如果某个终止符t,存在某种可能的展开式包含Xt,那么t属于FOLLOW(X)。
如果有多个满足上面条件的FIRST和FOLLOW集合,那么取值为最小的集合。
计算这些集合可以使用不动点算法。
For each terminal symbol Z
FIRST[Z] = {Z}
repeat
for each production X -> Y[1] Y[2] ... Y[k]
if Y[1] ... Y[k] are all nullable (or k = 0)
then nullable[X] = true
for each i from 1 to k, each j from i + 1 to k
if Y[1] ... Y[i - 1] are all nullable (or if i = 1)
then FIRST[X] = FIRST[X] + FIRST[Y[i]]
if Y[i + 1] ... Y[k] are all nullable (or if i = k)
then FOLLOW[Y[i]] = FOLLOW[Y[i]] + FOLLOW[X]
if Y[i + 1] ... Y[j - 1] are all nullable (or if i + 1 = j)
then FOLLOW[Y[i]] = FOLLOW[Y[i]] + FIRST[Y[j]]
until FIRST, FOLLOW, and nullable did not change in this iteration
对于一些简单的语法,如果我们可以通过后一个Token确定唯一的产生式,那么我们可以用递归下降的方式解析Token串。
递归下降能被使用的条件是对于所有的非终止符X,以及给定的下一个输入符号t,能唯一确定采用某个X的产生式。即我们可以通过一个二维表来表达这样的转移关系,这个二维表称为预测解析表(predictive parsing table)。
构建预测解析表的算法:对于产生式X->y和每一个FIRST(y)中的元素T,将产生式加入到预测解析表的第X行第T列。同样的,如果y可空,那么对于每一个FOLLOW(y)(这里应该是笔误,应该是FOLLOW(X))中的元素T,将产生式加入到预测解析表的第X行第T列。
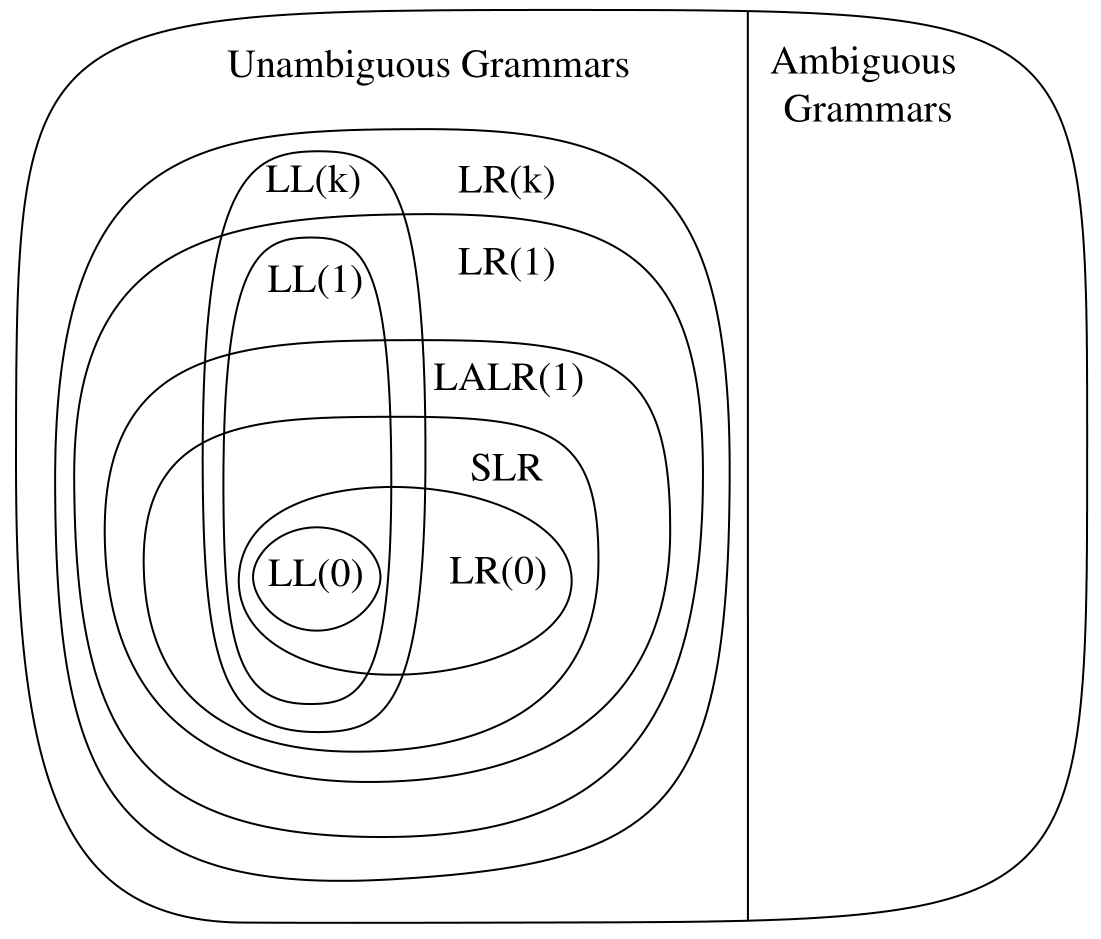
如果生成的预测解析表中没有重复表项,这样的语法称为LL(1)(left-to-right parse, leftmost-derivation, 1-symbol lookahead)。如果我们通过k个后继Token的信息构成一个k+1维的预测解析表,且表中没有重复表项,这样的语法称为LL(k),LL(k-1)语法一定也是LL(k)语法。
消除左递归
语法如果出现左递归,则一定不是LL(1)语法。
E -> Eb
E -> a
因为a一定是FIRST(Eb)的元素。可以发现E=ab*,我们可以通过一些技巧来消除左递归:
E -> aD
D -> bD
D ->
如果语法中存在非终止符,存在两个产生式,拥有非空公共前缀,那么这样的语法一定不是LL(1)语法。
S -> if E then S else S
S -> if E then S
我们可以使用提取公共部分的方法来消除问题
S -> if E then S X
X -> else S
X ->
一般如果遇到语法错误(输入串不存在于语言中),那么最简单的方式是抛出异常并结束编译。但是这样对用户不友好,因为每次只能报告一个编译错误。有两种可行的恢复编译的方式:
- 插入:插入一个期望的字符,但是这种方式可能会引起另外一个错误,最后导致无限循环
- 删除:删除后续不被期望的字符,这种方式比较安全且简单
LL(k)解析技术的缺点是必须在只有k个输入Token的情况下就必须确定使用某个产生式。LR(k)是一种更加强大的解析技术,它在遇到整个产生式后,并额外读取k个后继Token后才确定使用某个产生式。LR(k)表示left-to-right parse, rightmost-derivation, k-token lookahead。
LR解析算法,维护一个栈和输入,其中输入的前k个Token可以被提前得知。基于栈中和输入的前k个Token的信息,解析器会执行下面两类操作:
- Shift:读取输入的下一个Token,并入栈
- Reduce:选择一个产生式
X->ABC,从栈中分别弹出C,B,A,之后将X入栈。
初始时栈为空,输入为完整的源代码。如果对$执行Shift操作,则解析器接受源代码并成功停止。
LR解析引擎
LR解析器如何知道该做什么操作,需要通过一个DFA来实现,并且由于DFA不具有解析上下文无关文法的能力,因此DFA解析的是栈上的数据,而不是输入中的数据。
DFA的边上是可能出现在栈中的符号(终止符和非终止符),通过一个二维表来表示。行为状态,列为input中下一个符号,单元格中保存的是具体执行的操作。操作有如下数类:
- s(n):执行Shift操作,并转移到状态n
- g(n):转移到状态n
- r(k):根据规则k执行reduce操作
- a:接受输入
如果没有标识操作,则代表解析错误。
自动机是从栈底向栈顶解析的,因此如果遇到出栈的时候我们需要恢复自动机的状态,这可以通过记录每个栈中符号对应状态来实现。
LR(0)
在产生式中,我们向右边加入一个.表示当前已经匹配的位置,比如S'->.S$。这样形成新的表达式称为item。每个dfa的状态实际上都是一个item集合闭包,即这个集合中如果存在一个状态,.在某个非终止符X之前,那么X的所有产生式对应的.在最前的item也都属于这个集合。
需要定义两个关键操作Closure(I)和Goto(I,X),前者表示生成I的闭包,后者表示集合中所有item中,删除掉.后不是X的item,并将其余item的.后移一位得到的新的集合的闭包。
Closure(I):
repeat
for any item A -> a.Xb in I
for any production X -> y
I = I + {X -> .y}
until I does not change
return I
Goto(I, X):
set J to the empty set
for any item A->a.Xb in I
add A -> aX.b to J
return Closure(J)
下面是构造LR(0)的DFA的算法,计算E集合的算法
T = {Closure({S'->.S$})}
E = {}
repeat
for each state I in T
for each item A->a.Xb in I
let J be Goto(I, X)
T = T + {J}
E = E + {(I, X, J)}
until E and T did not change in this iteration
计算R集合的算法
R = {}
for each state I in T
for each item A -> a. in I
R = R + {(I, A -> a)}
解析表如下:
- 对于每条E中的边(I, X, J),且X是终止符,在(I, X)处放入shift J操作
- 对于每条E中的边(I, X, J),且X是非终止符,在(I, X)处放入goto J操作
- 对于每个包含
S'->S.$的状态I,在(I,$)放入accept操作。 - 对于R中的任意元素(I, A->a),对于每个Token Y,在
(I,Y)中放入reduce n操作,其中n是A->a的编号。
开始状态为Closure({S'->.S$})。
和LL(k)类似,解析表不允许有重复表项,否则就不是一个合法的LR(0)语法。
SLR(simple LR)的表达能力比LR(0)更加强大。
SLR的解析表的构建于LR(0)基本没有区别,除了在构建R的时候额外使用了FOLLOW集合。
R = {}
for each state I in T
for each item A->a. in I
for each token X in FOLLOW(A)
R = R + {(I, X, A->a)}
对于R中的任意元素(I, X, A->a),在(I,X)中放入reduce n操作,其中n是A->a的编号。
SLR的解析表同样不允许有重复表项,否则不是合法的SLR语法。
LR(1)
LR(1)的item的定义较之LR(0)更加复杂,(A->a.b,x)表示序列a处于栈顶,输入的前缀是bx的展开式。同理LR(1)中的状态也是item的一个集合闭包。
Closure(I):
repeat
for any item (A->a.Xb, z) in I
for any production X->y
for any w in FIRST(bz)
I = I + {(X->.y, w)}
until I does not change
return I
Goto(I, X):
J = {}
for any item (A->a.Xb, z) in I
J = J + {(A->aX.b, z)}
return Closure(J)
开始状态为(S'->.S$,?),其中?可以选择任意一个符号。
R = {}
for each state I in T
for each item (A->a., z) in I
R = R + {(I, z, A->a)}
构建E的算法于LR(0)是相同的。
LALR(1)
LR(1)的解析表可能会非常庞大。如果我们通过将LR(1)中在不考虑lookahead符号的情况下相同的状态进行合并来减少解析表的大小,则可以得到LALR(1)解析技术(lookahead LR(1))。
LALR(1)相较于LR(1)的表达能力会有所下降,但是在实践上可以忽略不记,所有合理的编程语言都存在LALR(1)语法,然而在存储上LALR(1)会比LR(1)小很多。
一种简单的错误修复的方式是选择之前解析的15个Token,选择一个Token,尝试一次插入、删除、替换操作,并统计在执行了每个修复操作后最多能额外解析多少个新的Token,选择解析最多的那个方案。考虑总共有N种Token,则只需要尝试15(2N+1)种可能性而已。
抽象语法树
语法分析环节只是判断字符串是否是语言的一部分,但是要理解代码,我们需要将字符串转化为更加强大结构,AST。
简单来说,要为每种符号创建一个类型,并且如果是非终止符则是抽象类,且还需要为每个相关的产生式创建一个子类。
并且我们需要遍历整个AST来获得有用信息,一般使用访问者模式。
语义指的是语言的含义。语义分析阶段负责连接变量的使用和定义,检查每个表达式拥有合适的类型,并将抽象语法转化为更适合生成机器码的表达。
我们用一张符号表来记录某个命名空间中所有的符号以及它们的类型。在进入新的作用域的时需要创建新的符号表,并用新作用域中的符号替代原来的符号,这里可以使用栈加哈希表来实现,用栈记录被替换的符号信息,在离开作用域的时候恢复。
有时候我们会在一个作用域中引入另外一个作用域中的符号,这意味着我们需要同时维护多张符号表,这时候我们需要使用持久化平衡树来记录符号。
在构建完成符号表后,我们需要对表达式执行类型检查,确保表达式中的操作元可以被操作。类型检查实际上只需要使用访问者模式遍历AST,并返回表达式的类型信息即可。
类似AST,IR是一种树形结构。一个好的IR需要同时满足下面要求:
- 语法分析阶段能够容易生产
- 方便翻译成机器码
- 构建拥有简单明了的特性,简化后期优化阶段重构的任务
AST的单独片段可以代表非常复杂的含义,比如数组下标,函数调用等。而IR树单独片段拥有更加简单的含义,每个IR代码都类似于若干个机器码的复合,支持诸如读写、基础运算,移动,跳转等基础的指令。
下面给出一个非常简单的指令集用作IR
表达式(expression)表示的是计算一些值,没有副作用
- CONST(i),表示整数常量i
- TEMP(t),表示一个寄存器t,认为抽象机器拥有无限的寄存器
- OP(e1, e2),先后计算表达式e1和e2,之后对二者的结果通过指定的二元运算符(+-*/)进行合并
- MEM(e),位于内存地址e处的一个字长内存对应的整数值
- CALL(f, e0, e1, …),用参数e0, e1, … 调用函数f
- NAME(n),代表标签n的地址
- ESEQ(s,e),先执行语句s,之后计算e的结果并丢弃(这是一个特殊的命令,可能带有副作用)
语句(statement)用于控制程序的执行,可能带副作用
- MOVE(dest, e),将表达式e的结果赋值给dest,dest可以是寄存器或内存
- EXP(e),计算表达式e,但是把结果丢弃
- SEQ(s1,…,sn),顺序执行指令s1,s2,…,sn
- JUMP(e),跳转到地址e
- CJUMP(e, l1, l2),如果表达式e值为真则跳转到l1,否则跳转为l2
- LABEL(n),创建一个名字为n的标签(用于作为地址使用)
- RETURN(e1, …, en),从函数返回(e1, …, en)
在绝大部分情况下,E的子结点也是E,S的父结点一定是S,但是存在一种例外情况,这也是我们定义ESEQ的目的。
而如何从AST转化为IR呢,这里需要引入Syntax-directed翻译,即递归地对源语言进行遍历并翻译,而对于一个给定的源语言结构,翻译结果是唯一的。下面定义翻译函数:
- E(e),表示将源语言中的表达式e翻译为IR中的表达式
- S(s),表示将源语言中的语句s翻译为IR中的语句
对于标量(整数或布尔值)
- E(false)=CONST(0)
- E(true)=CONST(1)
- E(n)=CONST(n)
- E(a+b)=ADD(E(a),E(b))
- E(a-b)=SUB(E(a),E(b))
对于局部遍历或者函数参数
- E(x)=TEMP(x)
对于函数调用
- E(f(a,b,c,…))=CALL(NAME(f),E(a),E(b),E(c),…)
语句的翻译
- S(x=e)=MOVE(TEMP(x),E(e))
- S(s1;…;sn)=SEQ(S(s1),…,S(sn))
- S(if (e) s) = SEQ(CJUMP(E(e), t, f), LABEL(t), S(s), LABEL(f))
- S(while(e) s) = SEQ(LABEL(begin), CJUMP(E(e), t, f), LABEL(t), S(s), JUMP(NAME(begin)), LABEL(f))
函数的翻译,设函数的格式为f(x1: t1, …, xn: tn) : t',函数体s翻译结果为
- SEQ(LABEL(f), S(s))
- S(return) = RETURN()
- S(return e1, …, en) = RETURN(E(e1),…,E(en))
逻辑运算与跳转,比如a&b,由于存在短路(如果a为真,则b不会被计算),因此必须特殊进行翻译
- S(a&b)=ESEQ(SEQ(MOVE(TEMP(x),0),CJUMP(E(e1),t1,f),LABEL(t1),CJUMP(E(e2),t2,f),LABEL(t2),MOVE(TEMP(x),1),LABEL(f)),TEMP(x))
上面的翻译很冗杂,我们可以同过引入一种新的IR形式C(e,t,f),它表示如果e的结果为真,则跳转到t,否则跳转到f。这样我们可以递归的引入新的翻译
- C(true,t,f)=JUMP(NAME(t))
- C(false,t,f)=JUMP(NAME(f))
- C(e,t,f)=CJUMP(E(e),t,f) (优先级最低)
- C(!e,t,f)=C(e,f,t)
- C(a&b,t,f)=SEQ(C(a,l1,f),LABEL(l1),C(b,t,f))
- C(a|b,t,f)=SEQ(C(a,t,l1),LABEL(l1),C(b,t,f))
对于数组类型的,我们需要额外存储数组的长度属性(存在数组起始地址的前w个字节处),以保证可以执行越界检查。不带越界检查的翻译
- E(a[b])=MEM(E(a)+w*E(b)),其中w表示的是机器字长
加上越界检查后(这里ULT表示无符号小于操作,选择无符号的目的是为了避免处理负数)
- E(a[b])=ESEQ(SEQ(MOVE(ta,E(a)),MOVE(tb,E(b)),CJUMP(ULT(tb,MEM(ta-8)),ok,err),LABEL(ok)),MEM(ta+tb*8))
数组元素赋值操作也是类似的
- E(a[b]=e)=ESEQ(SEQ(MOVE(ta,E(a)),MOVE(tb,E(b)),CJUMP(ULT(tb,MEM(ta-8)),ok,err),LABEL(ok)),MOVE(MEM(ta+tb*8),E(e)))
IR Lowering
IR虽然提供了一套统一的中间表示,但是IR依旧太过复杂,不容易转化为机器代码。可以通过展开表达式和语句,获得一个更低层级的IR树(称为Canonical IR语法),它满足
- SEQ结点只能作为根结点
- 移除ESEQ
- 语句最多只有一个副作用
- CALL结点出现在树的顶部,和一个语句一般
从IR翻译为IR Lowering也是一种Syntax-directed翻译。
由于SEQ结点只出现为根结点,因此Canonical IR树实际上就是若干条语句的复合:s1;s2;...;sn。
为了将IR翻译为Canonical IR,需要引入两个不同的翻译函数L[![s]!]和L[![e]!],前者将语句翻译为多条语句,后者将表达式翻译为若干条语句和一条无副作用的表达式。记→s=s1;…;sn,那么L[![e]!]=→s;e′。
先给出表达式的推导规则:
| 类型 | 前提 | 结果 |
|---|---|---|
| 无副作用的语句 | e=CONST(i)∨e=NAME(l)∨e=TEMP(t) | L[![e]!]=•;e |
| L[![e]!]=→s;e′ | L[![MEM(e)]!]=→s;MEM(e′)${\cal L}[![\textit{JUMP}(e)]!] = \vec{s}; \textit{JUMP}(e')$ L[![CJUMP(e,l1,l2)]!]=→s;CJUMP(e′,l1,l2)${\mathcal L}[![\textit{ESEQ}(s,e)]!] = \vec{s}; \vec{s'}; e'$ | |
| 函数调用 | L[![ei]!]=→si;e′i ∀i∈0‥n | L[![CALL(e0,e1,…,en)]!]=→s0;MOVE(TEMP(t0),e′0);→s1;MOVE(TEMP(t1),e′1);…→sn;MOVE(TEMP(tn),e′n);MOVE(TEMP(t),CALL(t0,t1,…,tn));TEMP(t) |
| 二元运算 | L[![e1]!]=→s1;e′1${\cal L}[![e_2]!] = \vec{s_2}; e_2'$ | L[![OP(e1,e2)]!]=→s1;→s2;OP(e′1,e′2)${\mathcal L}[![\textit{OP}(e_1, e_2)]!] =\vec{s_1};\textit{MOVE}(\textit{TEMP}(t_1), e_1');\vec{s_2}; \textit{OP}(\textit{TEMP}(t_1), e_2')$ |
这里有对于二元运算有两种不同的翻译,第一种更加简单且容易被编译器优化,但是要求e1与e2可以交换执行,比如→s2修改了e′1中的涉及项,而后者则不会有依赖问题。
再给出语句的翻译规则
| 类型 | 前提 | 结果 |
|---|---|---|
| SEQ | L[![SEQ(s1,…,sn)]!]=L[![s1]!];…;L[![sn]!] | |
| EXP | L[![e]!]=→s;e′ | L[![EXP(e)]!]=→s${\mathcal L}[![\textit{JUMP}(e)]!] = \vec{s}; \textit{JUMP}(e')$ ${\mathcal L}[![\textit{CJUMP}(e,l_1,l_2)]!] = \vec{s}; \textit{CJUMP}(e', l_1, l_2)\$ |
| LABEL | L[![LABEL(l)]!]=LABEL(l) | |
| 寄存器赋值 | L[![e]!]=→s′;e′ | L[![MOVE(TEMP(x),e)]!]=→s′;MOVE(TEMP(x),e′) |
| 内存赋值 | L[![e1]!]=→s′1;e′1${\mathcal L}[![e_2]!] = \vec{s_2'}; e_2'$ | L[![MOVE(MEM(e1),e2)]!]=→s′1;→s′2;MOVE(MEM(e′1),e′)${\mathcal L}[![\textit{MOVE}(\textit{MEM}(e_1), e_2)]!] = \vec{s_1'}; \textit{MOVE}(\textit{TEMP}(t), e_1');\vec{s_2'}; \textit{MOVE}(\textit{MEM}(\textit{TEMP}(t)), e_2');$ |
内存赋值也存在两种翻译,第一种要求e1与e2可以交换执行,而后者则不需要。
Control-Flow Graphs和Trace
IR Lowering后的IR树依旧存在一个问题,CJUMP指令可以选择跳转两个地址,一般情况上是不存在匹配的机器码的。要解决这个问题,我们需要强制CJUMP(e,t,f)指令中f标签紧跟在CJUMP指令之后。
将语句分成三类:
- 普通语句,即顺序执行的语句,包括CALL
- 跳转语句,包括RETURN,JUMP,CJUMP
- 标签,可以作为跳转的目标
一个基础块是若干条语句组成的序列,如果基础块的任意部分被执行,那么整个块都必须被执行。因此可以认为基础块是最小执行单元,对基础块的切分是没有意义的。
给定整个代码序列s1;…;sn,一个基础块是一个子序列 si;…;sj,其中除了首尾语句外,中间语句都是普通语句,且si只能是普通语句或标签,而sj只能是普通语句或跳转语句。当然如果基础块只包含一条语句,这条语句可以是任何类型的。
将基础块作为图中的结点,跳转作为边,构建一副有向图,可以发现每个结点的出度最多为2。形成的图称为control-flow graph(cfg)。
这里需要特别注意的是如果一个基础块不是以跳转结束的,这说明下一块是以标签开头的,那么应该在这个基础块的尾部插入一条跳转语句,跳转到下一块。
trace
要重组基础块为一个整体,通常的技术是通过构建trace。trace指的是若干个基础块组成的序列,且前一块存在一条到后一块的边。一个好的重组应该创建大的trace。为了指令缓存性能,应该尽量将频繁执行的代码包含进来。
简单的贪心算法是选择任意一个没有被选过的块,之后找到任意一条只包含未选块的路径,将这个路径作为新的trace选择。
这里有两个优化点:
- 为了增大trace,应该尽量选择没有入度的块
- 为了缓存性能,应该在选择块(起点或分支)的时候,尽量选择热点块。
所谓的热点块可以是出现在循环中的代码。
构建了trace序列后,我们可以通过任意排列trace得到完整代码。接下来我们需要修复跳转问题。修复方式如下:
- 如果CJUMP出现在trace中,且false标签指向的是下一个指令,则不需要修复。
- 如果CJUMP出现在trace中,且false标签指向的不是下一个指令,true标签指向的是下一个指令。这时候对条件取反,并交换true标签和false标签即可。
- 如果CJUMP出现在trace尾部,则还需要在后面插入一个JUMP指令,直接跳转到false地址。
- 如果JUMP指令跳转的位置是下一个标签,则删除JUMP指令。
目前我们已经得到了低级的IR代码,指令选择阶段会将其翻译未抽象汇编代码,与实际汇编代码的区别在于可以支持无数个寄存器和任意复杂的表达式。
由于存在大量不同的汇编指令可以使用来完成我们的目标,因此这个阶段我们需要挑选合适的汇编指令替代IR指令。
ISA全称为instruction set architechture,即指令集合架构。
目前主流的ISA是x86-64,拥有16个64位寄存器和64位地址。x86-64是2-address CICS架构,即每次运算时传入两个地址,其中一个地址即是运算元也是结果放置的地址。
在intel语法中,一般的二元运算是op dest, src,而在AT&A语法中,一般的二元运算是op src, dest。为了简单,这里我们采用intel语法。
| 操作 | 样例 | 解释 |
|---|---|---|
| mov | mov dest, src | 从src拷贝到dest |
| add,sub,mul,div | 算术运算 | |
| inc,dec | 自增和自减 | |
| and,or,xor,not | 二进制逻辑运算 | |
| shl,shr,sar | 二进制移位运算 | |
| jmp | 无条件跳转 | |
| jz/je,jnz/jne | 根据参数是否为0条件跳转 | |
| jl,jle,jg,jge | 根据比较结果条件跳转 | |
| jb,jbe,ja,jae | 根据无符号参数比较结果条件跳转 | |
| push,pop | 栈操作 | |
| test,cmp | 执行ALU操作 | |
| call | 调用子过程 | |
| ret | 从子过程返回 |
x86-64的寄存器包括: rax,rbx,rcx,rdx,rsi,rdi,rsp,rbp,r9-r15。
| Inter | AT&T | IR |
|---|---|---|
| 17 | $17 | CONST(17) |
| rax | %rax | TEMP(rax) |
| [rax] | (%rax) | MEM(TEMP(rax)) |
| [rbx+32] | 32(%rbx) | MEM(ADD(TEMP(rax), CONST(32))) |
| [rax+rbx*8] | (%rax,%rbx,8) | MEM(ADD(TEMP(rax),MUL(CONST(4),TEMP(rbx)))) |
在Intel中,运算元的大小会通过寄存器自动推断出来。但是如果运算使用的是内存,则会出现问题,比如inc [rax],这时候需要说明具体的字节数,比如inc qword ptr [rax],其余可用的长度有byte,word,dword。
同时运算最多允许一个运算元是地址。
用jcc代表所有条件跳转的指令,这些指令会基于一个特殊的寄存器——条件码寄存器(condition code register)中的内容判断是否跳转。而一般ALU中的运算会导致条件码的改变。
其中一些非常好用的用于改变条件码的指令:
- cmp:对两个运算元做减法操作并设置条件码(等价于比较操作)
- test:对两个运算元做逻辑且运算,并设置条件码
有时候我们需要读出条件码寄存器中的内容,比如我们要根据复杂的逻辑运算得出跳转条件。这时候可以使用setcc中的指令。比如setz al表示如果jumpz条件满足,则将al设置为1,否则为0。
ISA中的指令有时候不足以描述我们定义的IR中的一个指令,比如ISA中的指令不允许两个操作元都是内存,以及我们使用的是2-地址ISA,而IR中允许指定二元运算的结果地址。
我们需要定义一些tiles来匹配IR代码。每个tile都对应若干条ISA中的汇编代码,且其功能正好对应某些IR代码。
比如一个IR中的Add(t1,t2)操作对应的tile可以是:
mov t3, t1
add t3, t2
但是并不是说一个tile只对应一个IR结点,实际上MEM(ADD(TEMP(a), MUL(CONST(8), TEMP(i))))可以被映射为一个很简单的tile:mov dest, [a+8*i]
我们要设计的tile需要是完备的,即我们的tile能覆盖所有可能生成的IR树。同时tile要尽可能高效。
要从IR翻译为tile也是一种翻译函数,但是这个函数并不是syntax-directed。因为同样的IR结点可以有多种翻译。
tile选择算法
由于存在多种可能的IR树的tile翻译,因此要选择其中最高效的一种。有两种算法。
一种是贪心算法,非常简单,我们将tile按优先级排序,每次处理IR树结点的时候,优先选择第一个匹配的tile。
还有一种方式是动态规划。首先预估每个tile的执行时间,之后记录每个子树的最优解,这样问题就变成动态规划问题。
动态规划的效率一般很高,但是实际上我们无法精确计算一个tile的执行时间,因为这与到指令的顺序相关。但是大致的估计一般就足够了。
在汇编层面,函数调用等价于过程调用,其原理是将下一条指令地址(rip)入栈保存,之后跳转到函数的开始地址。rsp指向栈顶,栈是向下增长的。
sub rsp, 8 #预留8 byte
mov [rsp], rip
jmp f
栈帧是函数调用在栈上预留的一段空间,用于保存传入的参数、临时变量等。
传入的前6个参数通过寄存器rdi,rsi,rdx,rcx,r8,r9传入。对于后续的参数,以逆序的方式存在栈底传入。
一个实现简单的a+b操作的函数,它的汇编形式可能是
f: push rbp
mov rbp, rsp
sub rsp, 8*l
mov x, rdi
mov y, rsi
mov rax, x
add rax, y
mov rsp, rbp
pop rbp
ret
这里可以使用ISA提供的enter和leave操作来简化,前者会完成开始的3个指令,后者会完成倒数第3个和第2个指令。
f: enter 8*l, 0
mov x, rdi
mov y, rsi
mov rax, x
add rax, y
leave
ret
需要注意的是rsp必须按照16byte对齐,即rsp中的值应该能整除16,这是大量系统库的要求,否则调用其它过程会有问题。
caller-save和callee-save
由于过程可以继续调用其它过程,这意味着如果某个寄存器同时被二者使用,则需要一方负责恢复寄存器的状态。
寄存器分为caller-save和callee-save,前者由调用方负责备份,后者由被调用方负责备份。
caller-save的寄存器包括:rax,rcx,rdx,rsi,r8-r11。而其余寄存器则都是callee-save。
rbp一般用于备份rsp,即其存储的值是栈帧的开始地址。
但是如果我们可以在编译期计算过程需要的栈大小,那么我们就可以使用rsp减去栈大小得到栈帧开始地址。这样我们就能释放出rbp用于其它计算。
但是采用静态栈帧大小的缺点是我们不能在栈上分配动态长度的数组。
寄存器分配
对于抽象汇编代码,如果我们可以选择一块足够大的内存来分配给每个抽象寄存器一个唯一地址,那么我们就完成了寄存器分配。
而由于指令最多会使用三个寄存器,因此只需要三个寄存器就可以完成所有的操作。
事实上gcc -O0就使用了这种方式。
还有一种相对更好的方法-线性扫描寄存器分配。这种方法不仅性能远高于上面提到的方式,而且分配的性能很好。其原理就是在某个抽象寄存器第一次被使用的时候,分配一个实际的寄存器,在抽象寄存器被最后一次使用后,回收这个寄存器。
当然有可能多个抽象寄存器分配到了相同的寄存器,这时候就需要备份寄存器中的值来重复利用了。
优化的目的是提高程序的执行效率,但是不能改变程序的结果。
大量的代码可以通过空间和时间互换的技术来优化,比如循环展开中拷贝多份循环来增大代码空间,减少了循环带来的开销。
要执行代码分析,一般需要多种分析:
- 安全性分析:判断优化是否改变源程序的含义
- 成本分析:判断是否应该采用优化
优化发生的阶段
| 阶段 | 结构 | 优化 |
|---|---|---|
| HIR | AST,IR | Inlining,Specialization,Constant folding, Constant progagation, Value numbering |
| MIR | Canonical IR | Dead code elimination,Loop-invariant code motion,Common sub-expression elimination,Strength reduction,Constant folding&propagation(again),Branch prediction/optimization |
| LIR | Abstract Assembly,Assembly | Register allocation,Loop unrolling,Cache optimization,Peephole optimizations |
下面简单介绍各种优化技术
| 技术 | 简介 | 例子 |
|---|---|---|
| Register allocation | 将抽象寄存器映射到6个真实寄存器上,如果mov发生的抽象寄存器被映射到相同寄存器,则操作可以被消除 | |
| Constant folding | 如果操作元可以在编译期计算,则在编译期计算;如果分支条件的结果在编译期可知,则可以去除跳转命令 | 2+3+a=>5+a |
| Algebraic simplification | 在代数层面上做Constant folding | 1*a=>a |
| Unreachable code elimination | 在对起始基础块做搜索的时候,所有不可达的基础块都可以被删除(减少代码可以提高缓存命中) | return; … => return; |
| Inlining | 用函数体替代函数调用 | |
| Specialization | 创建特例化函数,用于接受特定类型的参数(比如参数是多态的基类时,可以提前确定一些信息) | |
| Constant propagation | 如果变量始终是常量值,则可以将变量的使用替代为常量 | x=1;y=x*2;=>y=2; |
| Dead code elimination | 如果语句的副作用永远不可能被观测到,则可以移除语句;变量定义后不再使用可以移除变量 | x=1;x=2;=>x=2 |
| Redundancy Elimination | 提取公共的表达式 | |
| Loop-invariant code motion | 提取不变的表达式 | |
| Strength reduction | 用廉价操作+-替代昂贵操作*/ | |
| Loop unrolling | 循环展开,减少分支跳转 |
live variable analysis
要合理的分配寄存器,就需要能够得知每条语句执行后,哪些变量依旧存活(已经定义过的变量,在改变之前可能会被读取)。
存活变量组成的集合为live set。live variable analysis负责计算每个程序点(语句之间以及基础块之间的边上)的live set。
变量是否存活又时候是无法确定的,比如
x:int = y; //is x live here
f();
return x;
由于f可能是一个永远不会退出的函数,因此x在定义后是否存活是无法得知的。在做存活性分析的时候应该做保守估计,即如果一个变量是否存活无从得知,应该始终认为是存活的。
CFG语法
数据流分析是一种计算信息的技术,比如计算存活变量。对于每条控制流中的边,都要计算信息。
| CFG node | IR |
|---|---|
| x←e | MOVE(x,e) |
| [e1]←e2 | MOVE(MEM(e1),e2) |
| if e | CJUMP(e,t,f) |
| start | LABEEL(f) |
| return e | RETURN(e) |
CFG语法中变量对应IR中的寄存器,同样存在表达式,其中可以出现常量,变量,内存和运算符:
e::=k|x|e1OPe2|[e1]
记use[n]表示在CFG的结点n处读取过的变量集合。def[n]表示在结点n处写入过的变量集合。对于表达式e,记vars[e]表示在表达式中出现过的所有变量组成的集合。
| 结点n | use[n] | def[n] |
|---|---|---|
| x←e | vars[e] | {x} |
| [e1]←e2 | vars[e1]∪vars[e2] | ∅ |
| if e | vars[e] | ∅ |
| start | ∅ | ∅ |
| return e | vars[e] | ∅ |
存活性分析
一个变量x在边E上是存活的,当且仅当存在从E出发可达的结点N,use[N]中包含x且中间没有结点修改过这个变量。
我们可以对每个变量的写入位置进行记忆化搜索,就可以算出变量在每条边上是否存活。
还有一种比较正式的方式,令in[n]表示结点n的所有入边的live set的并集,同理令out[n]表示结点n的所有出边的live set的并集。这样可以推出下面公式:
out[n]←⋃n′∈adj(n)in[n′]in[n]←use[n]∪(out[n]−def[n])
可以用不动点算法迭代计算上面公式。两者拥有相同的时间复杂度,都是O(VN),V是变量数,N是语句数(CFG结点数)
Available copies analysis
借助CFG,我们可以以与存活性分析类似的方式实现可用副本分析。如果一个变量始终是另外一个变量的副本,那么可以移除副本的拷贝,并替换前者为后者。
定义类似,数据流中计算的值是类似于{x=y,t=z}的集合。记gen[n]表示结点引入的新的元素(等式),而kill[n]表示结点移除的等式。
in(n)=⋂n′∈adj(n)out(n′)out(n)=gen(n)∩(in(n)−kill(n))
| n | gen(n) | kill(n) |
|---|---|---|
| x=y | {x=y} | x=z,z=x for all z |
| [e1]=e2 | ∅ | ∅ |
| if e | ∅ | ∅ |
| START | ∅ | {all nodes} |
| EXIT | ∅ | ∅ |
寄存器分配
寄存器分配阶段的任务是为每个变量分配一个真实的寄存器,并且希望能在其生命周期中始终占据这个寄存器(不需要备份到内存中)。一个寄存器可以分配给多个变量,但是这些变量不能同时存活。
存活性分析为我们提供了out[n],即离开结点n后依旧存活的变量集合。任意两个处于相同存活集合中的变量不能分配到相同的寄存器上,这样的变量称为相互干扰的。
推断图(inference graph)中所有结点都对应某一个变量,如果两个变量相互干扰,则在它们之间连一条无向边。寄存器分配问题就变成了对推断图的图着色问题。
图着色算法
Kempe's算法是一个启发性的算法。如果我们希望对图进行k着色,则每次迭代选择一个度小于k的顶点从原图中删除。
如果迭代结束时所有顶点都被移除了,则图可以被k染色,染色的方式非常简单,我们只要将顶点按照它们删除顺序逆向贪心染色即可,每次选择任意一个可用的颜色。
但是这个算法的问题在于,即使图可以被k染色,kempe's算法不一定能找到一个正确的删除顺序。
当Kempe's算法未能成功删除所有顶点,则任意选择一个顶点标记为spilling(存储在栈上),并从图中移除。这里可以启发性的选择使用不频繁的变量(不是在循环中的)。
在染色的时候即使标记为spilling的结点最终也是有机会被染色的,我们可以优先尝试进行染色,如果不行则标记为spill并分配一个栈位置。
对于溢出的变量,在要使用的时候,我们需要生成额外的指令来从栈上加载或写入。
一种简单的方式是始终保留三个寄存器专用于溢出变量的加载和使用。
但是上面的方式会使我们损失三个寄存器,考虑到总共可用的寄存器就不多,因此并不合理。一种更好的方式是对于溢出变量的读写,都引入一个新的临时变量来辅助。
之后对于得到的新的代码,重新做存活性分析和寄存器分配。新引入的临时变量的生命周期都非常短暂,这意味着染色会变得更简单。我们不断重复直到所有顶点都能被正确染色。实践上一般只需要一到两次迭代即可。
预分配寄存器
有些寄存器有特殊用处
- 对于乘法操作,
use(n)=rax,且def(n)={rax,rdx}。 - 对于call指令,会杀死所有caller-save寄存器:
def(n)={rax,rcx,rdx,...}
要合理分配寄存器,我们要把这些特殊寄存器的使用视作是特殊的临时变量,作为预染色结点加入到推断图中。预染色结点n与所有def(n)中出现的变量都相互干扰。
预染色结点的出现,要求我们修改之前提到的染色算法。
- 我们将所有的寄存器作为预染色特殊结点加入图中
- 预染色结点两两相互干扰
- 预结点允许和其它普通结点合并
- 应该将预染色结点视作拥有无穷的度数(保证最后删除且不会溢出到栈上)
- 如果
a<-e不能保存在某个寄存器t中,则认为变量a与寄存器t相互干扰
对于caller-save寄存器,与所有生命周期跨越call指令的变量都相互干扰。
对于生命周期没有跨过call指令的变量,则应该分配caller-save寄存器。
对于callee-save寄存器,使用之前必须保存。我们可以在函数开始前将这些寄存器中的内容拷贝到临时变量中,在函数退出前在拷贝回来。如果后来发现这些寄存器确实会被用到,则溢出到栈上;如果并不需要,则给临时变量分配与callee-save相同的寄存器,通过mov消除的方式去除额外的保存和恢复操作。
对于生命周期跨国call指令的变量,应该分配callee-save寄存器。
对于mov a, b操作,如果两个变量没有相互干扰,则可以合并两个变量为一个变量,这样就可以消除mov操作。
在合并变量(结点)的时候,可能会导致原本能k染色的图无法被k染色。这是由于创造了一些度数很大的顶点。而解决方案采用保守的态度,在合并的时候不允许合并后的结点度数超过k-1。
保守态度可能会使我们失去合并不同变量的机会,但是却可以避免引入溢出。

整体流程分为:
- Build: 构建推断图,并将结点按照是否参与过mov操作(作为起点或终点)分为两类,move-related和non-move-related。
- Simplify: 不断移除度数小于K的non-move-related结点
- Coalesce: 执行保守的顶点合并。之后回到顶点合并重新执行,直到剩下的顶点要么是度数不小于K,要么就是move-related的顶点。
- Freeze: 找到所有度数小于k的move-related顶点,将与它们相关的mov操作全部冻结,即之后认为这些顶点式non-move-related。之后回到Simplified阶段重新执行。
- Spill:不断剩下的度数不小于k的顶点,标记为spill并删除。
- Select:按照删除顺序逆向处理顶点,并为顶点分配颜色。
- 《Modern Compiler Implementation in Java》
- 《Introduction to Compilers》
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK